展开查看详情
1 .A Unified Platform for Real-time Storage and Processing Apache Pulsar as Stream Storage Apache Spark for Processing as an Example Yijie Shen yjshen 2019062 9
2 .Outline Motivation & Challenges Why Pulsar Spark-Pulsar Connector
3 .Motivation Ubiquity of real-time data Sensors, logs from mobile app, IoT Organizations got better at capturing data Data matters Batch and interactive analysis , stream processing, machine learning, graph processing The involvement of analytic platforms Unified / similar API for batch/declarative and stream processing E.g. Spark, Flink
4 .Challenges Compatibility with cloud infrastructure Multi-tenant management Scalability Data movement during its lifecycle Visibility of data Operational cost and problems Multiple systems to maintain Resource allocation and provisioning Message Queue Cold Storage
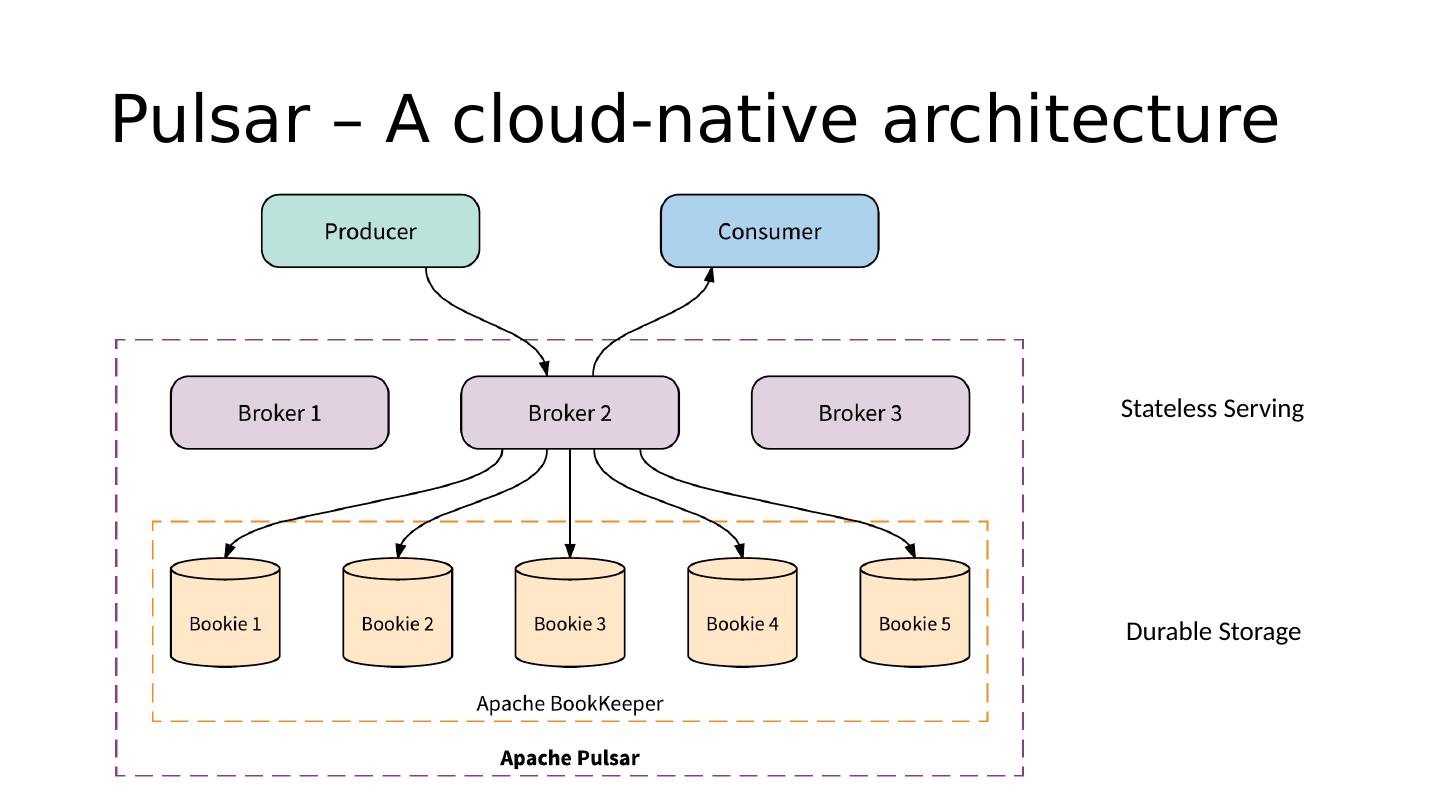
5 .Pulsar – A cloud-native architecture Stateless Serving Durable Storage
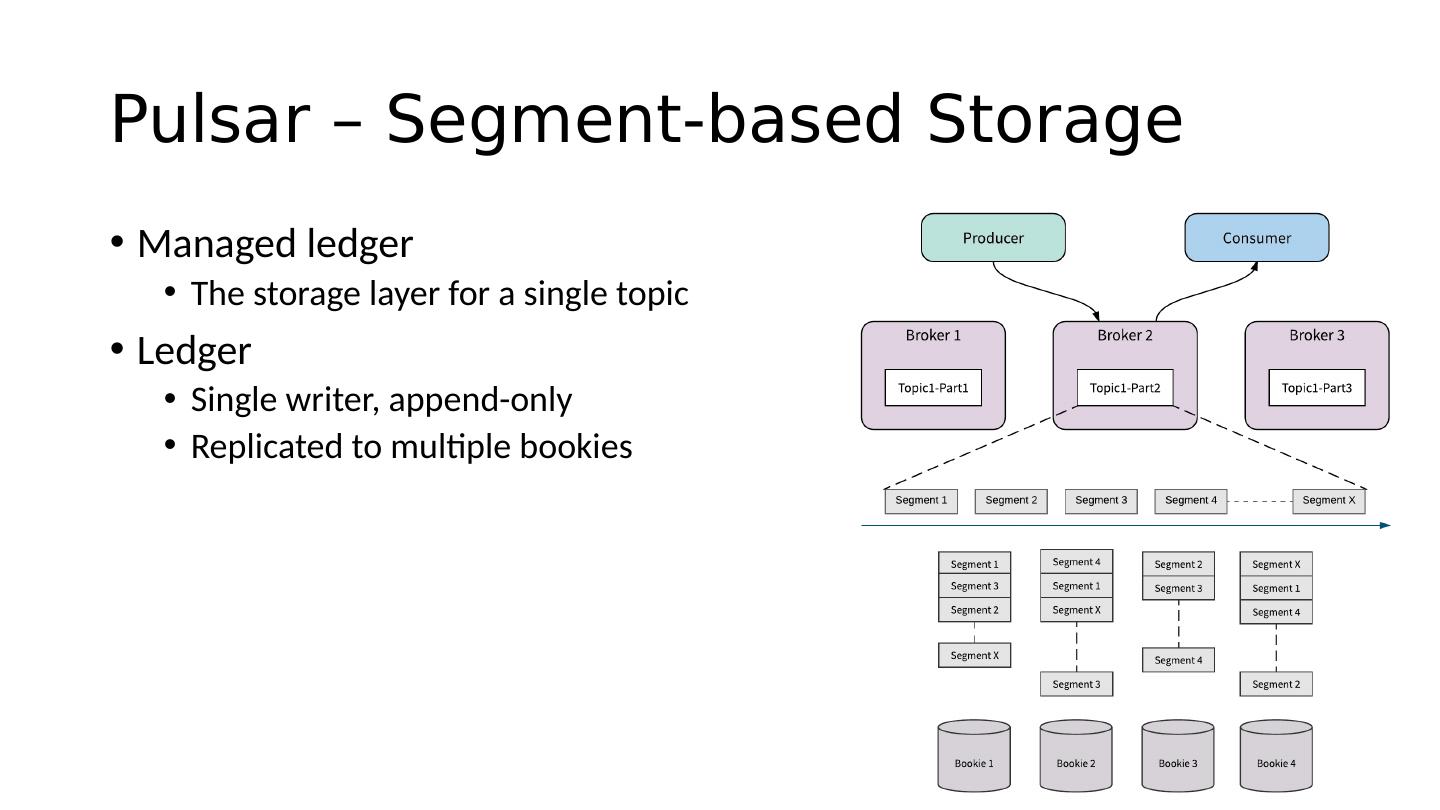
6 .Pulsar – Segment-based Storage Managed ledger The storage layer for a single topic Ledger Single writer, append-only Replicated to multiple bookies
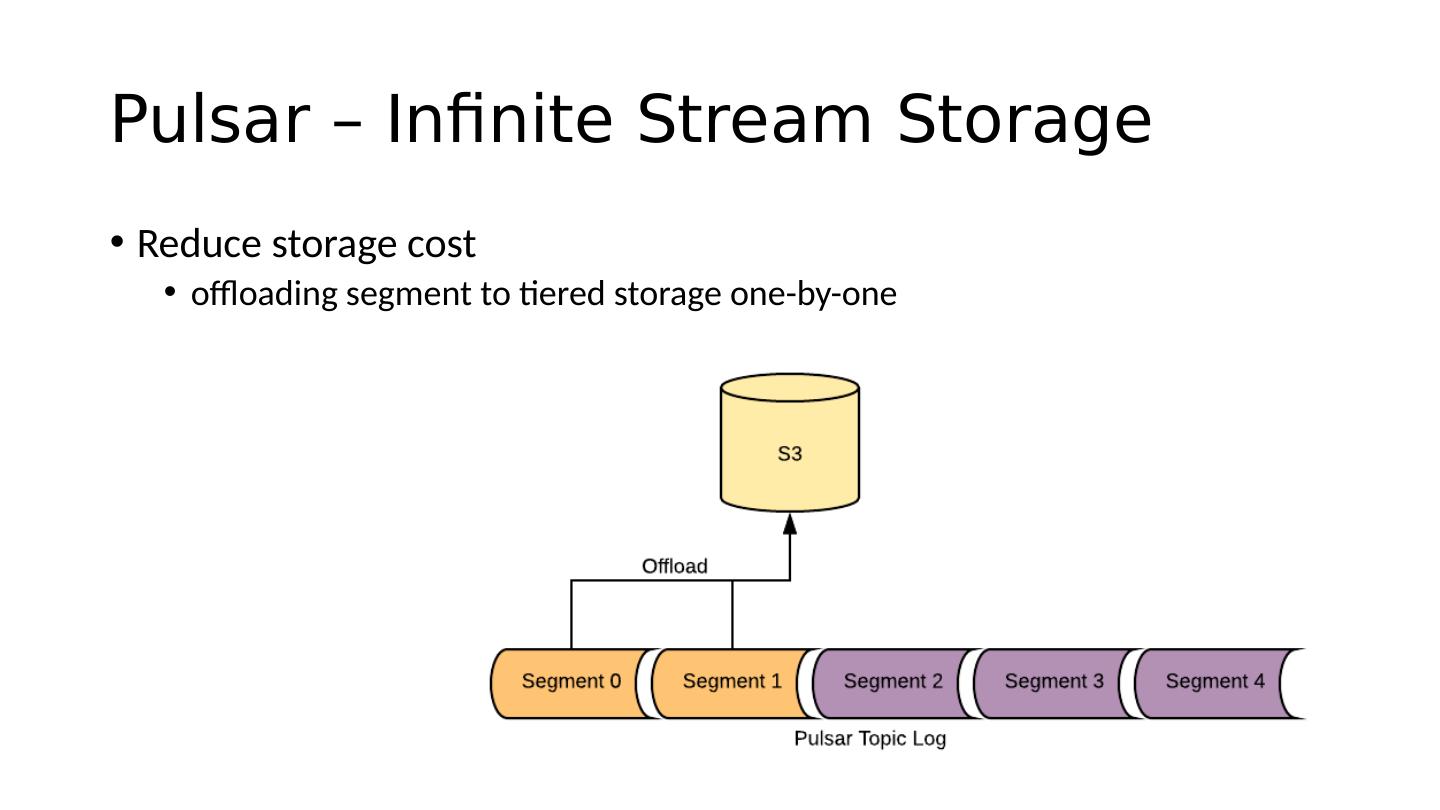
7 .Pulsar – Infinite Stream Storage Reduce storage cost offloading segment to tiered storage one-by-one
8 .Pulsar Schema Consensus of data at server-side Built-in schema registry Data schema on a per-topic basis Send and receive typed message directly Validation Multi-version
9 .Outline Motivation & Challenges Why Pulsar Spark-Pulsar Connector API Internals
10 .Spark Pulsar Connector – API Read val df = spark .read .format("pulsar") .option(" service.url ", "pulsar://...") .option(" admin.url ", "http://...") .option("topic", "topic1") .load() Write df .write .format("pulsar") .option(" service.url ", "pulsar://...") .option(" admin.url ", "http://...") .option("topic", "topic2") .save() Deploying ./bin/spark-submit --packages org.apache.pulsar.segment:psegment-connectors-spark-all _{{SCALA_BINARY_VERSION}}:{{PSEGMENT_VERSION}} ... Stream mode readStream writeStream start()
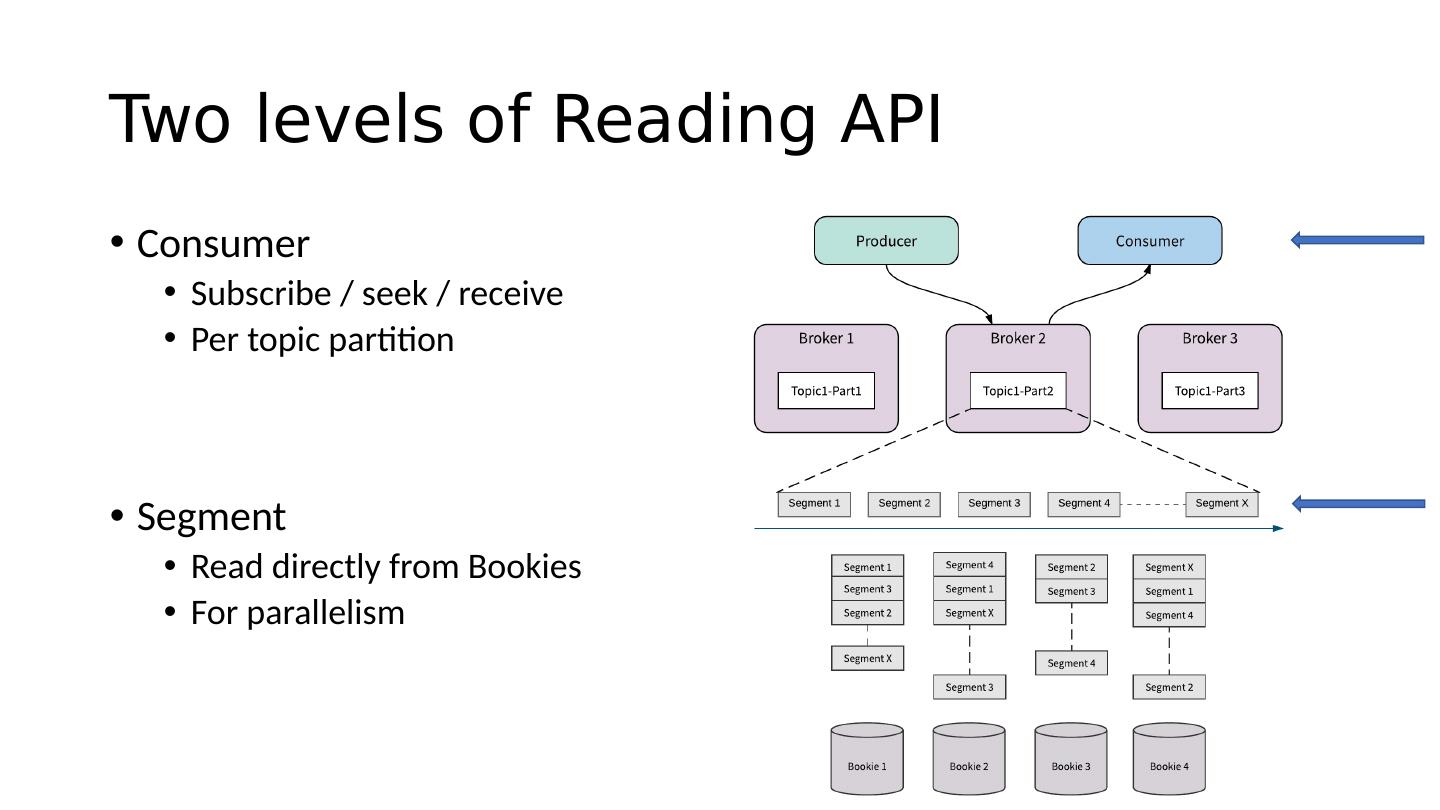
11 .Two levels of Reading API Consumer Subscribe / seek / receive Per topic partition Segment Read directly from Bookies For parallelism
12 .Spark Structured Streaming Overview Input and Output Input sources must be replayable Sinks must support idempotent writes for exactly-once semantic API that are streaming specifically Triggers how often the engine will attempt to compute a new result and update the output sink event time as watermark policy to determine when enough data has been received
13 .SS Source and Sink API trait Source { def schema: StructType def getOffset : Option[Offset] def getBatch (start: Option[Offset], end: Offset): DataFrame def commit(end: Offset): Unit def stop(): Unit } trait Sink { def addBatch ( batchId : Long, data: DataFrame ): Unit }
14 .Anatomy of StreamExecution availableOffsets offsetLog (WAL) getOffset () Logical Plan getBatch () IncrementalExecution addBatch () commit batchCommitLog Source StreamExecution Sink commit()
15 .Topic/Partition add/delete discovery Happens during logical planning getBatch (start: Option[Offset], end: Offset) Discovery topic differences between start and end Start – last end End – getOffset () Connector provide available offset for all topic/partitions for each getOffset Create DataFrame / DataSet based on existing topic/partitions SS take care of the rest Offset { topicOffsets : Map[String, MessageId ] }
16 .A Little More On Schema Regard Pulsar as structured data storage Only fetched once at the very beginning of query planning All topics for a DataFrame / DataSet must share same schema Fetched using Pulsar Admin API