展开查看详情
1 .Experimenting with Text Classification Algorithms in News Articles: SVM vs. Naive Bayesian Algorithm Nuhi BESIMI, Adrian BESIMI, Visar SHEHU DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj , Slovenia 1
2 .Collected Data Data Pre-processing The Naïve Bayes Classifier SVM (Support Vector Machine) Experiment and Evaluation Accuracy Execution Time Future work Content DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 2
3 .Sources: CNET – http://cnet.com PCWorld – http://pcworld.com TechCrunch – http://techcrunch.com NyTimes – http://nytimes.com Goal – http://goal.com Categories Politics Technology Sports Collected Data DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 3
4 .Collected Data (summary) Politics News Articles Technology News Articles Sports News Articles Total Training Data 200 (80 %) 345 (80 %) 409 (80 %) 954 Testing Data 49 (20 %) 86 (20 %) 102 (20 %) 237 Total 249 431 511 1191 CNET PCWorld TechCrunch NyTimes Goal Number of collected documents (news articles) 81 229 121 570 190 DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 4
5 .Data Cleaning: Stop-word removal Stemming (Porter Algorithm) Low term frequency filtering (count < 3) Data Transformation: Bag of words model (vector representation) Data Pre-processing DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 5
6 .Eager Learners Naïve Bayes Classifier SVM (Support Vector Machine) Classification Techniques DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 6
7 .Experiment and Evaluation Testing the accuracy of the classifiers (Total news articles: 237) Classification Techniques Algorithm Naïve Bayes SVM Correctly classified documents 217 178 Accuracy in % 91.5 % 75.1 % DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 7
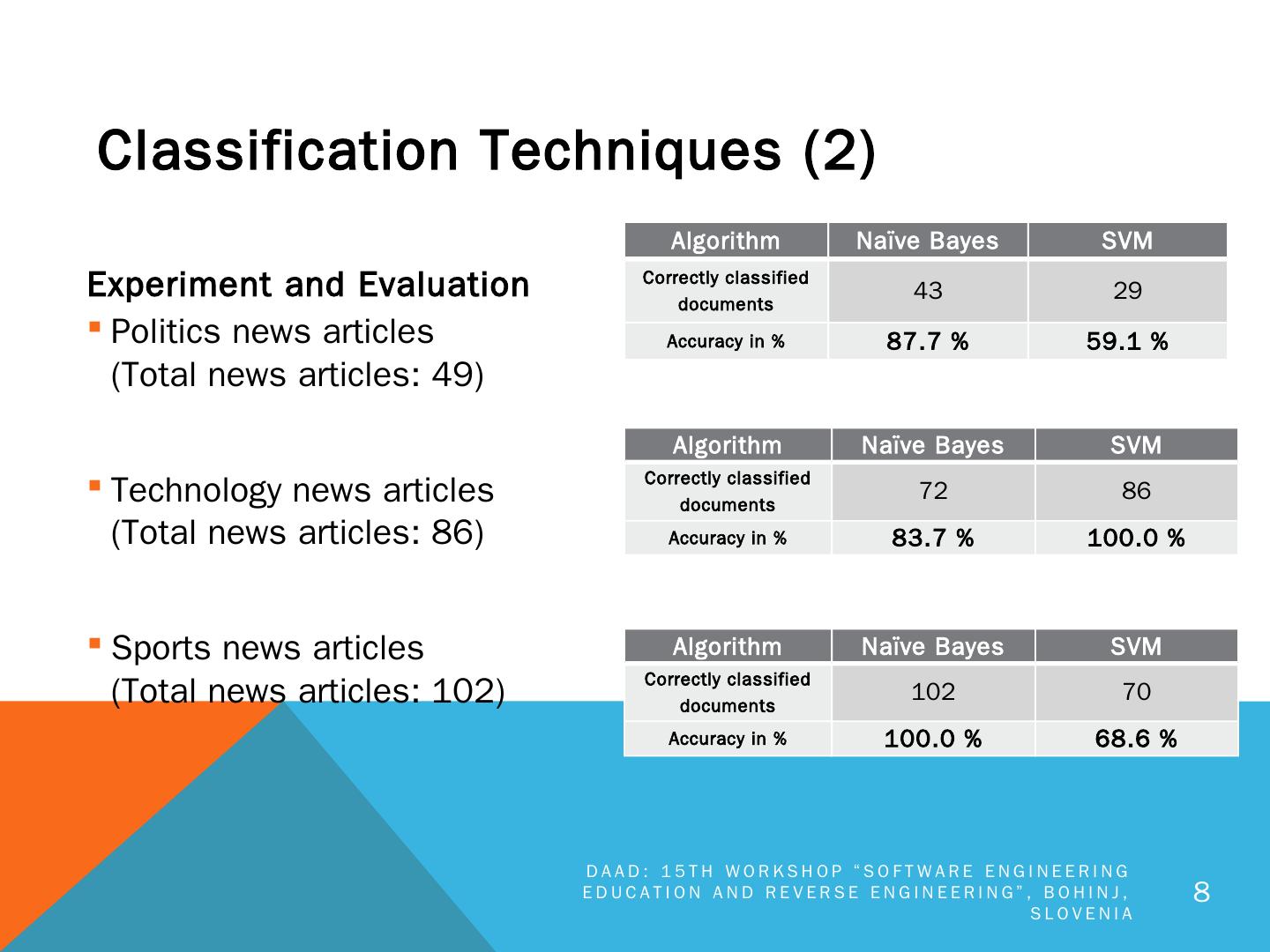
8 .Experiment and Evaluation Politics news articles (Total news articles: 49) Technology news articles (Total news articles: 86) Sports news articles (Total news articles: 102) Classification Techniques (2) Algorithm Naïve Bayes SVM Correctly classified documents 43 29 Accuracy in % 87.7 % 59.1 % Algorithm Naïve Bayes SVM Correctly classified documents 72 86 Accuracy in % 83.7 % 100.0 % Algorithm Naïve Bayes SVM Correctly classified documents 102 70 Accuracy in % 100.0 % 68.6 % DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 8
9 .Testing SVM only two classes? (good in some cases) Execution time (in seconds) Experiment and Evaluation Politics & Technology Politics & Sports Technology & Sports Number of documents 135 151 188 Correctly classified documents 120 130 149 Accuracy in % 88.8 % 87.0 % 79.2 % Algorithm Naïve Bayes SVM Training phase (in seconds) 612 7 Testing phase (single text document) 1.5 <0.1 DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 9
10 .SVM (Support Vector Machine) Definitely the fastest classifier and faster training (100x faster training than Naïve Bayesian classifier) Works very good in large datasets Works better in two class problems Naïve Bayes Classifier Very accurate when the number of training instances is high enough Slower comparing to SVM Larger dataset… bigger problems Conclusion: the findings DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 10
11 .News Archive (way back machine?) Crawl & store news from various media in Macedonia Store the changes in the text (find the text differences) for a given time interval Get the content, not just RSS Create Screen shots Measure similarity (plagiarism) between news sources (cosine similarity) Visualize trends in news Use to verify the facts (Media Fact Checking Service in Macedonia) Financially supported by Metamorphosis Foundation & USAID (maybe) Future Work DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 11
12 .Questions? THANK YOU Experimenting with Text Classification Algorithms in News Articles: SVM vs. Naive Bayesian Algorithm Nuhi BESIMI, Adrian BESIMI, Visar SHEHU DAAD: 15th Workshop “Software Engineering Education and Reverse Engineering”, Bohinj, Slovenia 12