1 .
2 .
3 .
4 .
5 .
6 .
7 .
8 .Request与Response Request Response 我 服务器 (2)服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器。这个过程叫做HTTP Response。 (3)浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示。 (1)浏览器就发送消息给该网址所在的服务器,这个过程叫做HTTP Request。
9 .什么是爬虫? 请求 网站并 提取 数据的 自动化 程序
10 .什么是爬虫? 请求 网站并 提取 数据的 自动化 程序
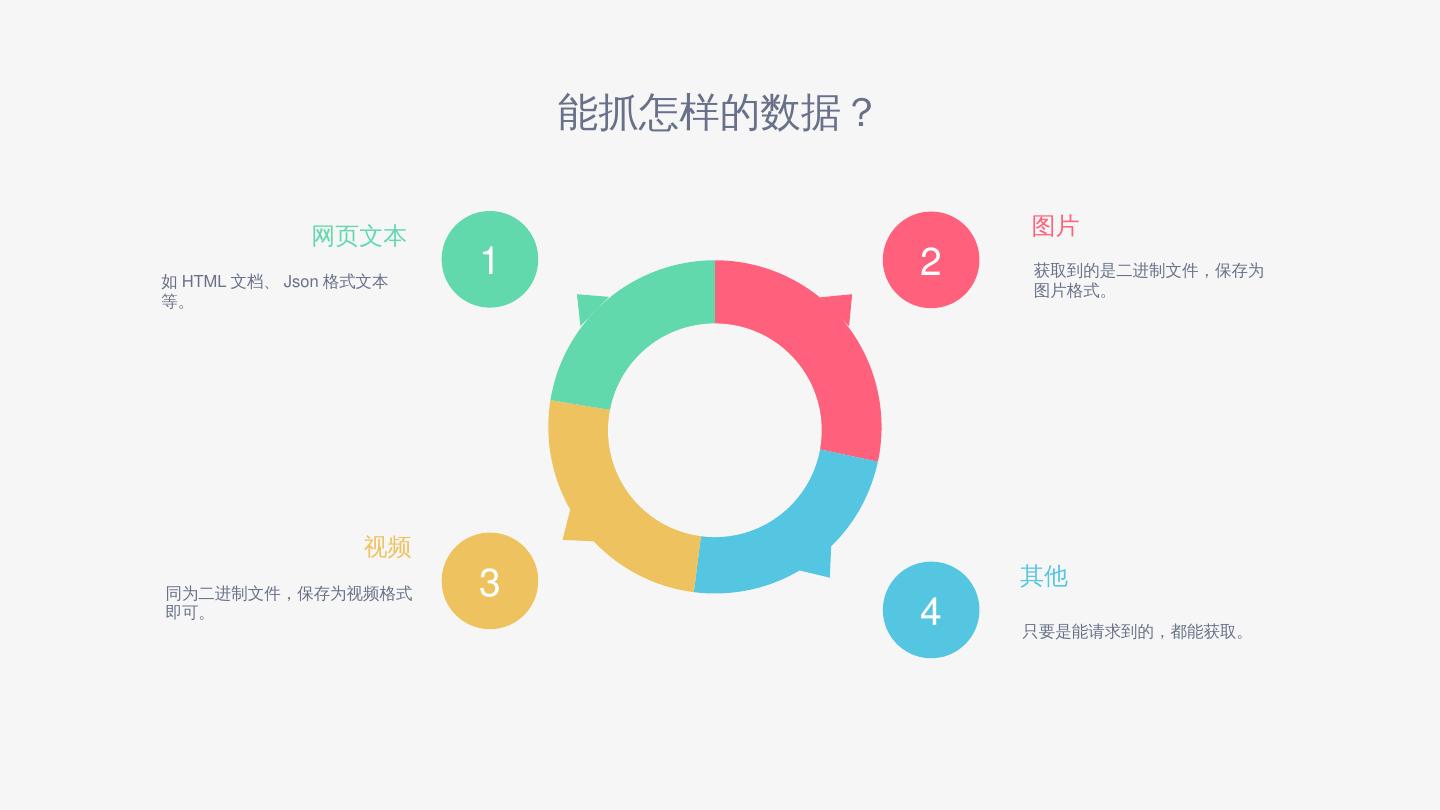
11 .能抓怎样的数据? 2 图片 获取到的是二进制文件,保存为图片格式。 4 1 3 其他 只要是能请求到的,都能获取。 网页文本 如HTML文档、Json格式文本等。 视频 同为二进制文件,保存为视频格式即可。
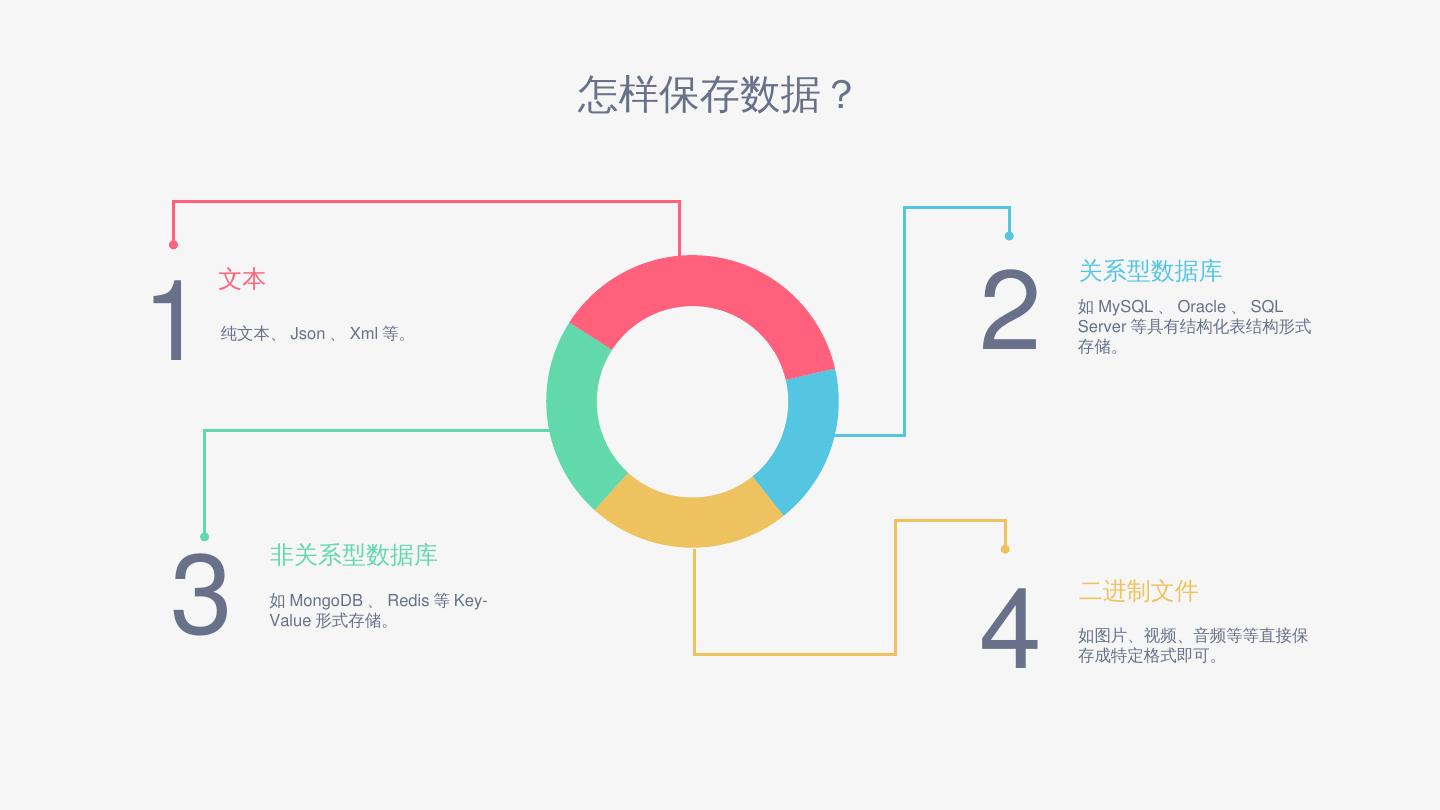
12 .可以怎样保存数据?
13 .为什么我抓到的和 浏览器看到的不一样?
14 .Response中包含什么?
确定删除吗?