






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
TDengine 专为物联网而生的大数据平台
来自涛思数据的工程师关胜亮,作的题为“TDengine专为物联网大数据设计的分布式存储处理引擎”的报告。TDengine是一个开源的专为物联网、车联网、工业互联网、IT运维等设计和优化的大数据平台。
展开查看详情
1 .TDengine 专为物联网而生的大数据平台
2 . 大数据时代 数据采集后被源源不断的发往云端
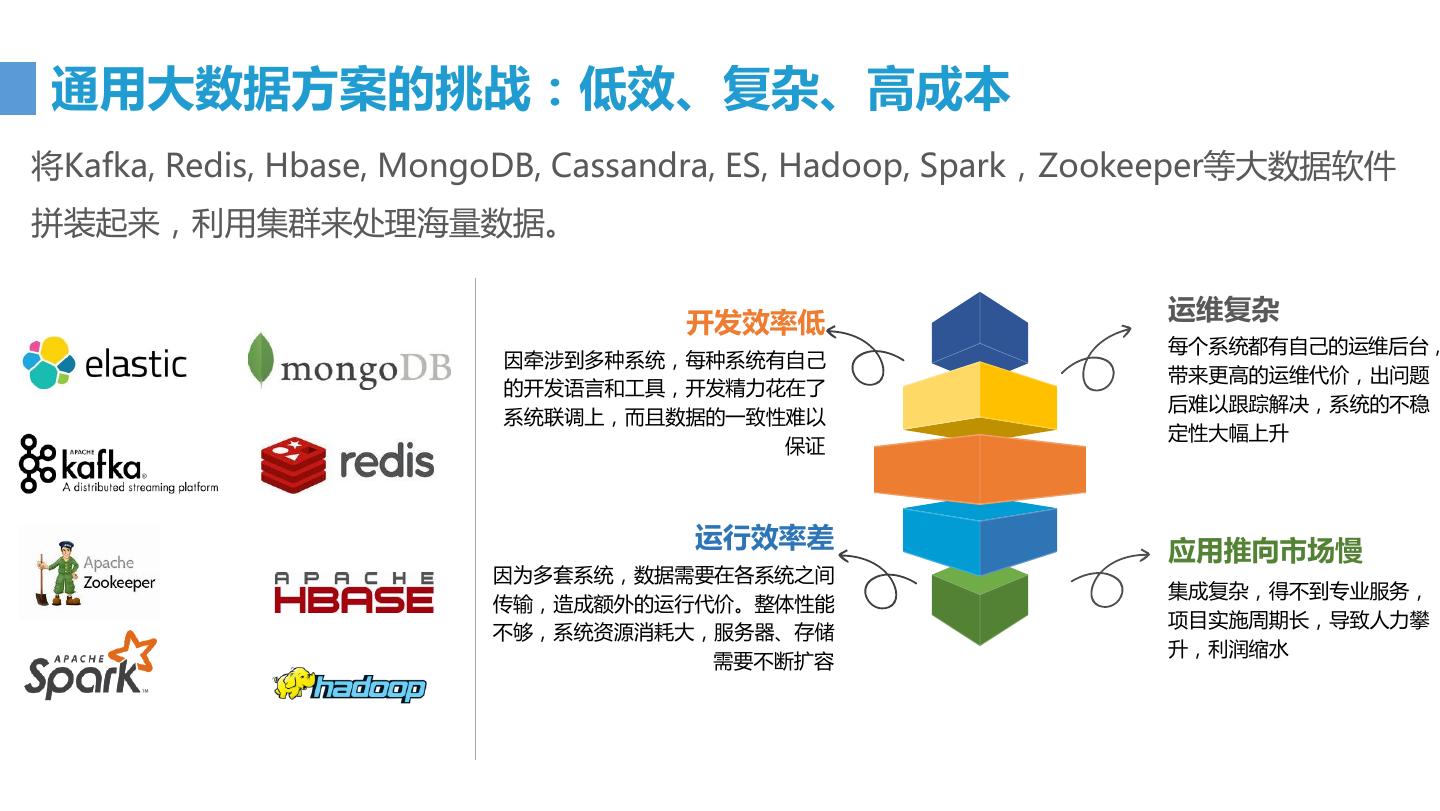
3 . 通用大数据方案的挑战:低效、复杂、高成本 将Kafka, Redis, Hbase, MongoDB, Cassandra, ES, Hadoop, Spark,Zookeeper等大数据软件 拼装起来,利用集群来处理海量数据。 开发效率低 运维复杂 每个系统都有自己的运维后台, 因牵涉到多种系统,每种系统有自己 带来更高的运维代价,出问题 的开发语言和工具,开发精力花在了 后难以跟踪解决,系统的不稳 系统联调上,而且数据的一致性难以 定性大幅上升 保证 运行效率差 应用推向市场慢 因为多套系统,数据需要在各系统之间 集成复杂,得不到专业服务, 传输,造成额外的运行代价。整体性能 项目实施周期长,导致人力攀 不够,系统资源消耗大,服务器、存储 升,利润缩水 需要不断扩容
4 .物联网大数据特点 1 所有采集的数据都是时序 6 数据以写操作优先 2 数据都是结构化 7 数据流量平稳,可以较为准确的计算 3 数据很少有更新或删除操作 8 数据都有统计、聚合等实时计算操作 4 数据一般是按到期日期来删除 9 数据量巨大,一天的数据量就超过100亿条 5 一个采集点的数据源是唯一 10 数据一定是指定时间段和指定区域查找的
5 .TDengine 技术介绍
6 .TDengine 技术亮点 快10倍的插入和查询 超融合 通过创新性地存储设计,并采用无锁设计和多 将大数据处理需要的消息队列、缓存、数据库、流式 核技术,让数据插入和查询的速度比现有专业 计算、订阅等功能融合在一起,提升运行效率,保证 的时序数据库提高了10倍以上 整个系统的数据一致性 更高的水平扩展能力 极低的资源消耗 通过先进的集群设计,保证了系统处理能力的 整个完整安装包才1.2M,内存的最低要求不到1M,计 水平扩展,而且让数据库不再依赖昂贵的硬件 算资源不到通用方案的1/5。通过列式存储和先进的压 和存储设备,不存在任何单点瓶颈和故障 缩算法,存储空间不到传统数据库的1/10。 零学习成本 零运维管理成本 操作管理与MySQL完全一致。向用户和DBA 追求极致的用户体验,将复杂的运维工作完全智能化。 提供标准SQL语法。开发接口包括MySQL- 分库分表、数据备份、数据恢复完全自动;扩容、升 like的API,标准化的工业接口包括JDBC(兼 级、IDC机房迁移轻松完成 容3.x及以上), ODBC (3.x), REST接口,不论 是管理还是开发的学习成本几乎为零
7 .TDengine 应用领域 军工 行业 石油 电力 行业 石化 通讯 公共 金融 行业 安全 行业 环境 制造业 监测 交通 物联网 物流 行业 出行 行业 工具 互联网
8 .TDengine 生态 Telegraf Grafana Visualization Tool Kafka TDengine Python/Matlab/R OPC Analytics, ML Applications Data Hub Time-series Data Processing Engine MQTT Server IoT Application Java/C/C++/Restful Clustered Shell: Web Based Command Management Tool Line Interface
9 .TDengine 产品应用实例
10 .TDengine 应用领域 上网记录、通话记录 话费详单、用户行为、 个体追踪、区间筛选 基站/通讯设备监测 交易记录、存取记录 智能电表、电网 ATM、POS机监测 发电设备集中监测 火车/汽车/出租/飞机 实时路况、卡口数据 自行车的实时监测 路口流量监测 油井、运输管线 服务器/应用监测 运输车队的实时监测 用户访问日志、广告点击日志
11 .TDengine 技术特征及优势
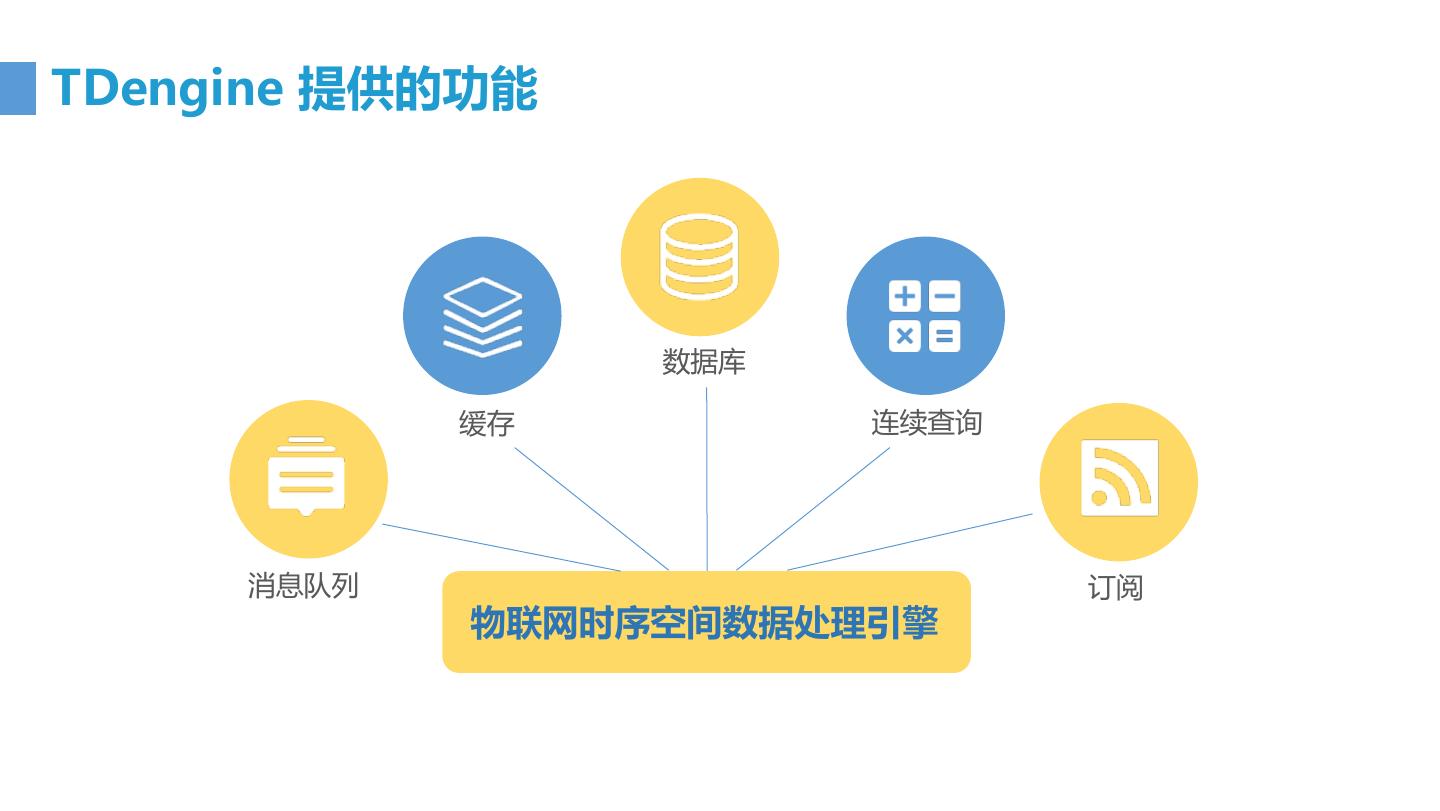
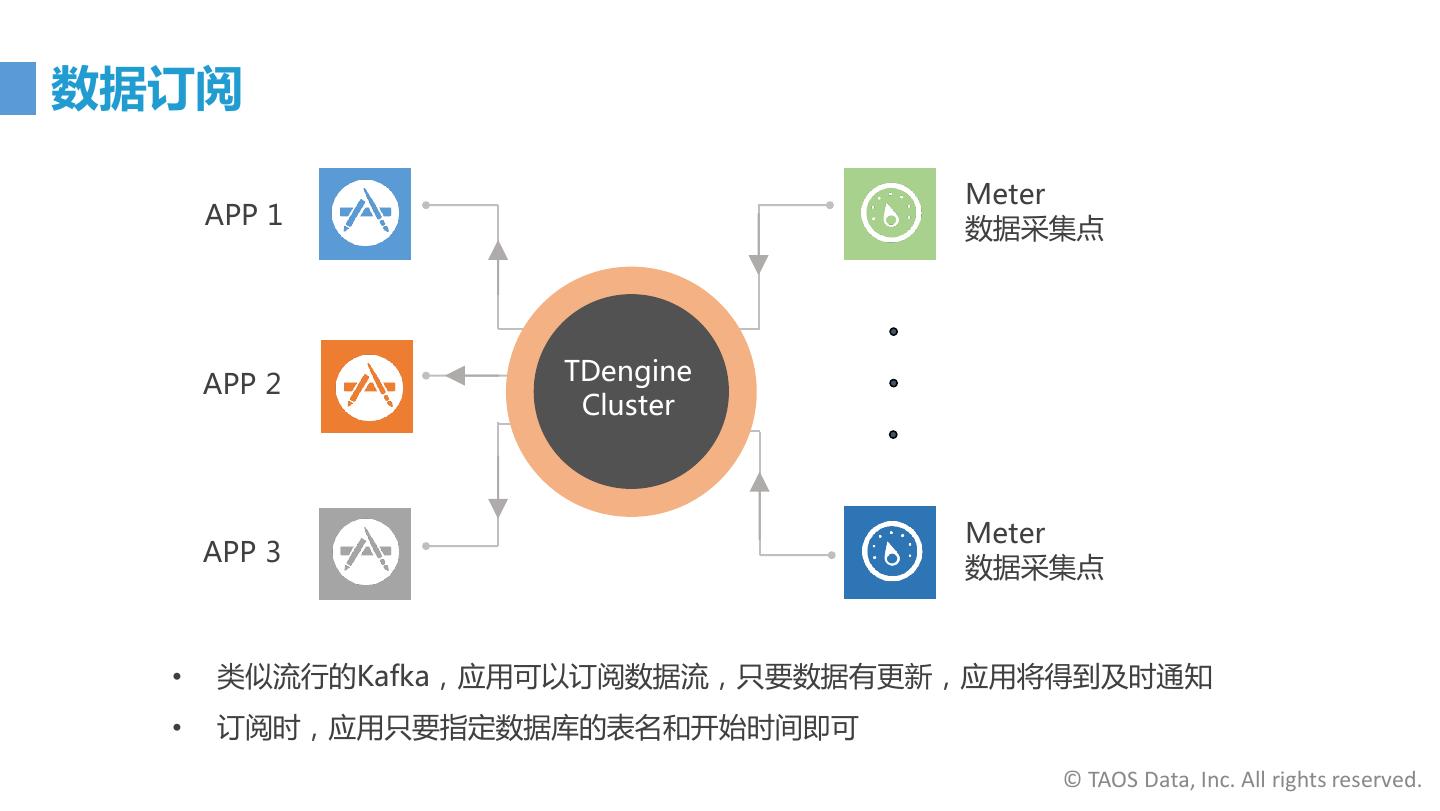
12 .TDengine 提供的功能 数据库 缓存 连续查询 消息队列 订阅 物联网时序空间数据处理引擎
13 .超过10倍性能优势 通过创新性地存储设计,并采用无锁设计和多核技术,让数据插入和查 询的速度比现有专业的时序数据库提高10倍以上
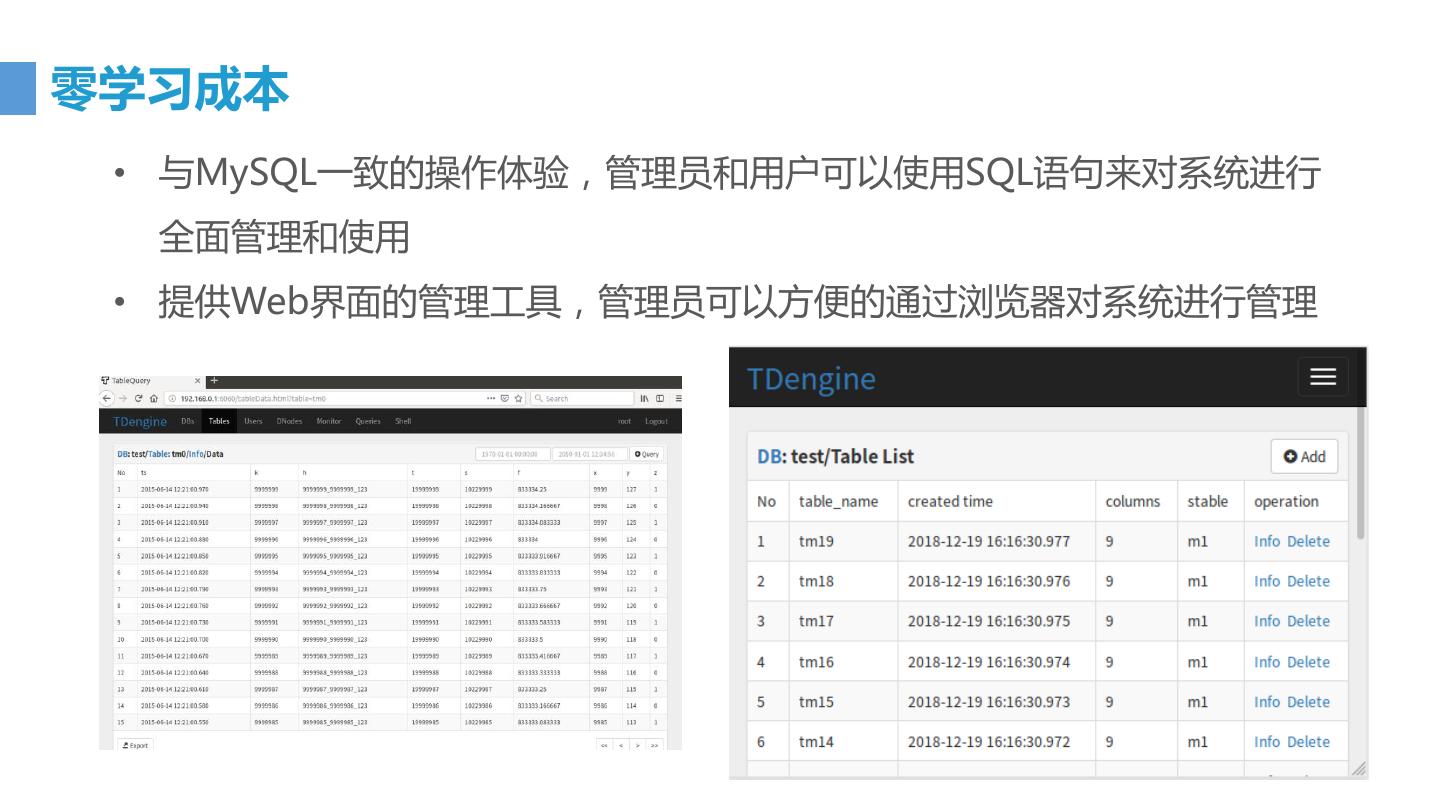
14 .零学习成本 • 与MySQL一致的操作体验,管理员和用户可以使用SQL语句来对系统进行 全面管理和使用 • 提供Web界面的管理工具,管理员可以方便的通过浏览器对系统进行管理
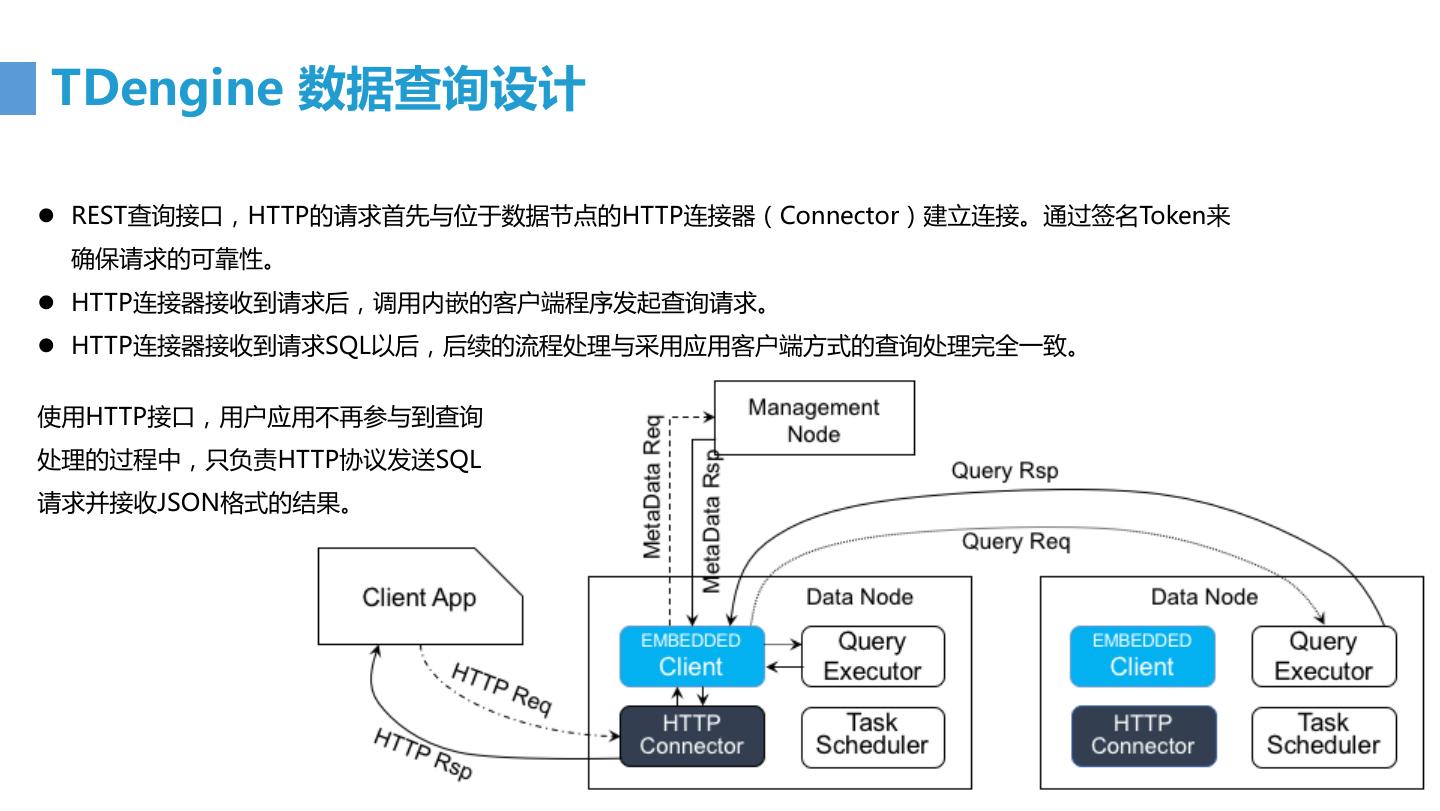
15 .便捷的开发支持 标准化的工业开发接口规范: 1. 支持JDBC 3.0及以上版本 2. 支持ODBC 3.x版本 支持多种开发语言: C/C++ Java Python C# JavaScript Go.. 支持Http的REST服务接口,可采用服务调用的方式使用数据库服务,数据库 提供采用HTTP方式使用的REST服务,用户可以使用任何熟悉的语言(Go、 Ruby、Perl)来调用REST接口进行业务应用开发 支持SprintBoot开发框架及默认连接池HikariCP。
16 .TDengine 技术介绍
17 .TDengine的设计理念 单个计算节点能够处理任意单个设备产生的数据,同一 个设备的数据具有内生关联性 物联网按照时序生成,绝大部分数据是顺序到达,乱序 数据比例非常少 物联网数据基本没有修改和更新需求
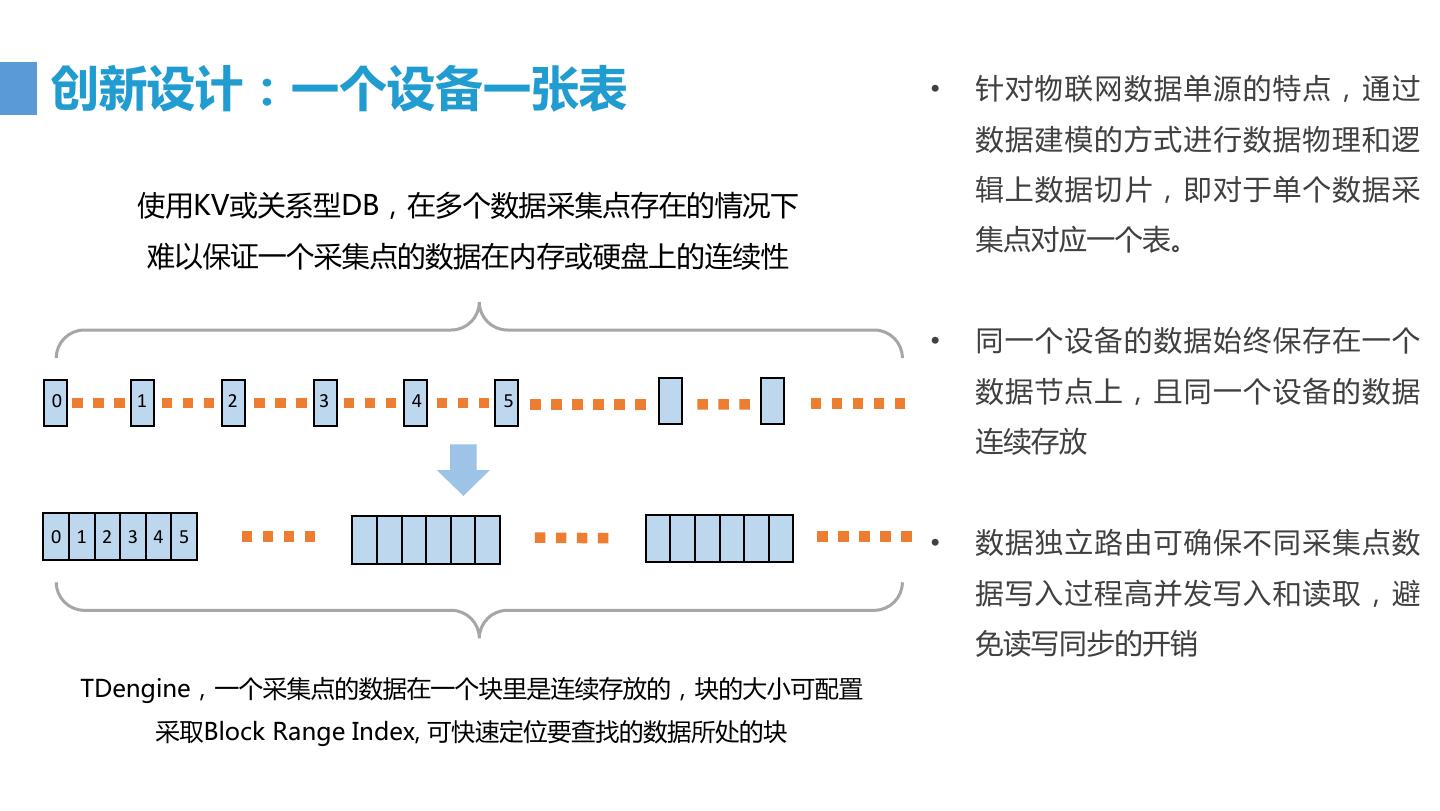
18 .创新设计:一个设备一张表 • 针对物联网数据单源的特点,通过 数据建模的方式进行数据物理和逻 辑上数据切片,即对于单个数据采 使用KV或关系型DB,在多个数据采集点存在的情况下 集点对应一个表。 难以保证一个采集点的数据在内存或硬盘上的连续性 • 同一个设备的数据始终保存在一个 0 1 2 3 4 5 数据节点上,且同一个设备的数据 连续存放 0 1 2 3 4 5 • 数据独立路由可确保不同采集点数 据写入过程高并发写入和读取,避 免读写同步的开销 TDengine,一个采集点的数据在一个块里是连续存放的,块的大小可配置 采取Block Range Index, 可快速定位要查找的数据所处的块
19 .数据模型及超级表 记录的标签(TAGS)在设备(表)级别,不同于传统时序库将标签记录在记录级别。 由于关联到表级别,将标签的总数极大地降低。将标签与数据分离管理,所有的标签信 息在管理节点进行管理,而数据是存储在数据节点。 TDengine引入超级表概念,与表一样,需要定义Schema, 但应用还可以定义多个标签。 具体创建表时,可以指定使用哪个超级表,并且指定标签的值。同一类型的数据监测点 属于同一个超级表, 一个超级表可以包含任意数量的表或监测点。 应用可以像查询表一样查询超级表, 但可以通过标签过滤条件查询部分或全部数据采集 点的记录,并且可以做各种聚合、计算等,方便支持复杂查询,应对业务需求。
20 .TDengine 单个采集点数据插入、查询示例 与传统关系型数据库一样,采用SQL语法,应用需先创建库,然后建表,就可以插入、查询 create database demo; use demo; create table t1 (ts timestamp, degree float); insert into t1 values(now, 28.5); select * from t1; 上述SQL 为一个温度传感器创建一张表,并插入一条记录、然后查询
21 .TDengine 超级表实例 为温度传感器建立一个STable, 有两个标签:位置和类型 create table thermometer (ts timestamp, degree float) tags(loc binary(20), type int); 用STable创建4张表, 对应4个温度传感器,地理位置标签为北京、天津、上海等 create table t1 using thermometer tags(‘beijing’, 1); create table t2 using thermometer tags(‘beijing’, 2); create table t3 using thermometer tags(‘tianjin’, 1); create table t4 using thermometer tags(‘tianjin’, 2); create table t5 using thermometer tags(‘shanghai’,1); 查询北京和天津所有温度传感器记录的最高值和最小值 select max(degree), min(degree) from thermometer where loc=‘beijing’ or loc=‘tianjin’;
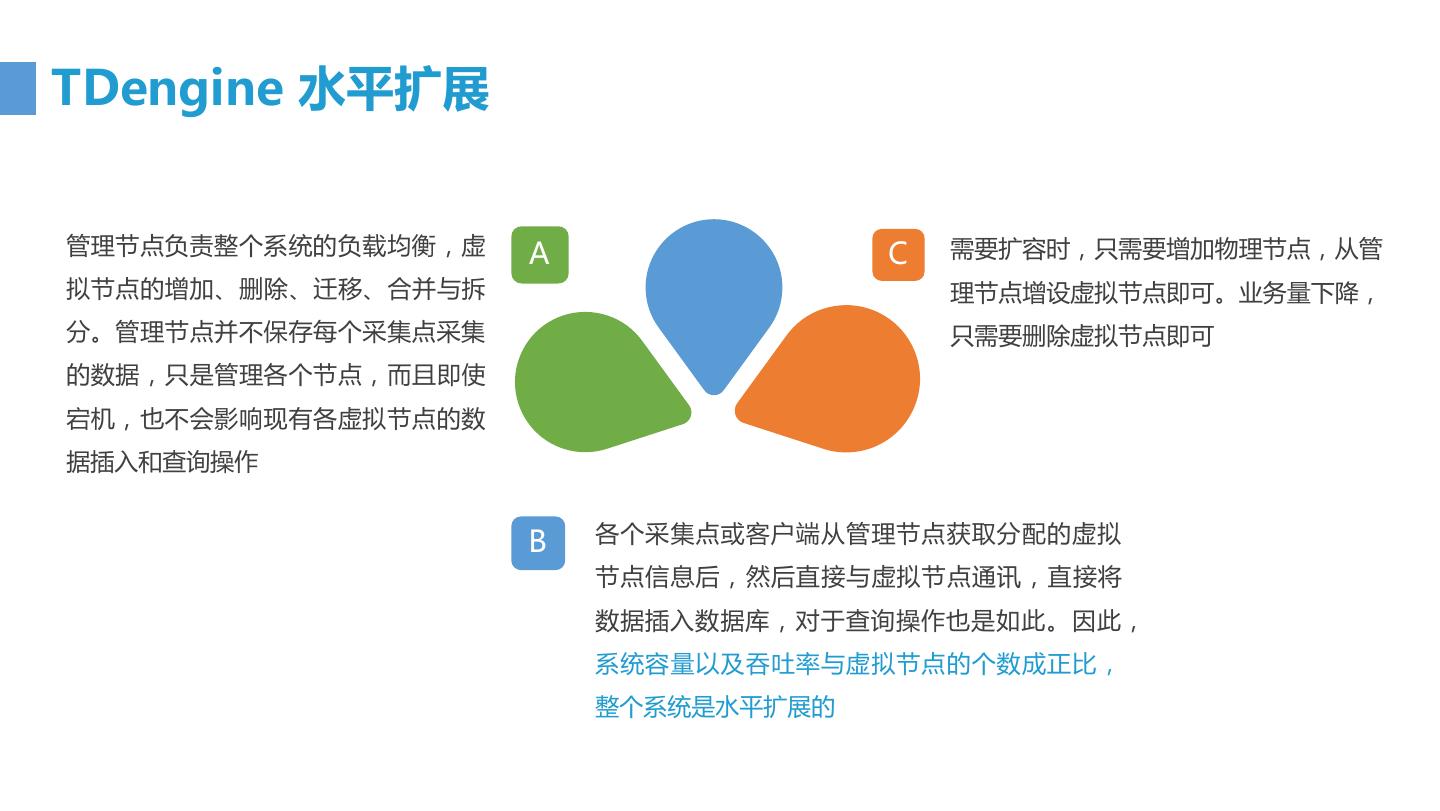
22 .数据节点虚拟化 虚拟节点v1 虚拟节点v2 物理节点 虚拟节点v3 虚拟节点... 一台实际服务器或虚拟机,根据具体的CPU、 内存和存储资源,一个物理节点可以配置多 物理节点 个虚拟节点。 • 当副本数大于1的时候,位于不同物理节点上 虚拟数据节点 的虚拟节点组成一个虚拟数据节点组,虚拟节 • 存储具体的数据,所有针对时序数据的插入和 点组里的虚拟节点分布于不同的物理节点,内 查询操作,都在虚拟数据节点上进行。 部数据是实时同步,保证系统的高可靠。 • 每个虚拟节点包含多个表,表的数量可以配置 • 数据迁移及负载均衡均以一个虚拟节点为基本 • 每个虚拟节点具有自己的任务队列, RPC消息队 单位 列、查询执行队列,独立管理自己的内存缓冲 更好地适应异构的硬件设备,负载均衡和查询任务切 区和磁盘上的文件。同一个物理节点上的虚拟 分也更简单 节点相互之间没有任何关系。
23 .TDengine 节点虚拟化及系统结构 V0 V1 V0 V1 V0 V1 V0 V1 V2 V3 V2 V3 V2 V3 M0 V3 dnode 0 dnode1 dnode 2 dnode 3 V0 V1 V0 V1 V0 V1 V0 V1 V2 V3 V2 M1 V2 V3 M2 V3 dnode 4 dnode 5 dnode 6 dnode 7 完全无中心化设计
24 .UDP/TCP混合连接 • 客户端与服务器之间采用UDP为主、按需启动TCP的方式建立连接通讯,小于64k的包均采用UDP进 行传输,大于64k的包使用TCP进行传输 • 基于UDP协议,开发一套数据包有序传输、失败重传、以及数据流量控制等机制 • 使用UDP协议配合端口重定向机制,充分利用CPU多核的优势 • 普通服务器即可轻松支持数万甚至几十万级别的客户端直连,充分利用UDP快速传输的机制高性能 数据传输。
25 .TDengine 存储结构
26 .TDengine 存储结构 将每一个采集点的数据作为数据库中的一张独立的表来存储,无论在内存 还是硬盘上,一张表的数据点在介质上是连续存放的,这样大幅减少随机 读取操作,数量级的提升读取和查询效率 数据写入硬盘是以追加的方式进行的,但每个数据文件仅仅保存固定一段时 间的数据,大幅提高数据落盘、同步、恢复、删除等操作的效率 为减少文件个数,一个虚拟节点内的所有表在同一时间段的数据都是存储 在同一个数据文件里,而不是一张表一个数据文件
27 .TDengine 存储结构 数据节点文 件结构
28 .TDengine 存储结构 数据节点 data文件结构 • 存储该列的预计算结果,包括最大值、最小值、和等 • 存储每个数据块的schema结构,支持秒级别的表模式的修改,表模式的修改与存量数据无关 • 针对海量的数据快速查询检索,摒弃B-TREE等索引结构,采用针对时间戳的 Block Range Index进行的数据检索,采用预计算模块进行过滤,针对普通字段暂不提供索引。 • 查询过程中,按需加载查询涉及的列。
29 .TDengine 数据的多级存储 最新采集的数据在内存里,根据业务场景,可配置大小,以保证计算全部在内存里进行。 使用TDengine, 无需再集成Redis或其他缓存软件。 当内存满或者设置的时间到,内存的数据会写到持久化存储设备上。TDengine既能处理 实时数据,又能处理历史数据,但这一切对应用是透明的。 持久化存储还可以按照时间分级,比如一天之内的数据在SSD盘上,一个月内的数据在普 通硬盘上,超过一个月的数据在最廉价的存储介质上,最大程度降低存储成本。
3秒后跳转登录页面
去登陆

