


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Kyligence 公开课(4)—Kylin 源码解读之:使用 MapReduce/Spark 进行 Cube 计算的原理及过程
本期课程,我们邀请了 Apache Kylin PMC 史少锋,为我们讲解源码解读的课程。课程主要介绍 Kylin 的离线 Cubing 过程(包括从 Hive 抽取数据并重新分布、获取维度字典值及数据采样、逐层聚合计算所有Cuboids、生成HFile并入库等),帮助开发者理解其内部原理,进而有针对性地进行优化。
展开查看详情
1 . Kyligence 公开课 使用 MapReduce/Spark 进 行 Cube 计算的原理及过程 Shaofeng Shi / Jan 9, 2019 i n f o @ ky l i g e n ce . i o
2 .Agenda • Kylin Architecture • Cubing overall process • Cubing steps on MR • Cubing on Spark © Kyligence Inc. 2019, Confidential.
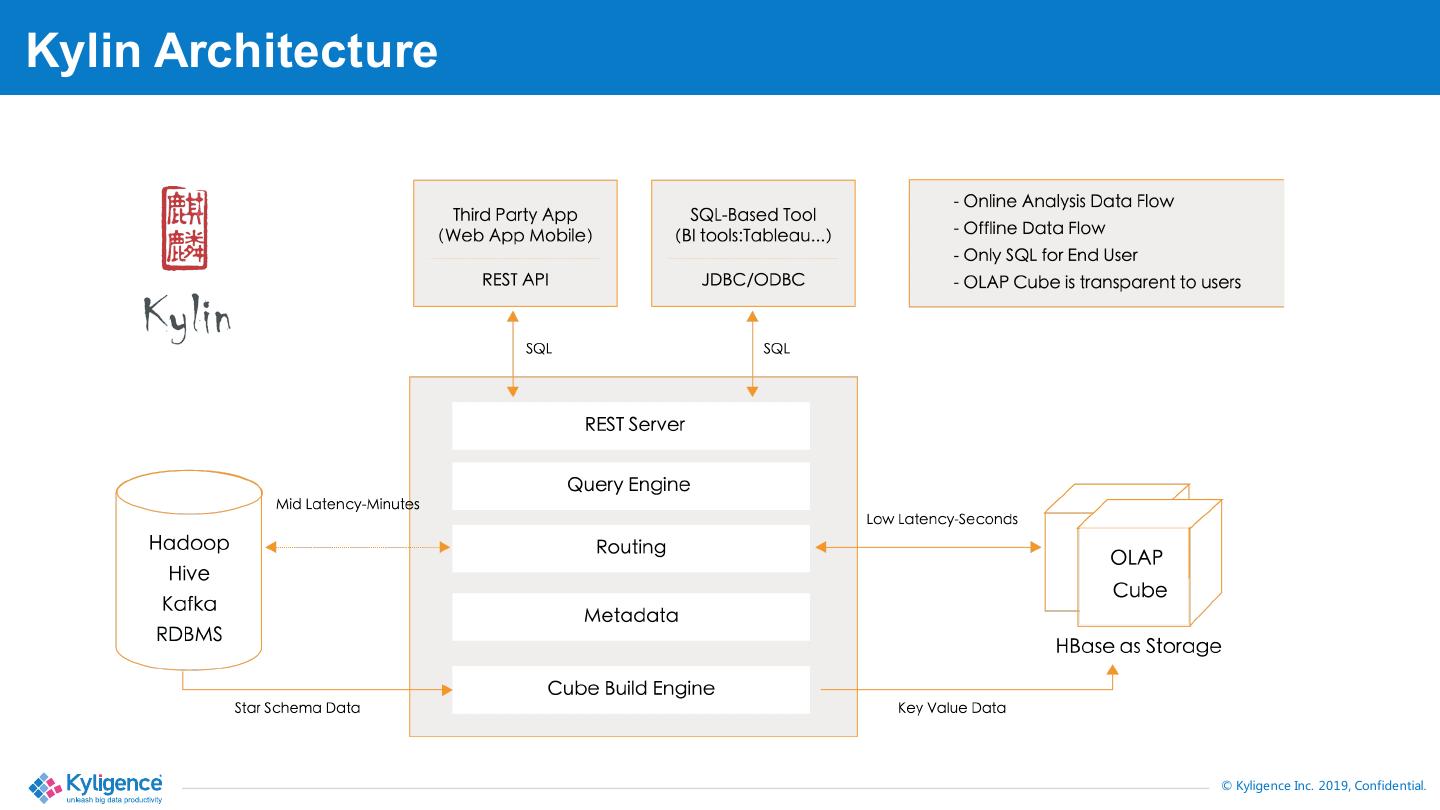
3 .Kylin Architecture © Kyligence Inc. 2019, Confidential.
4 .Two workloads in Kylin Build Cube Query Cube (write) (read) - Massive computing and disk I/O VS - Less I/O, compute on the fly - CPU / Disk / Network intensive - Memory intensive - Offline, long latency (minutes to hours) - Online, low latency (milliseconds to seconds)
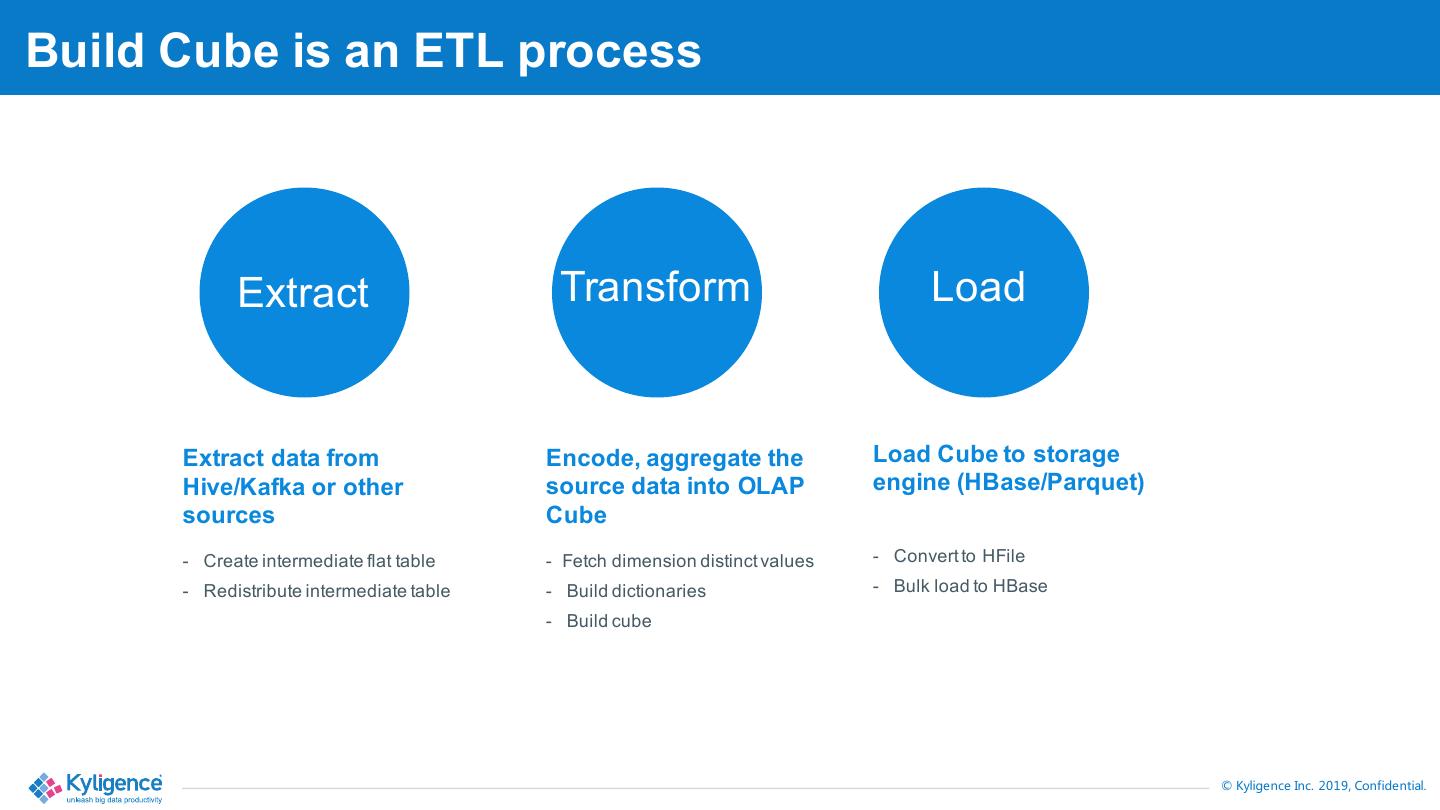
5 .Build Cube is an ETL process Extract Transform Load Extract data from Encode, aggregate the Load Cube to storage Hive/Kafka or other source data into OLAP engine (HBase/Parquet) sources Cube - Create intermediate flat table - Fetch dimension distinct values - Convert to HFile - Redistribute intermediate table - Build dictionaries - Bulk load to HBase - Build cube © Kyligence Inc. 2019, Confidential.
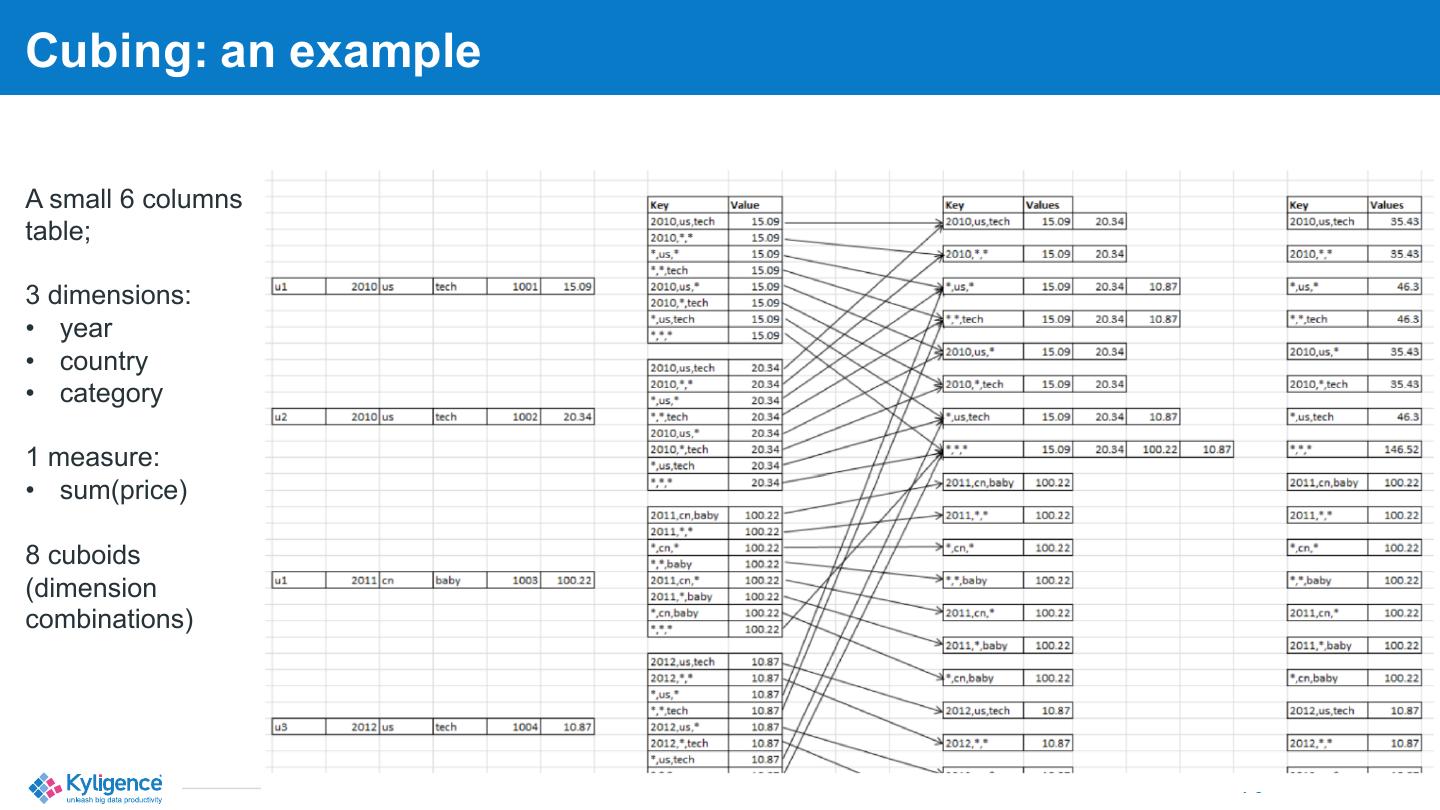
6 .Cubing: an example A small 6 columns table; 3 dimensions: • year • country • category 1 measure: • sum(price) 8 cuboids (dimension combinations) © Kyligence Inc. 2019, Confidential.
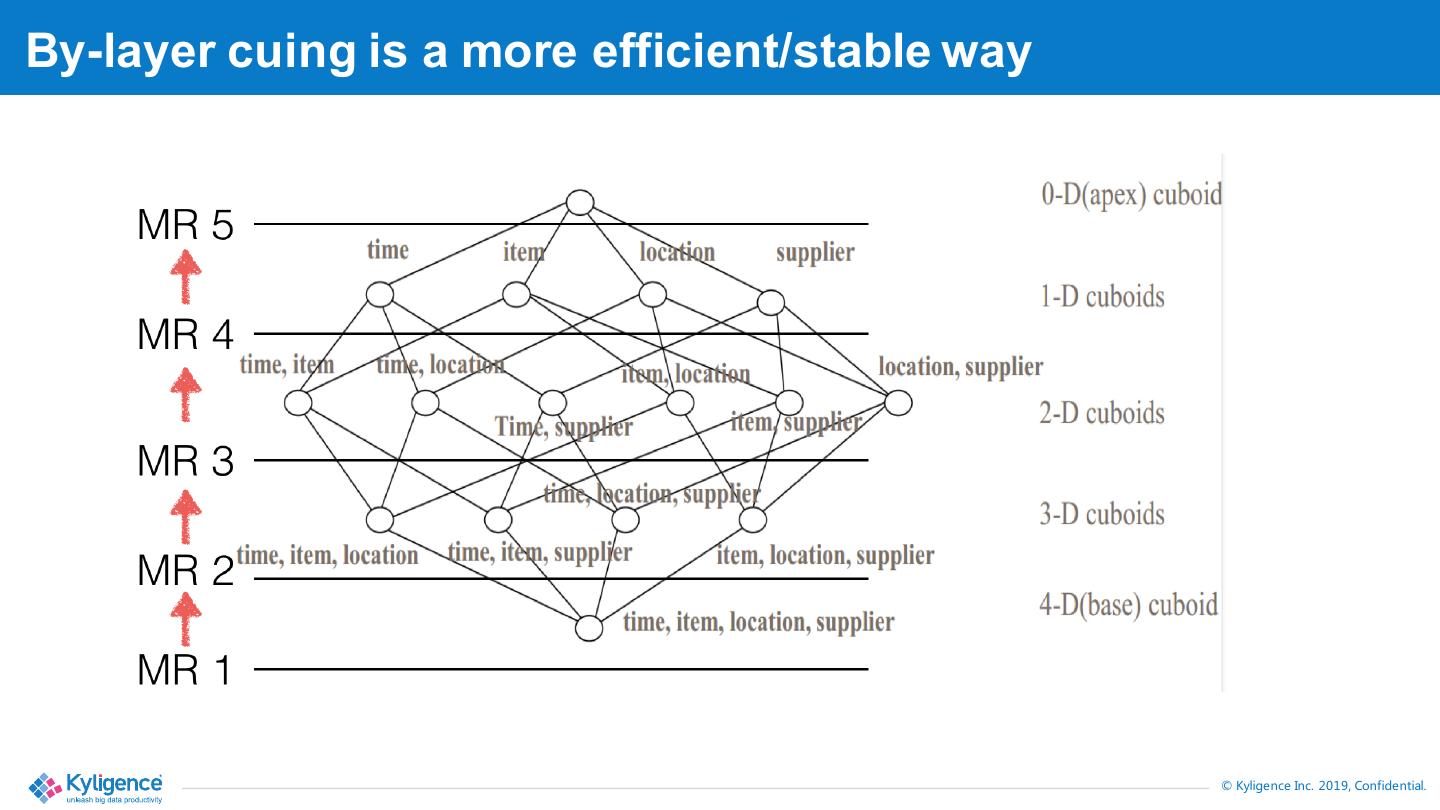
7 .Can we build the cube in one shuffle? Data explosion: 2^N (N=dimension number) Think if you have 20 dimensions, 1 million rows raw data, how many data need be shuffled? 1 million * 2^20 = 1 million * 1 million = 1 trillion rows (一万亿!) © Kyligence Inc. 2019, Confidential.
8 .By-layer cuing is a more efficient/stable way © Kyligence Inc. 2019, Confidential.
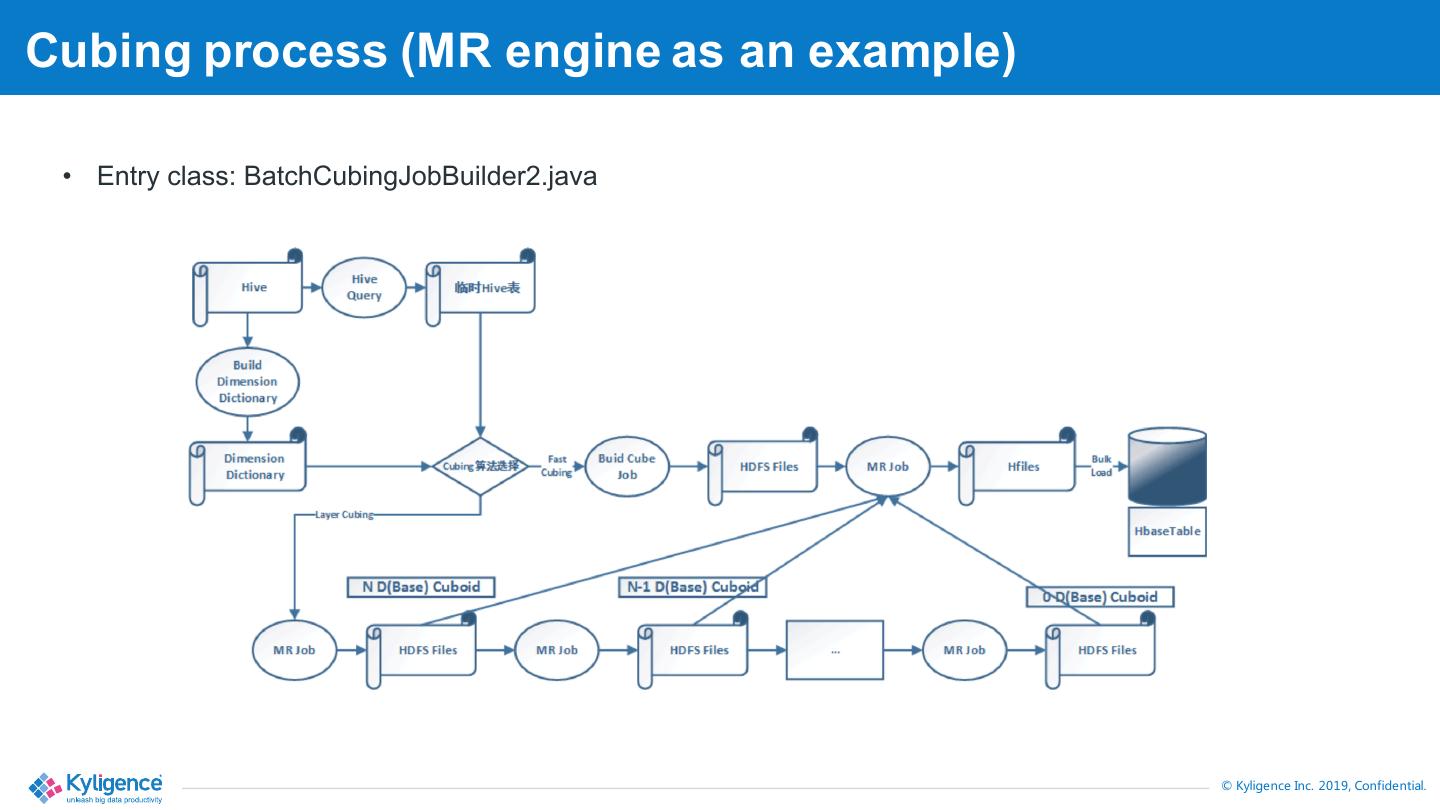
9 .Cubing process (MR engine as an example) • Entry class: BatchCubingJobBuilder2.java © Kyligence Inc. 2019, Confidential.
10 .1. Extract data from Hive to HDFS a) Create an intermediate table in Hive CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_kylin_sales_cube_spark_9229942d_5ac0_8674_6315_8607f13c9695 ( KYLIN_SALES_TRANS_ID bigint , KYLIN_SALES_PART_DT date , KYLIN_SALES_LEAF_CATEG_ID bigint , KYLIN_SALES_LSTG_SITE_ID int …) STORED AS SEQUENCEFILE LOCATION 'hdfs:///kylin/kylin_metadata/kylin-71fcf7b2-df11-3502- 2f18- 665e80bc79b5/kylin_intermediate_kylin_sales_cube_spark_9229942d_5ac0_8674_6315_8607f13c 9695'; Purpose: Create an temp external table for this processing; Use sequence file format. The table will be dropped after job finished. © Kyligence Inc. 2019, Confidential.
11 .1. Extract data from Hive to HDFS (cont.) b) Insert data to this table, by selecting from the source tables INSERT OVERWRITE TABLE \`kylin_intermediate_kylin_sales_cube_spark_9229942d_5ac0_8674_6315_8607f13c9695\` SELECT \`KYLIN_SALES\`.\`TRANS_ID\` as \`KYLIN_SALES_TRANS_ID\` ,\`KYLIN_SALES\`.\`PART_DT\` as \`KYLIN_SALES_PART_DT\` from \`DEFAULT\`.\`KYLIN_SALES\` as \`KYLIN_SALES\` INNER JOIN \`DEFAULT\`.\`KYLIN_CAL_DT\` as \`KYLIN_CAL_DT\` ON \`KYLIN_SALES\`.\`PART_DT\` = \`KYLIN_CAL_DT\`.\`CAL_DT\` WHERE 1=1 AND (\`KYLIN_SALES\`.\`PART_DT\` >= '2012-01-01' AND \`KYLIN_SALES\`.\`PART_DT\` < '2013-01-01') Purpose: Run a query to fetch the source data. Join the fact table with lookup tables by the model definition, apply the time condition to only fetch the given period data. After this step, the data that Kylin needs are persisted in HDFS in expected format. © Kyligence Inc. 2019, Confidential.
12 .2. Redistribute the intermediate table (optional) set mapreduce.job.reduces=X; set hive.merge.mapredfiles=false; INSERT OVERWRITE TABLE \`kylin_intermediate_kylin_sales_cube_spark_9229942d_5ac0_8674_6315_8607f13c9695\` SELECT * FROM \`kylin_intermediate_kylin_sales_cube_spark_9229942d_5ac0_8674_6315_8607f13c9695\` DISTRIBUTE BY KYLIN_SALES_BUYER_ID,KYLIN_SALES_SELLER_ID,KYLIN_SALES_TRANS_ID; Purpose: Make the source data be evenly distributed into files (also merge small files), good for subsequent in-parallel processing; • How many rows in one file/block be controlled by this parameter: kylin.engine.mr.mapper-input-rows= 1000000 File number X = count(*)/1000000 • How many heading dimension columns used for redistribution kylin.source.hive.redistribute-column-count=3 • When user set “shard by” column, will use the “shard by” column to redistribute; If has a countdistinct column, will let hive to “cluster by” it. © Kyligence Inc. 2019, Confidential.
13 .3. Extract Fact Table Distinct Columns To build dimension dictionary, Kylin need to get the full value set of each dimension. Use one round Map/Reduce job to fetch all dimension distinct values, and then build dictionaries in reducers. • Job class: FactDistinctColumnsJob.java • Mapper: FactDistinctColumnsMapper.java • Partitionner: FactDistinctColumnPartitioner.java • Reducer: FactDistinctColumnsReducer.java Mapper number = intermediate table file number Reducer number = dimension (in dict encoding) number + 1 (for cube statistics) Mapper also collects cuboid statistics by using HyperLogLog; For UHC column, Kylin can use multiple reducers to do the deduction in-parallel (disabled by default); • kylin.engine.mr.uhc-reducer-count=1 © Kyligence Inc. 2019, Confidential.
14 .4. Build Dimension Dictionary • Build Trie dictionary for each dimension, basing on the distinct values fetched in the previous step; • Persist dictionary into Kylin meta store © Kyligence Inc. 2019, Confidential.
15 .5. Save Cuboid Statistics • Save cuboid statistics (each cuboid’s size) to Kylin meta store, for future use • Estimate reducer numbers for each step; • Estimate HBase table size; • Determine the merged segment size; © Kyligence Inc. 2019, Confidential.
16 .6. Create HTable • Create the HBase table based on cuboid statistics • How many regions: n = (Cube estimated size) / (each region size) • Region split keys:1,2,3,… n © Kyligence Inc. 2019, Confidential.
17 .7. Build base cuboid • Base cuboid is the aggregation of all dimensions; • All other cuboids can be aggregated from the base cuboid; • The input of base cuboid is source data, encode dimension and measure into byte array; • Aggregate measures in the reducer side; • Output key: [shard][cuboid_id][dim1][dim2]…[dimN] • Output value: [measure1][measure2]…[measureN] • Job: BaseCuboidJob • Mapper: HiveToBaseCuboidMapper • Reducer: CuboidReducer © Kyligence Inc. 2019, Confidential.
18 .8. Build N-D cuboid • Use the previous step’s output as input, calculate next layer’s cuboids. • Parse the byte array, remove the aggregated dimension, output again. • Job: NDCuboidJob • Mapper: NDCuboidMapper • Reducer: CuboidReducer • Core: CuboidScheduler.java • CuboidScheduler determines the spanning tree of the cuboids; DefaultCuboidScheduler is the default implementation; © Kyligence Inc. 2019, Confidential.
19 .8. Convert Cuboid to HFile & Load Hfile to HBase • Use HBase Hadoop API to generate Hfiles • Key doesn’t need change, just write Cube measures into different Column Families (if more than 1 CF) • Job: CubeHFileJob • Mapper: CubeHFileMapper • Reducer: KeyValueReducer • Number of reducer = HFile numbers, determined by these parameters: • kylin.hbase.region.cut=2 • kylin.hbase.hfile.size.gb=1 © Kyligence Inc. 2019, Confidential.
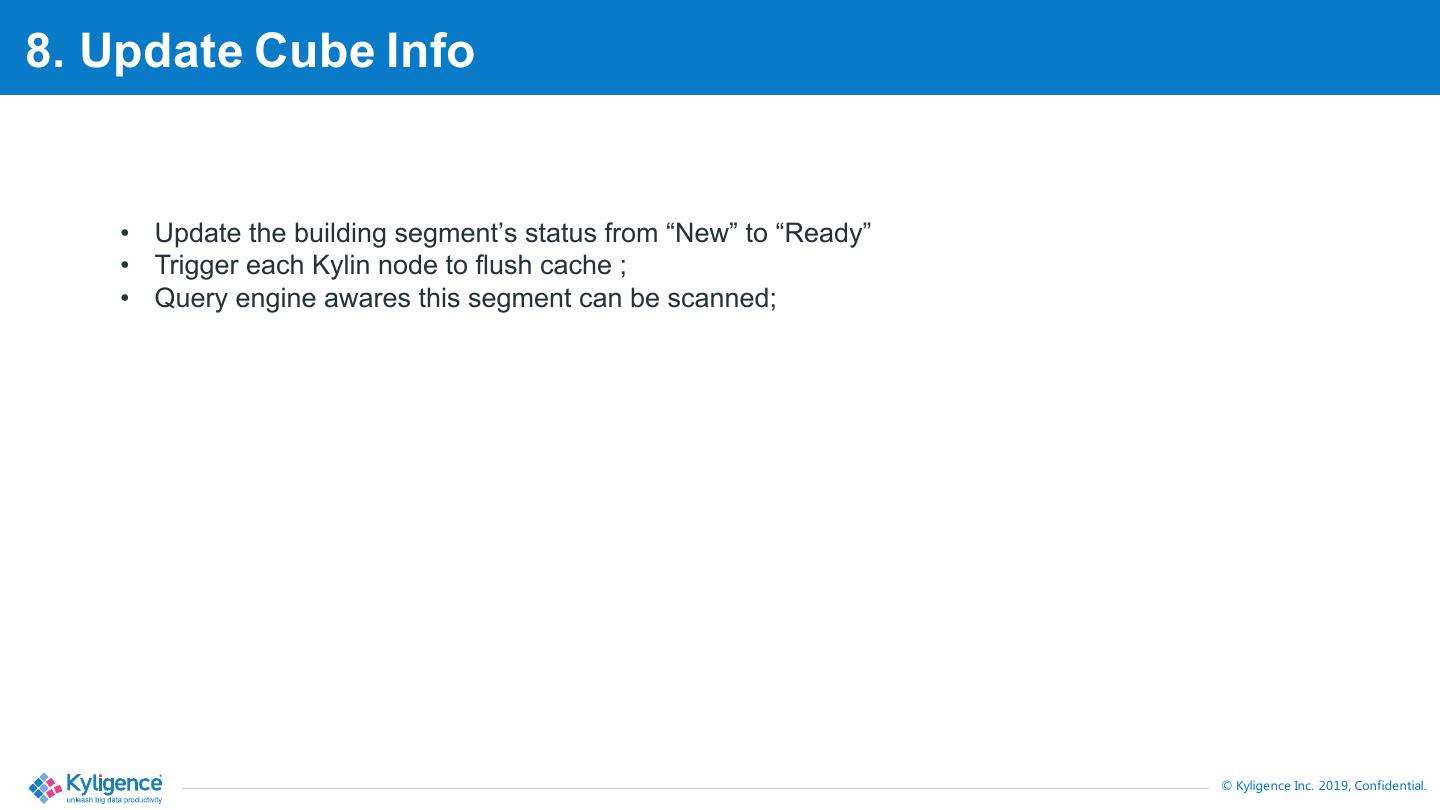
20 .8. Update Cube Info • Update the building segment’s status from “New” to “Ready” • Trigger each Kylin node to flush cache ; • Query engine awares this segment can be scanned; © Kyligence Inc. 2019, Confidential.
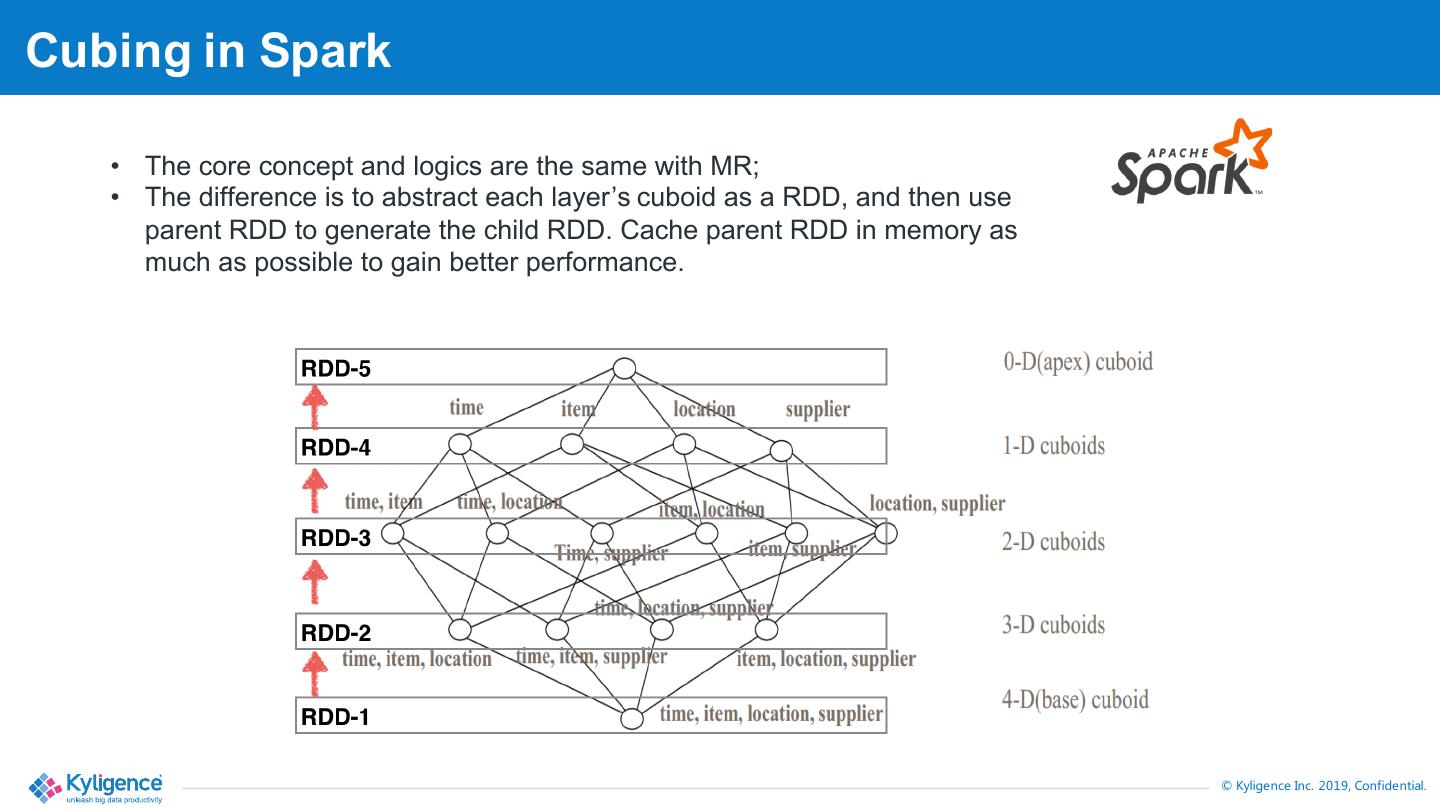
21 .Cubing in Spark • The core concept and logics are the same with MR; • The difference is to abstract each layer’s cuboid as a RDD, and then use parent RDD to generate the child RDD. Cache parent RDD in memory as much as possible to gain better performance. © Kyligence Inc. 2019, Confidential.
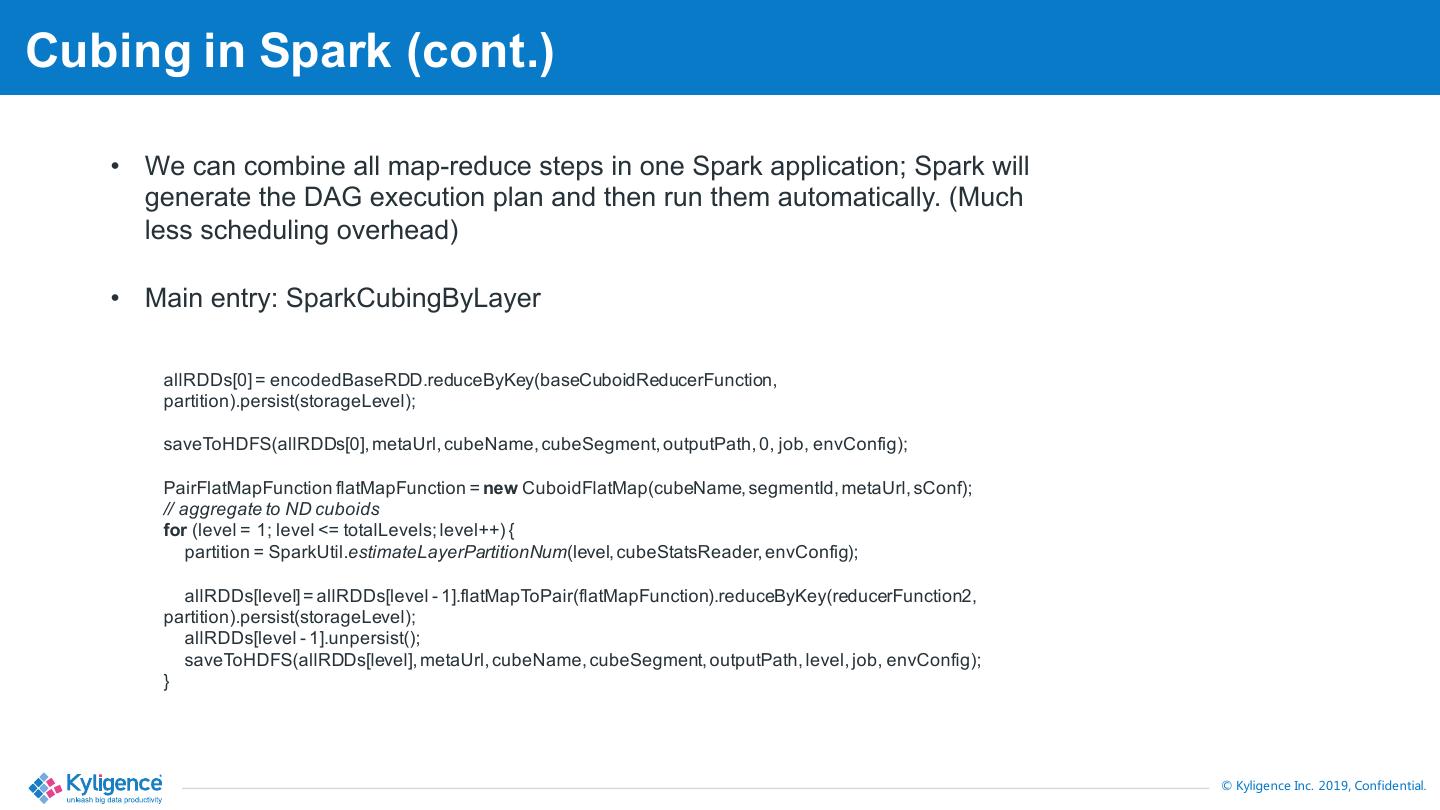
22 .Cubing in Spark (cont.) • We can combine all map-reduce steps in one Spark application; Spark will generate the DAG execution plan and then run them automatically. (Much less scheduling overhead) • Main entry: SparkCubingByLayer allRDDs[0] = encodedBaseRDD.reduceByKey(baseCuboidReducerFunction, partition).persist(storageLevel); saveToHDFS(allRDDs[0], metaUrl, cubeName, cubeSegment, outputPath, 0, job, envConfig); PairFlatMapFunction flatMapFunction = new CuboidFlatMap(cubeName, segmentId, metaUrl, sConf); // aggregate to ND cuboids for (level = 1; level <= totalLevels; level++) { partition = SparkUtil.estimateLayerPartitionNum(level, cubeStatsReader, envConfig); allRDDs[level] = allRDDs[level - 1].flatMapToPair(flatMapFunction).reduceByKey(reducerFunction2, partition).persist(storageLevel); allRDDs[level - 1].unpersist(); saveToHDFS(allRDDs[level], metaUrl, cubeName, cubeSegment, outputPath, level, job, envConfig); } © Kyligence Inc. 2019, Confidential.
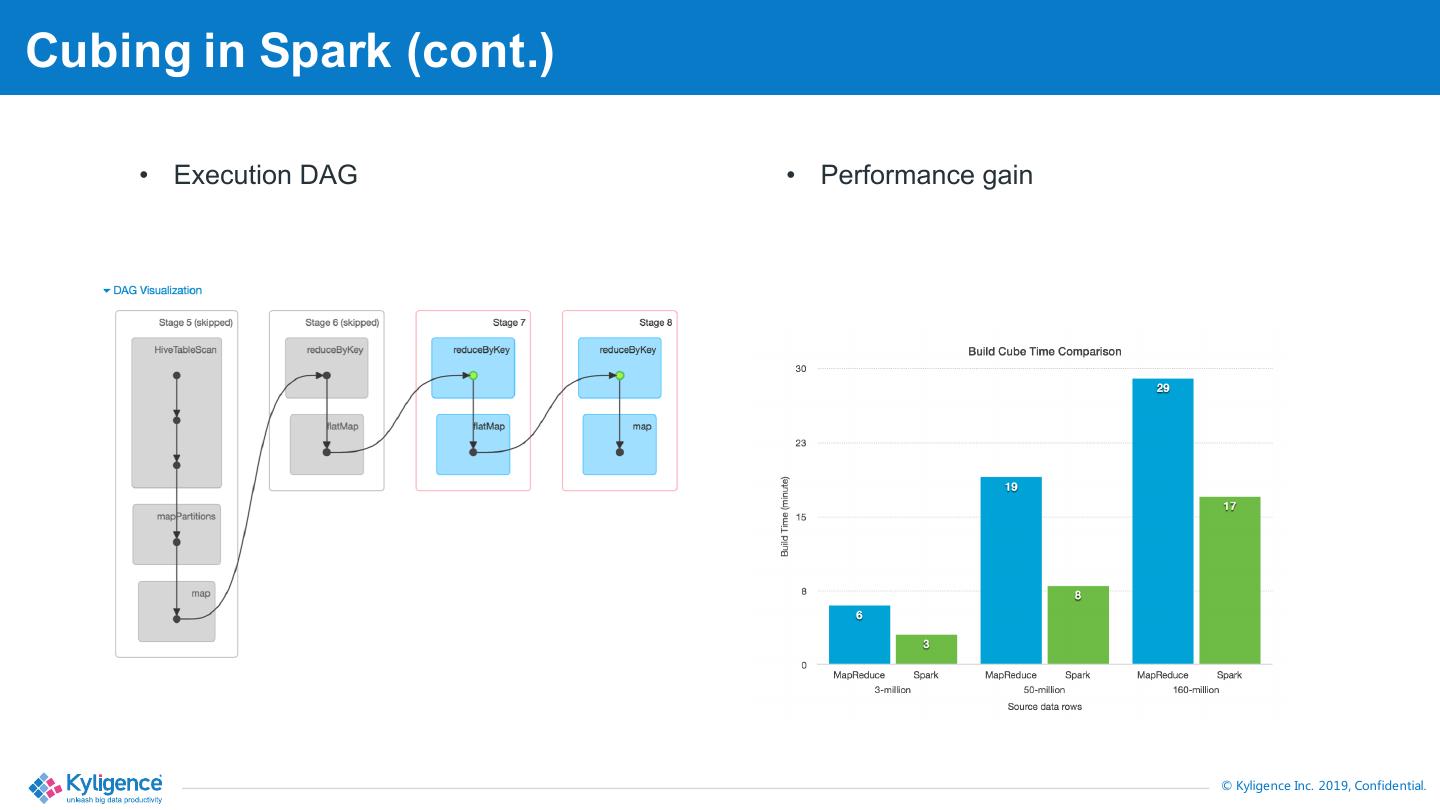
23 .Cubing in Spark (cont.) • Execution DAG • Performance gain © Kyligence Inc. 2019, Confidential.
24 .We’re hiring! Address 上海市浦东新区 亮秀路 112 号 Y1 座 405 Telephone +86 21-61060928 E-mail info@Kyligence.io Website http://kyligence.io © Kyligence Inc. 2019, Confidential.
25 .THANK YOU © Kyligence Inc. 2019, Confidential.
26 .
3秒后跳转登录页面
去登陆

