























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Hbase Tuning
来自Salesforce的首席架构师介绍HBase的性能调优手段,比如常见的HDFS配置,RegionServer配置,Compaction设置,ColumnFamily设置,GC的设置,服务器硬件配置,HBase客户端的配置,操作系统Linux的配置。是HBase应用工程师非常难得的参考资料,介绍非常全面。
展开查看详情
1 . HBase Tuning Performance and Correctness Lars Hofhansl Principal Architect, Salesforce (10 years!) HBase, Phoenix Committer, PMC Apache Incubator PMC Apache Foundation Member http://hadoop-hbase.blogspot.com/
2 .
3 . Boring Topic Experiment with Colorful Slides
4 . Agenda • HDFS • HBase – Server • HBase – Client • Correctness • Performance
5 .HDFS hdfs-site.xml
6 . HDFS - Background • Stores HBase WAL and HFiles • No sync-to-disk by default • Datanode writes tmp file, moves it into place • Old data lost on power outage
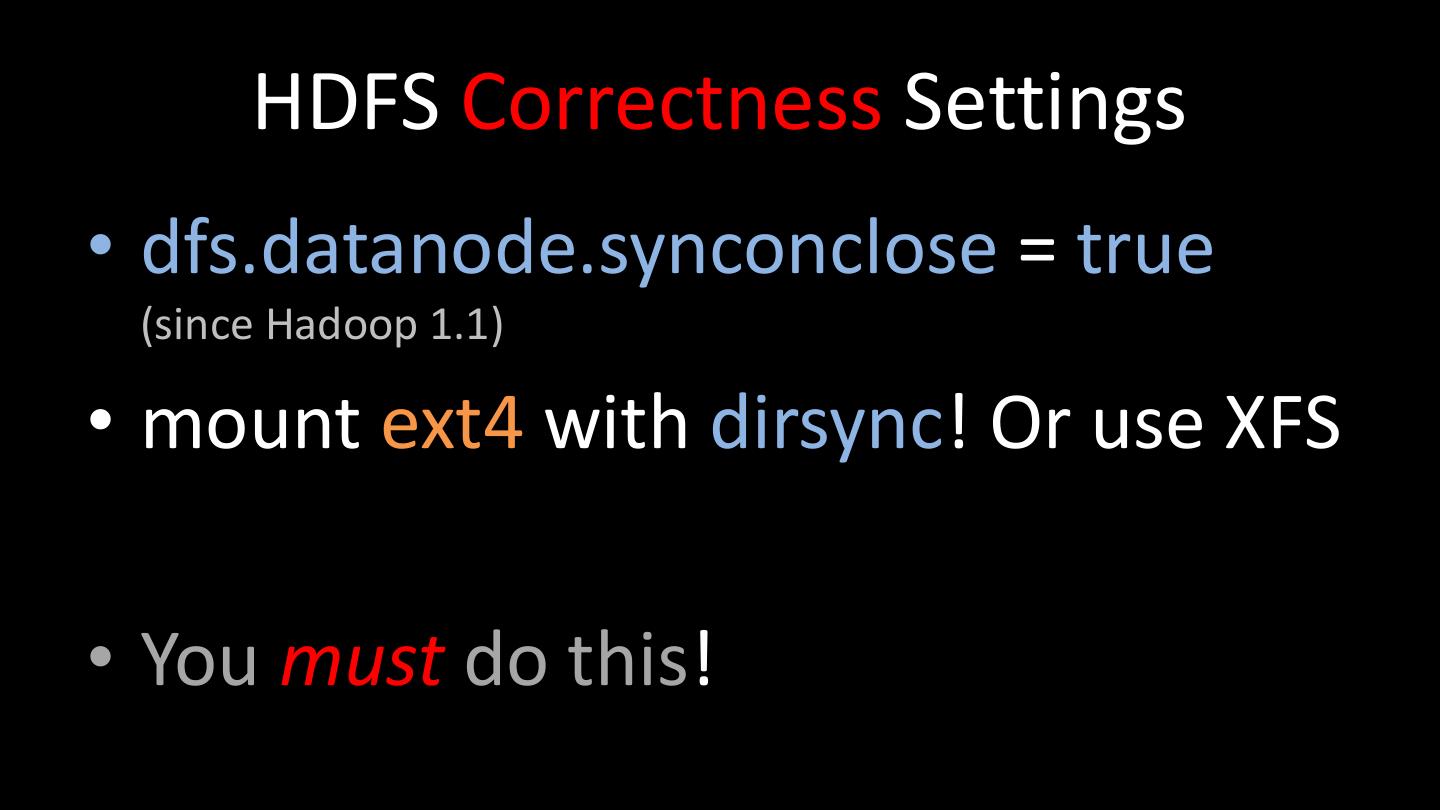
7 . HDFS Correctness Settings • dfs.datanode.synconclose = true (since Hadoop 1.1) • mount ext4 with dirsync! Or use XFS • You must do this!
8 . HDFS Performance Settings 1. Sync behind writes 2. Stale Datanode Detection 3. Short Circuit Reads 4. Miscellaneous Settings
9 . HDFS Sync Behind Writes • Syncs partial blocks to disk – best effort (OK, since blocks are immutable) • Necessary with sync-on-close for performance • Always enable this • dfs.datanode.sync.behind.writes = true (Since Hadoop 1.1)
10 . Stale Datanodes - Background • Datanodes (DNs) send block reports to the Namenode (NN) • After 10min(!) w/o a report, DN is declared dead • NN will still direct reads and writes to those DNs • Bad for recovery. Down by 1 DN by definition. (every 3rd read/write goes to a bad DN)
11 . Stale Datanodes - Detection Don’t use a DN for read or write when it looks like it is stale (default off) • dfs.namenode.avoid.read.stale.datanode = true • dfs.namenode.avoid.write.stale.datanode = true • dfs.namenode.stale.datanode.interval = 30000 (default)
12 . HDFS short circuit reads Read local blocks directly without DN, when RegionServers and DNs are co-located. • dfs.client.read.shortcircuit = true • dfs.client.read.shortcircuit.buffer.size = 131072 (important, OOM on direct buffers, default on 0.98+) • hbase.regionserver.checksum.verify = true (default on 0.98+) • dfs.domain.socket.path (local Unix domain socket, not group or world readable)
13 . Misc HDFS tips Keep DN running with some failed disks • dfs.datanode.failed.volumes.tolerated = <N> (tolerate losing this many disks) Distribute data across disks at a DN • dfs.datanode.fsdataset.volume.choosing.policy = AvailableSpaceVolumeChoosingPolicy (HDFS-1804 hit drives with more space with higher probability for writes when free space differs by more than 10GB by default)
14 . Misc HDFS settings (just trust me on these) • dfs.block.size = 268435456 (note that WAL is rolled at 95% of this) • ipc.server.tcpnodelay = true • ipc.client.tcpnodelay = true
15 . Misc HDFS settings (just trust me on these, really) • dfs.datanode.max.xcievers = 8192 • dfs.namenode.handler.count = 64 • dfs.datanode.handler.count = 8 (match number of spindles)
16 .
17 . HBase RegionServer Settings hbase-site.xml
18 .Compactions
19 . Compactions - Background • Writes are buffered in the memstore • Memstore contents flushed to disk as HFiles • Need to limit # HFiles by rewriting small HFiles into fewer larger ones • Remove deleted and expired Cells • Same data written multiple times => Write Amplification!
20 . Read vs. Write • Read requires merging HFiles => fewer is better • Write throughput better with fewer compactions => leads to more files • Optimize for Read or Write, not both
21 .Write Amplification Vs. Read Performance
22 . Control the number of HFiles • hbase.hstore.blockingStoreFiles = 10 (do not allow more flushes when there more than <N> files) small for read, large for write, will stop flushes and writes • hbase.hstore.compactionThreshold = 3 (number of files that starts a compaction) small for read, large for write • hbase.hregion.memstore.flush.size = 128 (max memstore size, default is good) larger good for fewer compaction (watch Region Server heap)
23 . Time Based Compactions • HBase does time based major compactions • expensive, always at wrong time • hbase.hregion.majorcompaction = 604800000 (week, default) • hbase.hregion.majorcompaction.jitter = 0.5 (½ week, default)
24 . Memstore/Cache Sizing • hbase.hregion.memstore.flush.size = 128 • hbase.hregion.memstore.block.multiplier (allow single memstore to grow by this multiplier, good for heavy, bursty writes) • hbase.regionserver.global.memstore.upperLimit (0.98) hbase.regionserver.global.memstore.size (1.0+) (percent of heap, default 0.4, decrease for read heavy load) • hfile.block.cache.size (percent heap used for the block cache, default 0.4)
25 .Autotune BlockCache vs. Memstores (1.0+) HBASE-5349, not well tested, Must Experiment • hbase.regionserver.global.memstore.size.{max|min}.range • hfile.block.cache.size.{max|min}.range • hbase.regionserver.heapmemory.tuner.class • hbase.regionserver.heapmemory.tuner.period
26 . Data Locality • Essential for Short Circuit Reads • hbase.hstore.min.locality.to.skip.major.compact (compact even when unnecessary to restore locality) • hbase.master.wait.on.regionservers.timeout (allow master to wait a bit upon restart, so not all region go to the first servers who sign in 30-90s is good. Default it 4.5s) • Don’t use the HDFS balancer!
27 .HBase Column Family Settings
28 . Block Encoding • NONE, FAST_DIFF, PREFIX, etc • alter 'test', { NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF' } • Scan friendly, decodes as you scan • Not so Get friendly (might need to decode many previous Cells) • Currently produces a lot of extra garbage • Safe to enable, always
29 . Compression • NONE, GZIP, SNAPPY, etc • create ’test', {NAME => ’cf', COMPRESSION => 'SNAPPY’}} • Compresses entire blocks, not Scan or Get friendly • Typically does not achieve much over block encoding • Blocks cached decompressed, unless hbase.block.data.cachecompressed = true (more cache capacity, but every access needs decompressions) • Need to test with your data
3秒后跳转登录页面
去登陆

