99 Problems but Databricks + Apache Spark Ain’t One
分享
点赞
1
收藏
2
下载 1
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
In this talk we will highlight lessons that we learned as we migrated ~100 analysts and engineers with little to no experience in big data from our Hive ecosystem into the Databricks unified analytics platform. Oh and we did it all with a small support team of one.
展开查看详情
1 .99 problems but Databricks
and Spark ain't one
Wesley Kerr, Riot Games
#DSSAIS20
�
2 .● Principal Data Scientist on
League of Legends
● Used to work at Google, Riot
Games, and Adknowledge
● Leona support main
�
6 .Players & Data
100+ million
500+ billion
32 petabytes
6
�
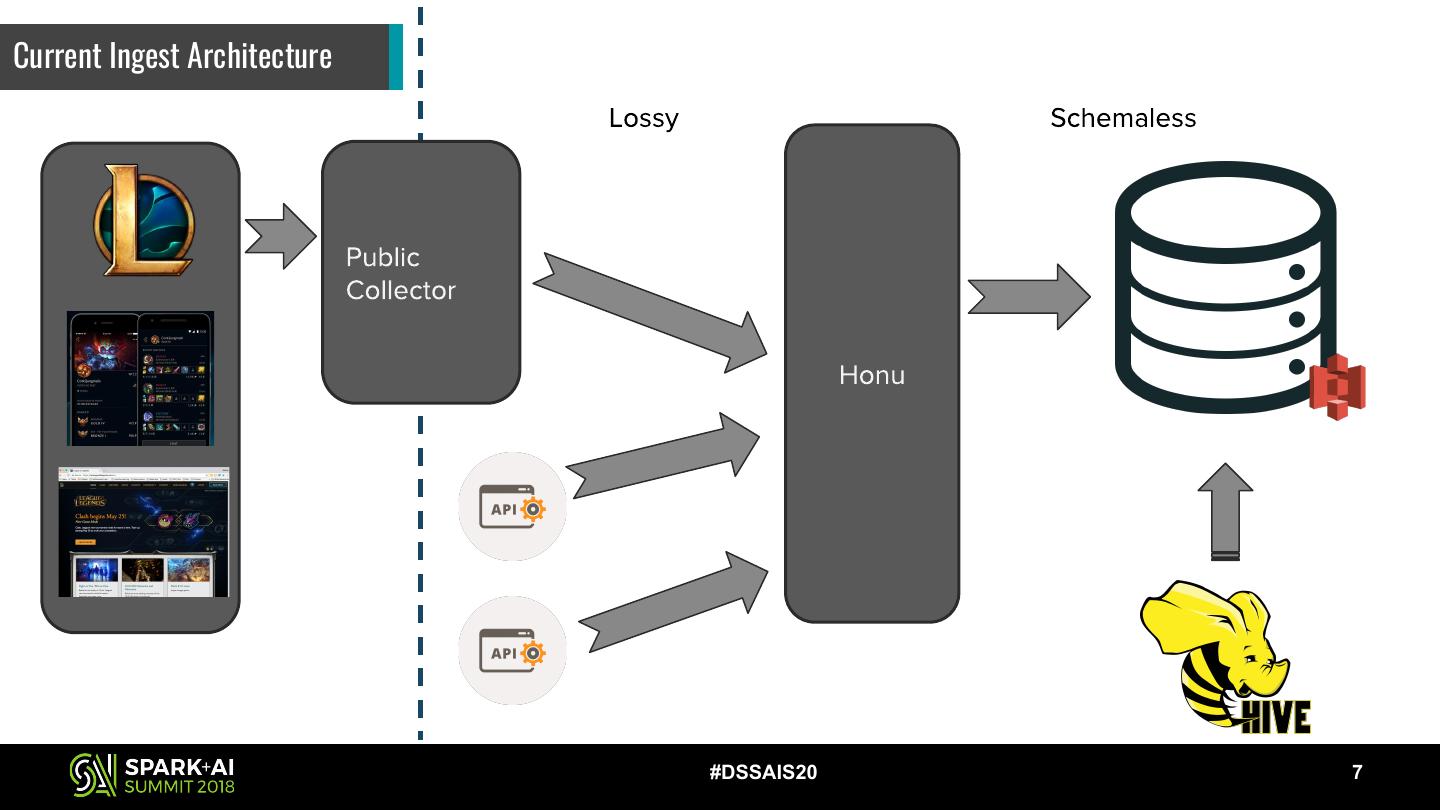
7 .Current Ingest Architecture
#DSSAIS20 7
�
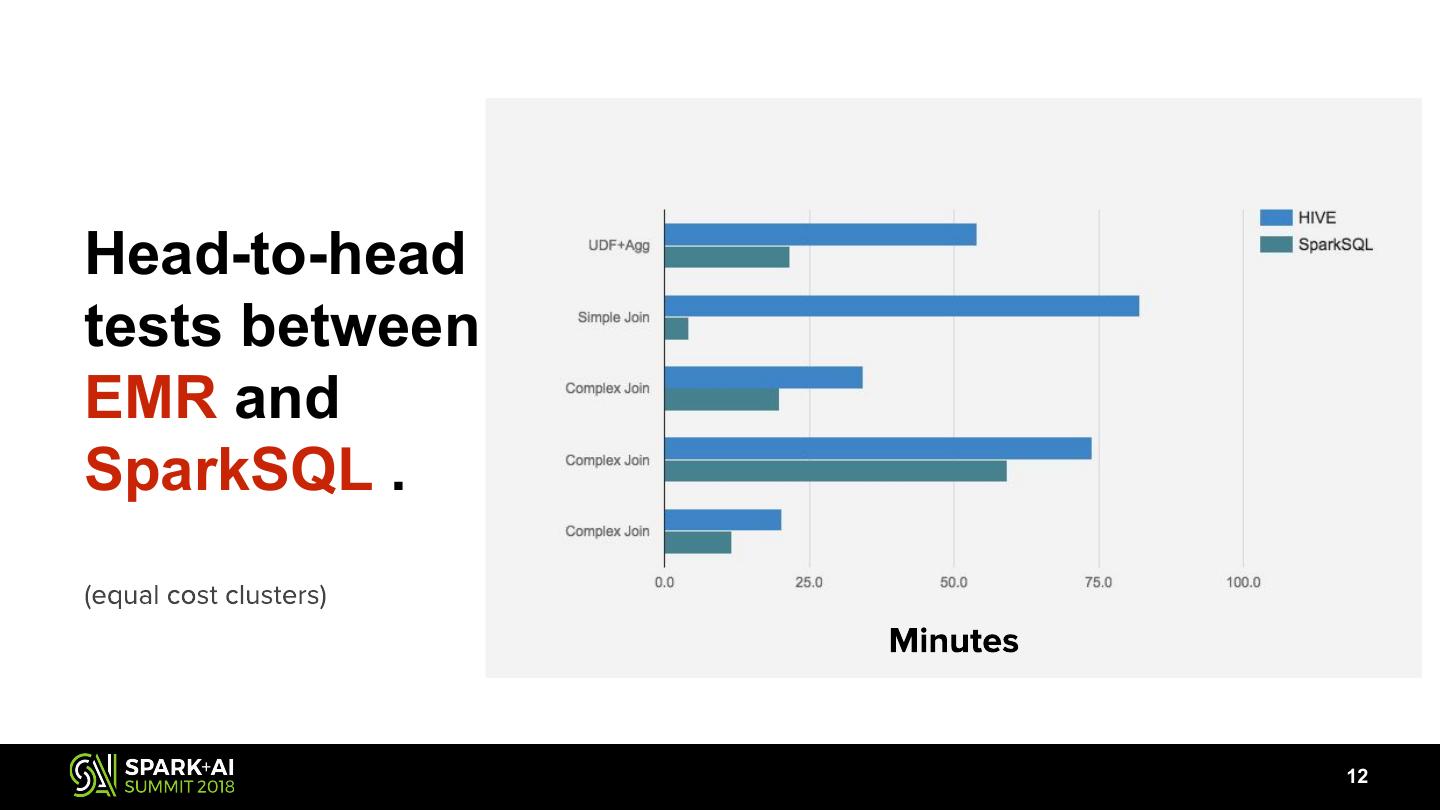
12 .Head-to-head
tests between
EMR and
SparkSQL .
12
�
13 .Personalized Offers
13
�
15 .Future Ingest Architecture
15
�
17 .Analysts’ Interactions
#DSSAIS20 17
�
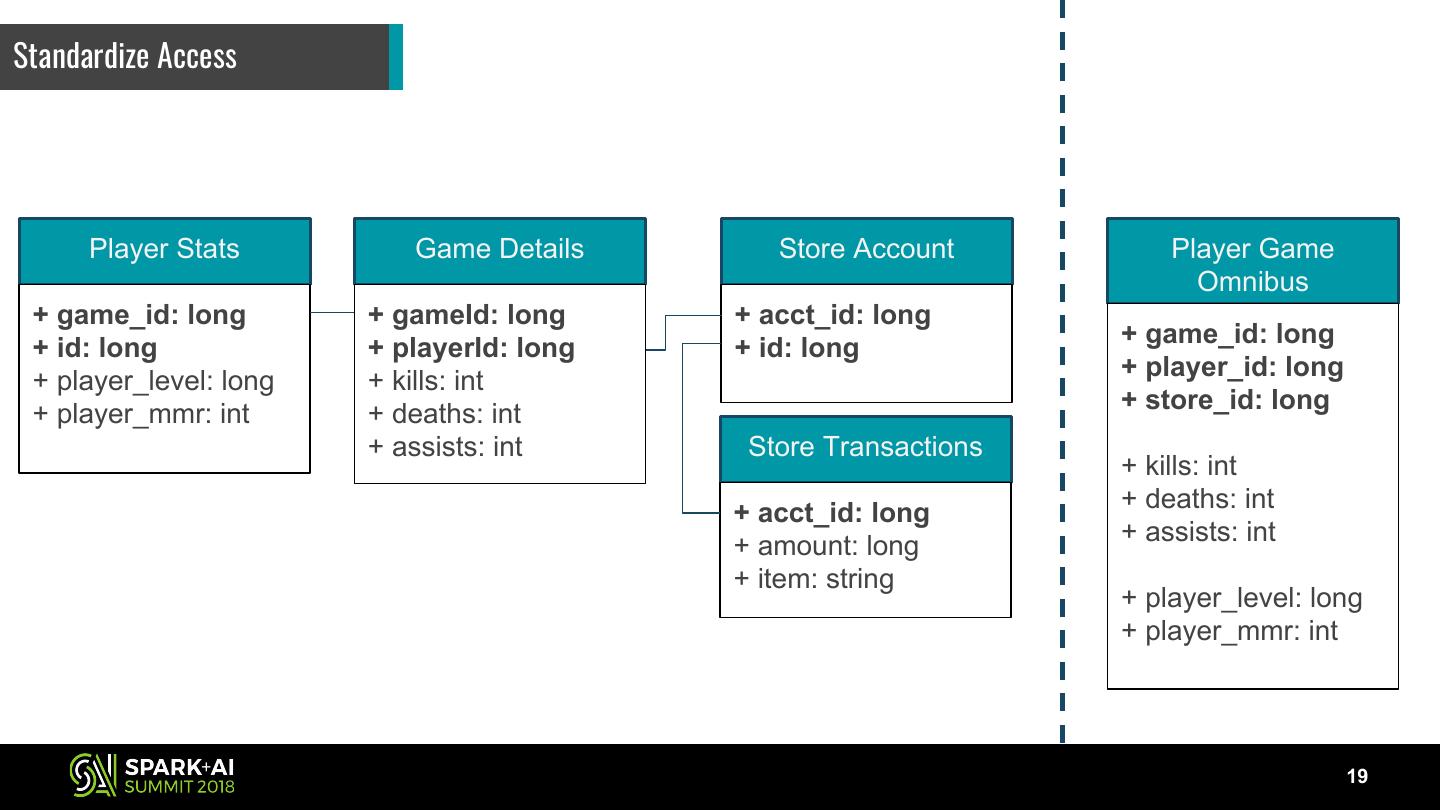
19 .Standardize Access
Player Stats Game Details Store Account Player Game
Omnibus
+ game_id: long + gameId: long + acct_id: long
+ game_id: long
+ id: long + playerId: long + id: long
+ player_id: long
+ player_level: long + kills: int
+ store_id: long
+ player_mmr: int + deaths: int
+ assists: int Store Transactions
+ kills: int
+ deaths: int
+ acct_id: long
+ assists: int
+ amount: long
+ item: string
+ player_level: long
+ player_mmr: int
19
�
20 .Be willing to experiment
20
�
25 .Foster a Community
25
�
26 . Thank you!
1. Standardize access
2. Be willing to experiment
3. Find a champion
4. Fix root causes
5. Be unblockable
6. Foster a community
#DSSAIS20 26
�