展开查看详情
1 . LUYANG WANG Restaurant Brands International
KAI HUANG Intel Corporation
Ray Summit 2021 #RaySummit
�
2 . Agenda
LUYANG WANG
▪ Food recommendation use case
▪ Transformer Cross Transformer Recommender
KAI HUANG
▪ AI on big data
▪ Distributed training pipeline with Ray on Apache Spark
Ray Summit 2021 #RaySummit
�
3 . Fast Food Recommendation Use Case
Ray Summit 2021 #RaySummit
�
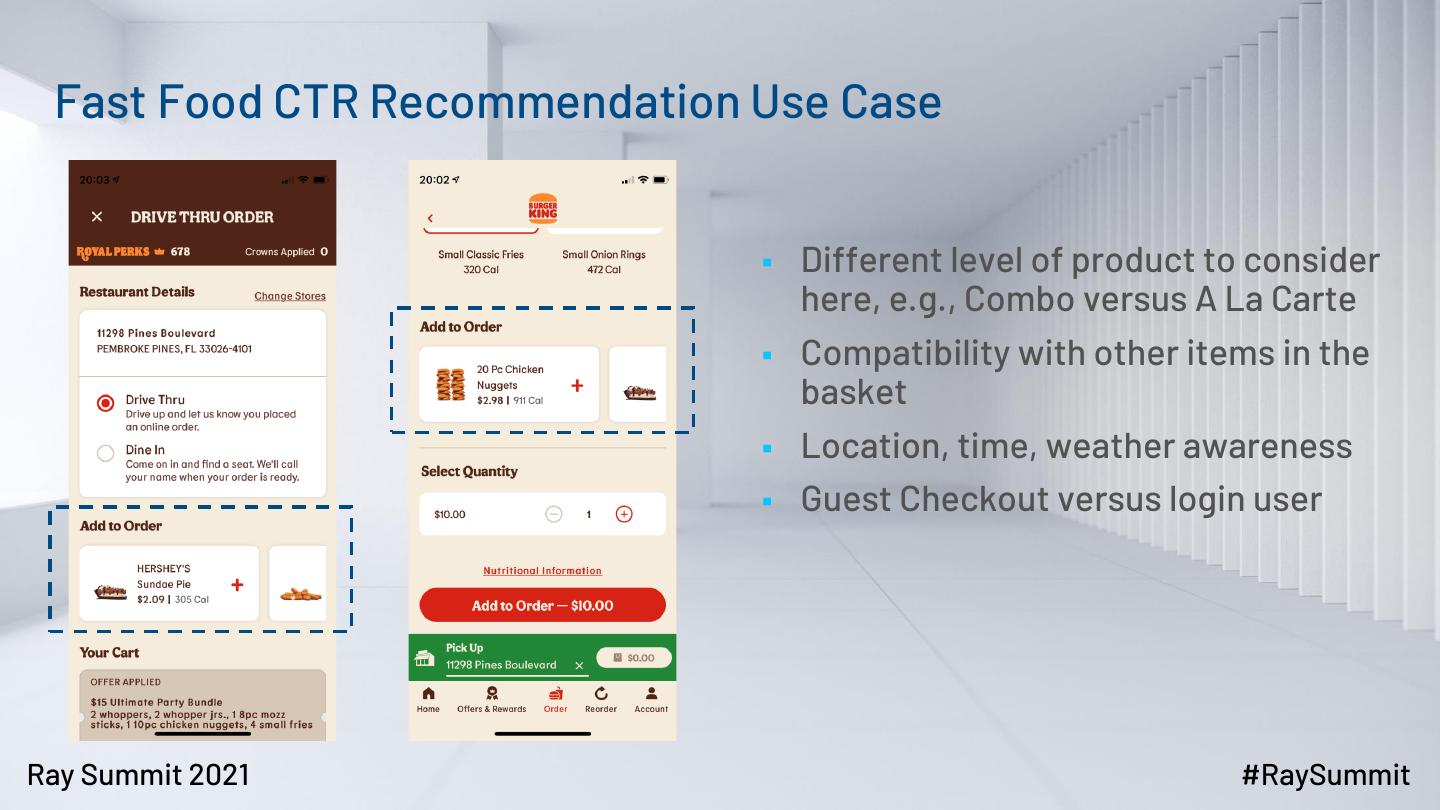
4 . Fast Food CTR Recommendation Use Case
▪ Different level of product to consider
here, e.g., Combo versus A La Carte
▪ Compatibility with other items in the
basket
▪ Location, time, weather awareness
▪ Guest Checkout versus login user
Ray Summit 2021 #RaySummit
�
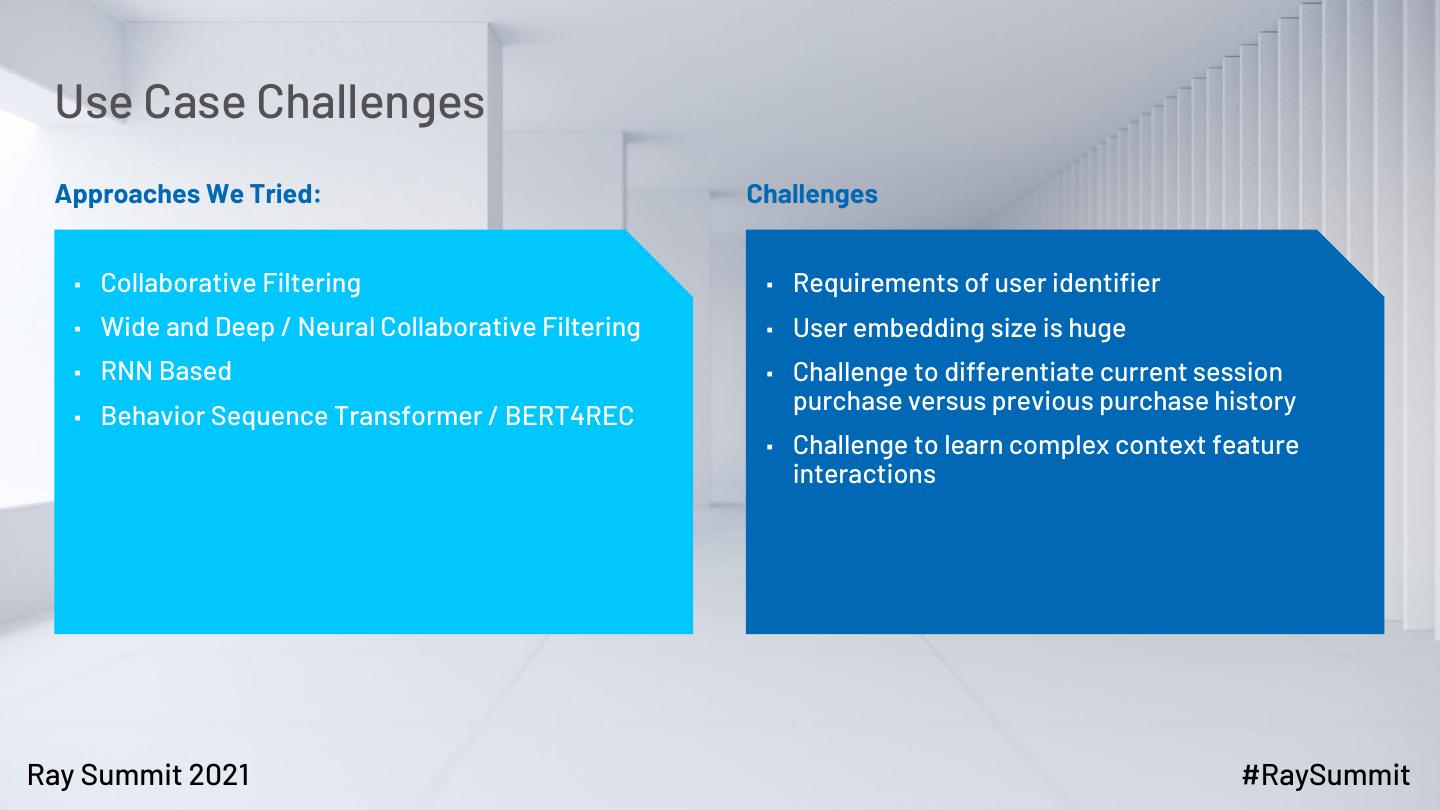
5 . Use Case Challenges
Approaches We Tried: Challenges
▪ Collaborative Filtering ▪ Requirements of user identifier
▪ Wide and Deep / Neural Collaborative Filtering ▪ User embedding size is huge
▪ RNN Based ▪ Challenge to differentiate current session
purchase versus previous purchase history
▪ Behavior Sequence Transformer / BERT4REC
▪ Challenge to learn complex context feature
interactions
Ray Summit 2021 #RaySummit
�
6 . Transformer Cross Transformer Recommender
Ray Summit 2021 #RaySummit
�
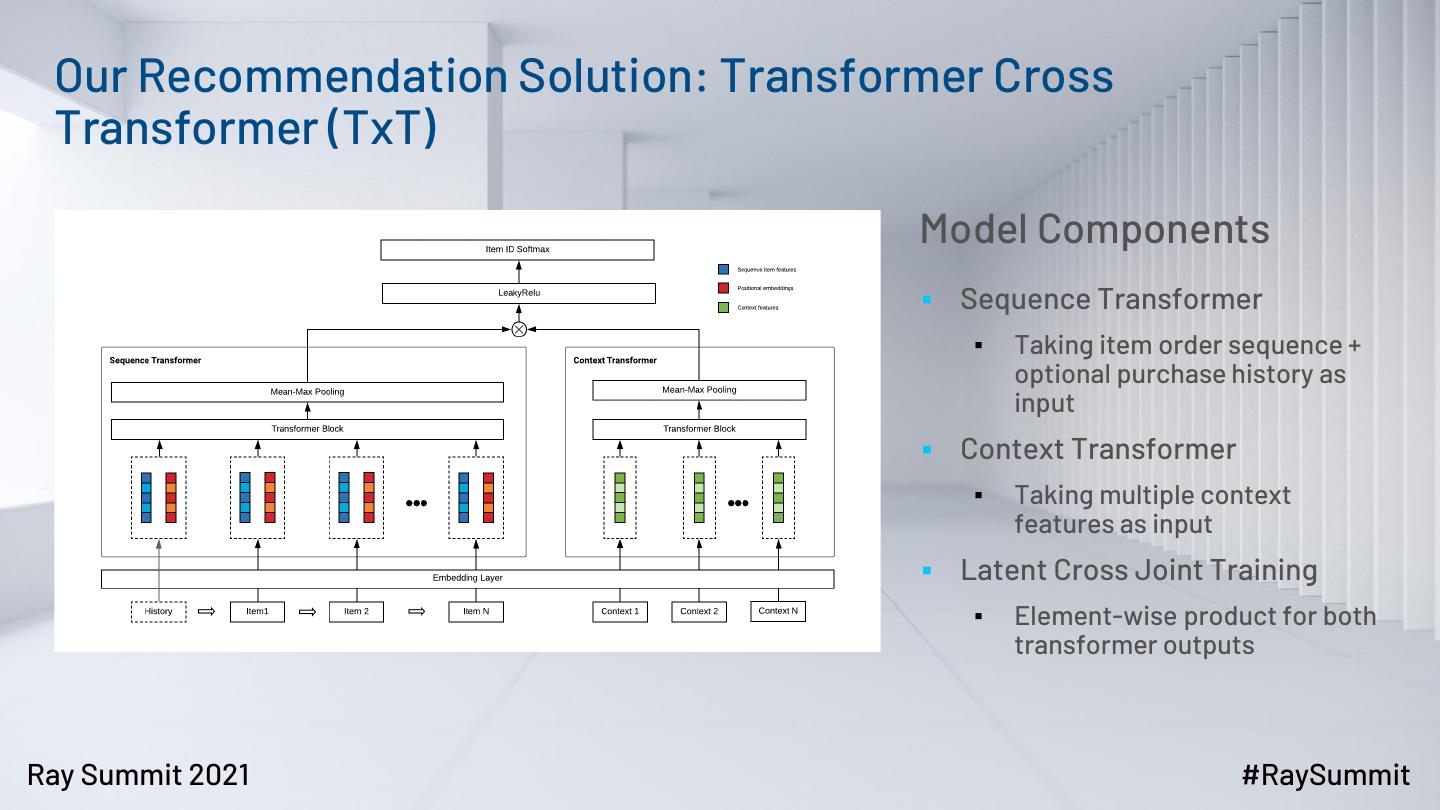
7 . Our Recommendation Solution: Transformer Cross
Transformer (TxT)
Model Components
▪ Sequence Transformer
▪ Taking item order sequence +
optional purchase history as
input
▪ Context Transformer
▪ Taking multiple context
features as input
▪ Latent Cross Joint Training
▪ Element-wise product for both
transformer outputs
Ray Summit 2021 #RaySummit
�
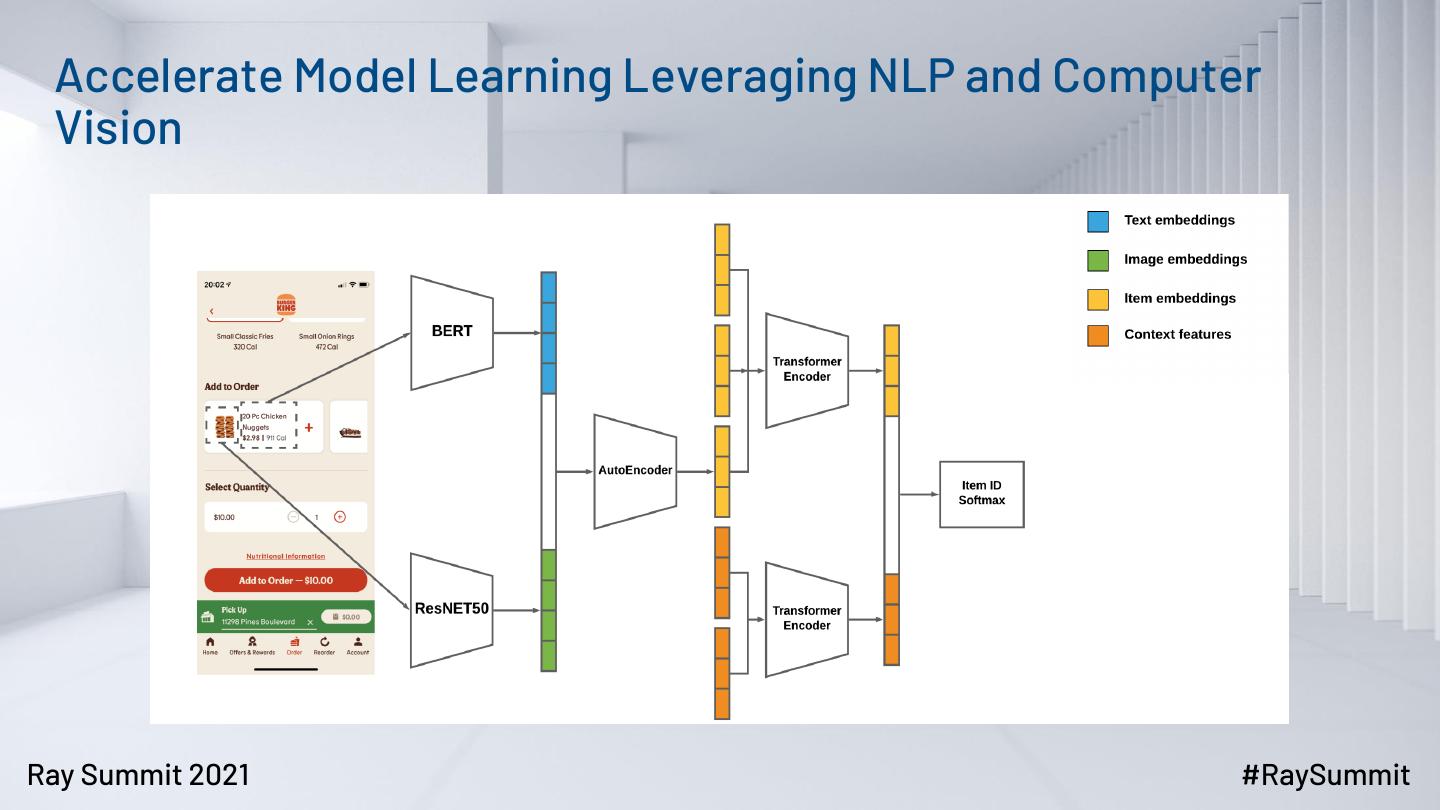
8 . Accelerate Model Learning Leveraging NLP and Computer
Vision
Ray Summit 2021 #RaySummit
�
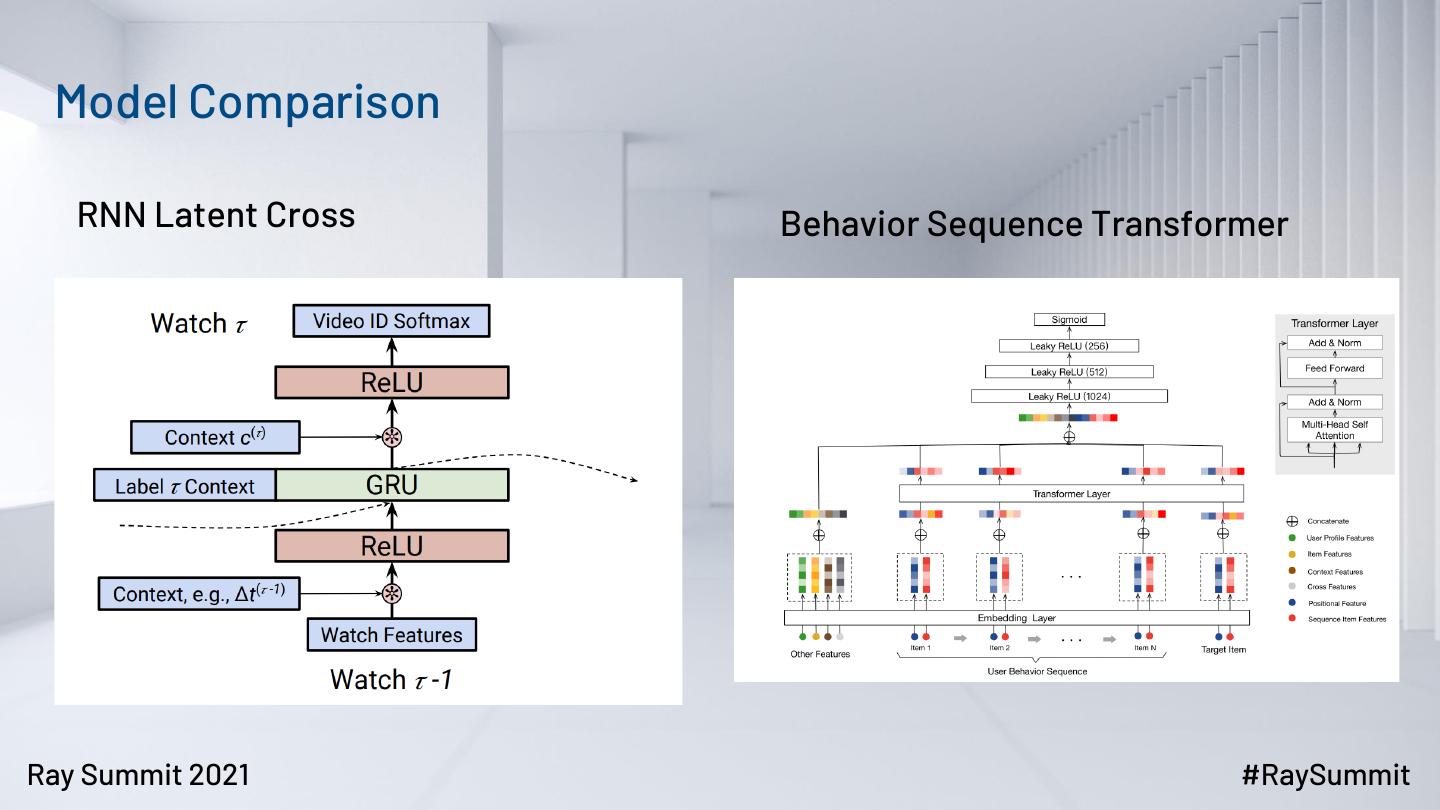
9 . Model Comparison
RNN Latent Cross Behavior Sequence Transformer
Ray Summit 2021 #RaySummit
�
10 . Performance Comparison
Inference Performance A/B Testing Performance
Inference Latency (ms) Model Conversation Rate Add-on Sales Gain
25 Gain
20
20 18
RNN Latent Cross - -
15 (control)
10
TxT +7.5% +4.7%
5
0
RNN Latent Cross TxT
Inference Latency (ms)
Ray Summit 2021 #RaySummit
�
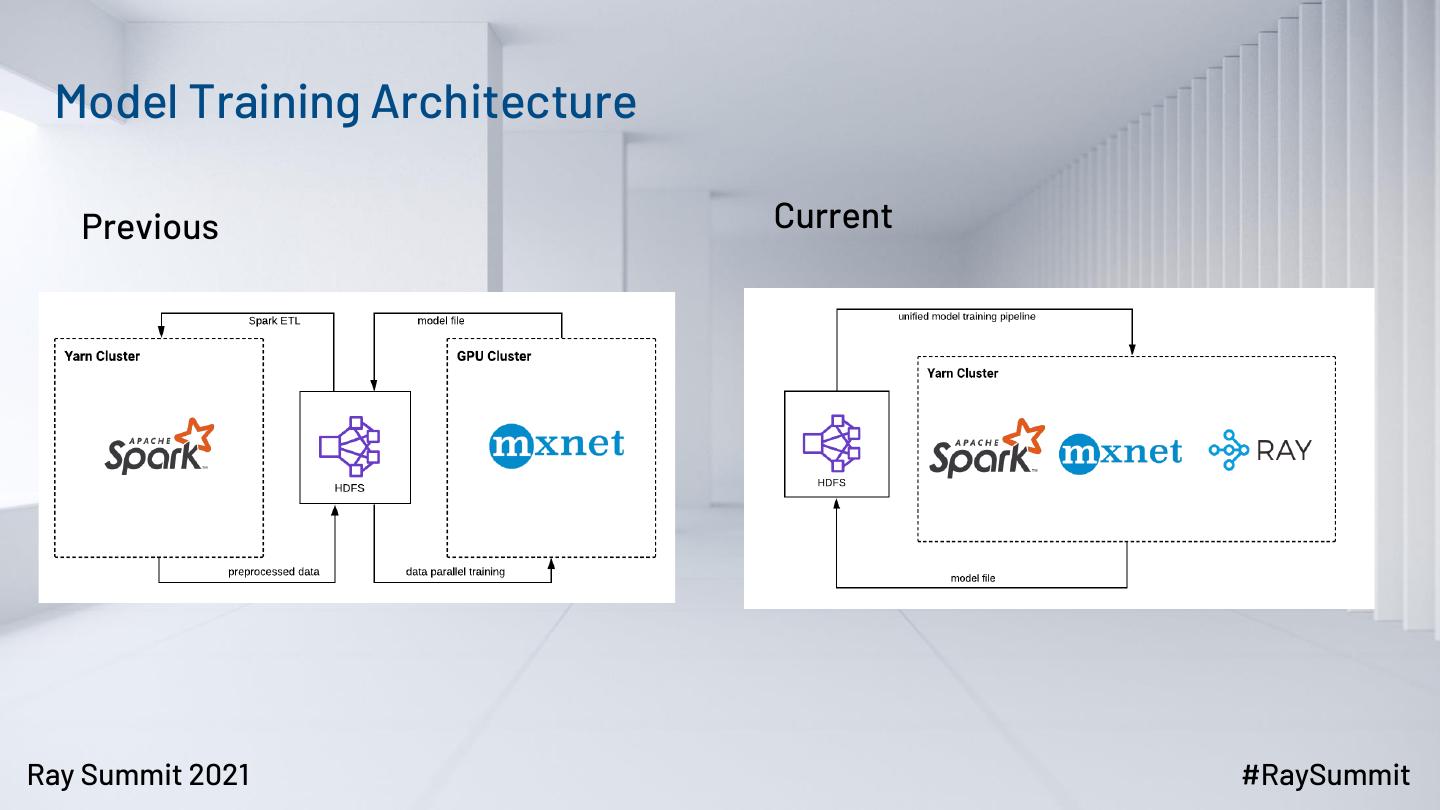
11 . Model Training Architecture
Previous Current
▪ Previous
Ray Summit 2021 #RaySummit
�
12 . AI on Big Data
Ray Summit 2021 #RaySummit
�
13 . AI on Big Data
Distributed, High-Performance Unified Analytics + AI Platform
Deep Learning Framework for distributed TensorFlow*, Keras*, PyTorch*
for Apache Spark* and BigDL on Apache Spark* and Ray
https://github.com/intel-analytics/bigdl https://github.com/intel-analytics/analytics-zoo
Accelerating Data Analytics + AI Solutions At Scale
Ray Summit 2021 #RaySummit
�
14 . Analytics Zoo: Software Platform for Big Data AI
Scaling End-to-End AI Pipelines to Distributed Big Data
PPML Privacy Preserving Data Analytics & ML on SGX
Cluster
Distributed real-time model serving on Flink
Serving
Zouwu Scalable time series analysis pipeline w/ AutoML
Orca Seamlessly scale out TF & PyTorch on Spark & Ray
RayOnSpark Run Ray programs directly on Big Data platform
Laptop K8s Cluster Hadoop Cluster Cloud
DL Frameworks Distributed Analytics Python Libraries
(TF/PyTorch/BigDL/OpenVINO/…) (Spark/Flink/Ray/…) (Numpy/Pandas/sklearn/…)
Powered by oneAPI
https://github.com/intel-analytics/analytics-zoo
Ray Summit 2021 #RaySummit
�
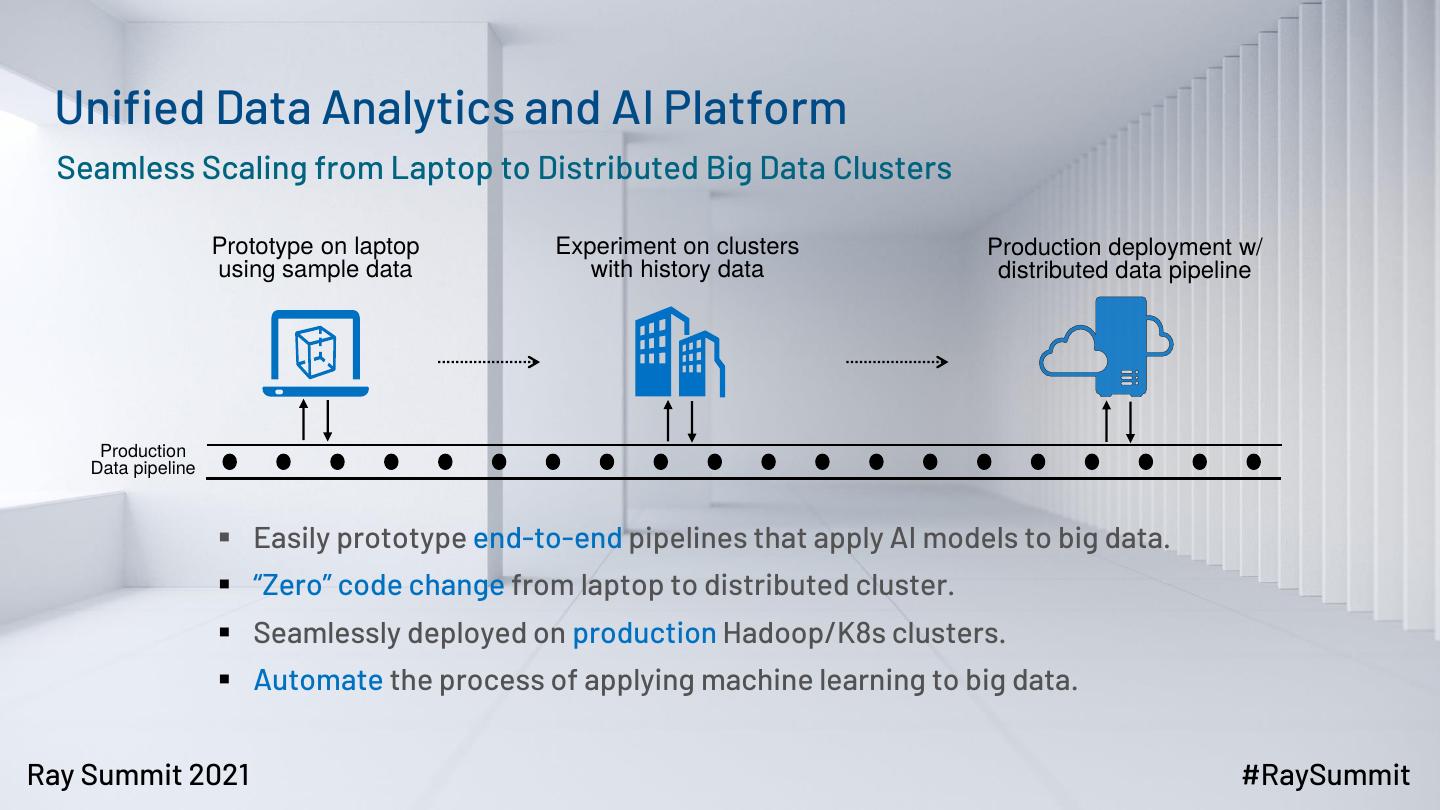
15 . Unified Data Analytics and AI Platform
Seamless Scaling from Laptop to Distributed Big Data Clusters
Prototype on laptop Experiment on clusters Production deployment w/
using sample data with history data distributed data pipeline
Production
Data pipeline
▪ Easily prototype end-to-end pipelines that apply AI models to big data.
▪ “Zero” code change from laptop to distributed cluster.
▪ Seamlessly deployed on production Hadoop/K8s clusters.
▪ Automate the process of applying machine learning to big data.
Ray Summit 2021 #RaySummit
�
16 . Motivations for RayOnSpark
▪ Efforts required to directly deploy Ray applications on existing Hadoop/Spark clusters.
▪ Challenge to prepare the Python environment on each node without modifying the cluster.
▪ Need a unified system for big data analytics and Ray applications.
Ray Summit 2021 #RaySummit
�
17 . Distributed Training Pipeline with RayOnSpark
Ray Summit 2021 #RaySummit
�
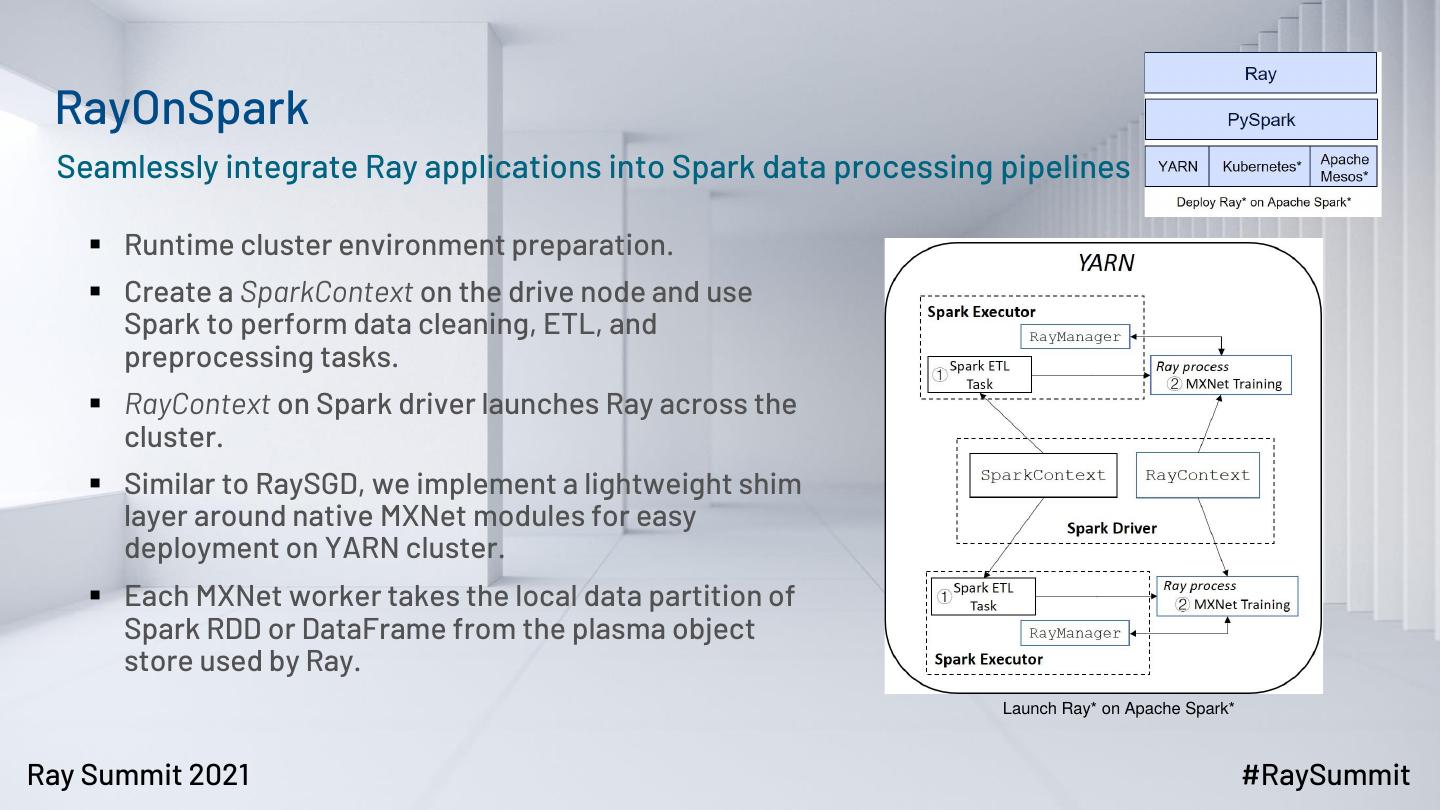
18 . RayOnSpark
Seamlessly integrate Ray applications into Spark data processing pipelines
▪ Runtime cluster environment preparation.
▪ Create a SparkContext on the drive node and use
Spark to perform data cleaning, ETL, and
preprocessing tasks.
▪ RayContext on Spark driver launches Ray across the
cluster.
▪ Similar to RaySGD, we implement a lightweight shim
layer around native MXNet modules for easy
deployment on YARN cluster.
▪ Each MXNet worker takes the local data partition of
Spark RDD or DataFrame from the plasma object
store used by Ray.
Launch Ray* on Apache Spark*
Ray Summit 2021 #RaySummit
�
19 . End-to-end Distributed Training Pipeline
Project Orca provides a user-friendly interface for the pipeline.
▪ Minimum code changes and learning efforts are needed to scale the training from single node
to big data clusters.
▪ The entire pipeline runs on a single cluster. No extra data transfer needed.
Import mxnet as mx
from zoo.orca import init_orca_context
from zoo.orca.learn.mxnet import Estimator
# init_orca_context unifies SparkContext and RayContext
sc = init_orca_context(cluster_mode="yarn", num_nodes, cores, memory)
# Use sc to load data and do data preprocessing.
mxnet_estimator = Estimator(train_config, model=txt, loss=SoftmaxCrossEntropyLoss(),
metrics=[mx.metric.Accuracy(), mx.metric.TopKAccuracy(3)])
mxnet_estimator.fit(data=train_rdd, validation_data=val_rdd, epochs=…, batch_size=…)
Ray Summit 2021 #RaySummit
�
20 . Conclusion
▪ Context-Aware Fast Food Recommendation at Burger King with RayOnSpark
https://arxiv.org/abs/2010.06197
https://medium.com/riselab/context-aware-fast-food-recommendation-at-burger-king-with-
rayonspark-2e7a6009dd2d
▪ For more details of RayOnSpark:
https://analytics-zoo.readthedocs.io/en/latest/doc/Ray/QuickStart/ray-quickstart.html
https://medium.com/riselab/rayonspark-running-emerging-ai-applications-on-big-data-clusters-
with-ray-and-analytics-zoo-923e0136ed6a
▪ More information for Analytics Zoo at:
https://github.com/intel-analytics/analytics-zoo
https://analytics-zoo.readthedocs.io/
Ray Summit 2021 #RaySummit
�
21 . Thank you
Ray Summit 2021 #RaySummit
�