展开查看详情
1 .Alluxio – Virtual Unified File System
Li Haoyuan – Founder and CEO at Alluxio
haoyuan@alluxio.com
�
2 . The Global Datasphere will grow from
33 ZB in 2018 to 175 ZB by 2025
China’s Datasphere is expected to grow 30% on average
over the next 7 years &
will be the largest Datasphere of all regions by 2025
Source: IDC White Paper – #US44413318
�
3 .We are in the era where
Data is your biggest asset
�
4 .Extracting maximum value from your data
The Data Ecosystem Evolution
�
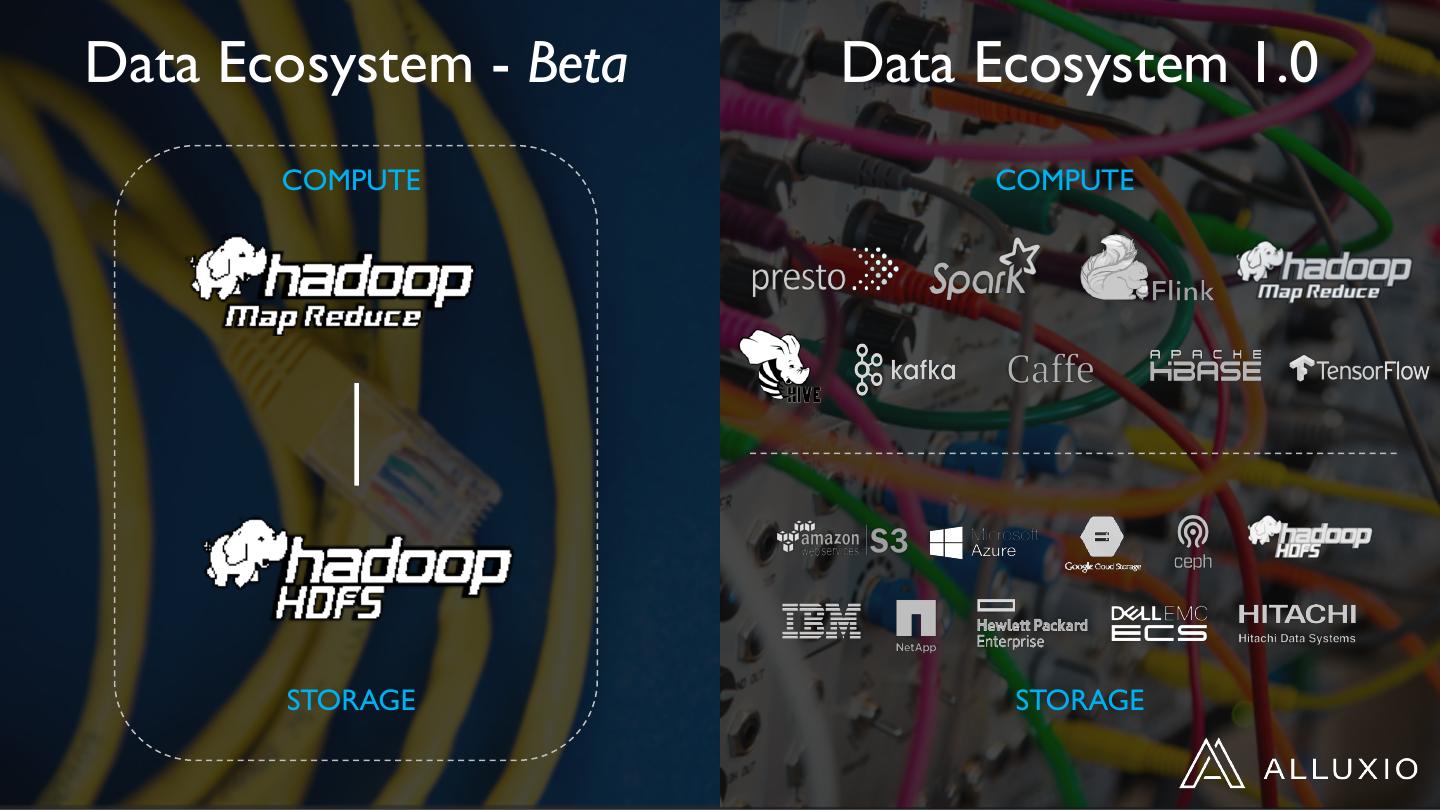
5 .Data Ecosystem - Beta Data Ecosystem 1.0
COMPUTE COMPUTE
STORAGE STORAGE
�
6 .Data Ecosystem 1.0 – The Challenges
COMPUTE
Complex
Low performance
Expensive
STORAGE
�
7 .3 big trends driving the need for a new architecture
Separation of Hybrid –Multi Self-service data
Compute & cloud across the
Storage environments enterprise
�
8 .The Data Architecture for the Digital Future
�
9 . Core requirements of 2.0 data ecosystem
Unified Memory-first Native APIs Multi-hybrid cloud
�
10 .A Virtual Unified File System
�
11 .Java File API HDFS Interface S3 Interface FUSE Interface REST API
Virtual Unified File System
HDFS Driver Swift Driver S3 Driver NFS Driver
�
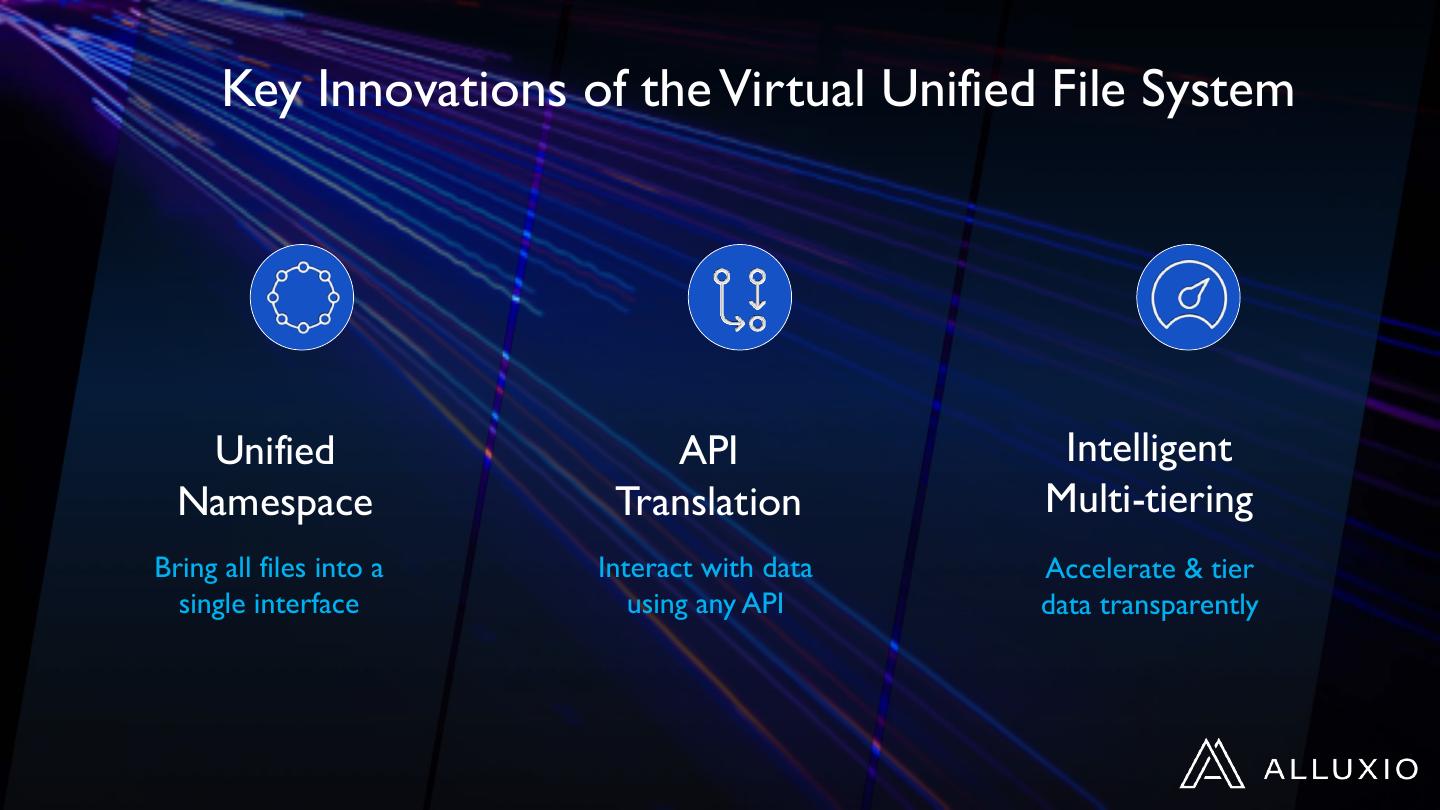
12 . Key Innovations of the Virtual Unified File System
Unified API Intelligent
Namespace Translation Multi-tiering
Bring all files into a Interact with data Accelerate & tier
single interface using any API data transparently
�
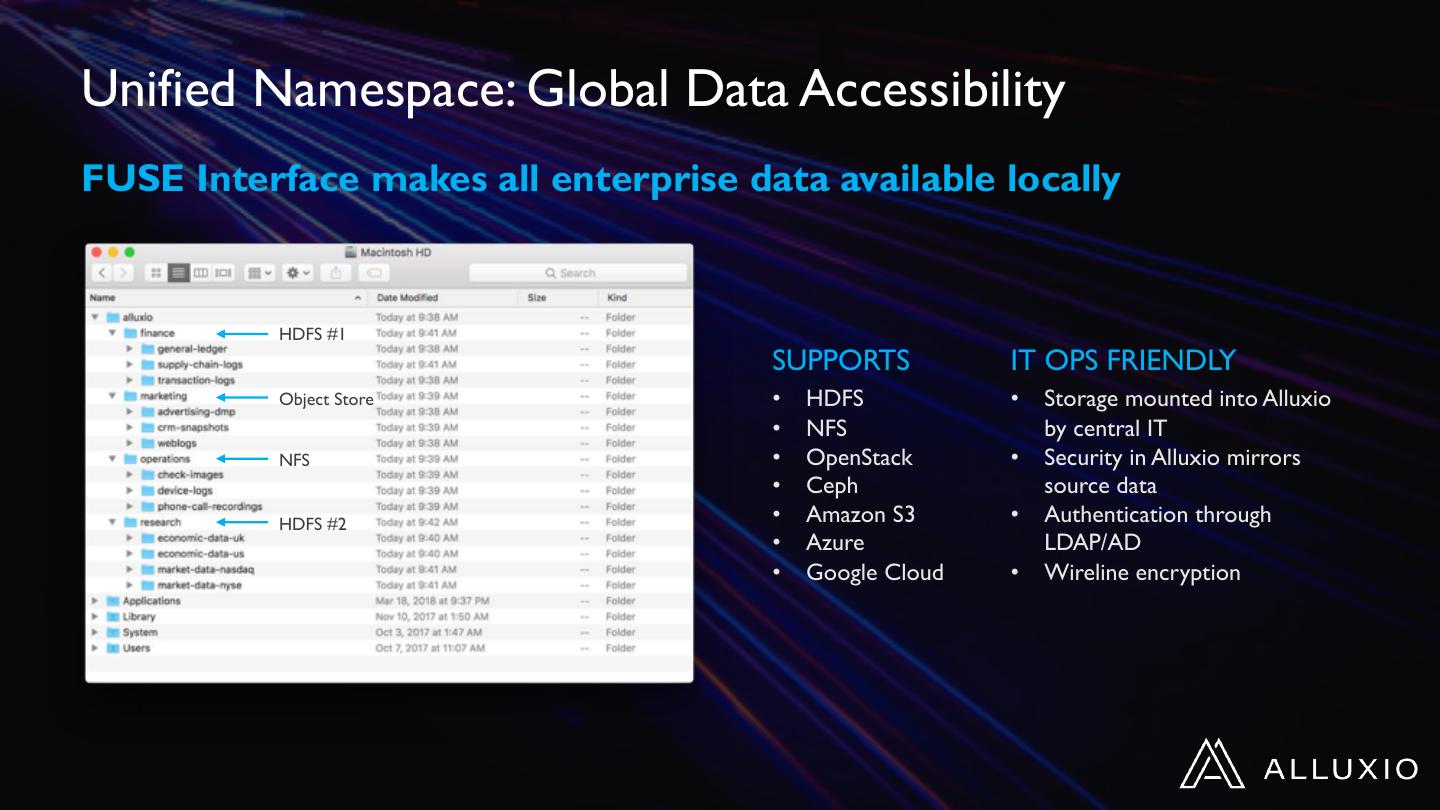
13 .Unified Namespace: Global Data Accessibility
FUSE Interface makes all enterprise data available locally
HDFS #1
SUPPORTS IT OPS FRIENDLY
Object Store • HDFS • Storage mounted into Alluxio
• NFS by central IT
NFS • OpenStack • Security in Alluxio mirrors
• Ceph source data
HDFS #2 • Amazon S3 • Authentication through
• Azure LDAP/AD
• Google Cloud • Wireline encryption
�
14 .Server-side API Translation: From legacy to modern
Convert from Client-side Interface to native Storage Interface
Java File API HDFS Interface S3 Interface FUSE Interface REST API
HDFS Driver S3 Driver Swift Driver NFS Driver
�
15 .Intelligent Multi-tiering: Get high-value data faster
Local performance from remote data using multi-tier storage
Read & Write Buffering
Transparent to App
RAM SSD HDD
Hot Warm Cold
Policies for pinning,
promotion/demotion, TTL
�
17 . Popular Technical Use Cases
Virtual Machine Learning Self-service data
Data Lake Productivity across hybrid cloud
§ Accelerate batch, micro- § Accelerate ML jobs § Provide unified interface
batch & streaming jobs running on object stores to access all data
or file systems
§ Slowly transition to § Accelerate & tier data
lower cost object stores § Provide consistent transparently across
performance to data storage tiers
§ Run in hybrid cloud scientists
environment with § Co-locate remote data
compute in the cloud with compute for
performance
�
18 .100+ Known Production Deployments
Massive clusters deployed, many with 500+ nodes
�
19 .Financial Services Case Study
Machine Learning Use Case
SPARK SPARK
TERADATA
TERADATA
Challenge – Solution –
Gain end to end view of business ETL Data from Teradata to Alluxio
with large volume of data
Impact –
Faster Time to Market – “Now we
Queries were slow / not interactive,
resulting in operational inefficiency don’t have to work Sundays”
�
20 .Retail Case Study
Customer Analytics Use Case
SPARK SPARK
HDFS
HDFS
Challenge – Solution –
Bottleneck in Trend Analysis of With Alluxio, data queries are 10X
mission critical daily sales and faster
inventory management
Impact –
Queries were slow / not interactive, Higher operational efficiency
resulting in operational inefficiency
�
21 .Telecom Case Study
Customer 360 Insights
HADOOP HDFS ML HADOOP ML
ETL
HDP CDH MAPR
HDFS HDFS HDFS HDFS HDFS HDFS
Challenge – Solution –
Desired a central view of consumer Alluxio integrates data into central
information in near real time for catalog for fast access to consumer
proactive support. interaction records.
Many HDFS, different distributions,
Impact –
many incompatible versions. On- Reduced integration time
Faster data speed & freshness
prem & cloud. Integration through
heavy ETL.
�
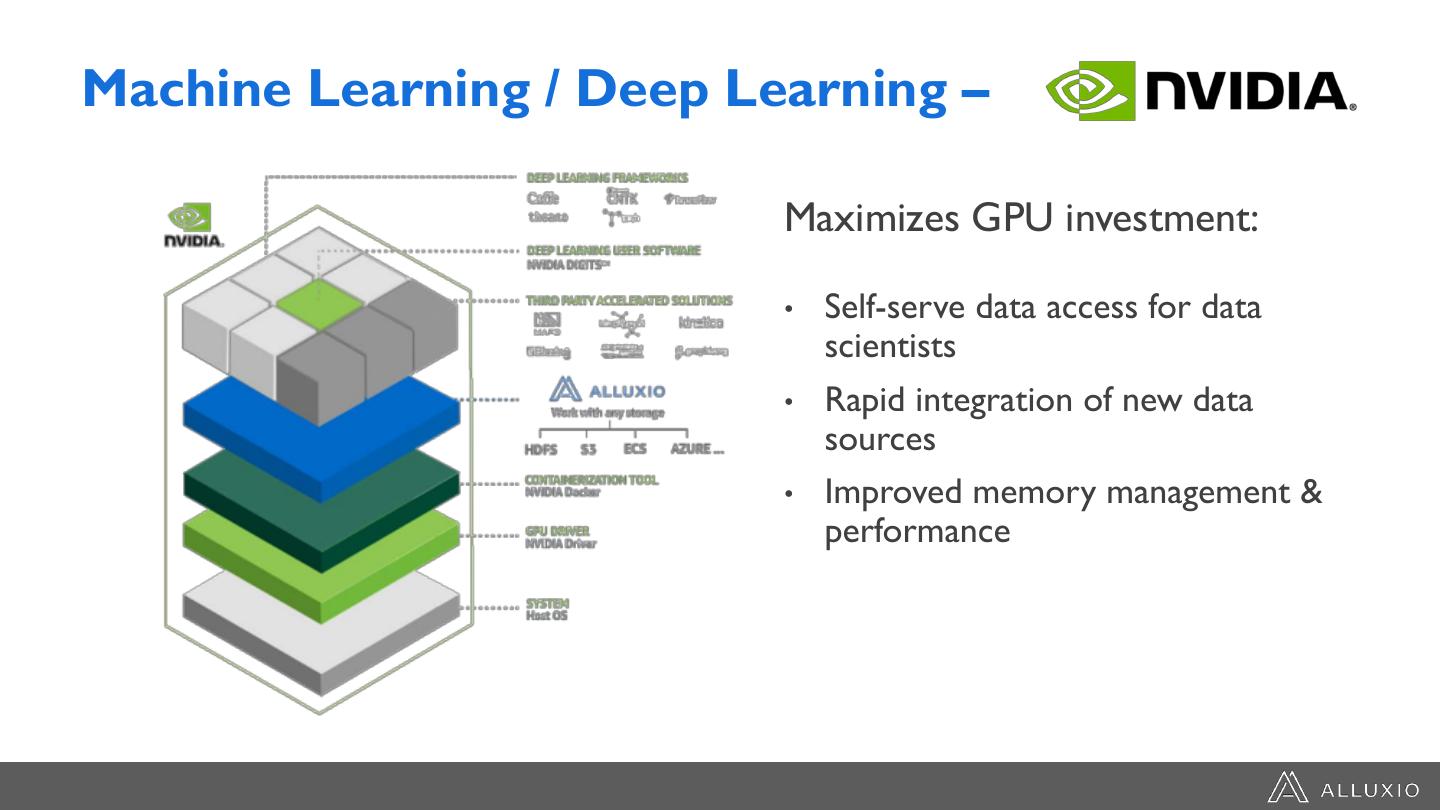
22 .Machine Learning / Deep Learning –
Maximizes GPU investment:
• Self-serve data access for data
scientists
• Rapid integration of new data
sources
• Improved memory management &
performance
�
23 . Incredible Open Source Momentum with growing community
920+ contributors &
Apache 2.0 Licensed
growing
Hundreds of thousands
3760+ Git Stars of downloads
Download Alluxio today @ www.alluxio.org
�
24 .Thank You
Join the Alluxio Community
www.alluxio.org | www.alluxio.com | Twitter: @alluxio
�