展开查看详情
1 .新浪微博 redis 优 化历程 陈波 @fishermen
2 .大纲 业务场 景 Redis 存储架 构演 进 一些经验 Q&A
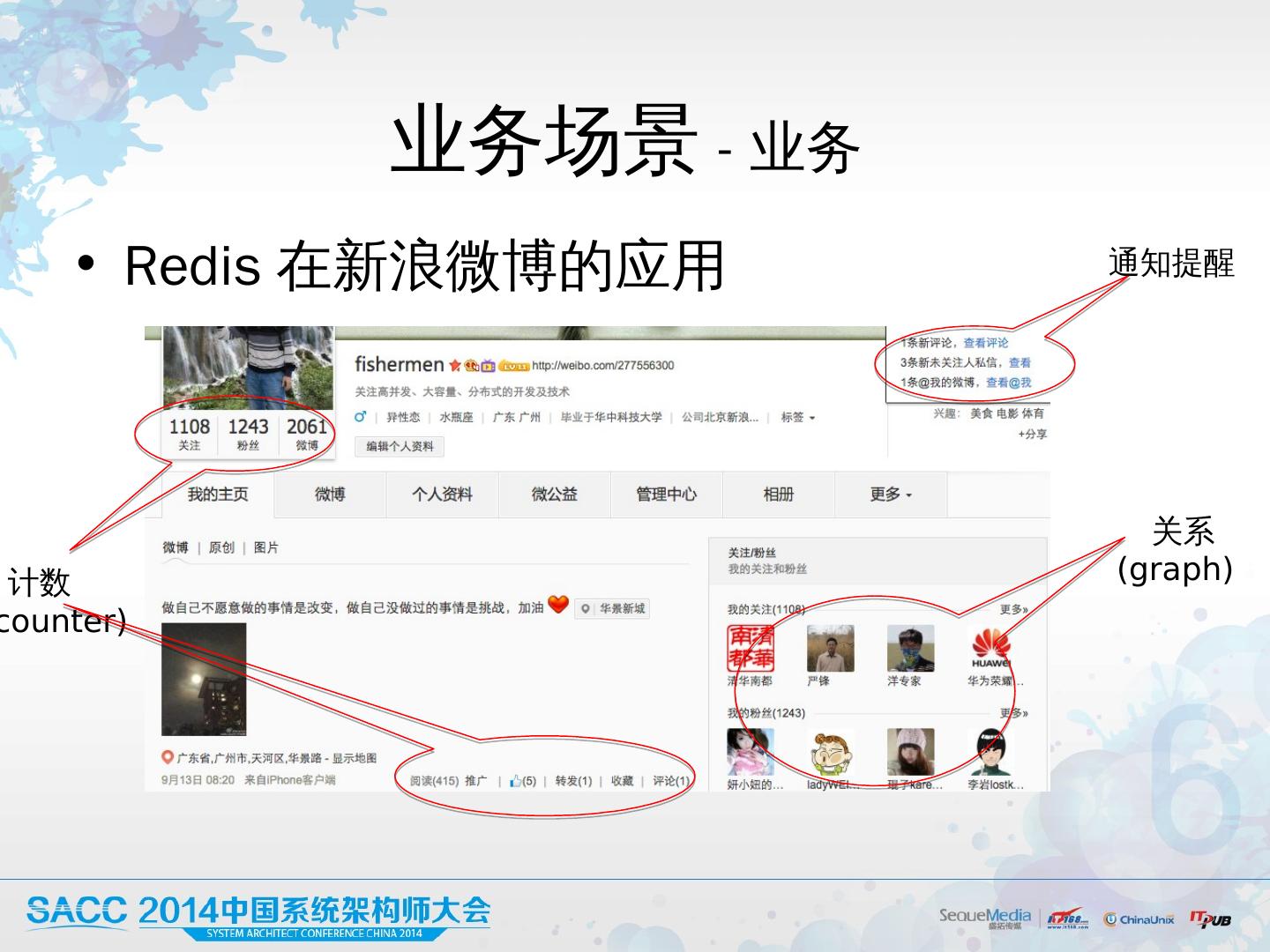
3 .业务场 景 - 业务 Redis 在新浪微 博的应 用 计数 ( counter) 关系 (graph) 通知提醒
4 .业务场景 - 数据 一些 数据 6 IDC 500+ servers 3700+ instances 千亿条记 录 24T+ 内存 7 千亿 cmds/ day 1.2 万亿 read/ day 2 千亿 write/day
6 .Redis 前时代 热数据 mc 全量落地 mysql 数据量不大 : Graph mc 10G,计数器 mc 2G 开发速度
7 .问题出现 2010 年, Graph mc 3 0G+ ,峰值 10wTPS Mysql 成为瓶颈 线程阻塞,访问卡顿 List 类型业务不适合 mysql 新的 关系计算 需求 实现困难 大量 关系 计算:从 MC 取全量 + 本地计算 -> 超时
8 .解决方案 初期方案 增大 mc 容量到 4 0G,Graph db 增至 一主六从 监控并及时清理僵死线程 关系计算性能问题暂时无解 最终方案 引入 Redis 做 storage (graph/counter) 关系 计算 在redis实现 O(1) 促进更 多复杂需 求 Graph db 恢复一主三从
9 .小结 项目初期 3 0G - 日PV5kw - 技 术 选 型 熟悉 度 拼 的是开发速 度 产品需求与新技术相互促进
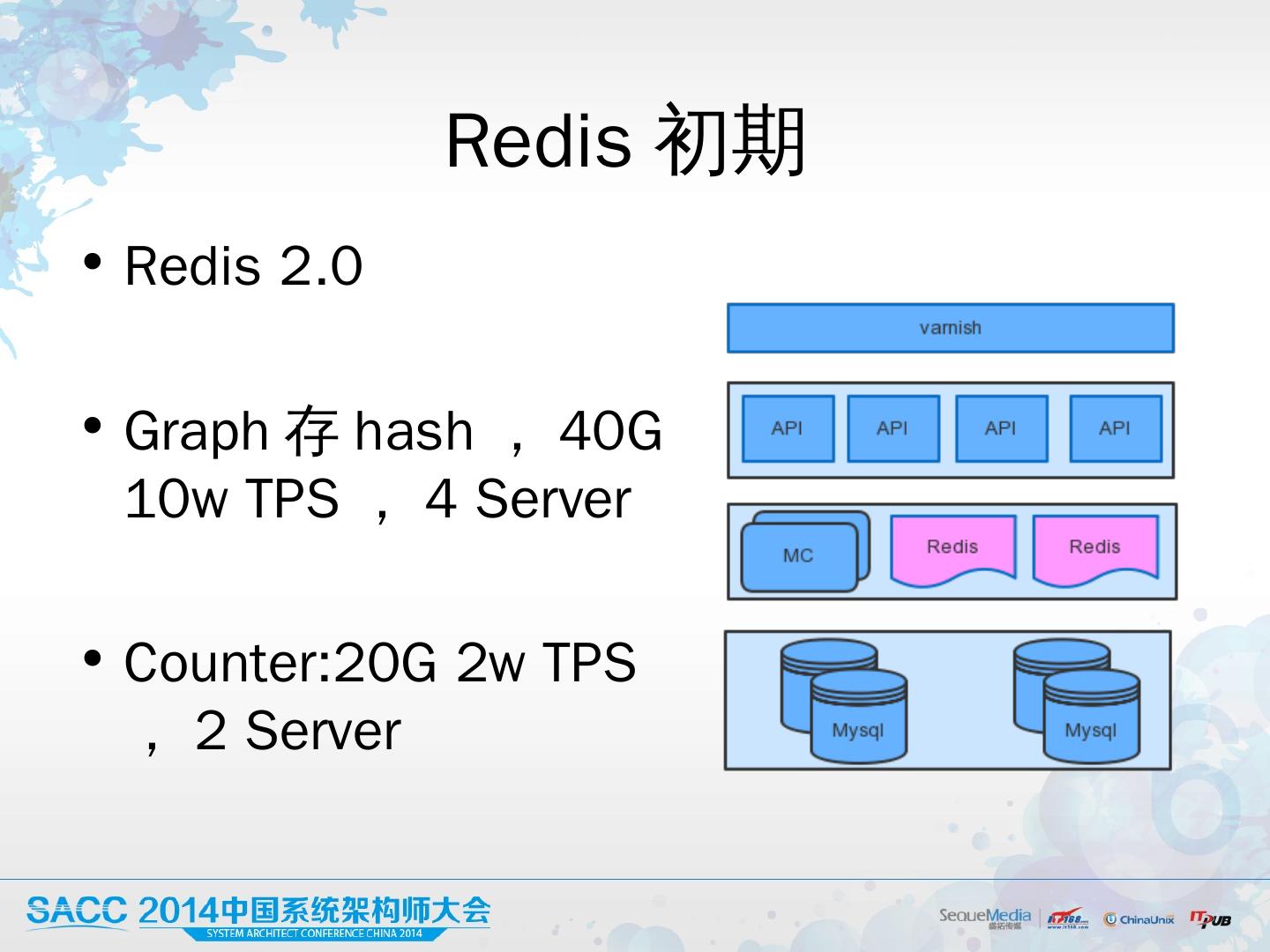
11 .Redis 初期 Redis 2.0 Graph 存 hash,40G 10w TPS , 4 Server Counter: 2 0G 2w TPS,2 Server
12 .问题出现 2011 年,初期使用经验不足 数据分片过 少 ,扩容困难 部分数据类型使用不当, 内 存超 预 期 多业务混 放 ,拆分不便 可用性不够 小业务初期没 有slave, server 故障 服务异 常 大业务挂 载 3-4 个 slave ,高峰期 write 超时,请求失败 重启耗时, 10-20 分钟服务异常
13 .解决方案 容量规划 提前 预估容量 ,上线前预拆足够的数据分片 选择合适的数据类型,慎用 zset 业务独立存储,拒绝混放
14 .解决方案 提高可用性 所有 Redis 全部增加 Slave Master 挂载 slave 不超过 2 个,采用 M-S-S 方式挂载 多 IDC 单 Master ,复制同步 凌晨低峰升级 ,访问 IP 域名 不完美, 但基本可 work
15 .问题 升级 2011 年底, Graph 1 00G + 灵异事件 凌晨 3 点低峰期, redis 无征兆崩 溃 批量升级、扩容拆分,引发其他业务异常报警 多个slave严重负载不均,请求数 最大 差1-2个数量级,峰值 响应从 不足1ms->3ms 在线版本增多 最多 6 个版本 BUG 重复修复, 运维困难
16 .问题分析 崩溃:读写会用 pageCache , 导致redis进swap而崩溃 其他服务报警:复制 全量推送导致网络阻塞 负载不均: client 通过 域名访问,域名解析返回随机 ip ,结果连接不均衡,最终导致负载不均衡
17 .问题解决 紧急方案 超过物理内存 3/5 迁移端口 错峰 升级/ 扩容 对网络仍然有一定冲击 开发 ClientBalancer 组件,保持域名下 IP 连接均衡,负载均衡 进一步优化方案: 及时清理pagecache,减少对正常业务影响 Aof去掉rewrite,改用rotate 类似 mysql ,独立 IO 线 程对rdb 、 aof转发复制(社区版p s ync , repl-backlog-size, repl-backlog-ttl) 支 持热升级 ,避免重启, 提高可运维性 Others…
18 .小结 小规模 50G 1 -2 个集群 人肉运维 中规模 100 G+ , 3+ 集群 可运维性 -> 重要 开源组件 -> 熟悉架构实现
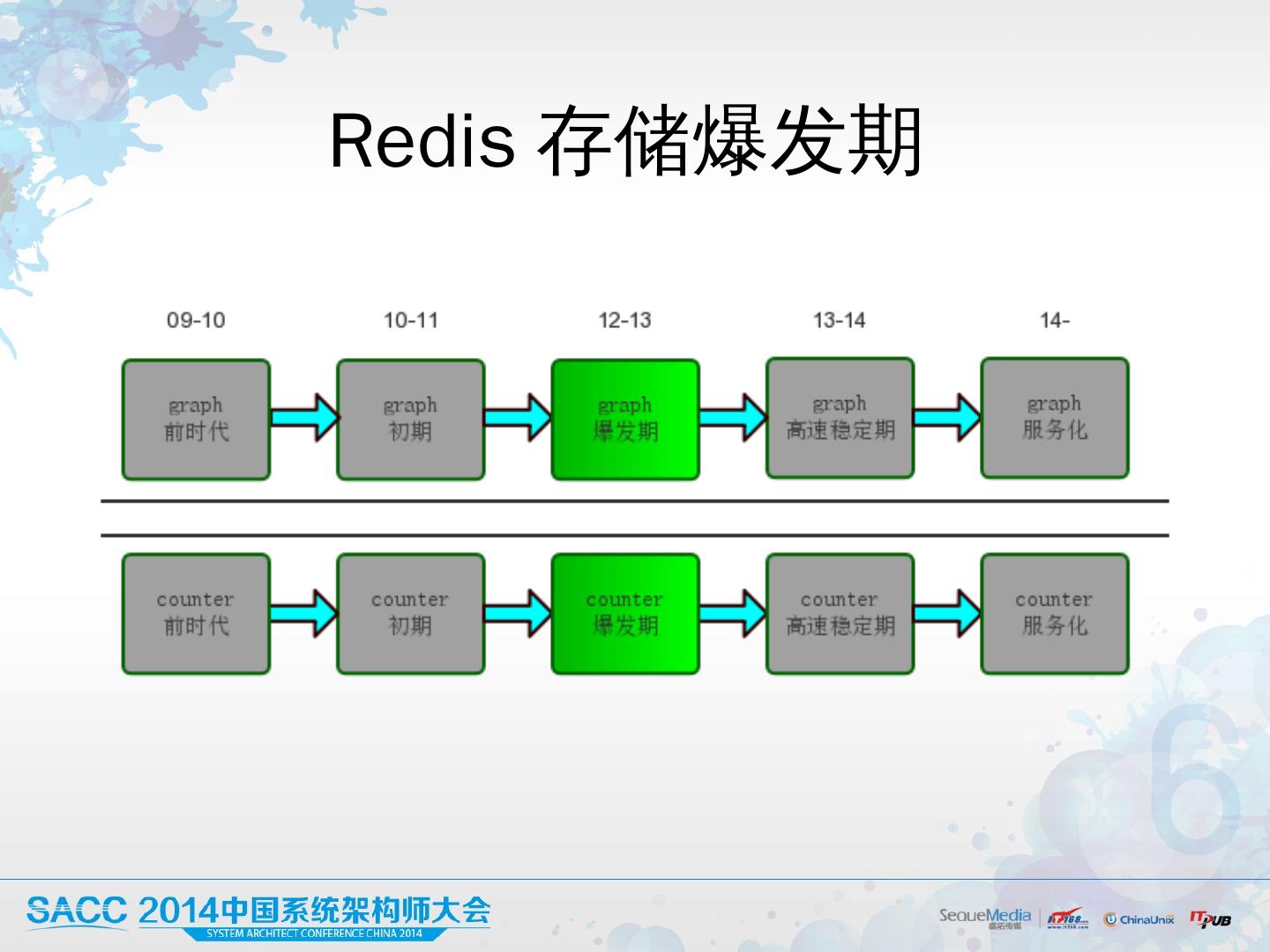
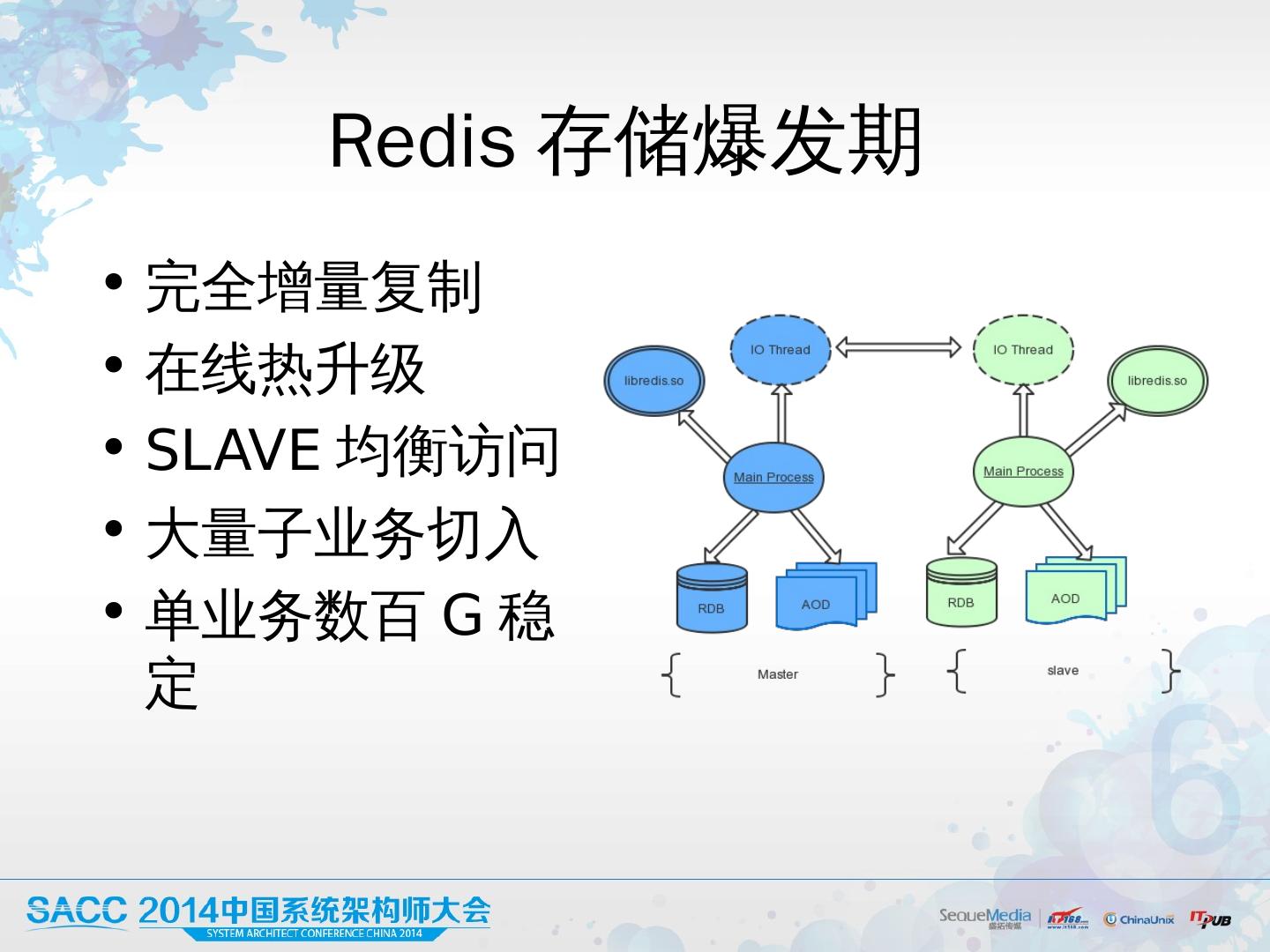
20 .Redis 存储爆发期 完全 增量复 制 在线热升级 SLAVE 均衡访问 大量子业务切入 单业务数百 G 稳定
21 .问题出现 2013 年, Graph海量规模 数据T级,MS 十 T级 数百台server ,而且还在快速增加 Graph 用 Hash 结构,存储效率不高
22 .问题出现 Counter 业务增加, 增长迅猛 日 增:计 数亿 条 内存 5G+ 总 数据百 G 级, MS T 级 Feed请求 计 数 近百倍 读 放大, 高 峰超时报警 存储效率低 <30% 2013000001.cmt 360 2013000001.like 1000 2013000001.rep 800 2013000001.read 10000
23 .问题出现 占 用机器增 加 迅猛 , 成本合理 性需要考虑 部分机房机架饱和
24 .解决方案 Graph 定位: storage cache 定制: hash Longset Counter 定制 cdb,通过table分段存储计数 一 个KV存多个计 数 2013000001.cmt 360 2013000001.like 1000 2013000001.rep 800 2013000001.read 10000 2013000001 800|360|1000|10000
25 .解决方案 Counter 存储结构 cdb=schema+tables 计数 double -hash寻址,消除冗余robj存储结 构 冲突过多aux_dict 数值过大extend_dict 多管齐下, 节省数百台机 器 下线低配server , 寻找 廉价新机 房
26 .小结 量变->质变,极端业务定 制 大规模集群 T 级 3 +idc 成本 单个请求成 本 总拥有成本
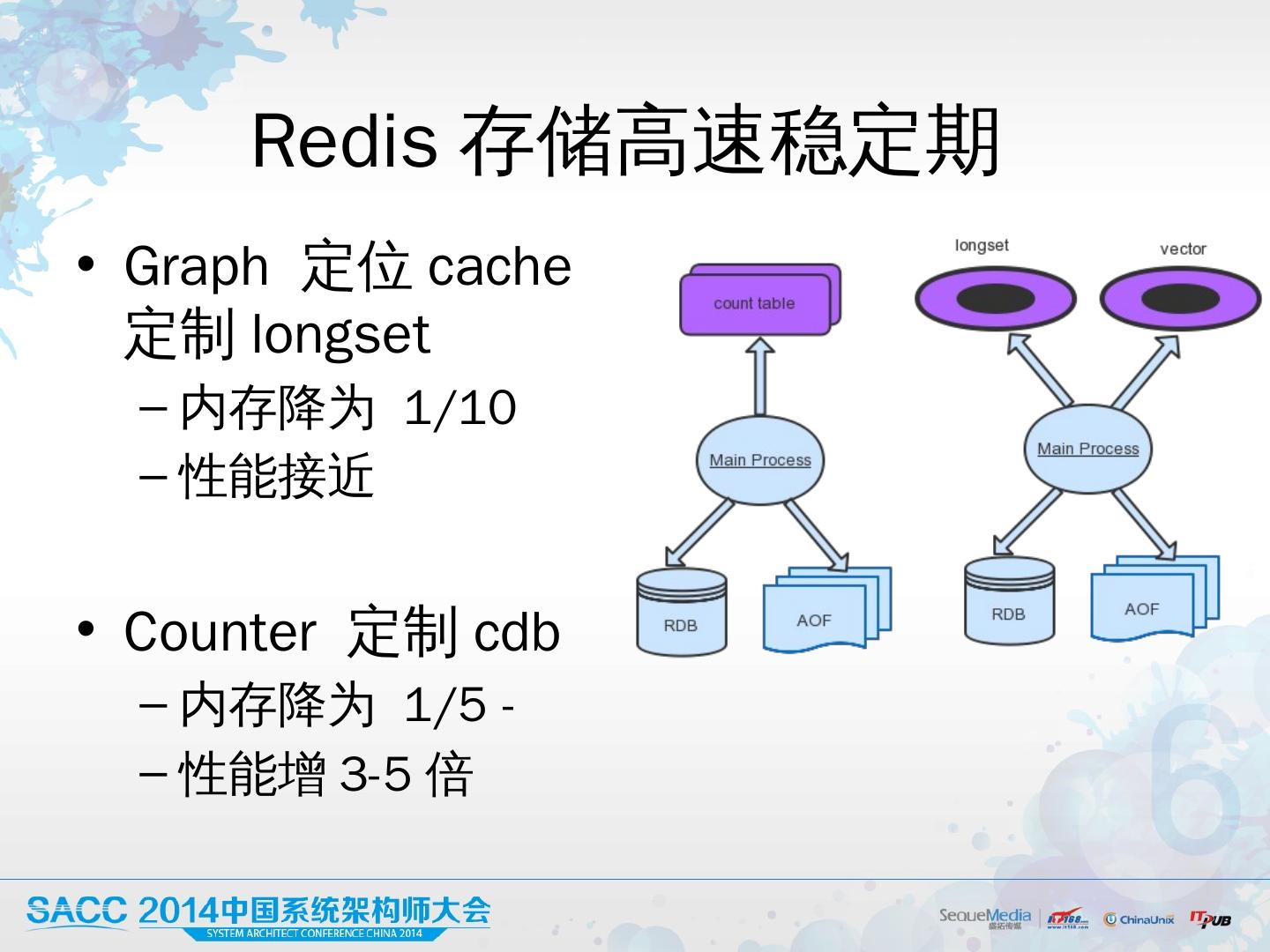
28 .Redis 存储高速稳定期 Graph 定位 cache 定制longset 内存降为 1/10 性能接近 Counter 定制cdb 内 存降为 1/5 - 性能增3-5倍
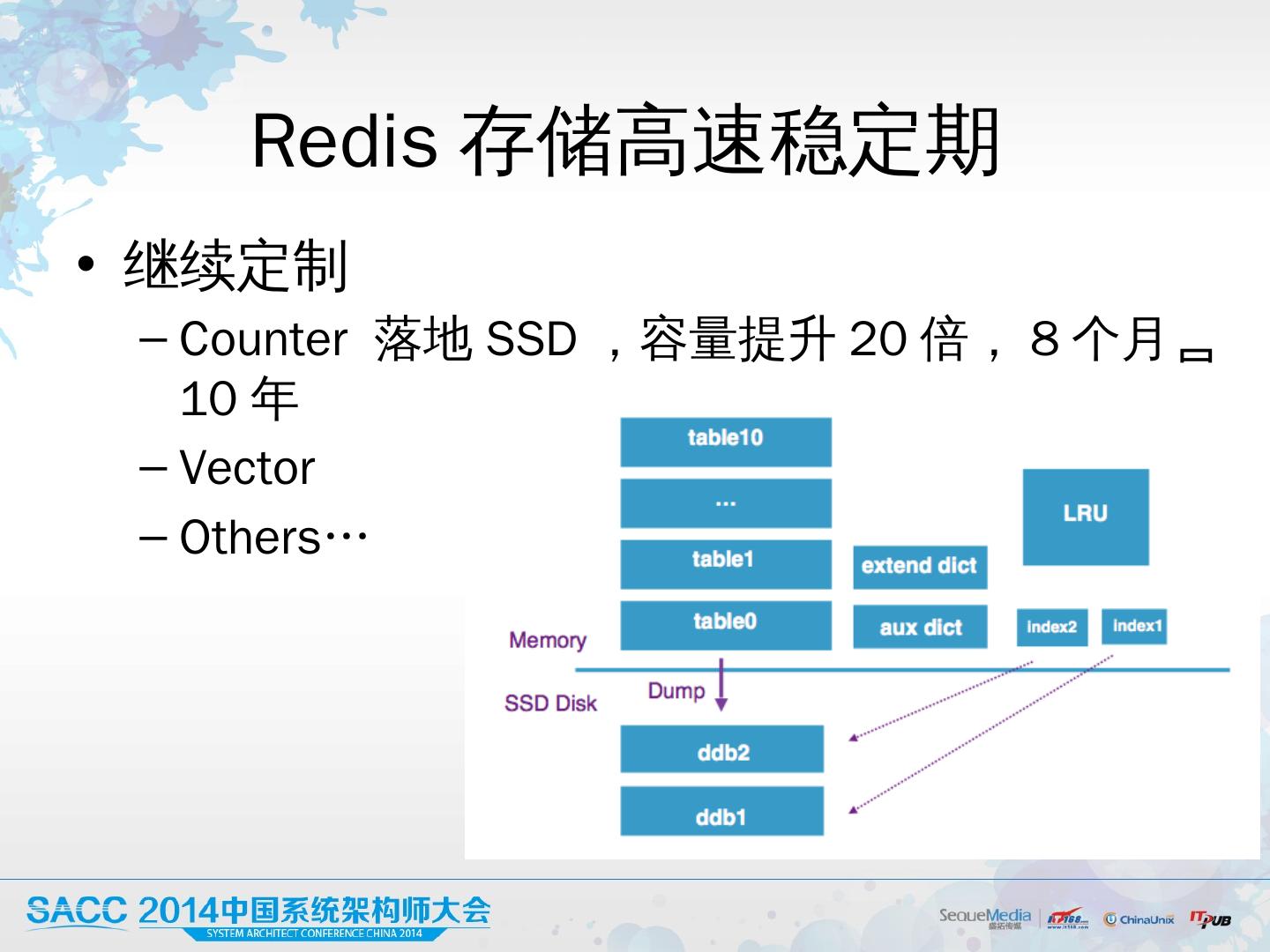
29 .Redis 存储高速稳定期 继续定制 Counter 落地 SSD , 容量提升 20 倍, 8 个月 10 年 Vector Others…