




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Atom:A cloud-native deep learning platform at Supremind
李朝光(上海闪马智能科技(原七牛云AI部门)的首席架构师)在2019年6月北京Alluxio meetup上做的分享
议题简介:李朝光将分享如何利用云端资源和诸如Pytorch,Mxnet,Kubernetes, Alluxio等开源数据组件架构云原生的深度学习平台。该平台通过使用Kubernetes编排模型训练和服务,以及使用Alluxio编排作为云端数据,深度学习框架可以无缝运行于指定运行环境并对接各种云端数据。
展开查看详情
1 .Atom:A cloud native deep learning platform at Supremind 李李朝光 Chief Architect, Supremind lichaoguang@supremind.com
2 . Agenda • Who and where we are • Deep training platform (Atom) introduction • Alluxio data echosystem • Atom data management • Atom dataset and workflow management • Future work
3 .Who and where we are? ATLAB 闪⻢马智能 Supremind Image censor Traffic analysis Crowd gathering Abnormal behavior analysis for picture/video
4 . Why we need a deep learning platform • Algorithm team & joint laboratory • Easy to use portal • Can not manage data efficiently in cloud • Data virtualization globally • P+ training data, E+ reference data • Resource utilization is low • GPU resource pool • Model transition is painful • Tron: +20% performance • Service publishing is painful • Verify/test in 3rd party (aliyun) • Workflow for repeat job
5 . Agenda • Who and where we are • Deep training platform (Atom) introduction • Alluxio data echosystem • Atom data management • Atom dataset and workflow management • Future work
6 .Atom - Backbone of supremind production Production line Training Traffic Security • Atom is developed Censor Monitor Knowledge during d2d deep training Model detection • High quality model Face Car plate ReID Mass trained and rectified by Crown Behavior Vide data structure Knowledge Atom platform graph • 60B+ picture/video Video mgt Camera drive • B+ added per day Search Crawler Cloud data Streaming Label system Cooperatio n Ato Deep 城市⼤大数据 Big data VAS Video analysis LEGO learning 第三⽅方云⼚厂商 Platform m platform Platform Operation team Research and development team
7 . Atom labelx labeling sub-system Imag Video Text e Interface Cloud Private Censo Car/ r Bike Pre-process Cleaning Label Audit Publish Training Ato m Operating system Trackin Person g Certif Training Mentor Award Quality Channel Finance y
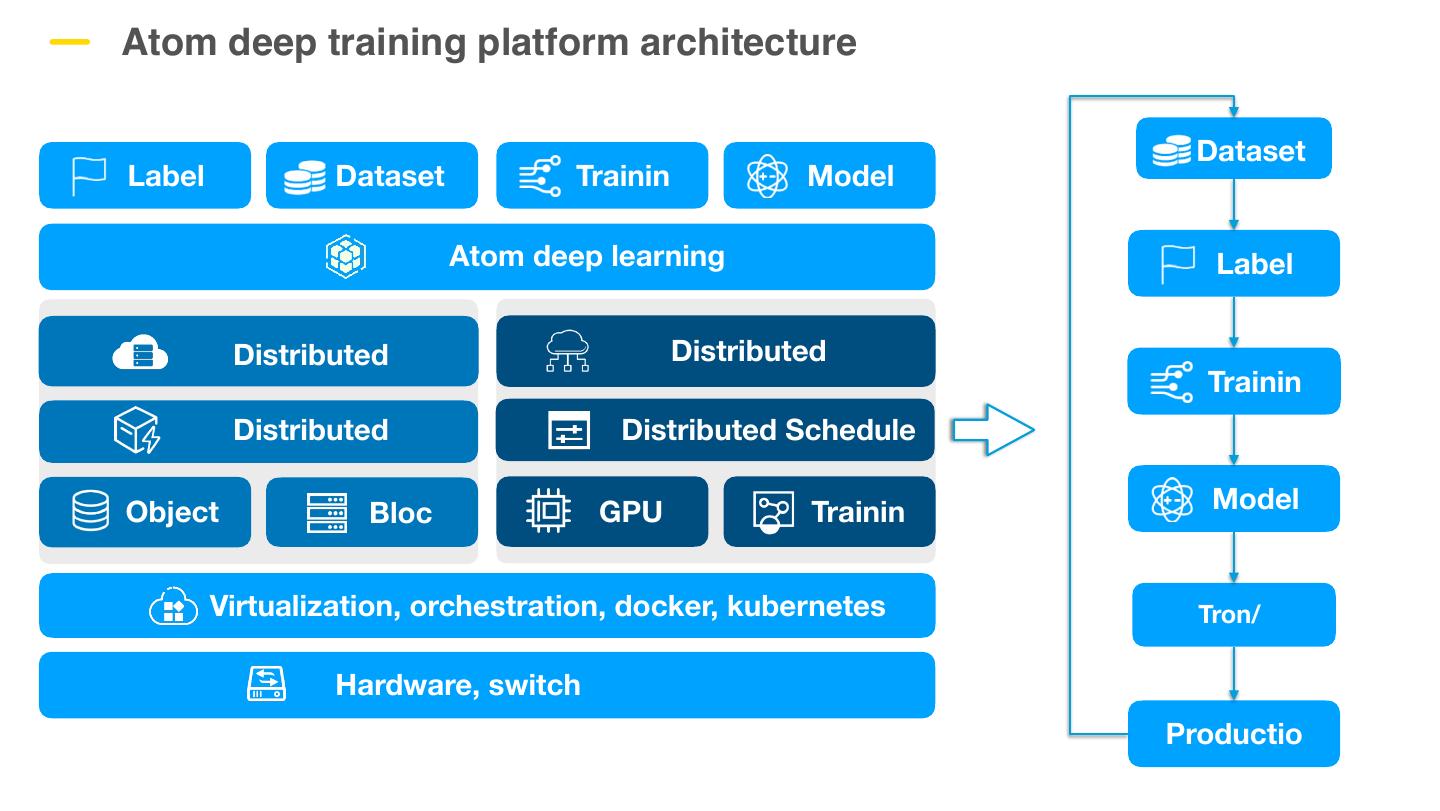
8 .Atom deep training platform architecture Dataset Label Dataset Trainin Model Atom deep learning Label Distributed Distributed Trainin Distributed Distributed Schedule Object Bloc GPU Trainin Model Virtualization, orchestration, docker, kubernetes Tron/ Hardware, switch Productio
9 . Compute orchestration in deep learning platform SOC SOC Switch Switch Kubelet schedule Kubelet schedule Select slot 1st allocation K8s schedule Select node 2nd allocation 3th allocation Atom schedule Select cluster: Rank cost/data/bw etc
10 . Data orchestration in deep learning platform Simple data management: Intuitive solution NFS: shared, poor performance Local cluster data management: Not designed for CEPH(RBD): copying, duplicated large scale data Global object data management: Data: alluxio + qiniu object storage Need Meta mgt Careful resource planning for alluxio & Data mobility Dataset and data flow management: new challenge Later on …
11 . Agenda • Who and where we are • Deep training platform (Atom) introduction • Alluxio data echosystem • Atom data management • Atom dataset and workflow management • Future work
12 . Alluxio and Data Ecosystem • Data Locality: • Accelerate big data workloads with transparent tiered local data • Data Accessibility: • Run Spark, Hive, Presto, ML workloads on your data located anywhere • Data Elasticity: • Abstract data silos & storage systems to independently scale data on- demand with compute Apache 2.0 License 4000+ 1000+ Originated as Tachyon project Github Stars Github Contributors at the UC Berkley’s AMP Lab
13 . Alluxio File System APIs • Spark > rdd = sc.textFile(“alluxio://localhost:19998/myInput”) • Hadoop $ hadoop fs -cat alluxio://localhost:19998/myInput • POSIX (e.g., Tensorflow and etc) $ cat /mnt/alluxio/myInput • Java FileSystem fs = FileSystem.Factory.get(); FileInStream in = fs.openFile(new AlluxioURI("/myInput"));
14 .Alluxio Reference Architecture WAN Alluxio Alluxio Worker Client RAM / SSD / HDD Application Under Store 1 … Alluxio Alluxio Client Worker Application RAM / SSD / HDD Under Store 2 Alluxio Zookeeper / Master RAFT Standby Master
15 . Agenda • Who and where we are • Deep training platform (Atom) introduction • Alluxio data echosystem • Atom data management • Atom dataset and workflow management • Future work
16 . Access global object storage for deep training platform • Data • Hundreds of TB image Deep learning training program • Motivation: /a1 /a2 /a1 /a2 • Use cloud data efficiently FUSE FUSE • Problem: • Storage capacity is limited (CEPH) FUSE Adapter (on host) • Storage sub-sys is not scalable • Deep learning can’t use cloud object alluxio Virtual File System • Challenge: • Fuse overhead • Resource allocation KODO S3 • Random read support • First time access Qiniu object storage AWS object storage Data access 10x+ faster!
17 . Data optimization in deep training platform POD • Data App • Several PB training data Short circuit • Hundreds of PB inference data Attr Local worker • Motivation: cache • Use data efficiently • Problem: • Resource starvation • Meta data (master) Alluxio cluster 1 Alluxio cluster 2 • Video clipping • Distributed training • Optimization: • Shard • Short circuit Block dev pool • Local worker • Cache policy • Data warmup
18 . Data locality Problems: • Fuse: 30% off GPU GPU • Random r/w Atom io agent Atom io agent • Mmap Alluxio fuse Alluxio fuse Alluxio worker Alluxio worker Solution: Block dev Block dev • Send worker to GPU • Send data to worker Gain: Worker warmup • Load r/w performance scheduler service • Random IO perf Alluxio cluster • Mmap/Direct io Atom scheduler Data access 50%-300% faster Atom Compared with fuse
19 .Metadata management Challenges: • All memory meta data On heap Off heap • Journal in shared folder B+ tree ! (mapdb) • Mobility JNI • Data gone, meta left Share storage (cephfs) ! Solutions: • Off-heat • Disk-based Fuse cache inside alluxio • Meta-caching policy Heap cache Heap cache • Fuse cache Raft Alluxio-2.0 (preview): Block dev Block dev • Raft for journal • RocksDB w/ inode cache
20 . New challenge • Motivation: • Support both training and business • Cost control Azure AVA + Alluxio • Problem: Qiniu • Data lake AVA + Alluxio • GPU starvation AWS • Star-up mode AVA + Alluxio • Challenges: • Multiple vendors support • Cluster federation (Kubernetes) AVA + Alluxio Customer Data Local • Workflow management cluster • Day-to-day training and inference • Complicated data flow managemen Cluster federation • Dataset design
21 . Agenda • Who and where we are • Deep training platform (Atom) introduction • Alluxio data echosystem • Atom data management • Atom dataset and workflow management • Future work
22 . Observation • Some data (set) never changed • Some undergoes 1%-3% updated during iteration • Data access together with same pattern • Why bother data service frequently? Training Datasets Index cluster Alluxio cache Training Objects Datasets Alluxio cache
23 . Atom: adapt to data challenge Pod Pod /dir1 /dir1 • Problems ——/dir1-1 ——/dir1-1 ————/dir1-1-1 ————/dir1-1-1 • Not production ready ——/dir1-2 ——/dir1-2 • Manual intervention Front end portal • Not cross cluster • Features Labelx subsystem Service runtime interfaces • Based on cloud Service layer • Access everywhere • Light-weight • Movable Dataset manager Warmup srv Data clearn scheduler Cloud adpt Training • Versioned • Easy to use (file system) • Good performance Kubernetes cluster • Solution • Dataset design Dataset • Send data to compute AWS KODO OSS Alluxio cluster
24 . Atom dataset management flow Label personel Send dataset to compute! LableX system Data gathering Data extractor Lablex pipeline Export Training set Feedback Label Datasets Ato Dataset & Schedule engine Testing m Online feedback set DL platform Deploy Revise Model Deploy model Model versions Evaluate
25 . Atom Workflow management Define parameters Pre-defined • Why/how work flow management Workflow 2 • Multiple clouds support 1 • Data accessible every where (via alluxio) • Need cluster federation • A training job launched in backend • Production efficiency 3 • For new hire Resources requirements 4 Go: Train on cluster x
26 . Agenda • Who and where we are • Deep training platform (Atom) introduction • Alluxio data echosystem • Atom data management • Atom dataset and workflow management • Future work
27 .Future work • Datasets for Distributed Training • Param exchange overwhelm network • Network optimization • Distributed training does not scale with machine number • Model optimization and chip adaption • Model conversion & compaction (Tron & Shadow) • ARM, AMD, etc
3秒后跳转登录页面
去登陆

