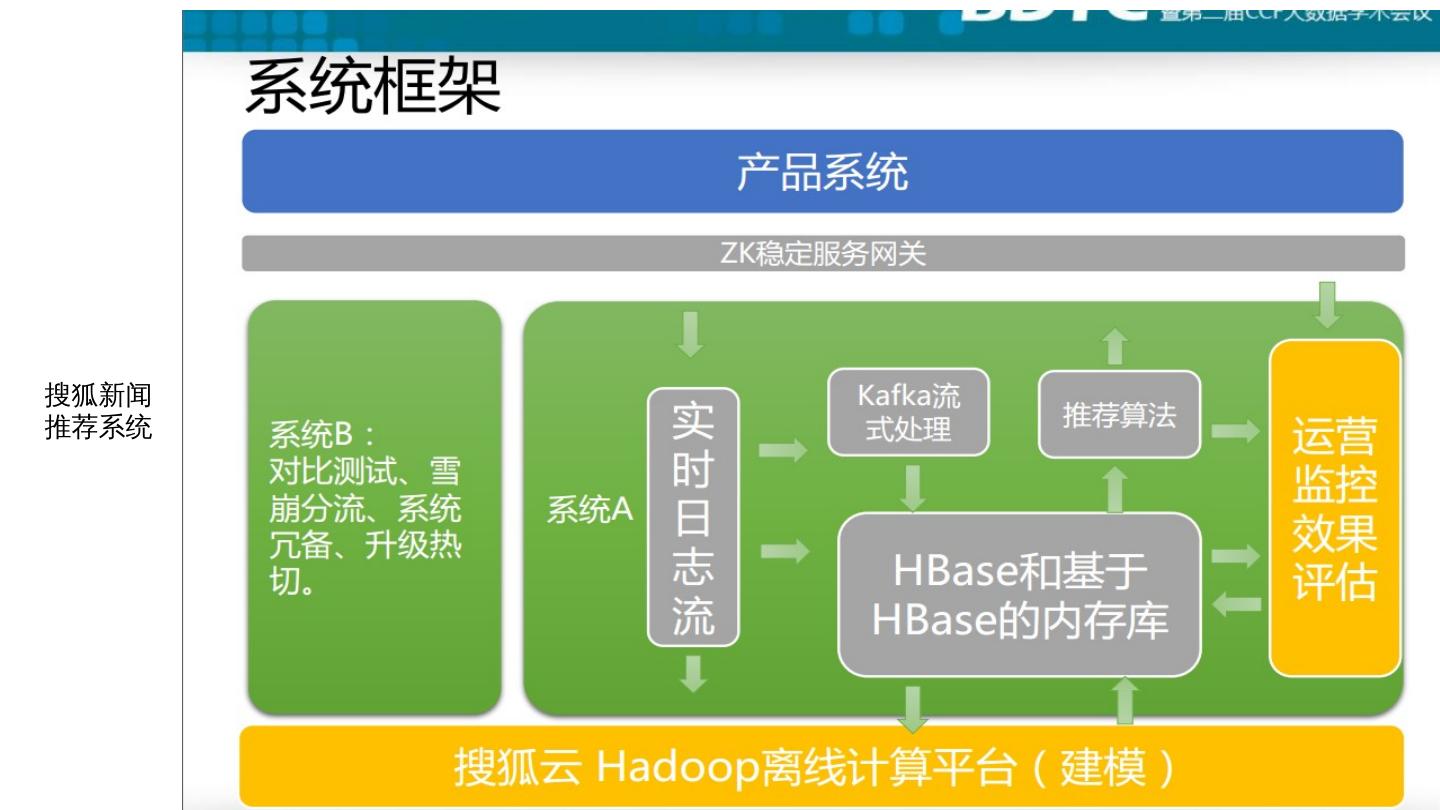
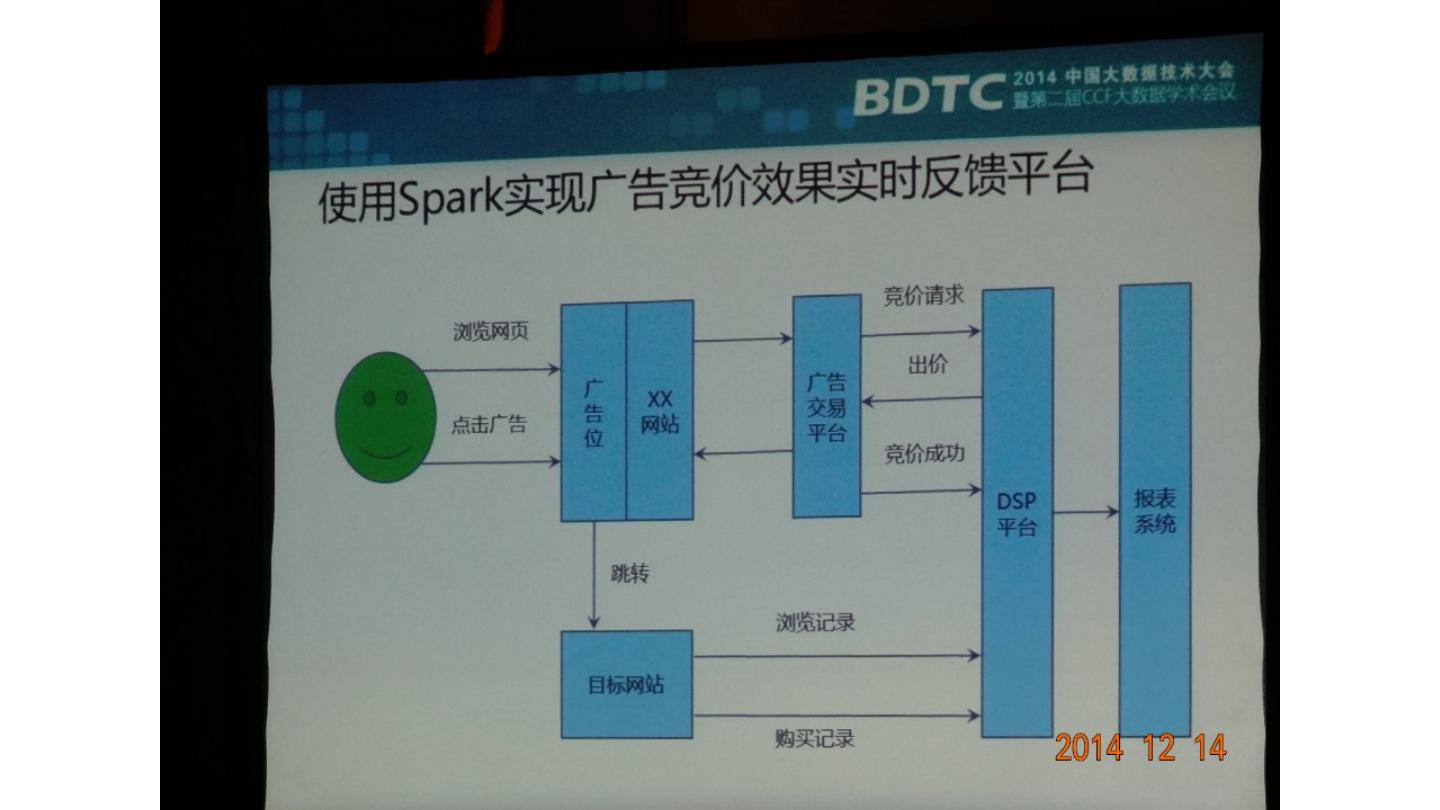
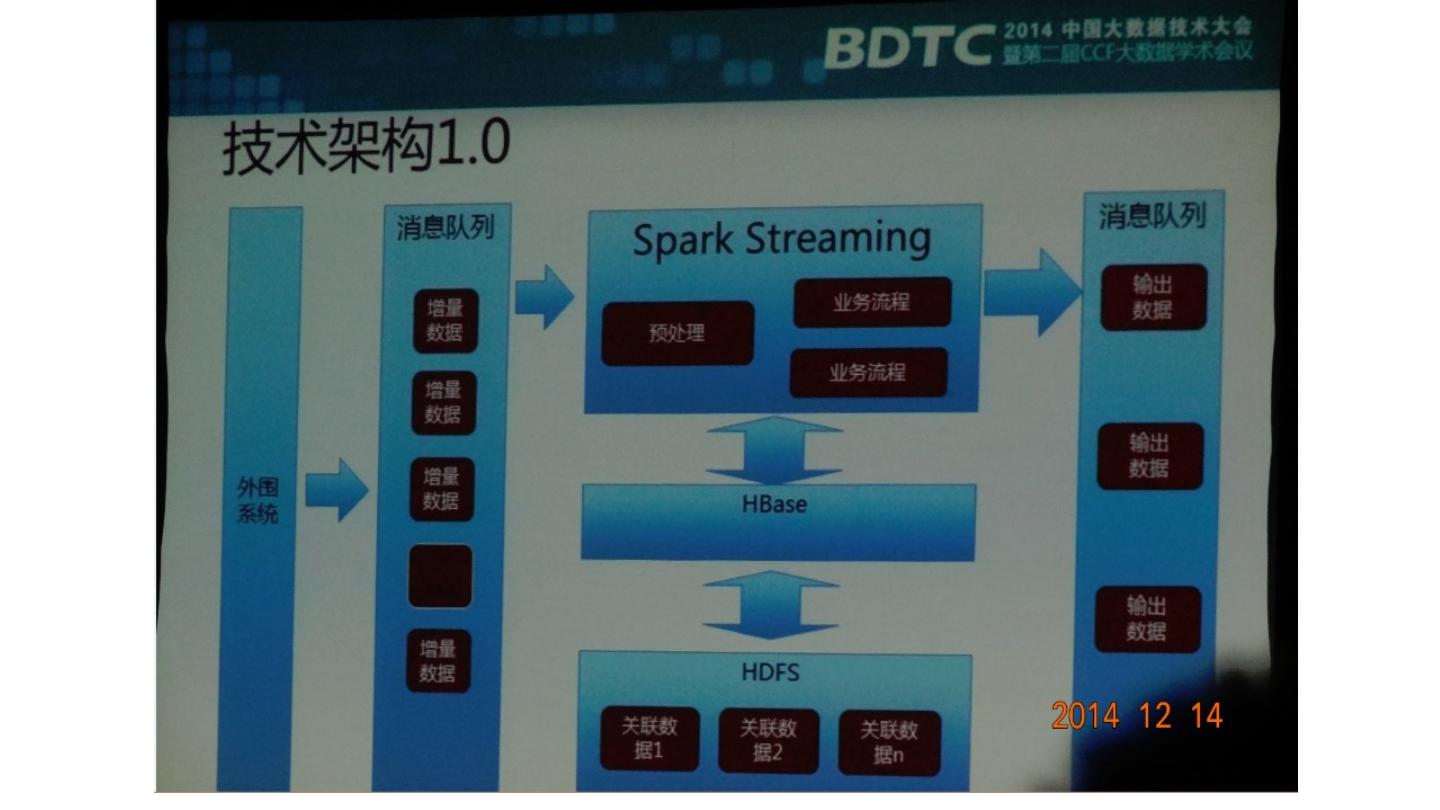
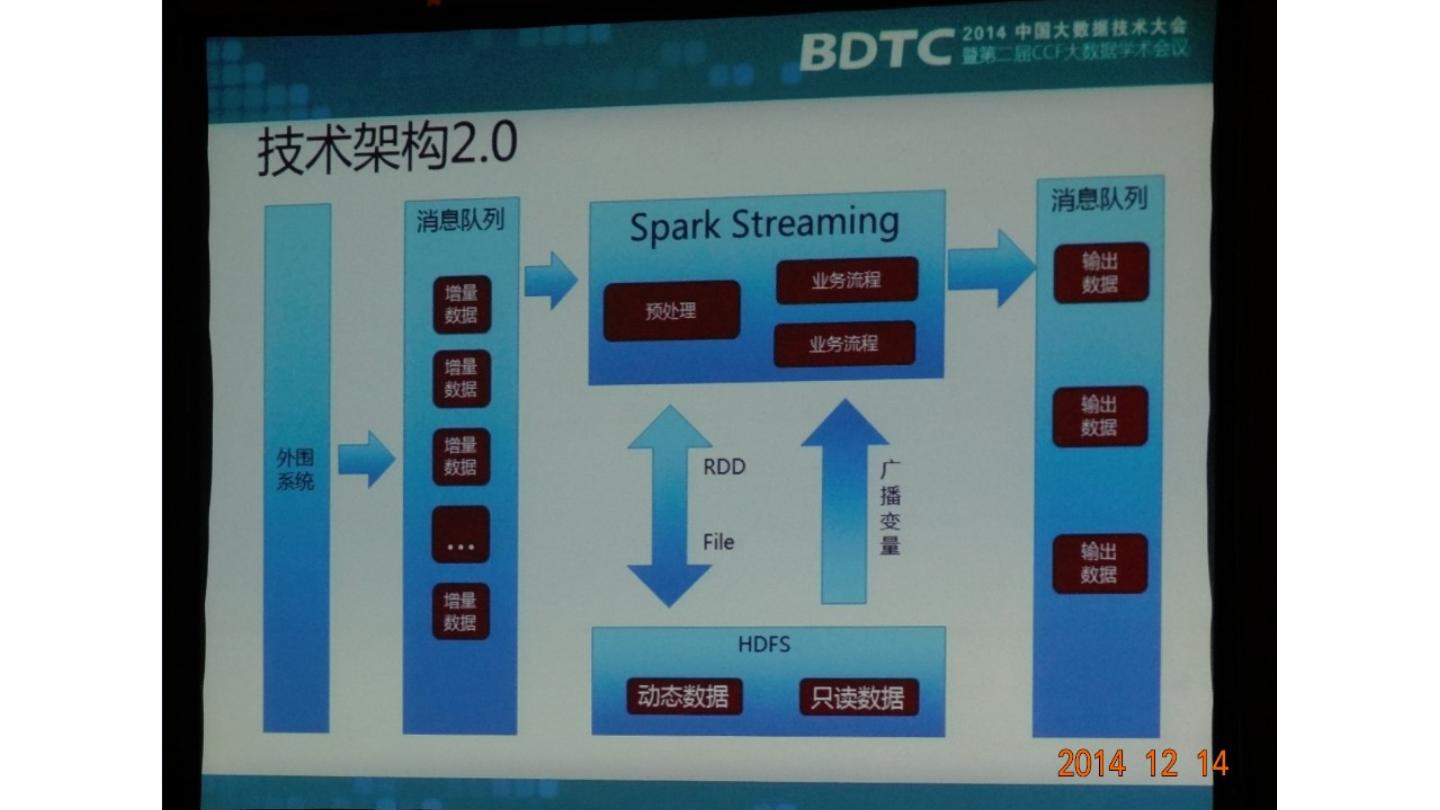
展开查看详情
2 . 介绍
• 中国大数据技术大会前身是 Hadoop 中国云计算大会
• 描绘大数据领域内的技术热点,沉淀行业实战经验,见证整个大数
据生态圈技术的发展与演变
• 提出学习的方法:找个平台看看我们能做什么,而不是闷头看书
• 技术热点: Spark 、机器学习(尤其是大数据平台上的深度学习)
、流数据处理和实时快速分析以及在 Hadoop 上的快速 SQL 接口
• 大多数在讲公司的平台架构和一些公司用的开源项目
�
4 .2015 年大数据基础技术的演进趋势
• 星环科技 CTO 孙元浩的演讲主题是“ 2015 年大数据基础技术的演进趋
势”。期间,他一共总结了四大趋势:
• SQL on Hadoop 技术对 SQL 支持的完整度和性能大幅提升,混合架构将逐渐消
失
• 从 In-Memory Computing 转向 On-SSD Computing ,固态盘将替代内存作为缓
存
• 数据产生的速度以及处理的速度要求都在快速提高,实时大数据技术得到关注
• 虚拟化技术的快速演化与 Hadoop 技术的日益平台化,云计算与大数据终得融合
期间,他分享了 Spark 的一个数据:全球已有近 50 家企业围绕 Spark
提供产品和服务, 11 家提供商业 Spark 版本。
�
5 .一、混合架构逐渐消失
混合架构
1 、 Hadoop 离线处理非结
构化的数据,对于结构化的
数据用关系型数据库协助
2 、数据量小的时候,大家
发现 Hadoop 的性能不如传
统的 MPP 数据库
�
6 .一、混合架构逐渐消失
Impala- 类似于 MPP 的引擎
Tez- 吸收了 Spark 的一些设计
思想。 Transwarp Inceptor- 基
于 Spark 开发的 SQL 引擎,目
前支持 SQL2003 ,支持函数、
游标等功能
SparkSQL 和 Drill
Spark 会成为一个主流
�
7 .一、混合架构逐渐消失
• Hadoop 的 SQL 支持程度已经接近 MPP 数据库
• 现在 Hadoop 性能可以超过 MPP 若干倍
• 传统的 BI 厂商都已经转向 Hadoop , Hadoop 系统的 BI 工具也越来越
丰富,还有一些新兴的创业公司在 Hadoop 上开发全新的 BI 工具,这些
工具原生支持 Hadoop ,从这个角度来讲 Hadoop 的生态系统将很快超
越传统 MPP 数据库。
现状: SQL 支持仍然不够完整,而通过 Spark 可以快速并行化 SQL , S
QL 支持的完整程度可以快速提高。同时,通过 Spark 引擎我们证明新引
擎性能可以超过 MPP 数据库。我们发现一个事实现在 Spark 成为最受
欢迎的计算引擎
�
8 .二、内存可以被大容量的 SSD 取代做缓存
SSD 价格便宜,速度也很快,相对于
内存,性价比还是很高的
现有的 TXT 和行列混合等文件格式不足以
利用 SSD 的高性能如果使用 SSD ,还需要
为 SSD 设计专有的数据格式
两个趋势:
基于磁盘的 Hadoop 借鉴内存数据库的经验
设计新格式为 SSD 优化
现有的内存数据库为 SSD 优化
�
10 .三、实时大数据的技术得到更多关注
• 随着现在传感器网络、物联网的发展,数据产生的速度越来越快
,当然在互联网里面早就有实时数据产生,使得实时大数据的技
术慢慢开始得到更多的关注,我们预计明年有更多的应用。
�
11 .Hadoop
Storm 融合
架构—
Lambda
Architecture
(没有实战经验,所以好
多理解不了各种问题、优
缺点)
�
13 .四、云计算和大数据终于可以融合起来
让 Hadoop 成为一种服务
(东西太多)
�
14 .• 虚拟机帮助快速部署已经得到了时间的验证,这种方式把一台机器拆分到很多小机器,每台机器给用户使用。大数据觉得一台机器不够
,我需要上千台、几百台机器组成一台机器处理。这个怎么融合起来,是不是我把虚拟机替代物理机做成了一个集群?这个尝试基本上
都是失败的,因为 IO 的瓶颈是非常严重的,特别是在虚拟机跑大数据应用, CPU 利用往往达到 99% ,很少有人在虚拟机上把 CPU 用到 99
% ,这样对 hypervisor 是很大的考验,稳定性成为一个大问题。最近一两年虚拟化技术在快速发展,不亚于一场新的技术革命。首先轻量
级的 Linux container 技术出现, container 之间可以做资源隔离,这使得虚拟机变得非常轻量级。很快一家公司叫做 Docker 发现应用打包
迁移安装还是不方便,所以做了一个工具,使得你做应用打包迁移非常容易。大家发现还不大够,因为我要创立单个 container 或者单个
应用比较容易,但是多个 container 应用就很麻烦。谷歌开发一个开源项目叫做 Kubernetes , 简化了创建 container 集群的任务,你可以
非常方便的创建 Hadoop 集群,也可以创建传统的应用,提供多 container 集群的部署同时也提供一些基础服务,比如说一些调度服务,这
开始具备分布式操作系统的雏形。另外一个方向像大数据领域去年推出 Hadoop2.0 资源管理的框架 YARN ,这个确实是革命性的,因为把
资源管理放在最底层,在上面可以跑多种计算框架,我们觉得可以一统天下了。随后大家发现 YARN 资源隔离做得不够好,内存/磁盘/
IO 没有管好。因此 Hortonworks 尝试把 Google Kubernetes 作为 YARN 的一个 Application Manager, 内部用 Docker 进行资源调度。而另一
家公司 mesosphere 异军突起,以 mesos 为资源调度核心,以 docker 作为 container 的管理基础工具,开发了一套分布式资源管理的框架
,提出了数据中心操作系统的概念。这家公司最近融资了数千万美元。尽管底层技术在快速变化,但不妨碍一些公司已经提供 Hadoop a
s a Service 的服务,例如 AltiScale , BlueData , Xplenty 等。
• 大家看到在这个领域过去一两年发生了革命,从底层虚拟化技术到上层都在发生非常大的变化。逐渐引出了数据中心操作系统的概念。
我们把数据中心操作系统分成三层,最底层就跟操作系统内核是一样的,可以方便的创建方便销毁计算资源,包括对 CPU /网络/内存
/存储进行处理。同时我们还需要多个服务之间能够发现这种机制,这种机制是目前还是缺乏的,我们需要在这一层继续往上加一些基
础服务。再往上是平台服务,我们可以创建 Hadoop 、 Spark 等我们可以部署这样传统应用。这种架构提出来我们发现现在市场上有几种
,两个技术方向,我们不知道哪一种会获胜。一个方向是把 YARN 作为资源调度的基础, Kubernetes 作为运行在 YARN 上的某一个应用框
架,但实际上 Kubernetes 是和 YARN 并列在同一层的。另外一个技术方向是把调度器抽象出来作为 plugin ,例如 YARN 和 mesos 都可以作
为 Kubernetes 的调度器,当然也可以实现自己的调度程序;使用 docker 或者 coreOS 进行 container 的管理,而 hadoop 等分布式服务运行
在 Kubernetes 之上。对下能够提供资源隔离和管理,对上面能够提供各种服务,包括 Hadoop 生态系统的各种服务,这个可能是明年的主
流趋势,现在还很难判断谁会获胜,但是我更倾向于第二种,我们可以首先尝试这两种方案,看哪种方案更有生命力。
�
16 .ML on Big Data- 大数据机器学习
• 深度学习 - 余凯
�
17 .深度学习适合大数据
• 第一方面,深度学习模拟了大脑的行为。一开始做深度学习这帮
人,他们的想法受到卷积神经系统网络的影响,在 80 年代受到
了神经科学家对于视觉神经系统理解的影响
• 第二,从统计和计算的角度来看,深度学习特别适合大数据
• 第三,深度学习是 End-to-end 学习
• 第四,深度学习提供一套建模语言
�
18 .大数据时代传统深度学习的误区
• 统计分析机器学习系统效果
• A- 数学模型不完美
• E- 数据不完美
• O- 算法不完美
�
19 .大数据时代传统深度学习的误区
• 随着数据规模的扩大,从推广误差的角度来说,传统的深度学习研究中
存在着一些误区:
• 从 Approximation error 的角度来说,过去我们认为简单的模型就是好的,但实际
上简单的模型是不够好的,随着机器的增多,参数越来越多,模型越来越复杂,
是大趋势,过去认为简单的模型是好的这是错误的观念
• 从 Estimation error 的角度来说,为了保证数据的精确,应该收集充分的数据
• 从 Optimization error 的角度来说,通常是学术界的观点是,开发研究非常精致的
优化算法,但是这些算法存在一个大问题:不能覆盖大数据。比如, SVM 的复杂
度是在数据二次方到三次方之间的复杂度,今天处理一万个训练样本没问题,但
是如果变成十万个训练样本,你需要一百倍到一千倍的计算资源,这是灾难性的
问题,所以在大数据的时代,工业界反而要倡导的是 desgin “an OK algorithm”
�
20 .Experience-Centric Software
Defined Infrastructure Platform
• 网络的延迟一直是互联网面临的难题,没有一个很好的办法来解
决。但是随着以下三项互联网技术的发展,使得改善用户的互联
网体验成为了现实:
• 企业可以从用户端提取细颗粒信息
• 软件定义的迅速发展
• 大数据的实时技术发展。
�
21 .Experience-Centric Software
Defined Infrastructure Platform (方
向?)
• 网络的延迟一直是互联网面临的难题,没有一个很好的办法来解
决。但是随着以下三项互联网技术的发展,使得改善用户的互联
网体验成为了现实:
• 企业可以从用户端提取细颗粒信息
• 软件定义的迅速发展
• 大数据的实时技术发展。
�
22 .提取细颗粒信息
• 我们知道现在从网上看视频,或者下载一个 APP 看视频,这个过
程中我们浏览的视频,下载的视频都会被收集起来。服务商可以
通过在软件植入代码来实现。这样就可以获得用户的一些基础信
息。
�
23 .软件定义
• 根据用户客户端数据的反馈(卡断率、失败率等),实时分析出
合适的码流路径,使得视频流畅
• 不同参数质量好坏对于一个服务器来讲在不同时间是不一样的,
所以没有一个固定路径是最好,而且没有一个固定的指标是一个
路径比另外一个路径绝对好
• 引进冗余
�
24 .实时的大数据技术和算法
• 这个算法就是概念上是一个很简单的概念,做起来稍微复杂一点。
概念是什么概念?如果我们把每一个网上的视频都在采样,就像
我们在北京每辆车上都装一个摄象头,知道他车速是什么情况?
我车越多,但是我路上没有摄象头,车越多我的路况了解就越多
,我要知道北京所有车的速度怎么样,我就基本上知道北京路况
是怎么样。但是卡车和出租车走的速度是不一样,也许你骑摩托
车和坐卡车的速度不一样。细分起来找一个概念是这样的,比如
说这个会场里面大家看一个直播的视频,现在有一个新的人来看
,用哪一条新的路径去选?算法我就不深入去讲了,但是我想说
一两个,你观察数量越多,观察颗粒越细,采集数量点越大,你
最后达到预测的效果越好。
�
25 .Experience-Centric Software
Defined Infrastructure Platform
• 观察数据越多,粒度越细,效果越好(车辆越多,观察的东西越
多,越能知道路况)
• 实时才能控制,不实时只能分析( Spark 做实时处理)
�
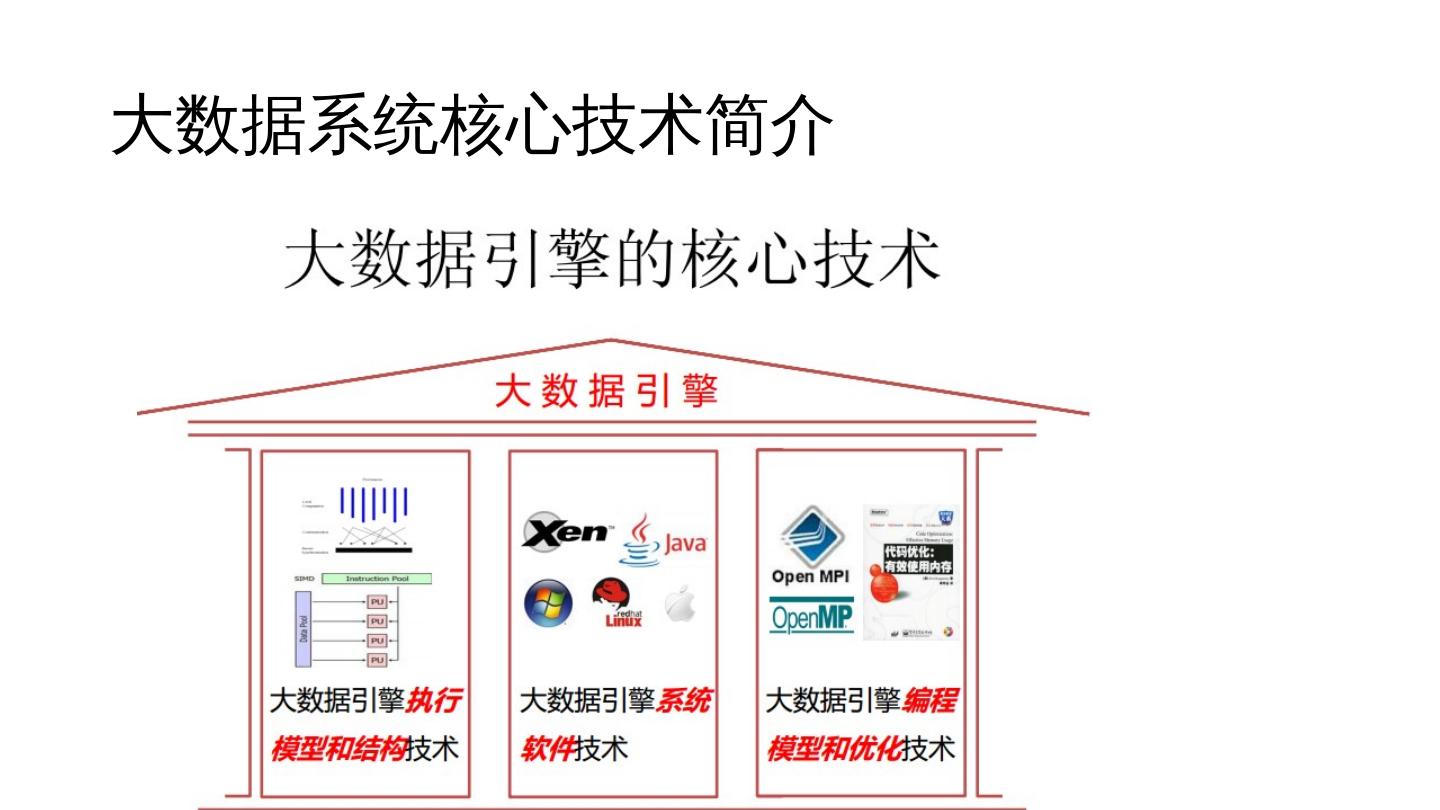
26 .大数据技术核心
• 大数据系统面临的严重挑战
• 大数据系统核心技术简介
• 数据流与大数据引擎的创新
(从系统软件的角度讲,理解不了)
�