




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark+Alluxio:面向K8s的数据本地性优化
Alluxio用缓存的方式,将数据带到计算端,通过更好的数据本地性提升计算效率。随着更多人将服务迁移到云端的容器中并使用K8s来进行容器编排,新的技术、框架和设计理念也给数据本地性带来了新的挑战。Alluxio针对用户在K8s上的不同使用场景,提供了不同的数据本地化解决方案。这个分享将从Spark+Alluxio在非K8s环境下如何实现数据本地性出发,深入介绍Spark+Alluxio如何在K8s环境下实现同样的数据本地性,最后介绍针对不同使用场景的两种解决方案。
展开查看详情
1 .Spark+Alluxio:⾯面向K8s的数据本地性优化 刘嘉承 | Alluxio core maintainer ALLUXIO ONLINE MEETUP 2020
2 .背景综述 ▪ 刘嘉承 • Core maintainer @ Alluxio • Email: jiacheng@alluxio.com !2
3 .⽬目录 ▪ Alluxio概览 ▪ Spark + Alluxio的数据本地性:远程数据,⾮非K8s场景 ▪ Kubernetes概览 ▪ Spark + Alluxio的数据本地性:远程数据,K8s场景 ▪ 管理理员部署场景和⾮非管理理员部署场景 -- Alluxio 2.3新特性 !3
4 . Alluxio概览 ALLUXIO ONLINE MEETUP 2020
5 .开源的数据编排平台Alluxio !5
6 . Spark + Alluxio的数据本地性 ⾮非K8s,远程数据场景 ALLUXIO ONLINE MEETUP 2020
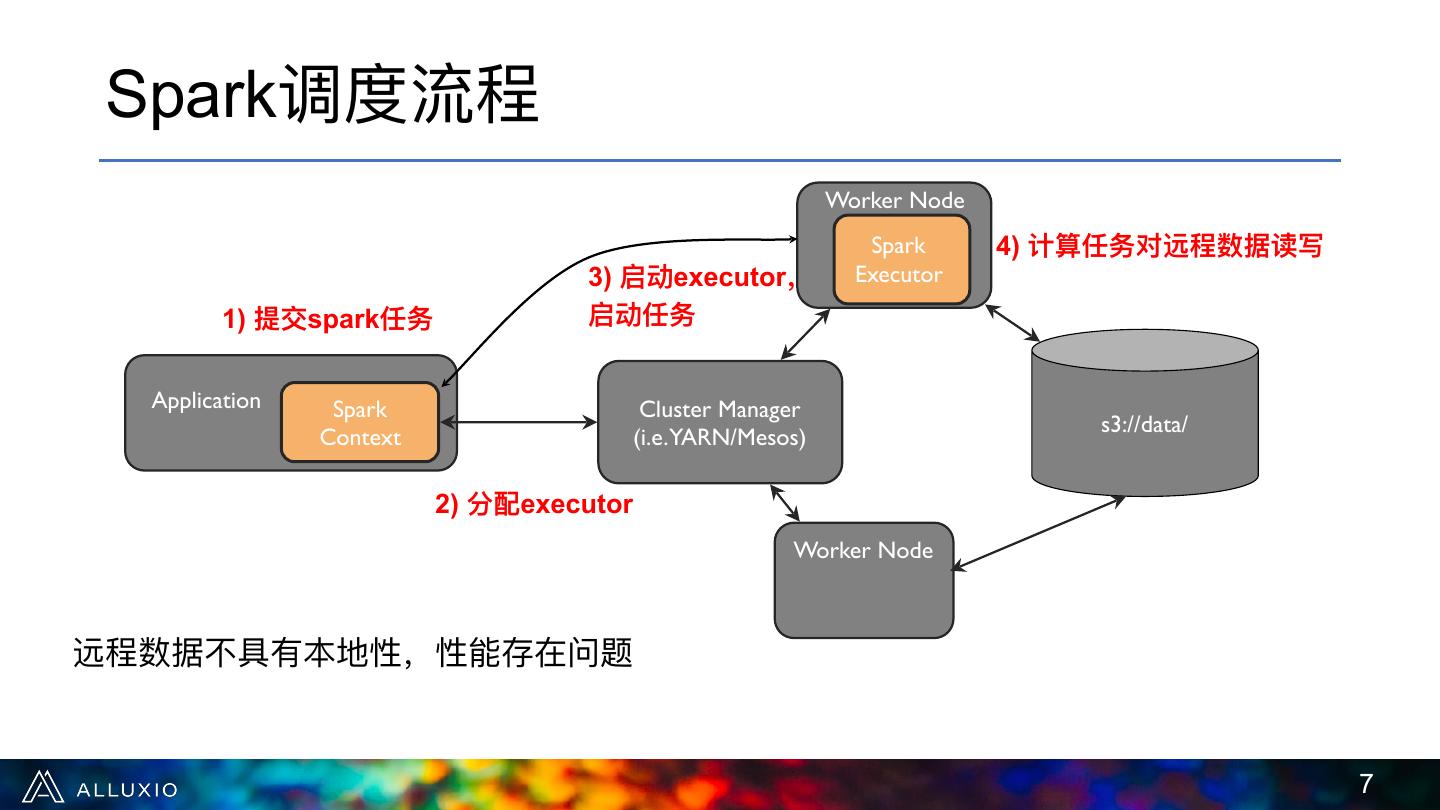
7 . Spark调度流程 Worker Node Spark 4) 计算任务对远程数据读写 3) 启动executor, Executor 1) 提交spark任务 启动任务 Application Spark Cluster Manager s3://data/ Context (i.e.YARN/Mesos) 2) 分配executor Worker Node 远程数据不不具有本地性,性能存在问题 !7
8 .第2步: Alluxio帮助Spark将计算调度到缓存位置 Alluxio Masters HostA: 196.0.0.7 Alluxio 2.1) block1 2.1) block1 Worker 在哪⼉儿? 在[HostA] block1 Application Alluxio Spark Cluster Manager Client Context (i.e.YARN/Mesos) 2.2) 在[HostA]启动executor HostB: 196.0.0.8 Alluxio ● Alluxio client实现了了HDFS API,Spark可以向Alluxio Worker client请求数据块地址 block2 ● Alluxio master记录着缓存的数据块在哪些worker节点 !8
9 .第4步: Spark executor本地读写 [HostA] Alluxio HostA: 196.0.0.7 本地I/O通过本地fs Masters (/mnt/ramdisk/) block1? 或者本地domain Spark Executor Alluxio socket Worker (/opt/domain) Alluxio block1 Client s3://data/ ● Spark executor通过⽐比较hostname,找到本 HostB: 196.0.0.8 地的Alluxio worker Alluxio ● Spark executor通过短路路读写和本地的 Worker Alluxio worker进⾏行行数据交换 !9
10 . 总结:Spark + Alluxio的数据本地性 Alluxio Masters Worker Node 4) 在计算任务中通过 Spark Alluxio Worker Alluxio读写数据 Executor 2.1) 向Alluxio请求数据 3) 启动executor,启动 Alluxio 块(缓存)的位置 Client 任务 Alluxio Spark Cluster Manager Application Client Context (i.e.YARN/Mesos) s3://data/ 2.2) 分配executor 1) 提交Spark任务 Worker Node Alluxio Worker 第2步:Alluxio帮助Spark将计算调度到缓存位置 第4步:Alluxio将Spark的数据操作变成本地缓存读写 !10
11 . Kubernetes概览 ALLUXIO ONLINE MEETUP 2020
12 .Kubernetes “Kubernetes是容器器集群管理理系统,是⼀一个开源的平台,可以 实现容器器集群的⾃自动化部署、⾃自动扩缩容、维护等功能。” !12
13 .容器器编排 ▪ 快速部署应⽤用 ▪ 快速扩展应⽤用 ▪ ⽆无缝对接新的应⽤用功能 ▪ 节省资源,优化硬件资源的使⽤用 ▪ ... !13
14 .K8s专有名词 ▪ Node(节点) • VM/物理理机 ▪ Container(容器器) • Docker镜象:轻量量级的OS和应⽤用程序运⾏行行环境 • Container:运⾏行行中的镜像 ▪ Pod • K8s中的最⼩小可调度单元,⼀一个Pod可以运⾏行行⼀一个或多个container • 同⼀一个Pod中的Container共享存储和⽹网络等资源 ▪ Controller • 管理理Pod的状态,⽐比如控制Pod有多少个 ▪ DaemonSet • Controller的⼀一种,保证这种Pod在每⼀一个Node上只有⼀一个 ▪ Volume • 定义了了⼀一个Pod上Container可访问的⽬目录,和Pod有相同的⽣生命周期 ▪ Persistent Volume • 有持久化保证的Volume,⽣生命周期和Pod⽆无关 !14
15 . Spark + Alluxio的数据本地性 K8s,远程数据场景 ALLUXIO ONLINE MEETUP 2020
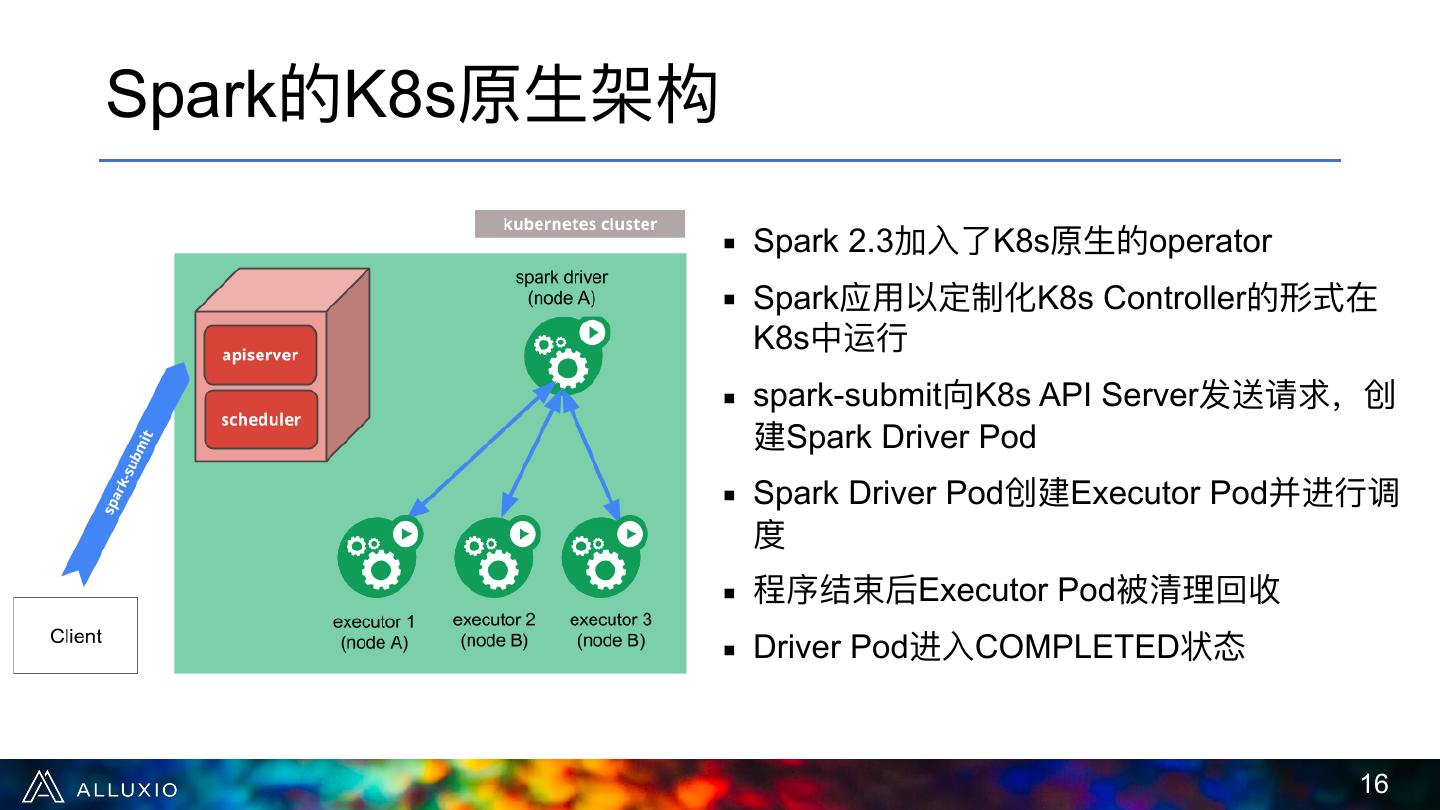
16 .Spark的K8s原⽣生架构 ▪ Spark 2.3加⼊入了了K8s原⽣生的operator ▪ Spark应⽤用以定制化K8s Controller的形式在 K8s中运⾏行行 ▪ spark-submit向K8s API Server发送请求,创 建Spark Driver Pod ▪ Spark Driver Pod创建Executor Pod并进⾏行行调 度 ▪ 程序结束后Executor Pod被清理理回收 ▪ Driver Pod进⼊入COMPLETED状态 !16
17 . 部署模式:co-location ▪ 将Spark Executor Pod和Alluxio Worker Pod部署在 Worker Node 同⼀一物理理机(Node)上 Co-location Spark Executor ⾮非K8s场景 ▪ ⽣生命周期 Alluxio Alluxio Worker • Spark executor⽣生命周期和计算任务相同 Client • Alluxio worker⼀一直存在,为所有的计算任务提供 缓存服务 ▪ 部署顺序: Worker Node Co-location • 先部署Alluxio集群(Master Pod和Worker Pod) Spark K8s场景 • 使⽤用DaemonSet保证每⼀一个节点都有Alluxio Executor Pod Alluxio Worker Pod提供缓存 Alluxio Worker Pod Client • 使⽤用spark-submit来创建Spark Driver和Spark Executor !17
18 . 挑战1: Spark Driver不不知道在哪⾥里里启动Executor Some Node HostA: 196.0.0.7 Alluxio Master Pods AlluxioWorkerPodA: 10.0.1.1 block1? [AlluxioWorkerPodA] block1 Some Node Spark Driver HostB: 196.0.0.8 Application Alluxio Spark Pod Client Context 在[AlluxioWorkerPodA] AlluxioWorkerPodB: 启动Executor? 10.0.1.2 Alluxio Worker Pod地址和物理理机地址不不同 !18
19 . 解决⽅方案:使⽤用hostNetwork选项启动Alluxio worker Some Node HostA: 196.0.0.7 Alluxio Network Master adapter Pods HostA: 196.0.0.7 hostNetwork: true block1? [HostA] Some Node block1 Alluxio Spark Application Client Context Spark HostB: 196.0.0.8 Driver Pod Network 在[HostA]启动executor adapter HostB: 196.0.0.8 hostNetwork: true Block2 !19
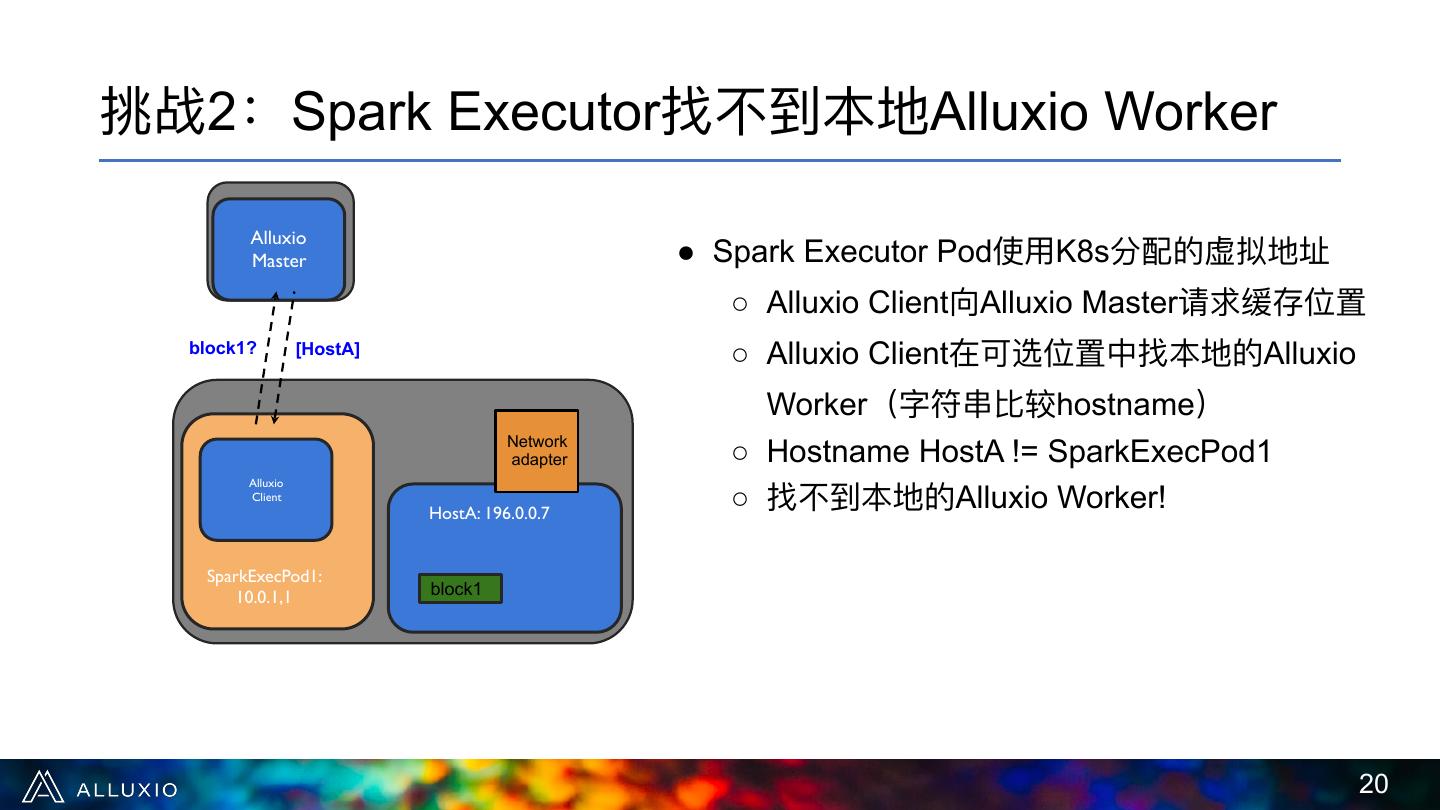
20 .挑战2:Spark Executor找不不到本地Alluxio Worker Alluxio Master ● Spark Executor Pod使⽤用K8s分配的虚拟地址 ○ Alluxio Client向Alluxio Master请求缓存位置 block1? [HostA] ○ Alluxio Client在可选位置中找本地的Alluxio Worker(字符串串⽐比较hostname) Network adapter ○ Hostname HostA != SparkExecPod1 ○ 找不不到本地的Alluxio Worker! Alluxio Client HostA: 196.0.0.7 SparkExecPod1: 10.0.1,1 block1 !20
21 .挑战3:Spark Executor找不不到本地domain socket Alluxio Master ● Pod之间不不共享⽂文件系统 block1? [HostA] ● domain socket⽂文件/opt/domain在Alluxio Worker Pod内,对Spark Executor Pod不不 Alluxio Network 可⻅见 Client adapter HostA: 196.0.0.7 /opt/domain/ SparkExecPod1: 10.0.1,1 block1 !21
22 . 解决⽅方案:使⽤用UUID来辨认本地worker;使⽤用hostPath Volume将domain socket共享给Spark Executor Alluxio ● 每⼀一个Alluxio Worker有⾃自⼰己的UUID Master ● 通过hostPath Volume在Alluxio Worker和Spark block1? [HostA: Executor之间共享/opt/domain⽂文件夹 UUIDABC] ● Alluxio Client通过查找/opt/domain⽂文件夹下⽂文件的 /opt/domain/UUIDABC ⽅方式找本地Worker的domain socket ● /opt/domain/d -> /opt/domain/UUIDABC Alluxio 配置项: Client block1 alluxio.worker.data.server.domain.socket.as.uuid=true UUID: UUIDABC ● 为Spark executor添加了了挂载各种Volume的选项 SparkExecPod1: HostA: 196.0.0.7 10.0.1,1 Spark 2.4 (PR) !22
23 . 总结:Spark + Alluxio在K8s场景下的本地性 Some Node Worker Node Alluxio 4) 在计算任务中通过 Master Spark Alluxio读写数据 Pods Executor Alluxio 3) 启动executor, Pod Worker 2.1) 向Alluxio请求数据 启动任务 Alluxio Pod 块(缓存)的位置 Client Some Node s3://data/ Alluxio Spark 2.2) 启动driver Application Client Spark Context Driver Pod Worker Node 1) 提交Spark任务 Alluxio Worker Pod 第2步:Alluxio帮助Spark将计算调度到缓存位置 第4步:Alluxio将Spark的数据操作变成本地缓存读写 !23
24 . 管理理员和⾮非管理理员部署场景 ALLUXIO ONLINE MEETUP 2020
25 .权限控制问题: ● 许多⽤用户的环境有权限控制,⽆无法使⽤用hostNetwork和hostPath,⽆无法取得 数据本地性 ● Alluxio 2.3(2020/06)将会移除对hostNetwork和hostPath的依赖,⽀支持⾮非 管理理员部署场景下的数据本地性 !25
26 .两种部署场景: 场景1: 管理理员部署 ● 使⽤用hostNetwork和hostPath !26
27 .两种部署场景: 场景2: ⾮非管理理员部署 ● Alluxio worker需要使⽤用Node hostname,否则Spark executor⽆无法调度到正确 的节点 ○ Alluxio 2.3:将hostNetwork改为使⽤用K8s downward API在Pod启动时获取 Node hostname和Pod hostname alluxio.worker.hostname=<hostIP> alluxio.worker.container.hostname=<podIP> ○ 使⽤用alluxio.worker.hostname进⾏行行调度 ○ 使⽤用alluxio.worker.container.hostname进⾏行行RPC ● domain socket⽂文件需要在Volume中共享给Spark executor ○ Alluxio 2.3:⽤用户可以使⽤用local Volume取代hostPath Volume !27
28 .拓拓展阅读 K8s中⽂文⽂文档 http://docs.kubernetes.org.cn/ Spark Native K8s Support https://spark.apache.org/docs/latest/running-on-kubernetes.html Spark + Alluxio Advanced Data Locality https://www.alluxio.io/blog/top-10-tips-for-making-the-spark-alluxio-stack-blazing-fast/ Running Alluxio in K8s https://docs.alluxio.io/os/user/stable/en/deploy/Running-Alluxio-On-Kubernetes.html Running Spark with Alluxio in K8s https://docs.alluxio.io/os/user/stable/en/compute/Spark-On-Kubernetes.html How Alluxio Helps Analytics Stack in Kubernetes https://www.alluxio.io/blog/kubernetes-alluxio-and-the-disaggregated-analytics-stack/ How Spark scheduling works on K8s https://banzaicloud.com/blog/spark-k8s-scheduler/ !28
29 .欢迎加⼊入Alluxio社区 Slack channel alluxio.io/slack 微信公众号 知乎专栏 B站专区 !29
3秒后跳转登录页面
去登陆

