










































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Analytics Zoo-Distributed Tensorflow, Keras and BigDL in product
Analytics Zoo: Distributed Tensorflow, Keras and BigDL in production on Apache Spark, Strata Data conference, March 2019, San Francisco
展开查看详情
1 .Analytics Zoo: Distributed Tensorflow, Keras and BigDL in production on Apache Spark Jennie Wang, Big Data Technologies, Intel Strata2019
2 . Agenda • Motivation • BigDL • Analytics Zoo • Real-world applications • Conclusion and Q&A Strata2019
3 . Motivations Technology and Industry Trends Real World Scenarios Strata2019
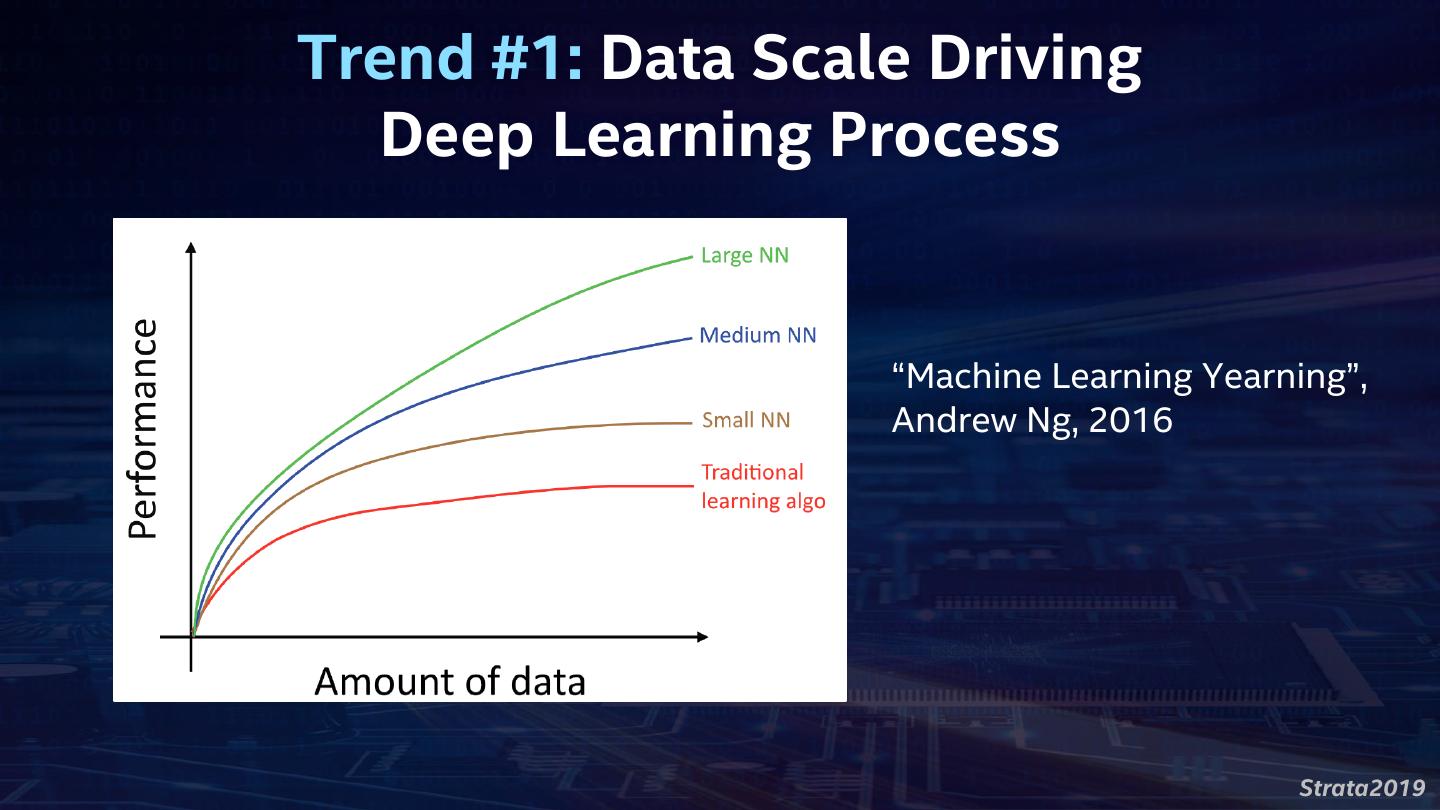
4 .Trend #1: Data Scale Driving Deep Learning Process “Machine Learning Yearning”, Andrew Ng, 2016 Strata2019
5 .Trend #2: Real-World ML/DL Systems Are Complex Big Data Analytics Pipelines “Hidden Technical Debt in Machine Learning Systems”, Sculley et al., Google, NIPS 2015 Paper Strata2019
6 . Trend #3: Hadoop Becoming the Center of Data Gravity Phillip Radley, BT Group Matthew Glickman, Goldman Sachs Strata + Hadoop World 2016 San Jose Spark Summit East 2015 Strata2019
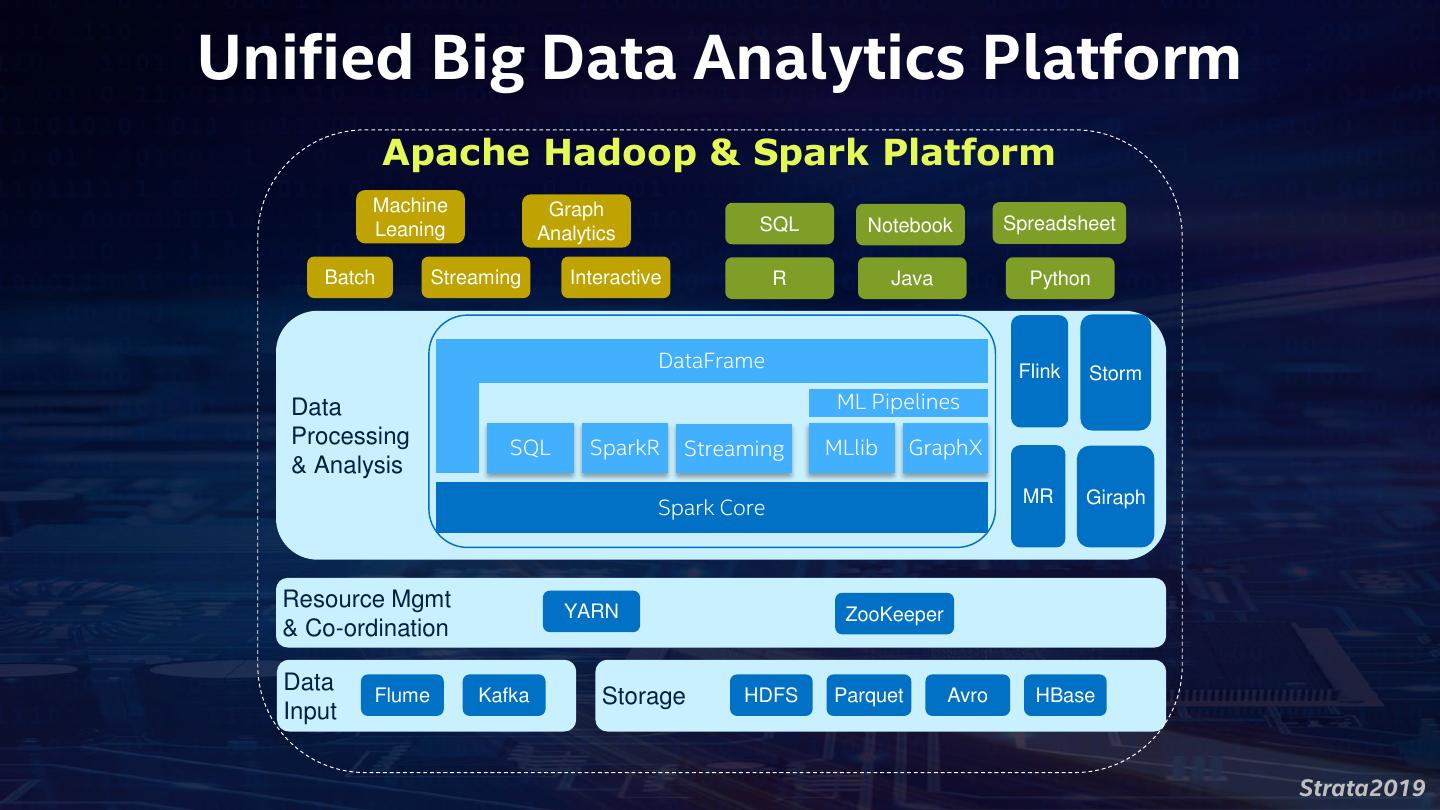
7 .Unified Big Data Analytics Platform Apache Hadoop & Spark Platform Machine Graph Leaning SQL Notebook Spreadsheet Analytics Batch Streaming Interactive R Java Python DataFrame Flink Storm Data ML Pipelines Processing SQL SparkR Streaming MLlib GraphX & Analysis MR Giraph Spark Core Resource Mgmt YARN ZooKeeper & Co-ordination Data Flume Kafka Storage HDFS Parquet Avro HBase Input Strata2019
8 . Chasm b/w Deep Learning and Big Data Communities The Chasm Deep learning experts Average users (big data users, data scientists, analysts, etc.) Strata2019
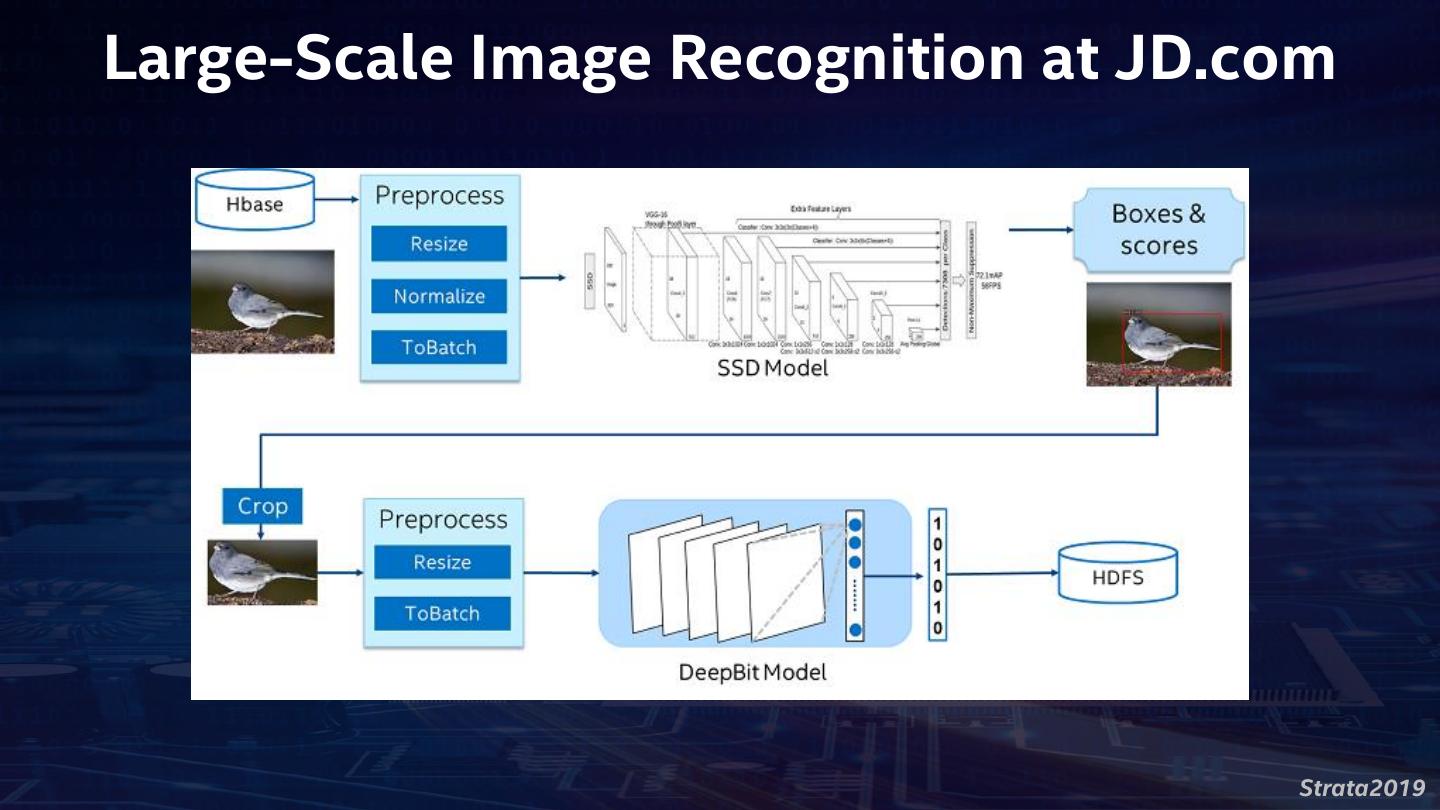
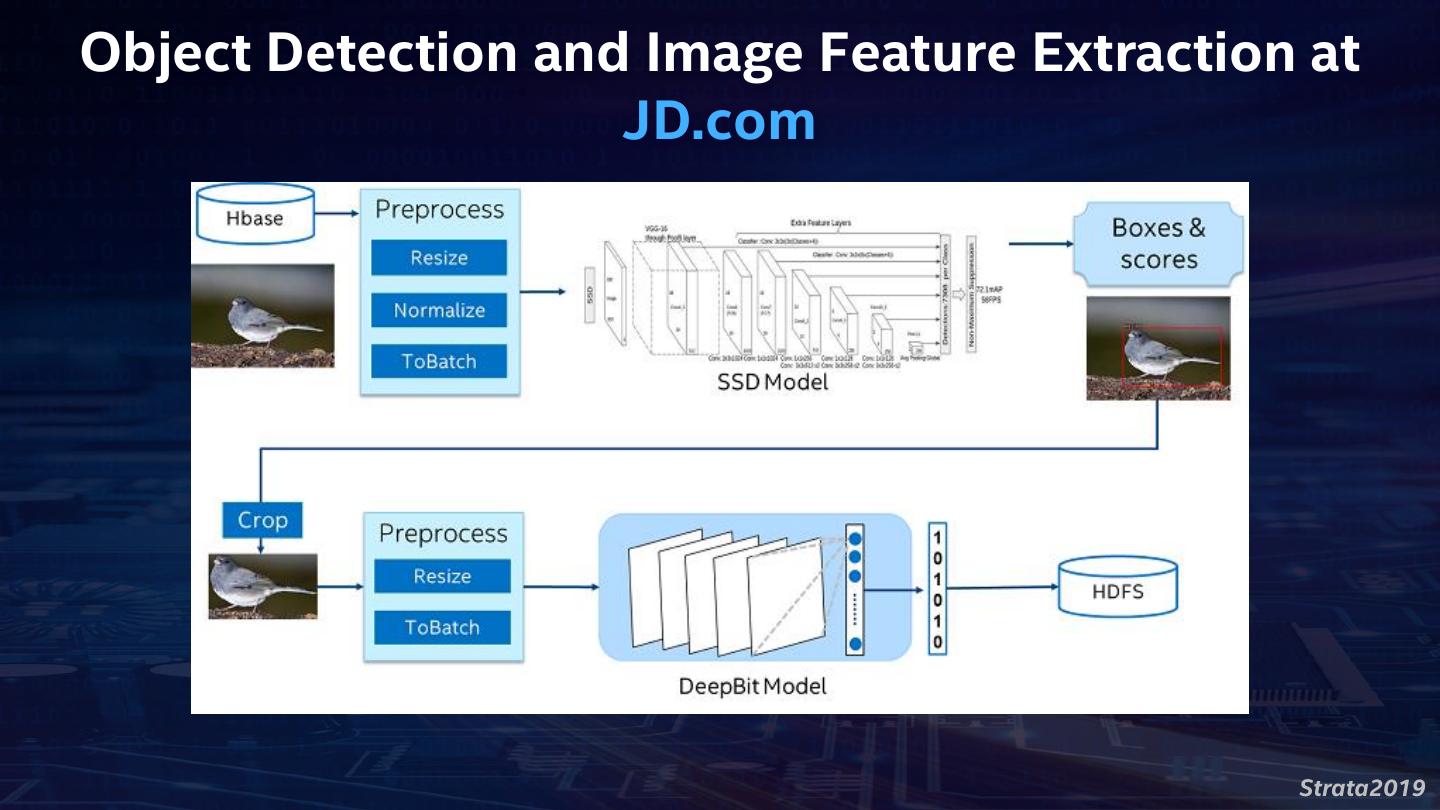
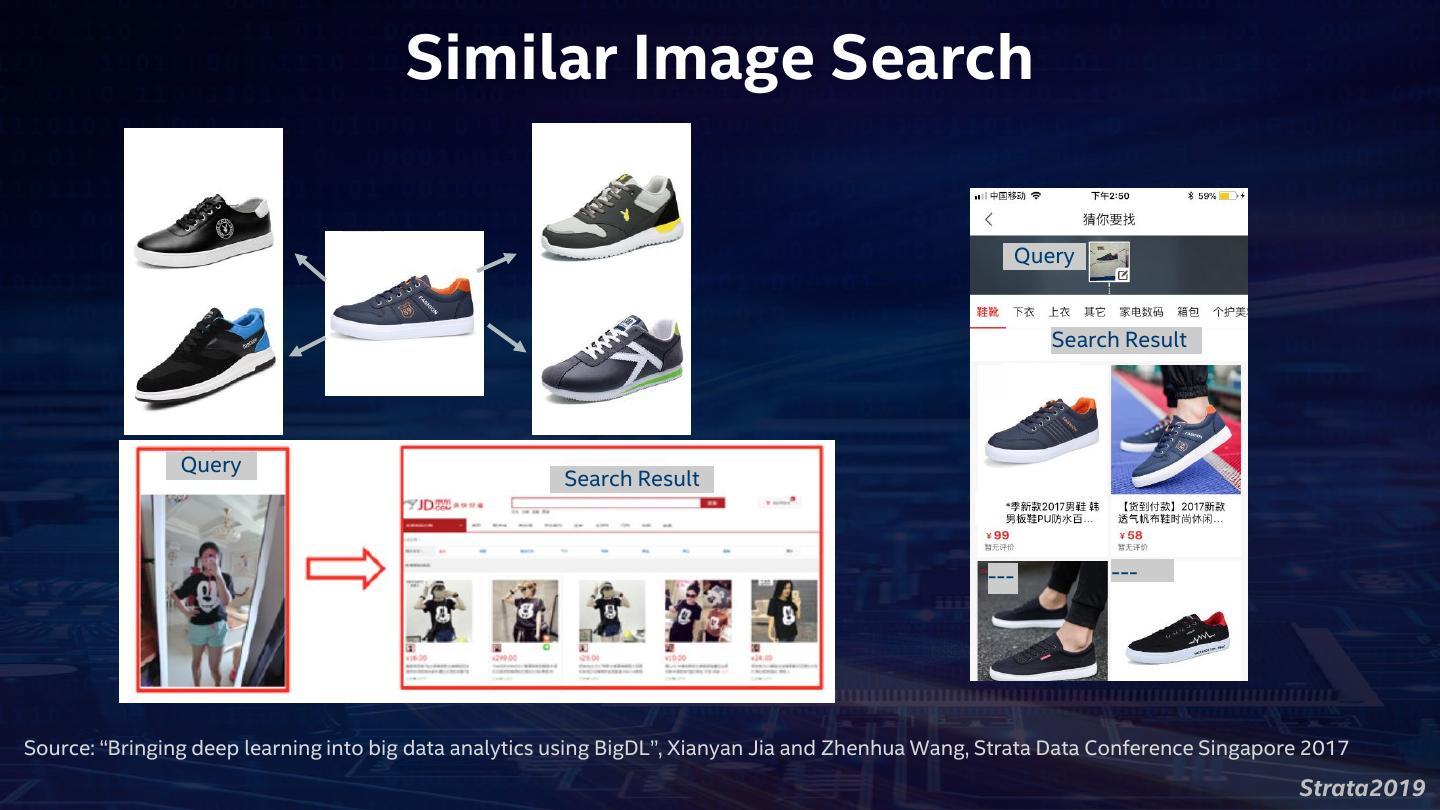
9 .Large-Scale Image Recognition at JD.com Strata2019
10 . Bridging the Chasm Make deep learning more accessible to big data and data science communities • Continue the use of familiar SW tools and HW infrastructure to build deep learning applications • Analyze “big data” using deep learning on the same Hadoop/Spark cluster where the data are stored • Add deep learning functionalities to large-scale big data programs and/or workflow • Leverage existing Hadoop/Spark clusters to run deep learning applications • Shared, monitored and managed with other workloads (e.g., ETL, data warehouse, feature engineering, traditional ML, graph analytics, etc.) in a dynamic and elastic fashion Strata2019
11 . BigDL Bringing Deep Learning To Big Data Platform • Distributed deep learning framework for Apache Spark* • Make deep learning more accessible to big data users DataFrame and data scientists • Write deep learning applications as standard Spark programs ML Pipeline • Run on existing Spark/Hadoop clusters (no changes needed) SQL SparkR Streaming MLlib GraphX • Feature parity with popular deep learning frameworks • E.g., Caffe, Torch, Tensorflow, etc. Spark Core • High performance (on CPU) • Powered by Intel MKL and multi-threaded programming https://github.com/intel-analytics/BigDL • Efficient scale-out https://bigdl-project.github.io/ • Leveraging Spark for distributed training & inference Strata2019
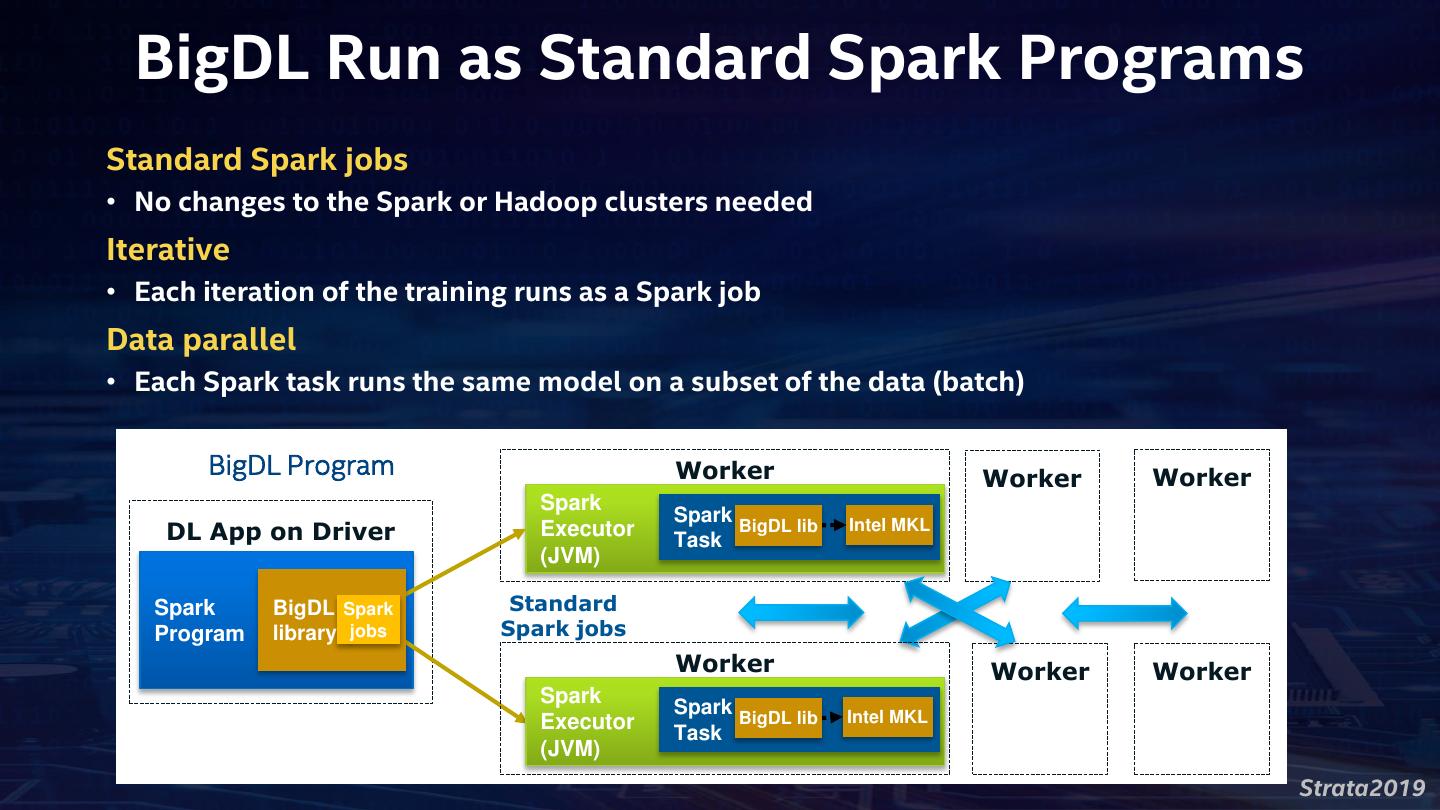
12 . BigDL Run as Standard Spark Programs Standard Spark jobs • No changes to the Spark or Hadoop clusters needed Iterative • Each iteration of the training runs as a Spark job Data parallel • Each Spark task runs the same model on a subset of the data (batch) BigDL Program Worker Worker Worker Spark Spark BigDL lib DL App on Driver Executor Task Intel MKL (JVM) Spark BigDL Spark Standard Program library jobs Spark jobs Worker Worker Worker Spark Spark BigDL lib Intel MKL Executor Task (JVM) Strata2019
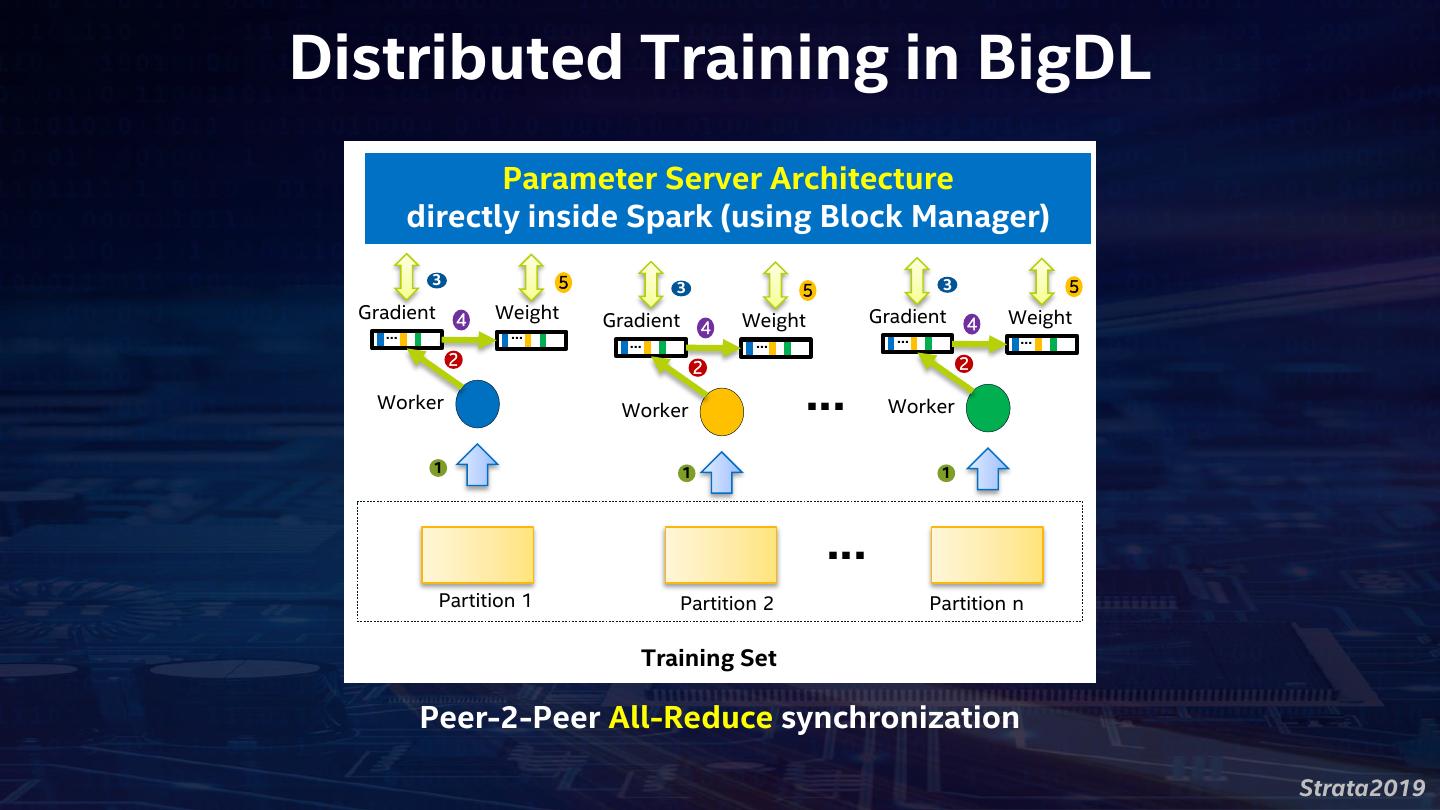
13 .Distributed Training in BigDL Parameter Server Architecture directly inside Spark (using Block Manager) 3 5 3 3 5 5 Gradient 4 Weight Gradient Weight Gradient Weight 4 4 … … … … … … 2 2 2 Worker Worker … Worker 1 1 1 … Partition 1 Partition 2 Partition n Training Set Peer-2-Peer All-Reduce synchronization Strata2019
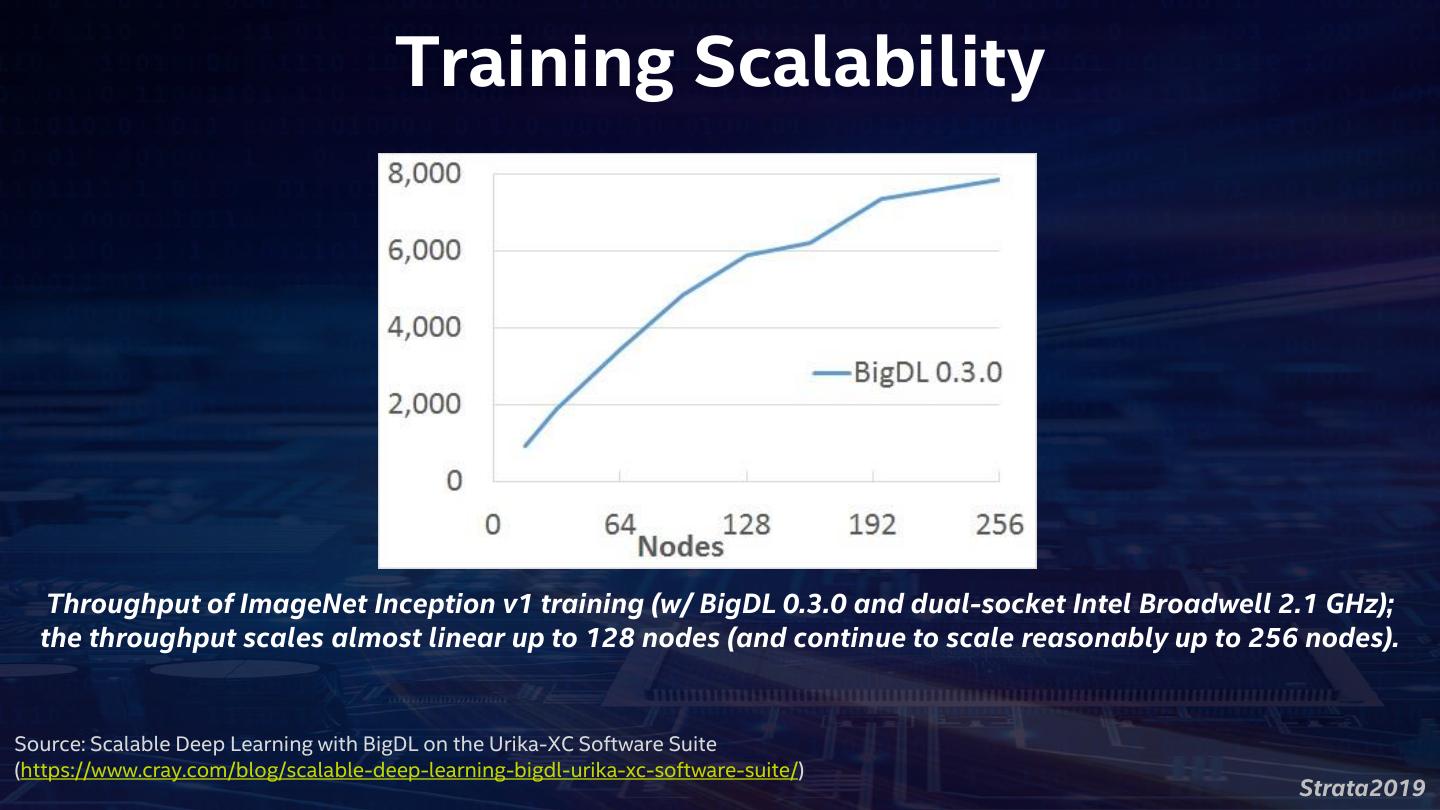
14 . Training Scalability Throughput of ImageNet Inception v1 training (w/ BigDL 0.3.0 and dual-socket Intel Broadwell 2.1 GHz); the throughput scales almost linear up to 128 nodes (and continue to scale reasonably up to 256 nodes). Source: Scalable Deep Learning with BigDL on the Urika-XC Software Suite (https://www.cray.com/blog/scalable-deep-learning-bigdl-urika-xc-software-suite/) Strata2019
15 . Analytics Zoo A unified analytics + AI platform for distributed TensorFlow, Keras and BigDL on Apache Spark https://github.com/intel-analytics/analytics-zoo Strata2019
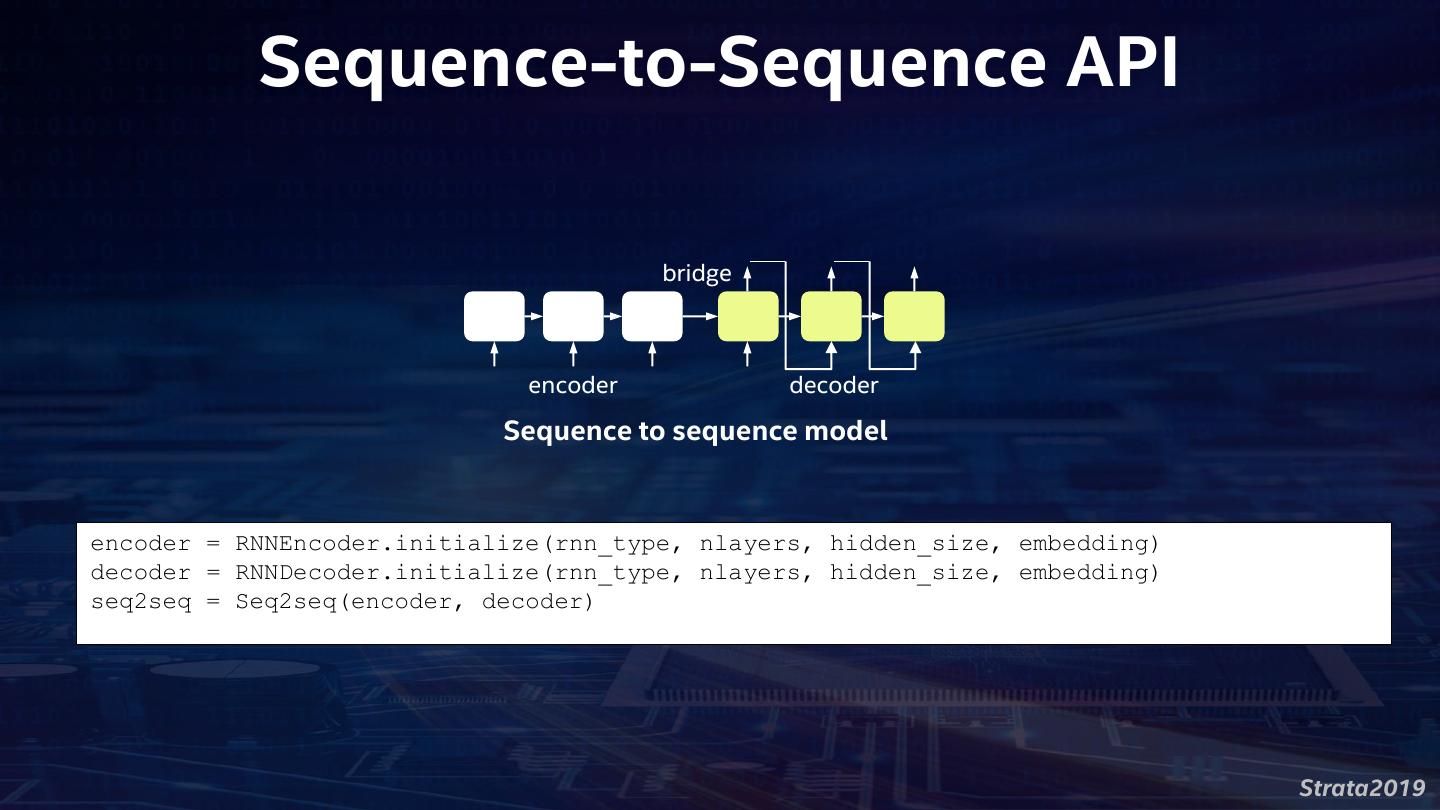
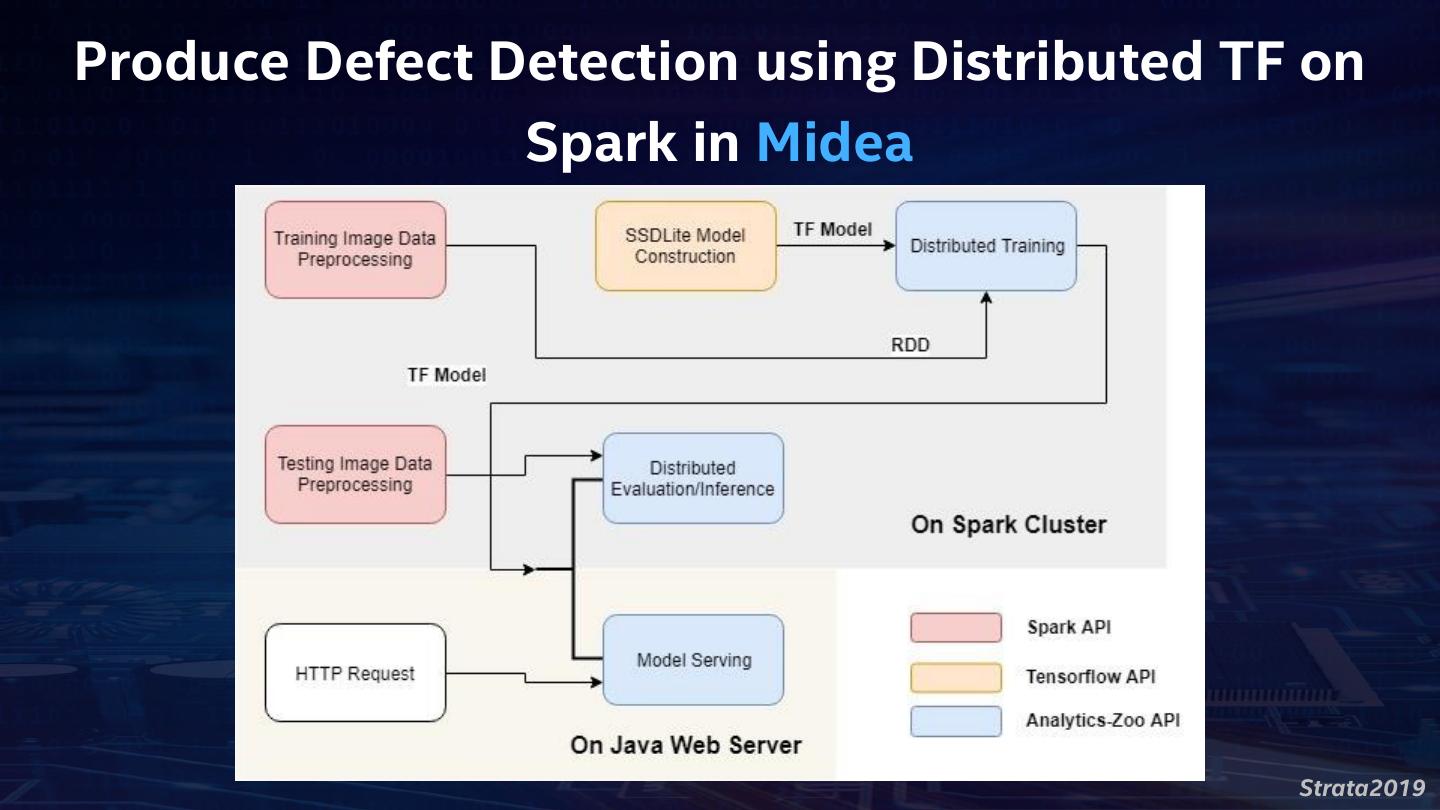
16 . Analytics Zoo Unified Analytics + AI Platform for Big Data Distributed TensorFlow, Keras and BigDL on Spark • Anomaly detection, sentiment analysis, fraud detection, image Reference Use Cases generation, chatbot, etc. Built-In Deep Learning • Image classification, object detection, text classification, text matching, Models recommendations, sequence-to-sequence, anomaly detection, etc. Feature transformations for Feature Engineering • Image, text, 3D imaging, time series, speech, etc. • Distributed TensorFlow and Keras on Spark High-Level Pipeline APIs • Native support for transfer learning, Spark DataFrame and ML Pipelines • Model serving API for model serving/inference pipelines Backbends Spark, TensorFlow, Keras, BigDL, OpenVINO, MKL-DNN, etc. https://github.com/intel-analytics/analytics-zoo/ https://analytics-zoo.github.io/ Strata2019
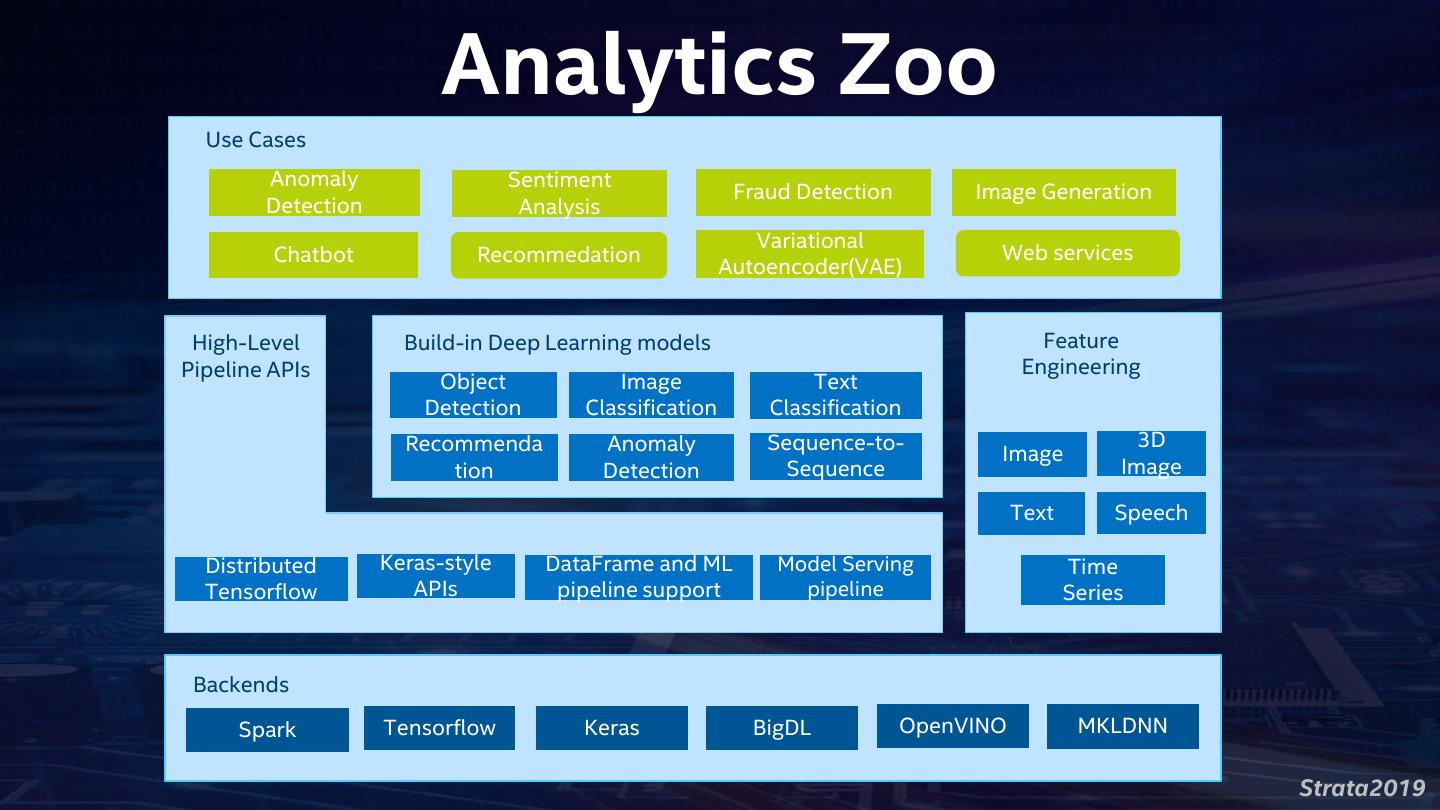
17 . Analytics Zoo Use Cases Anomaly Sentiment Fraud Detection Image Generation Detection Analysis Variational Chatbot Recommedation Web services Autoencoder(VAE) High-Level Build-in Deep Learning models Feature Pipeline APIs Engineering Object Image Text Detection Classification Classification Recommenda Anomaly Sequence-to- 3D Image tion Detection Sequence Image Text Speech Distributed Keras-style DataFrame and ML Model Serving Time Tensorflow APIs pipeline support pipeline Series Backends Spark Tensorflow Keras BigDL OpenVINO MKLDNN Strata2019
18 . Analytics Zoo Build end-to-end deep learning applications for big data • Distributed TensorFlow on Spark • Keras-style APIs (with autograd & transfer learning support) • nnframes: native DL support for Spark DataFrames and ML Pipelines • Built-in feature engineering operations for data preprocessing Productionize deep learning applications for big data at scale • Model serving APIs (w/ OpenVINO support) • Support Web Services, Spark, Storm, Flink, Kafka, etc. Out-of-the-box solutions • Built-in deep learning models and reference use cases Strata2019
19 . Analytics Zoo Build end-to-end deep learning applications for big data • Distributed TensorFlow on Spark • Keras-style APIs (with autograd & transfer learning support) • nnframes: native DL support for Spark DataFrames and ML Pipelines • Built-in feature engineering operations for data preprocessing Productionize deep learning applications for big data at scale • POJO model serving APIs (w/ OpenVINO support) • Support Web Services, Spark, Storm, Flink, Kafka, etc. Out-of-the-box solutions • Built-in deep learning models and reference use cases Strata2019
20 . Distributed TensorFlow on Spark in Analytics Zoo 1. Data wrangling and analysis using PySpark from zoo import init_nncontext from zoo.pipeline.api.net import TFDataset sc = init_nncontext() #Each record in the train_rdd consists of a list of NumPy ndrrays train_rdd = sc.parallelize(file_list) .map(lambda x: read_image_and_label(x)) .map(lambda image_label: decode_to_ndarrays(image_label)) #TFDataset represents a distributed set of elements, #in which each element contains one or more TensorFlow Tensor objects. dataset = TFDataset.from_rdd(train_rdd, names=["features", "labels"], shapes=[[28, 28, 1], [1]], types=[tf.float32, tf.int32], batch_size=BATCH_SIZE) Strata2019
21 . Distributed TensorFlow on Spark in Analytics Zoo 2. Deep learning model development using TensorFlow import tensorflow as tf slim = tf.contrib.slim images, labels = dataset.tensors labels = tf.squeeze(labels) with slim.arg_scope(lenet.lenet_arg_scope()): logits, end_points = lenet.lenet(images, num_classes=10, is_training=True) loss = tf.reduce_mean(tf.losses.sparse_softmax_cross_entropy(logits=logits, labels=labels)) Strata2019
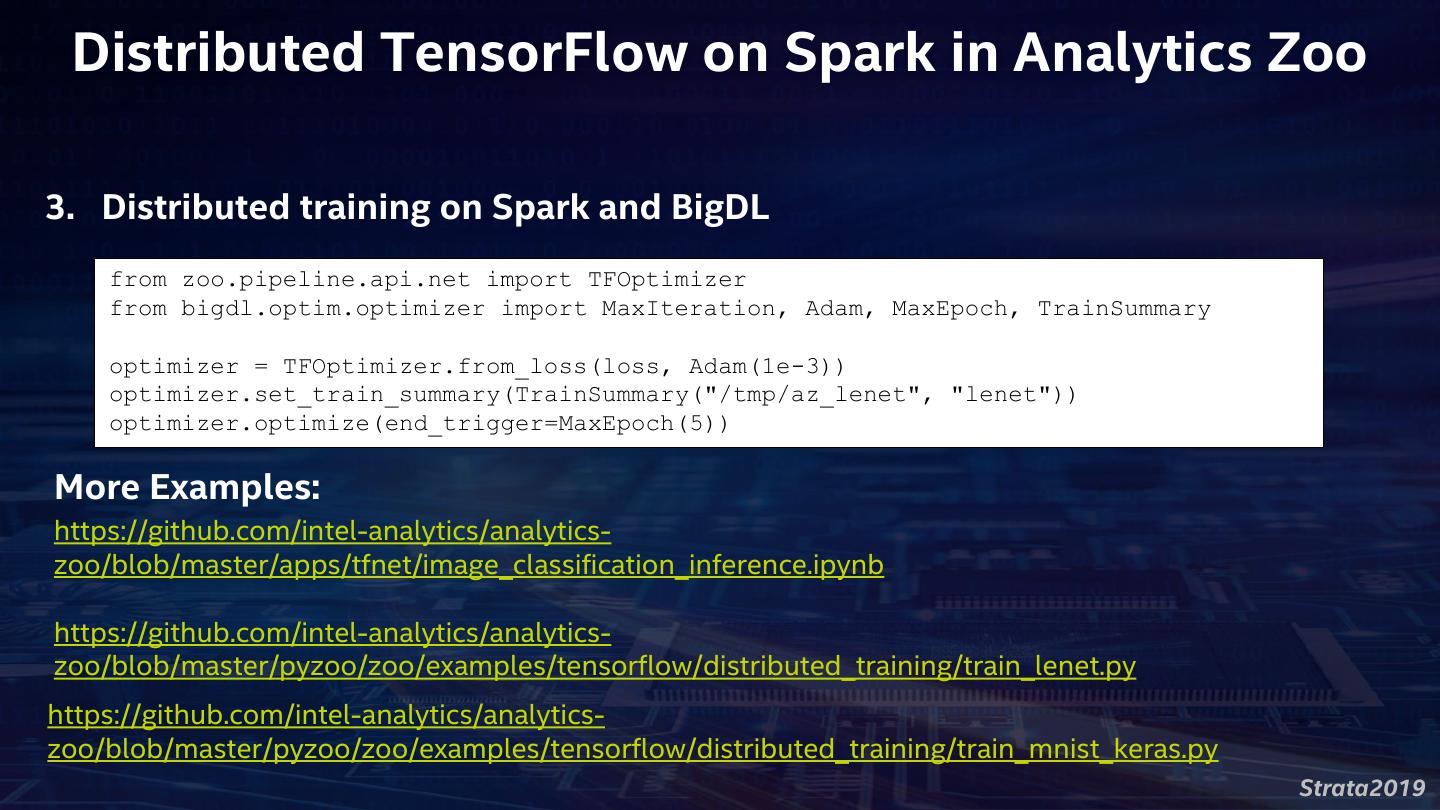
22 . Distributed TensorFlow on Spark in Analytics Zoo 3. Distributed training on Spark and BigDL from zoo.pipeline.api.net import TFOptimizer from bigdl.optim.optimizer import MaxIteration, Adam, MaxEpoch, TrainSummary optimizer = TFOptimizer.from_loss(loss, Adam(1e-3)) optimizer.set_train_summary(TrainSummary("/tmp/az_lenet", "lenet")) optimizer.optimize(end_trigger=MaxEpoch(5)) More Examples: https://github.com/intel-analytics/analytics- zoo/blob/master/apps/tfnet/image_classification_inference.ipynb https://github.com/intel-analytics/analytics- zoo/blob/master/pyzoo/zoo/examples/tensorflow/distributed_training/train_lenet.py https://github.com/intel-analytics/analytics- zoo/blob/master/pyzoo/zoo/examples/tensorflow/distributed_training/train_mnist_keras.py Strata2019
23 . Analytics Zoo Build end-to-end deep learning applications for big data • Distributed TensorFlow on Spark • Keras-style APIs (with autograd & transfer learning support) • nnframes: native DL support for Spark DataFrames and ML Pipelines • Built-in feature engineering operations for data preprocessing Productionize deep learning applications for big data at scale • POJO model serving APIs (w/ OpenVINO support) • Support Web Services, Spark, Storm, Flink, Kafka, etc. Out-of-the-box solutions • Built-in deep learning models and reference use cases Strata2019
24 . Keras, Autograd &Transfer Learning APIs 1. Use transfer learning APIs to • Load an existing Caffe model • Remove last few layers • Freeze first few layers • Append a few layers from zoo.pipeline.api.net import * full_model = Net.load_caffe(def_path, model_path) # Remove layers after pool5 model = full_model.new_graph(outputs=["pool5"]) # freeze layers from input to res4f inclusive model.freeze_up_to(["res4f"]) # append a few layers image = Input(name="input", shape=(3, 224, 224)) resnet = model.to_keras()(image) resnet50 = Flatten()(resnet) Build Siamese Network Using Transfer Learning Strata2019
25 . Keras, Autograd &Transfer Learning APIs 2. Use Keras-style and autograd APIs to build the Siamese Network import zoo.pipeline.api.autograd as A from zoo.pipeline.api.keras.layers import * from zoo.pipeline.api.keras.models import * input = Input(shape=[2, 3, 226, 226]) features = TimeDistributed(layer=resnet50)(input) f1 = features.index_select(1, 0) #image1 f2 = features.index_select(1, 1) #image2 diff = A.abs(f1 - f2) fc = Dense(1)(diff) output = Activation("sigmoid")(fc) model = Model(input, output) Build Siamese Network Using Transfer Learning Strata2019
26 . Analytics Zoo Build end-to-end deep learning applications for big data • Distributed TensorFlow on Spark • Keras-style APIs (with autograd & transfer learning support) • nnframes: native DL support for Spark DataFrames and ML Pipelines • Built-in feature engineering operations for data preprocessing Productionize deep learning applications for big data at scale • POJO model serving APIs (w/ OpenVINO support) • Support Web Services, Spark, Storm, Flink, Kafka, etc. Out-of-the-box solutions • Built-in deep learning models and reference use cases Strata2019
27 . nnframes Native DL support in Spark DataFrames and ML Pipelines 1. Initialize NNContext and load images into DataFrames using NNImageReader from zoo.common.nncontext import * from zoo.pipeline.nnframes import * sc = init_nncontext() imageDF = NNImageReader.readImages(image_path, sc) 2. Process loaded data using DataFrame transformations getName = udf(lambda row: ...) df = imageDF.withColumn("name", getName(col("image"))) 3. Processing image using built-in feature engineering operations from zoo.feature.image import * transformer = ChainedPreprocessing( [RowToImageFeature(), ImageChannelNormalize(123.0, 117.0, 104.0), ImageMatToTensor(), ImageFeatureToTensor()]) Strata2019
28 . nnframes Native DL support in Spark DataFrames and ML Pipelines 4. Define model using Keras-style API from zoo.pipeline.api.keras.layers import * from zoo.pipeline.api.keras.models import * model = Sequential() .add(Convolution2D(32, 3, 3, activation='relu', input_shape=(1, 28, 28))) \ .add(MaxPooling2D(pool_size=(2, 2))) \ .add(Flatten()).add(Dense(10, activation='softmax'))) 5. Train model using Spark ML Pipelines Estimater = NNEstimater(model, CrossEntropyCriterion(), transformer) \ .setLearningRate(0.003).setBatchSize(40).setMaxEpoch(1) \ .setFeaturesCol("image").setCachingSample(False) nnModel = estimater.fit(df) Strata2019
29 . Analytics Zoo Build end-to-end deep learning applications for big data • Distributed TensorFlow on Spark • Keras-style APIs (with autograd & transfer learning support) • nnframes: native DL support for Spark DataFrames and ML Pipelines • Built-in feature engineering operations for data preprocessing Productionize deep learning applications for big data at scale • POJO model serving APIs (w/ OpenVINO support) • Support Web Services, Spark, Storm, Flink, Kafka, etc. Out-of-the-box solutions • Built-in deep learning models and reference use cases Strata2019
3秒后跳转登录页面
去登陆

