展开查看详情
1 .Spark-SQL 在字节跳动的应用实践 白泉 baiquan@bytedance.com 2019 年 6 月 16 日
2 .目录 应用实践 Spark - SQL 引擎优化 执行计划自动调优 数据读取剪枝 其他一些优化 Spark - SQL 运行调优 自动引擎路由 / 自动参数调优 未来的一些工作
3 .团队介绍: 数据平台 - 查询分析团队 定位 为公司内部提供 Hive 、 Spark - SQL 等 OLAP 查询引擎服务支持。 目标: 提供全公司大数据查询的统一服务入口,支持丰富的 API 接口,覆盖 Adhoc 、 ETL 等 SQL 查询需求 支持多引擎的智能路由、参数的动态优化 Spark-SQL/Hive 引擎性能优化
4 .Spark - SQL 引擎优化 执行计划自动调优 基于 AE 的 ShuffledHashJoin 调整 Left join build left map 技术 数据读取剪枝 Parquet local sort BloomFilter & BitMap Prewhere 一些其它优化 优化效果: TPC_DS 较社区 branch2-3 平均提升 1.4 倍,部分 case 提升 2-3 倍
5 .1. 执行计划自动调优 基于 AE 的执行计划 自动调优 Spark Adaptive Execution ( Intel® Software ) , 简称 Spark AE , 总体思想是将 spark sql 生成的 1 个 job 中的所有 stage 单独执行,为每一个 stage 单独创建一个子 job , 子 job 执行完后收集该 stage 相关的统计信息(主要是数据量和记录数),并依据这些统计信息优化调整下游 stage 的执行计划。 优化点: 在 AE 的框架下,根据 shuffle 数据量大小,自动调整 join 执行计划: SortMergeJoin 调整为 ShuffledHashJoin 扩展 支持 left-join 时将左表 build 成 HashMap 。 目标 : 省去了大表 join 小表的情况下对 shuffle 数据的排序过程、 join 过程以 HashMap 完成,实现 join 提速
6 .SortMergeJoin 调整为 ShuffledHashJoin
7 .Left join build left side map 目标: 对于 Left-join 的情况,可以对左表进行 HashMap build 。使得小左表 left join 大右表的情况可以进行 ShuffledHashJoin 调整 难点: Left-join 语义:左表没有 join 成功的 key ,也需要输出 原理 在构建左表 Map 的时候,额外维持一个“是否已匹配”的映射表;在和右表 join 结束之后,把所有没有匹配到的 key ,用 null 进行 join 填充 以 A left join B 为例: 1 、初始化表 A 的一个匹配记录的映射表
8 .Left join build left side map 2 、 join 过程中,匹配到的 key 置为 1 ,没有匹配到的项不变(如 key3 ) 3 、 join 结束后,没有匹配到的项,生成一个补充结果集 R2
9 .Left join build left side map 4. 合并结果集 R1 和结果集 R2 , 输出最终生成的 join 结果 R 。
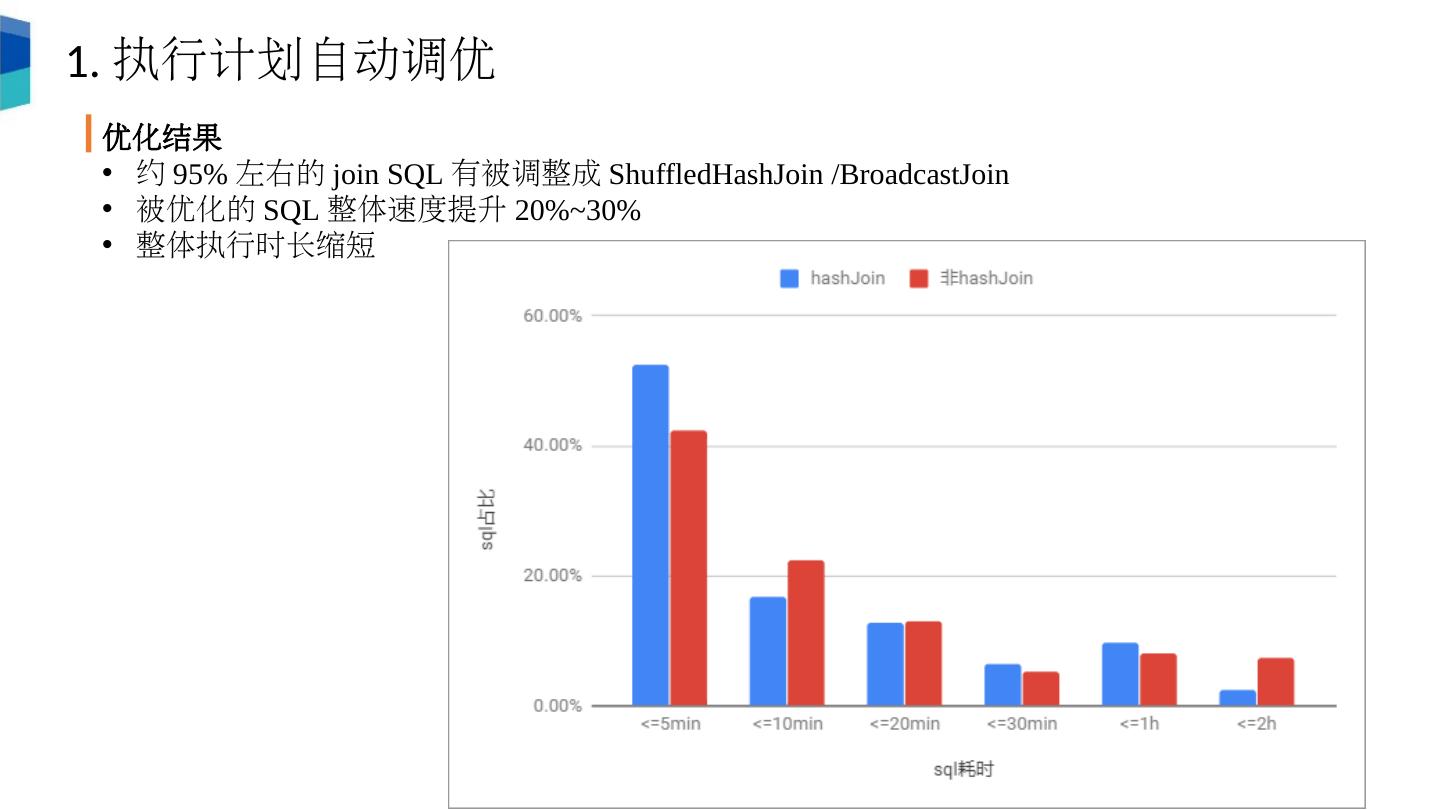
10 .1. 执行计划自动调优 优化结果 约 95% 左右的 join SQL 有被调整成 ShuffledHashJoin / BroadcastJoin 被优化的 SQL 整体速度提升 20%~30% 整体执行时长缩短
11 .Spark - SQL 引擎优化 基于 Parquet 数据读取剪枝 目标 : 以 parquet 格式数据为对象,在数据读取时进行适当的过滤剪枝,从而减少读取的数据量,加速查询速度 优化点: Local Sort, BoomFilter , & BitMap Prewhere
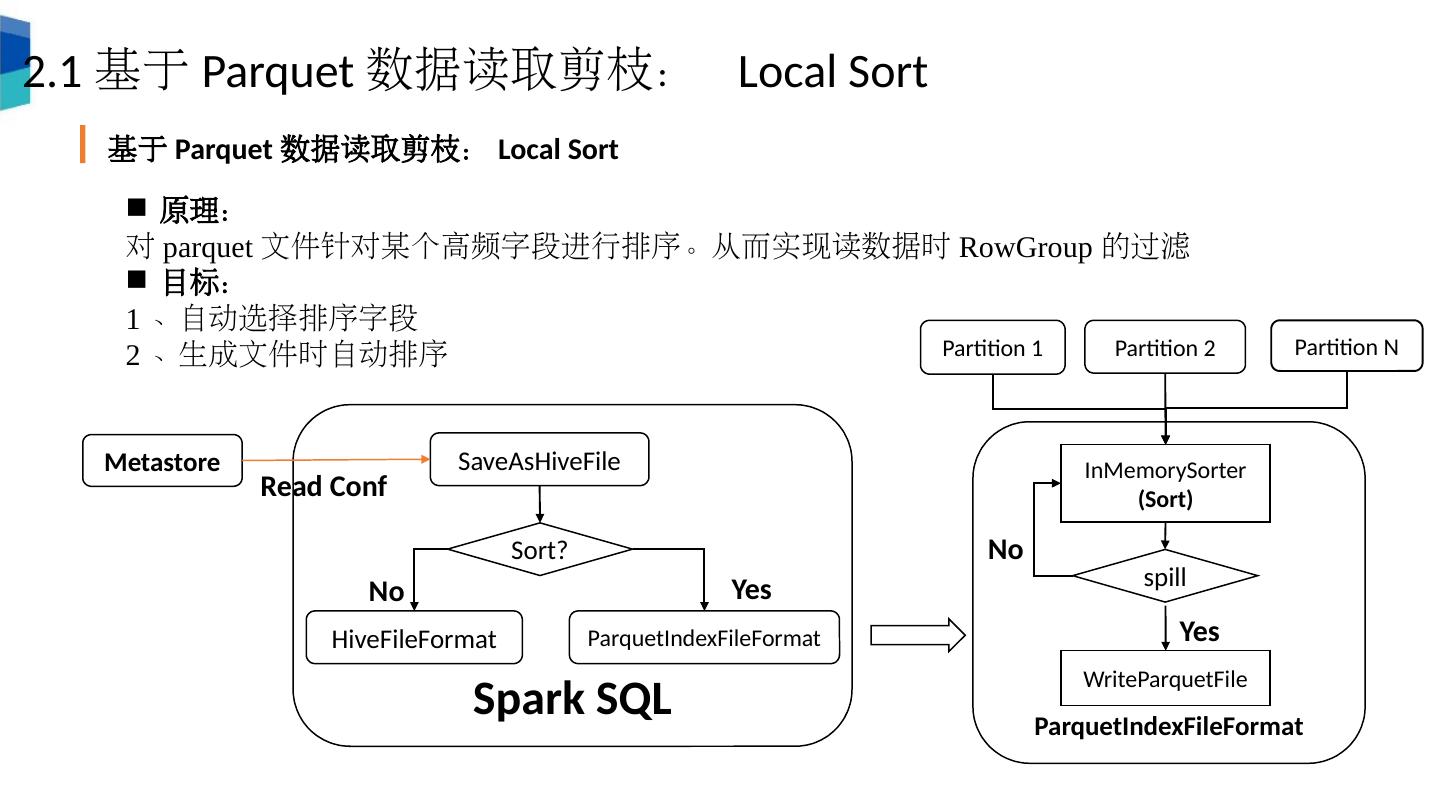
12 .2.1 基于 Parquet 数据读取剪枝: Local Sort 基于 Parquet 数据读取剪枝: Local Sort 原理: 对 parquet 文件针对某个高频字段进行排序。从而实现读数据时 RowGroup 的过滤 目标: 1 、自动选择排序字段 2 、生成文件时自动排序 Spark SQL SaveAsHiveFile Sort? HiveFileFormat ParquetIndexFileFormat ParquetIndexFileFormat Partition 1 Partition 2 Partition N InMemorySorter (Sort) spill WriteParquetFile Metastore Read Conf No Yes Yes No
13 .2.1 基于 Parquet 数据读取剪枝: Local Sort ParquetFile After Sort RowGroup0: Min - abc , Max - def RowGroup i : Min - opq , Max - uvw RowGroup n: Min -www , Max - xyz 优化结果: 平均性能提升 30% 生成时间:只增加 5% 目标文件格式:
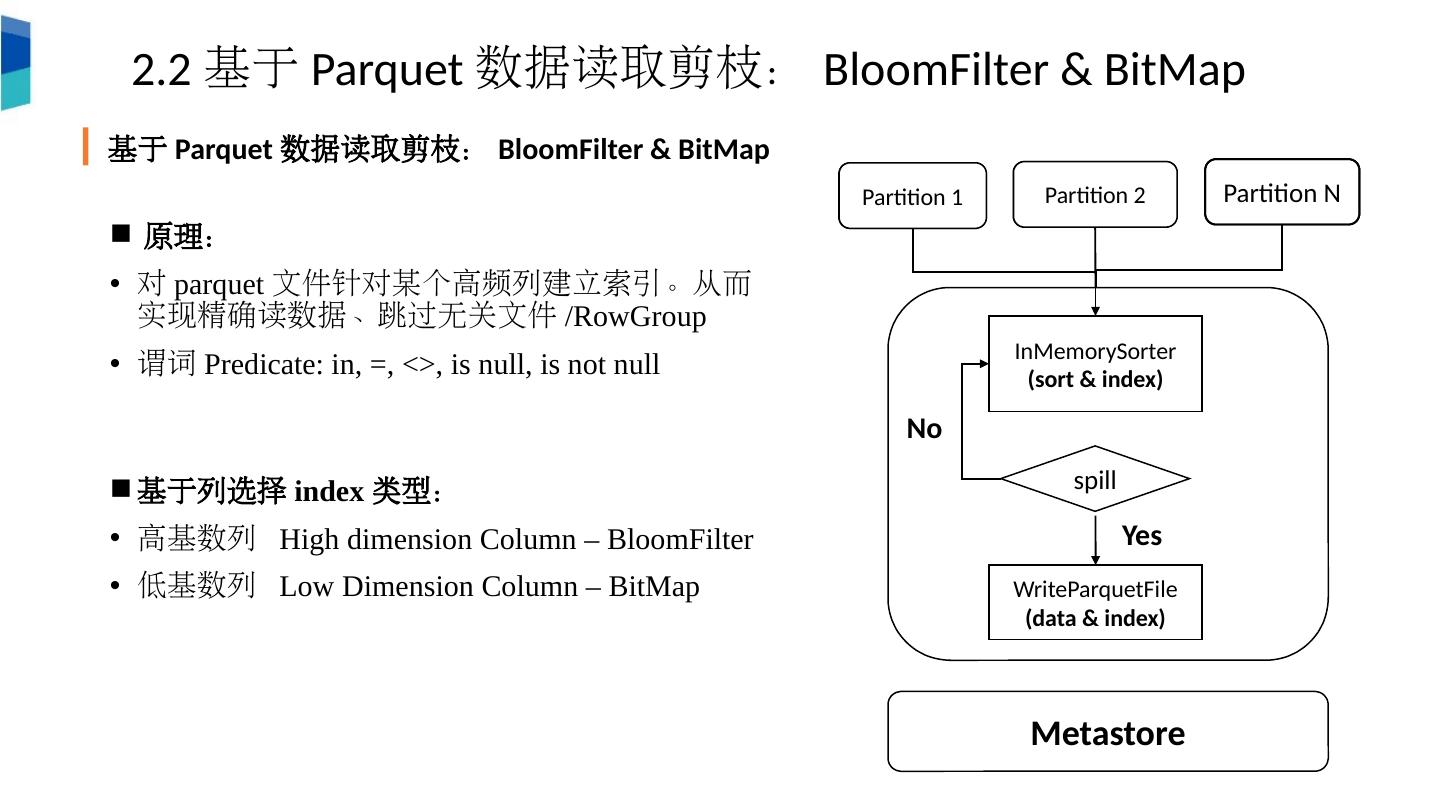
14 .原理: 对 parquet 文件针对某个高频列建立索引。从而实现精确读数据、跳过无关文件 / RowGroup 谓词 Predicate: i n, =, <>, is null, is not null 基于列选择 index 类型: 高基数列 High dimension Column – BloomFilter 低基数列 Low Dimension Column – BitMap Partition 1 Partition 2 Partition N InMemorySorter (sort & index) spill WriteParquetFile (data & index) Metastore Yes No Partition 1 Partition 2 2.2 基于 Parquet 数据读取剪枝: BloomFilter & BitMap 基于 Parquet 数据读取剪枝: BloomFilter & BitMap
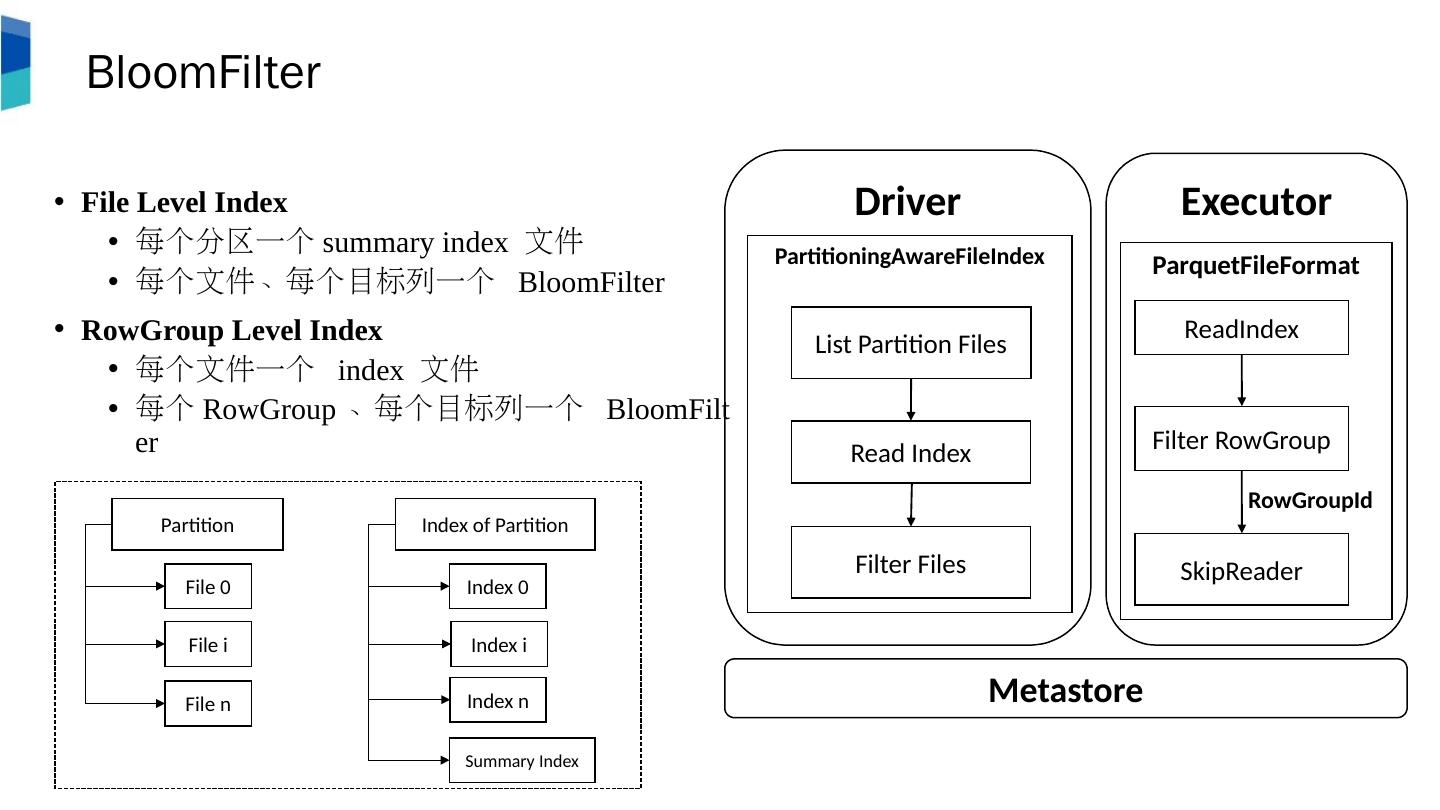
15 .Executor ParquetFileFormat Driver PartitioningAwareFileIndex BloomFilter File Level Index 每个分区一个 summary index 文件 每个文件、每个目标列一个 BloomFilter RowGroup Level Index 每个文件一个 index 文件 每个 RowGroup 、每个目标列一个 BloomFilter List Partition Files Read Index Filter Files ReadIndex Filter RowGroup SkipReader Metastore RowGroupId Partition File 0 File i File n Index of Partition Index 0 Index i Index n Summary Index
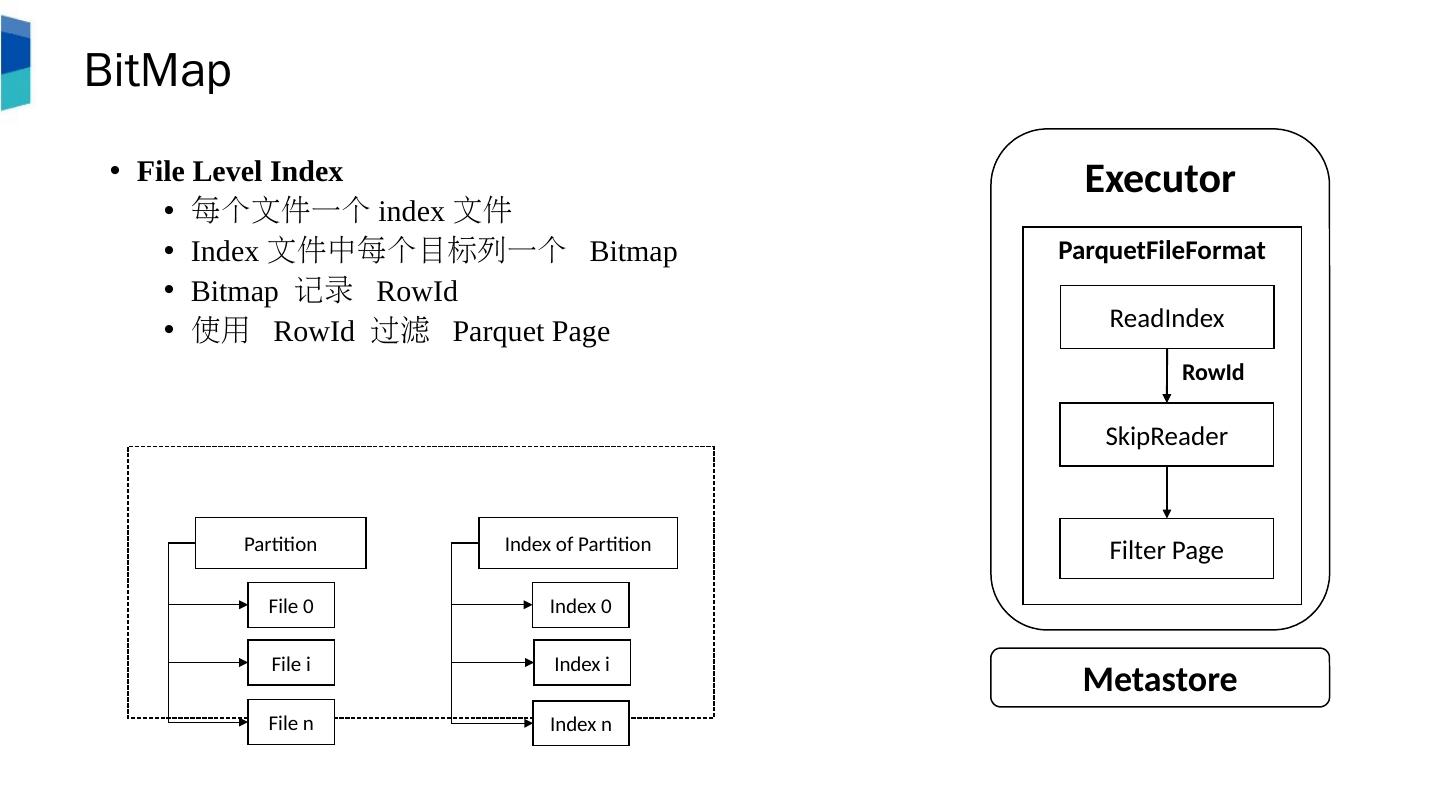
16 .BitMap File Level Index 每个文件一个 index 文件 Index 文件中每个目标列一个 Bitmap Bitmap 记录 R owId 使用 RowId 过滤 Parquet Page Executor ParquetFileFormat ReadIndex Filter Page SkipReader RowId Metastore Partition File 0 File i File n Index of Partition Index 0 Index i Index n
17 .BloomFilter & BitMap 优化结果: 命中索引平均性能提升 30% 生成时间增加: 10% 空间开销增加: 5% 问题: 1 、如何选择合适的列进行 Local_sort 以及构建 BloomFilter & BitMap ? 2 、如何实现自动生效?
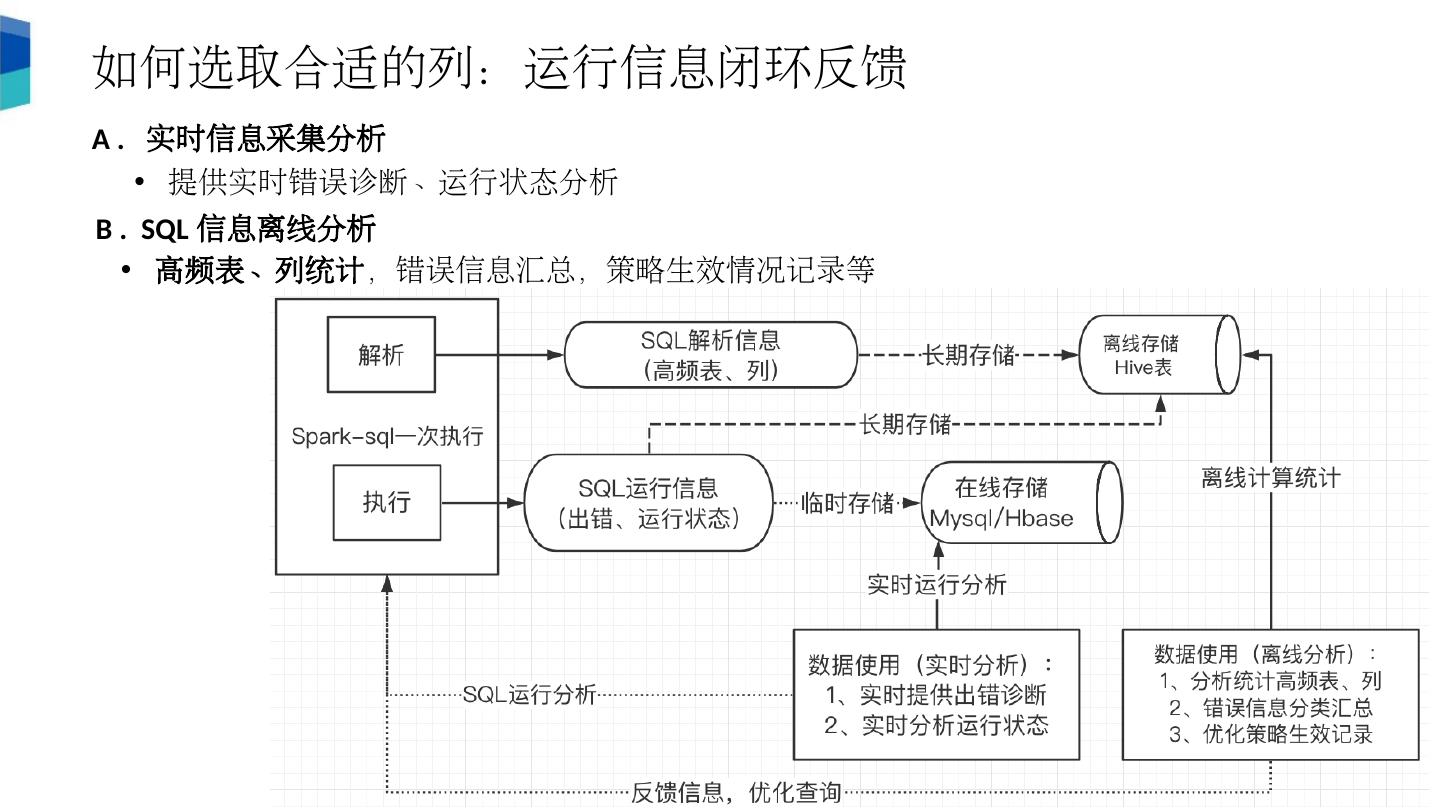
18 .如何选取合适的列 :运行信息闭环反馈 A . 实时信息采集分析 提供实时错误诊断、运行状态分析 B . SQL 信息离线分析 高频表、列统计 ,错误信息汇总,策略生效情况记录等
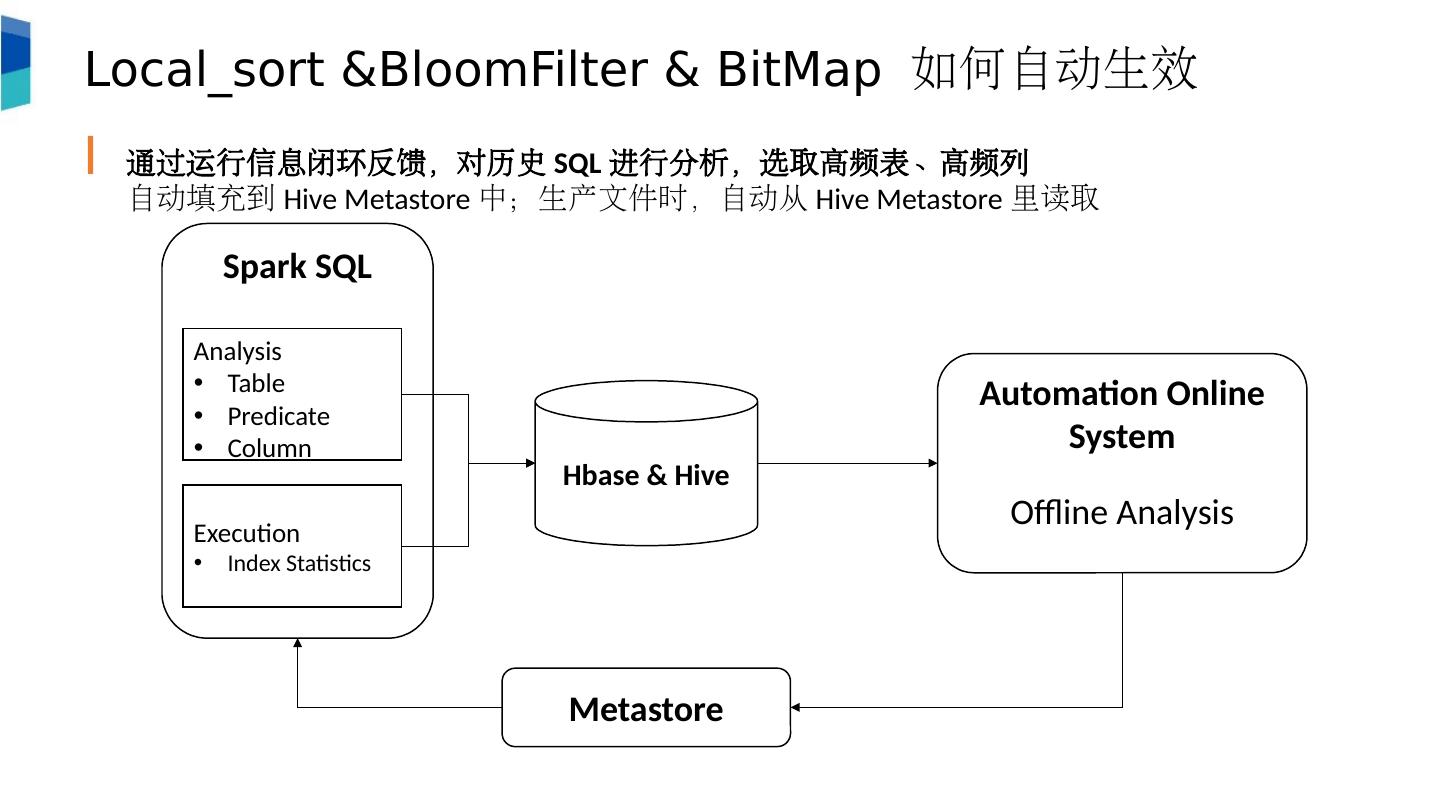
19 .Local_sort & BloomFilter & BitMap 如何自动生效 通过 运行信息闭环反馈 ,对历史 SQL 进行分析,选取高频表、高频列 自动填充到 Hive Metastore 中;生产文件时,自动从 Hive Metastore 里读取 Automation Online System Offline Analysis Spark SQL Analysis Table Predicate Column Execution Index Statistics Metastore Hbase & Hive
20 .原理: 基于列式存储各列分别存储、读取的特性 针对需要返回多列的 SQL ,先根据下推 条件对 R owId 进行过滤、选取。再有跳过地读取其他列,从而减少无关 IO 和后续计算 谓词选择(简单、计算量小) : i n, =, <>, is null, is not null 2.3 基于 Parquet 数据读取剪枝: Prewhere 基于 Parquet 数据读取剪枝: Prewhere 优化结果: 特定 SQL ( Project 16 列, where 条件 2 列) SQL 平均性能提升 20%
21 .3. 一些其它的优化 一些其他的优化 Hive/Spark Load 分区 Move 文件优化: 通过调整 staging 目录位置,实现在 Load 过程中 mv 文件夹,替代逐个 mv 文件,从而减少与 NameNode 的交互次数 Spark 生成文件合并 通过最后增加一个 repartition stage 合并 spark 生成文件。 Vcore 对于 CPU 使用率低的场景,通过 vcore 技术使得一个 yarn-core 可以启动多个 spark-core Spark 访问 hivemetastore 特定 filter 下推: 构造 get_partitions_by_filter 实现 cast 、 substring 等条件下推 hivemetastore ,从而减轻 metastore 返回数据量
22 .Spark - SQL 运行调优 目标: 在 SQL 执行前,通过统一的查询入口,对其进行 基于代价的预估 ,选择合适的引擎和参数 1. SQL 分析 抽取 Hive explain 逻辑,进行 SQL 语法正确性检查 对 SQL 包含的算子、输入的数据量进行标注 2. 自动引擎选择 / 自动参数优化 标注结果自动选择执行引擎 : 小 SQL 走 SparkServer (省去 yarn 申请资源耗时) 其他默认走 Spark-Submit 标注结果选择不同运行参数: Executor 个数 / 内存 Overhead 、堆外内存 效果 Adhoc 30s 以内 SQL 占比 45% Spark-Submit 内存使用量平均减少 20%
23 .未来的一些工作 全局字典 对特定列建立全局字典、从而减少 IO 、序列化开销 部分算子 C++ 实现 对部分 Spark 算子进行 C++ 改写,提升计算速度和内存管理 JOIN 数据倾斜 / 笛卡尔积 task 拆分 在 AE 的基础上,对某些数据倾斜 / 笛卡尔积(大量相同字段 join ) task 进行识别和拆分