























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Alluxio Introduction & Community Roadmap
来自阿里云的工程师、Alluxio项目PMC成员毛宝龙作的题为“Alluxio Introduction& Community roadmap”的报告。他首先介绍了Alluxio是什么,整体架构及架构演进、Alluxio重要feature,接着介绍了Alluxio的roadmap以及Benefits of contributing to Alluxio,最后介绍了How to contribute to Alluxio。
展开查看详情
1 .Alluxio Introduction & Community Roadmap Baolong Mao| Alluxio PMC maobaolong@139.com baolong.mbl@alibaba-inc.com
2 .About me 毛宝龙(神龙),阿里云数据库产品事业部 ,丛事数据传输、数据备份、数据重删等数据相关工作 之前,京东大数据分布式存储相关工作。 研发京东万台规模大数据分布式文件存储。 热爱开源,并积极投入开源社区。 • Alluxio PMC & contributor • Hadoop contributor
3 . Open Source Started From UC Berkeley AMPLab 1000+ contributors & growing Apache 2.0 Licensed GitHub’s Top 100 Most 4000+ Git Stars Valuable Repositories Join the Out of 96 Million conversation on Slack www.alluxio.io/slack
4 .Companies Using Alluxio - Read More
5 . The Alluxio Story [əˈluksio] All luxury IO Originated as Tachyon project, at the UC Berkley’s AMP Lab by then Ph.D. student & now Alluxio CTO, Haoyuan (H.Y.) Li. 2014 Open Source project established & company to commercialize Alluxio founded 2015 Goal: Orchestrate Data at Memory Speed for the Cloud for data driven apps such as Big Data, Analytics ML and AI. 2018 2018 2019
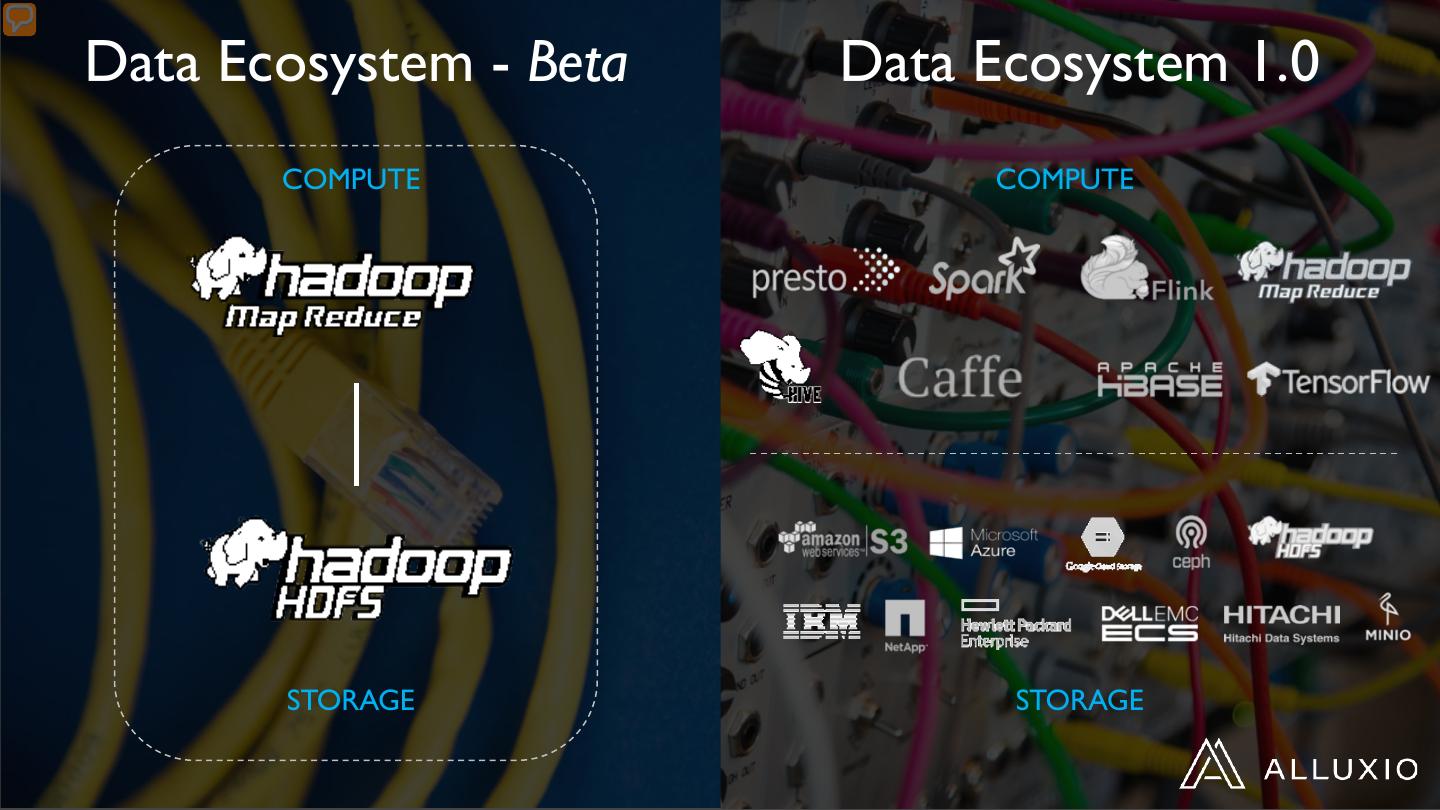
6 .Data Ecosystem - Beta Data Ecosystem 1.0 COMPUTE COMPUTE STORAGE STORAGE
7 .Data Ecosystem 1.0 – The Challenges COMPUTE No Api Translate Complex No Cache Low performance No Cache Expensive STORAGE
8 . Data stack journey and innovation paths Co-located Disaggregated Support more frameworks Co-located Disaggregated Support Presto, Spark compute & HDFS compute & HDFS across DCs without on the same cluster on the same cluster app changes HDFS for Hybrid Cloud MR / Hive Hive Burst HDFS data in HDFS the cloud, HDFS public or private Transition to Object store Typically compute-bound Compute & I/O can be clusters over 100% capacity scaled independently but Compute & I/O need to be I/O still needed on HDFS Enable & accelerate scaled together even when which is expensive big data on not needed object stores
9 . Independent scaling of compute & storage Java File API HDFS Interface S3 Interface POSIX Interface REST API Data Orchestration for the Cloud HDFS Driver Swift Driver S3 Driver NFS Driver
10 . APIs to Interact with data in Alluxio Application have great flexibility to read / write data with many options Spark > rdd = sc.textFile(“alluxio://master:19998/myInput”) Presto CREATE SCHEMA hive.web WITH (location = 'alluxio://master:19998/my-table/') POSIX $ cat /mnt/alluxio/myInput Java FileSystem fs = FileSystem.Factory.get(); FileInStream in = fs.openFile(new AlluxioURI("/myInput"));
11 . Challenges with running workloads on cloud storage Accelerate analytical frameworks Compute caching for S3 / GCS/ OSS on the public cloud S3 performance is variable and consistent query SLAs are hard to achieve Spark Spark Spark Spark S3 metadata operations are expensive making workloads run longer Alluxio Alluxio Alluxio Alluxio S3 egress costs add up making the Same instance solution expensive / container S3 is eventually consistent making it hard to predict query results or
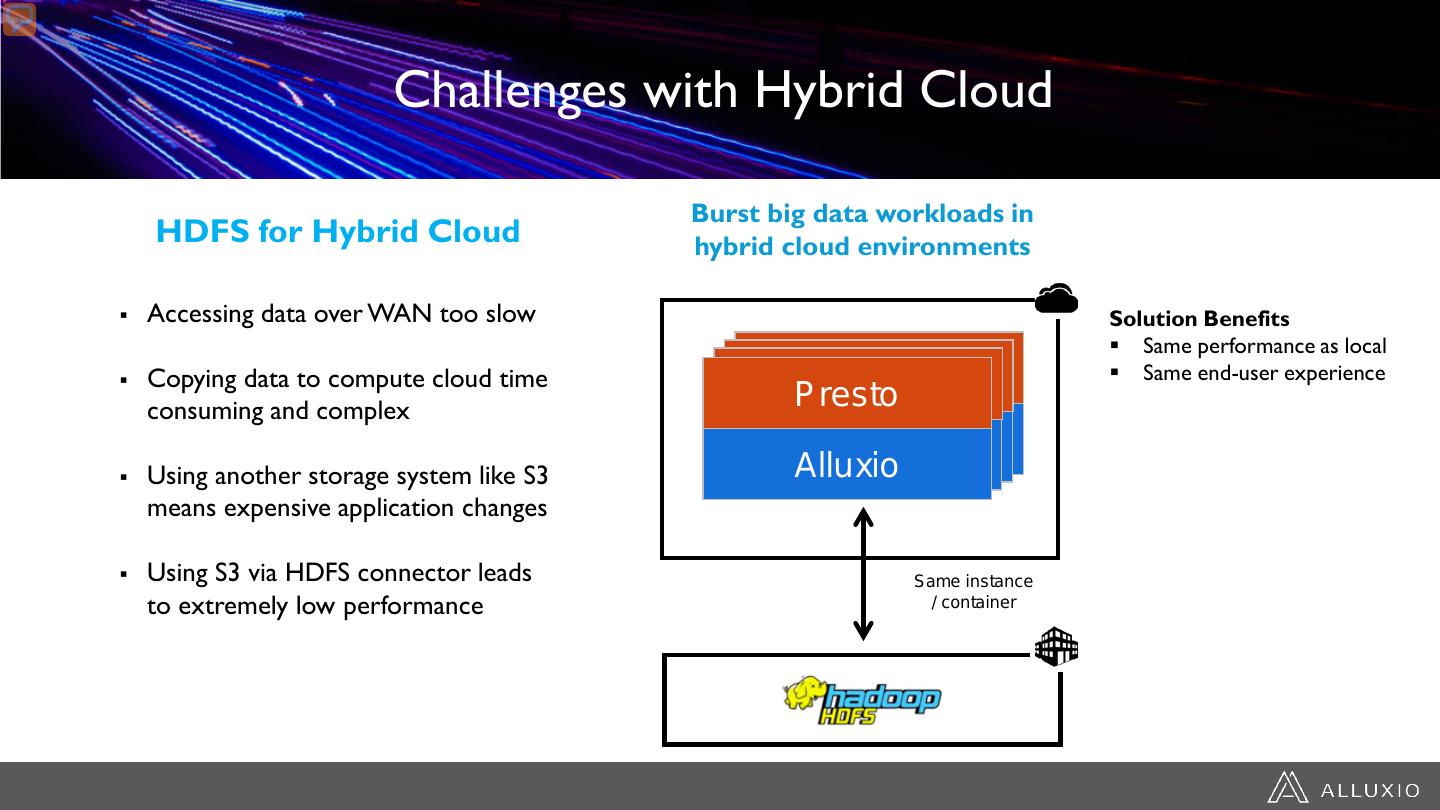
12 . Challenges with Hybrid Cloud Burst big data workloads in HDFS for Hybrid Cloud hybrid cloud environments Accessing data over WAN too slow Solution Benefits Same performance as local Copying data to compute cloud time Presto Presto Presto Same end-user experience consuming and complex Presto Alluxio Alluxio Alluxio Using another storage system like S3 Alluxio means expensive application changes Using S3 via HDFS connector leads Same instance to extremely low performance / container
13 . Alluxio – Key innovations Data Locality Data Accessibility Data Elasticity with Intelligent for popular APIs & with a unified Multi-tiering API translation namespace Accelerate big data Run Spark, Hive, Presto, ML Abstract data silos & storage workloads with transparent workloads on your data systems to independently scale tiered local data located anywhere data on-demand with compute
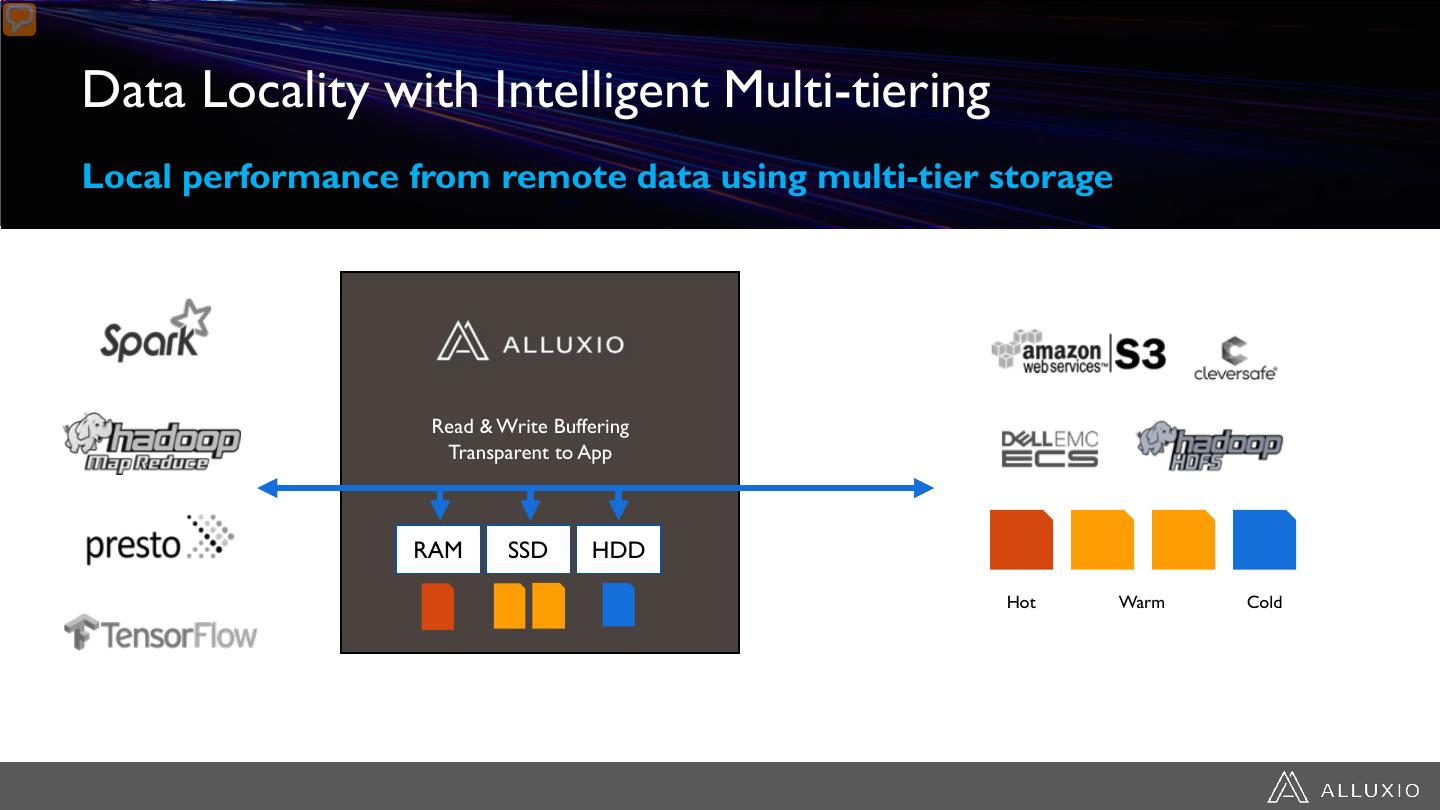
14 .Data Locality with Intelligent Multi-tiering Local performance from remote data using multi-tier storage Read & Write Buffering Transparent to App RAM SSD HDD Hot Warm Cold Policies for pinning, promotion/demotion,TTL
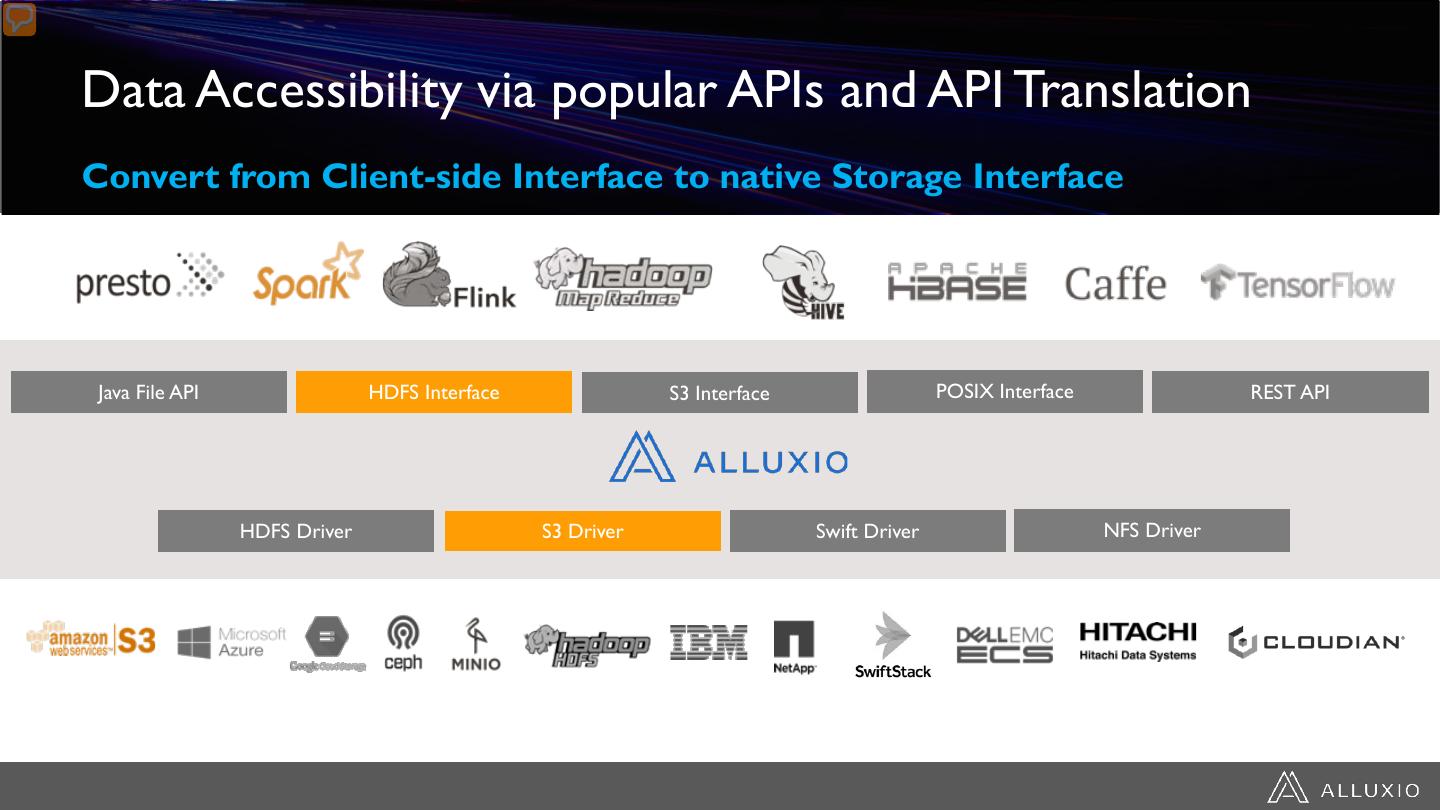
15 .Data Accessibility via popular APIs and API Translation Convert from Client-side Interface to native Storage Interface Java File API HDFS Interface S3 Interface POSIX Interface REST API HDFS Driver S3 Driver Swift Driver NFS Driver
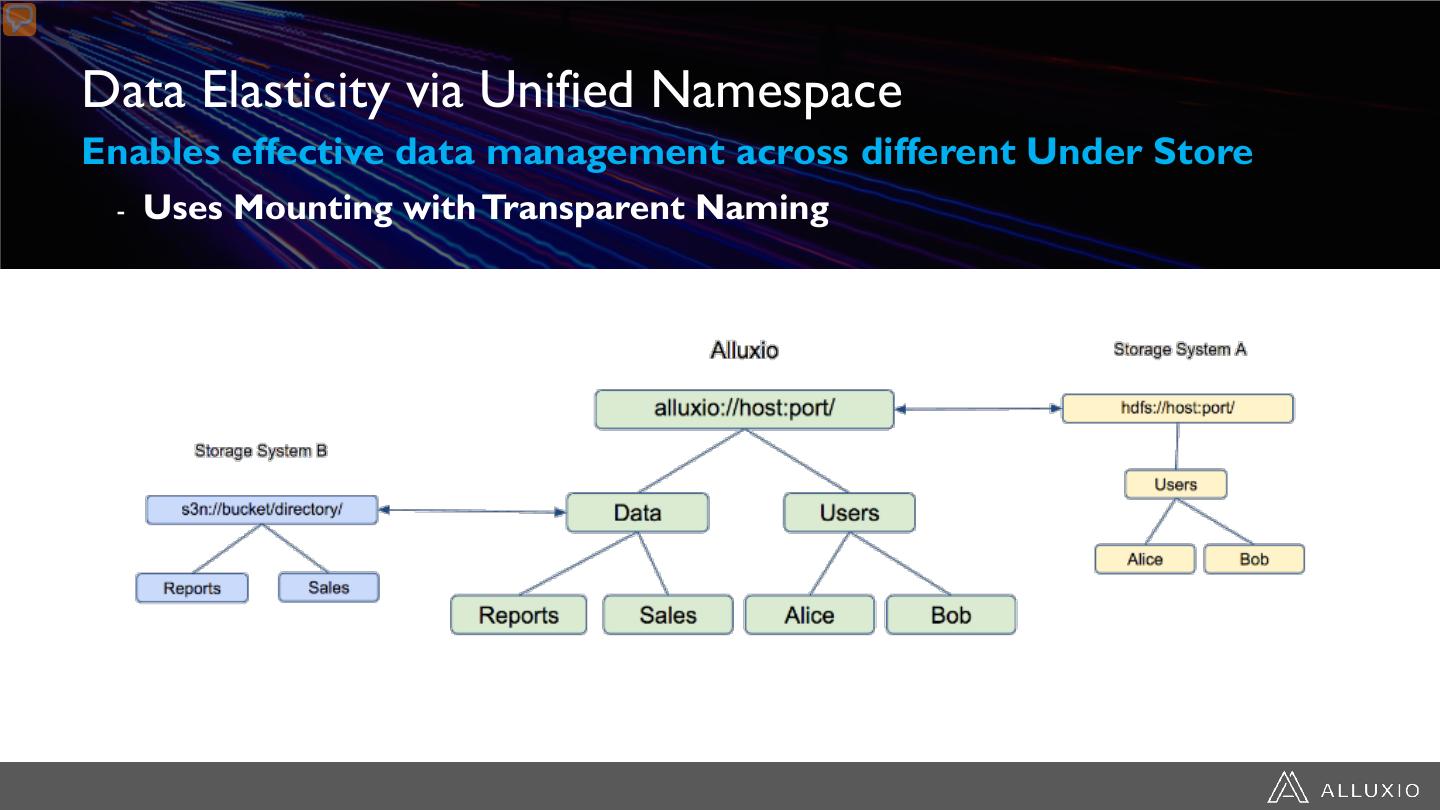
16 .Data Elasticity via Unified Namespace Enables effective data management across different Under Store - Uses Mounting with Transparent Naming
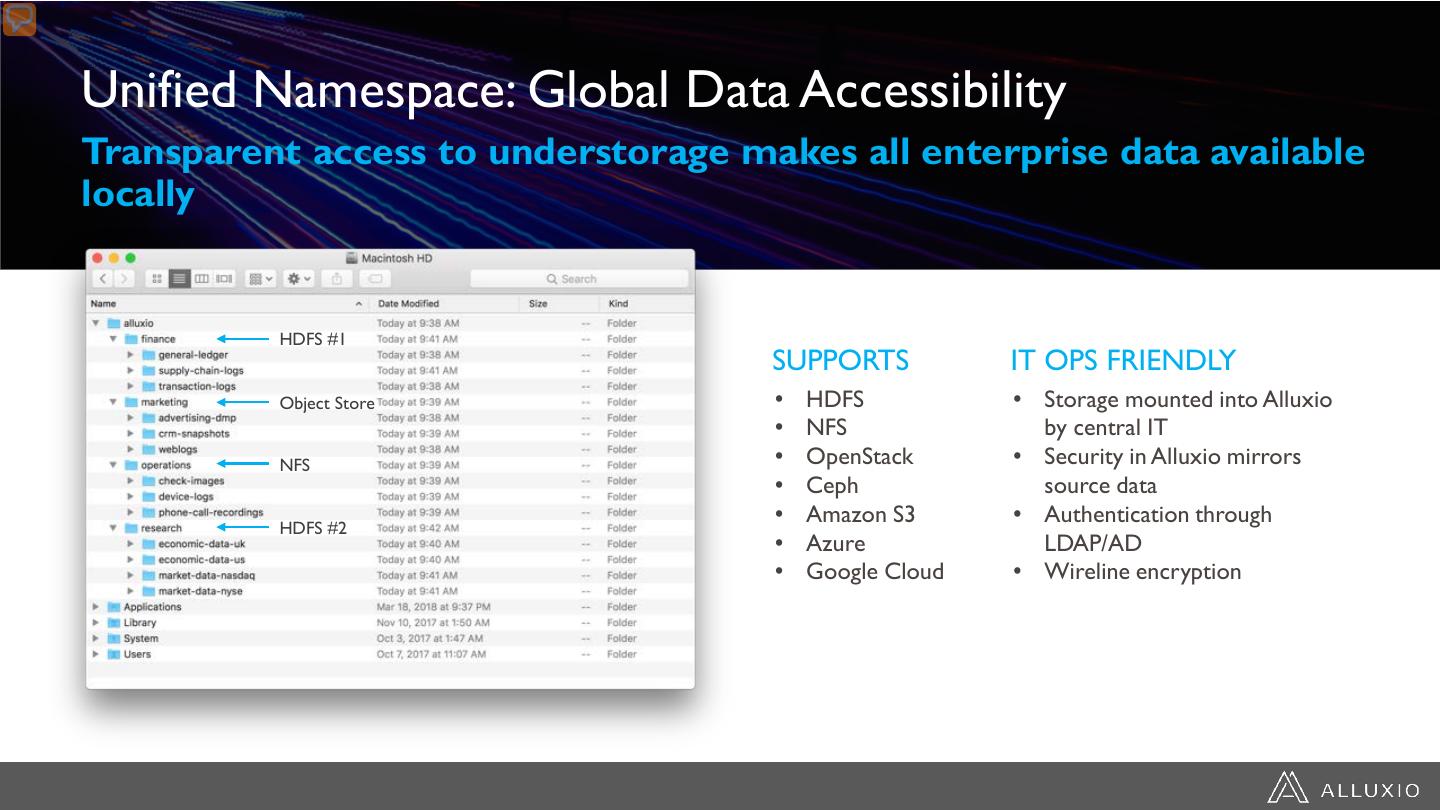
17 .Unified Namespace: Global Data Accessibility Transparent access to understorage makes all enterprise data available locally HDFS #1 SUPPORTS IT OPS FRIENDLY Object Store • HDFS • Storage mounted into Alluxio • NFS by central IT NFS • OpenStack • Security in Alluxio mirrors • Ceph source data • Amazon S3 • Authentication through HDFS #2 • Azure LDAP/AD • Google Cloud • Wireline encryption
18 .Alluxio Reference Architecture WAN Alluxio Alluxio Worker Client RAM / SSD / HDD Application Under Store 1 Alluxio Alluxio Client Worker Application RAM / SSD / HDD Under Store 2 Alluxio Zookeeper Master / RAFT Standby Master
19 .Why of contributing to Alluxio Deep in Alluxio, it can give you more A international Code Review process, improve your code style and skill. With great power comes great responsibility. Platform to show your skill and talent. Honour and enjoy to join and contribute your code to open-source community, your code could be used everywhere of the world Wine a better offer, gain more salary.
20 .Why you are not here No Bandwith. 996 or 007 —— Save your split time Poor English —— Communicate with others on line. Read and write documents in English Reply slow, lots of review comments, modified again and again —— More patience make you better Lack of the culture of open source —— So bring it to your team. Develop a branch as a private repository, hard to feedback ——Come back from dead way
21 .Welcome to the Alluxio Community! Prerequisites Java 8 Maven Git GitHub账户 Forking the Alluxio Repository Building Alluxio Taking a New Contributor Task Video Run Alluxio https://docs.alluxio.io/os/user/edge/cn/contributor/Contributor-Getting-Started.html
22 .Next steps - Try it out! • Getting Started • Try 10 Minutes Alluxio & Presto Tutorial on Laptop • Try 10 Minutes Alluxio & Presto Tutorial on AWS • Spark and Alluxio in 5 minutes • Tops 5 Performance tips running Presto on Alluxio Questions or Suggestions? Engage with our Community in Slack!
23 .Coming in 2.1 Release A Presto-Alluxio Connector Iceberg Integration to serve metadata of tables File System Wrapper to Support Transparent URI Insert Alluxio as a caching layer without touching HMS Details: https://github.com/Alluxio/alluxio/issues/9231 Cloud Integration: AMIs
24 .Two Sigma Fastest growing big hedge fund managing $46 billion for investors Use case | Cloud bursting on-premise data SPARK SPARK Public Cloud Public Cloud HDFS HDFS Compute scales elastically independent of storage Faster time to insights with seamless data orchestration Accelerated workloads with memory-first data approach
25 .Bazaarvoice Leading Digital marketing Company in Austin Use Case | Compute Caching for Cloud Hive Hive Alluxio AWS S3 AWS S3 Cache hot data in Alluxio, keep all data in S3 Faster time to insights with seamless data orchestration Accelerated workloads with memory-first data approach by 10x https://www.alluxio.io/blog/accelerate-spark-and-hive-jobs- on-aws-s3-by-10x-with-alluxio-tiered-storage/
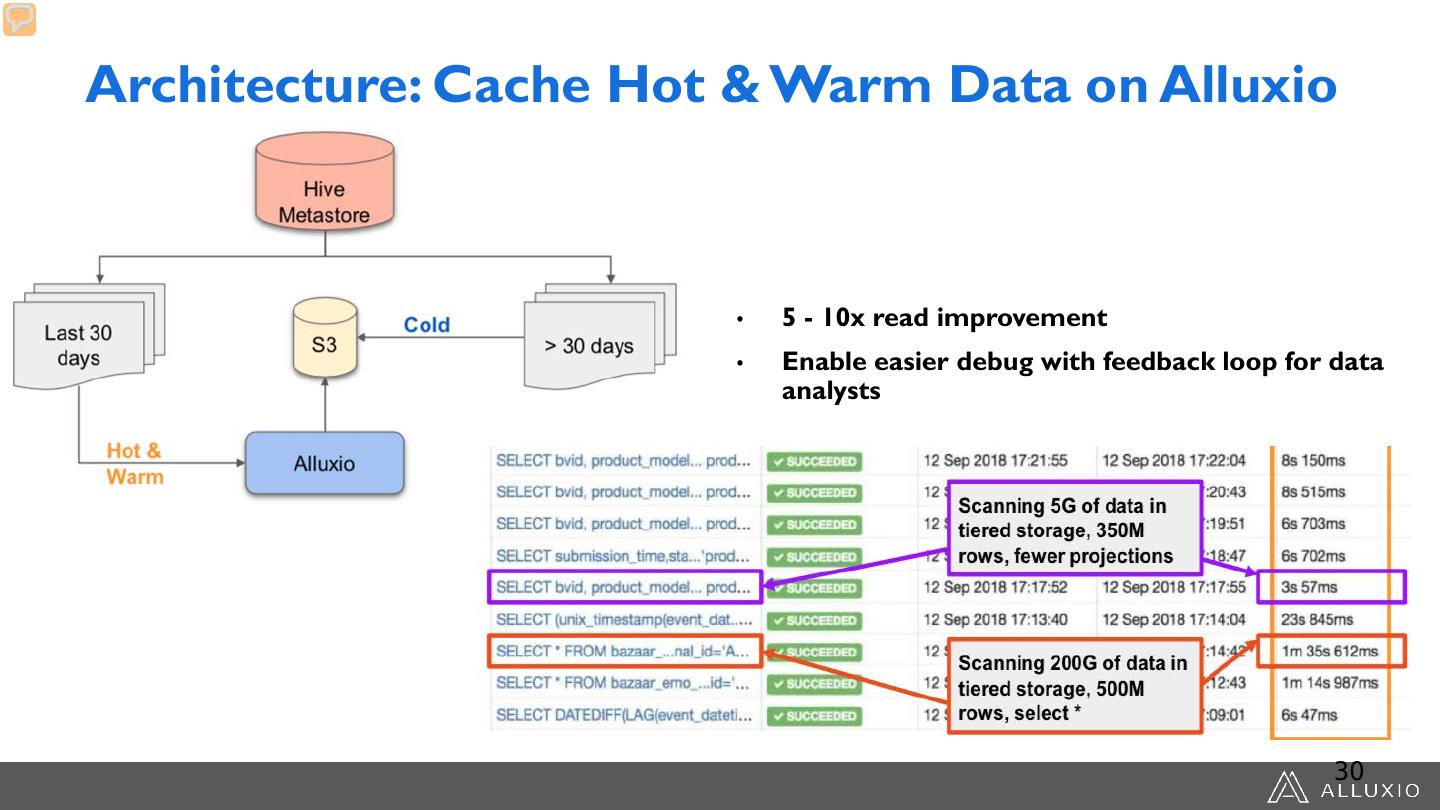
26 .Architecture: Cache Hot & Warm Data on Alluxio • 5 - 10x read improvement • Enable easier debug with feedback loop for data analysts 30
27 .JD.com Leading Online Retailer in China Use Case | On-premise Satellite Cluster for Presto SPARK Presto SPARK Presto Alluxio HDFS HDFS Presto workers may read remotely from HDFS datanodes -> large query variance Data local to Presto accelerates workloads https://www.slideshare.net/Alluxio/alluxio-in-jd
28 .Architecture: Colocate Alluxio with Presto 32
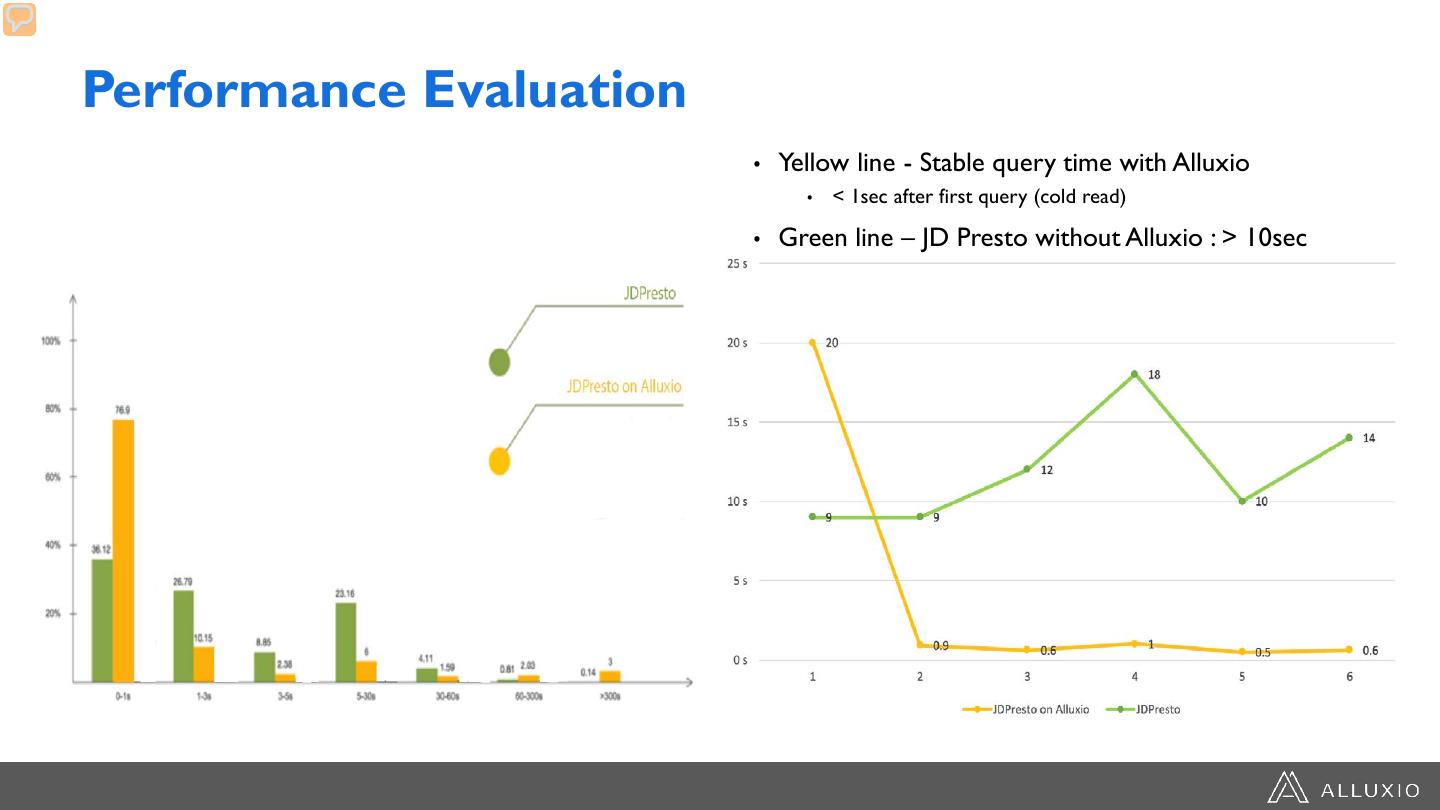
29 .Performance Evaluation • Yellow line - Stable query time with Alluxio • < 1sec after first query (cold read) • Green line – JD Presto without Alluxio : > 10sec
3秒后跳转登录页面
去登陆

