展开查看详情
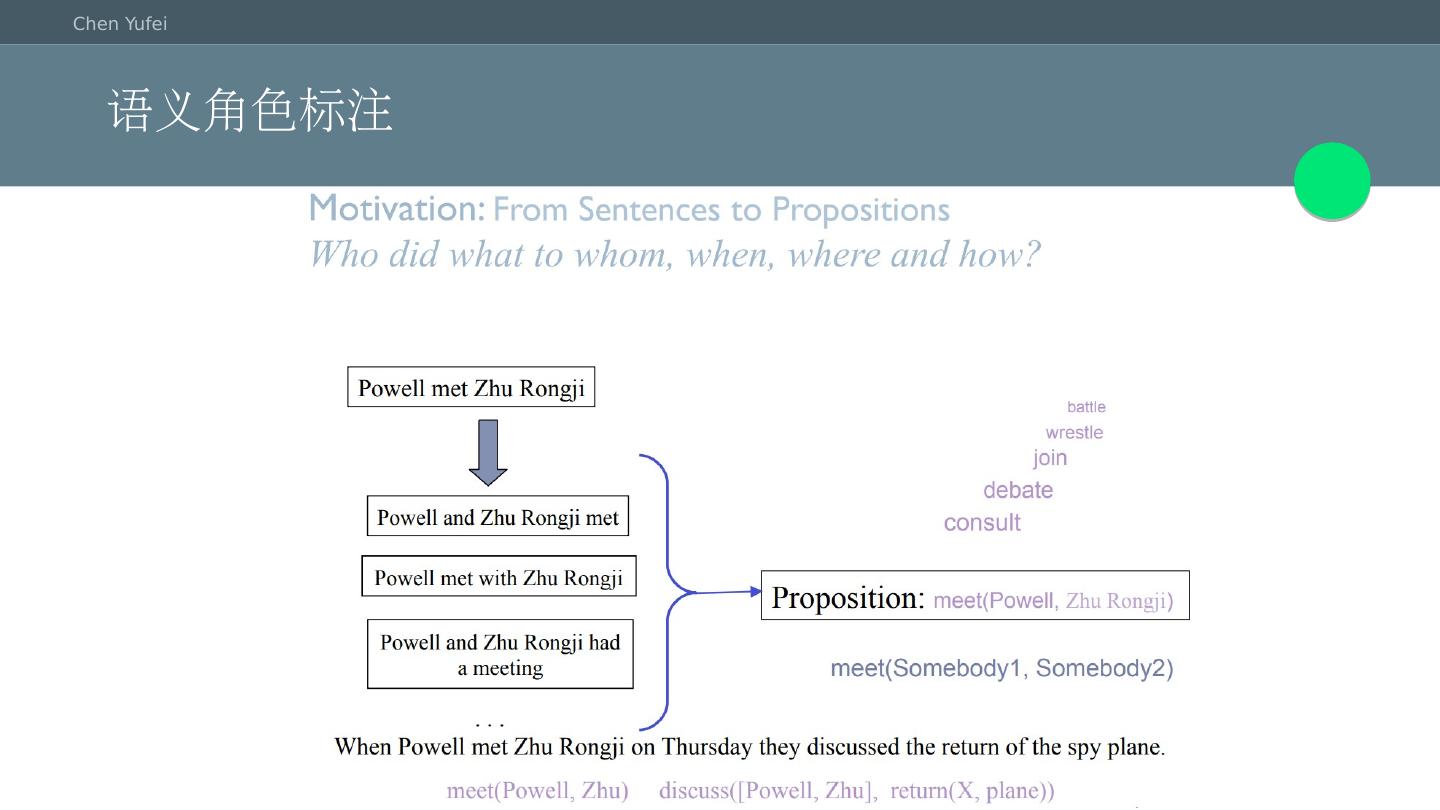
2 .什么是语义分析 语义分析是一个非常宽泛的概念,任何对语言的理解都可以归纳为语义分析的范畴 不同任务中的语义分析具有不同含义 词语级的语义分析:词语消歧、词表示、同义词和上下位词的挖掘 句子级别的语义分析:语义角色标注、语义依存分析
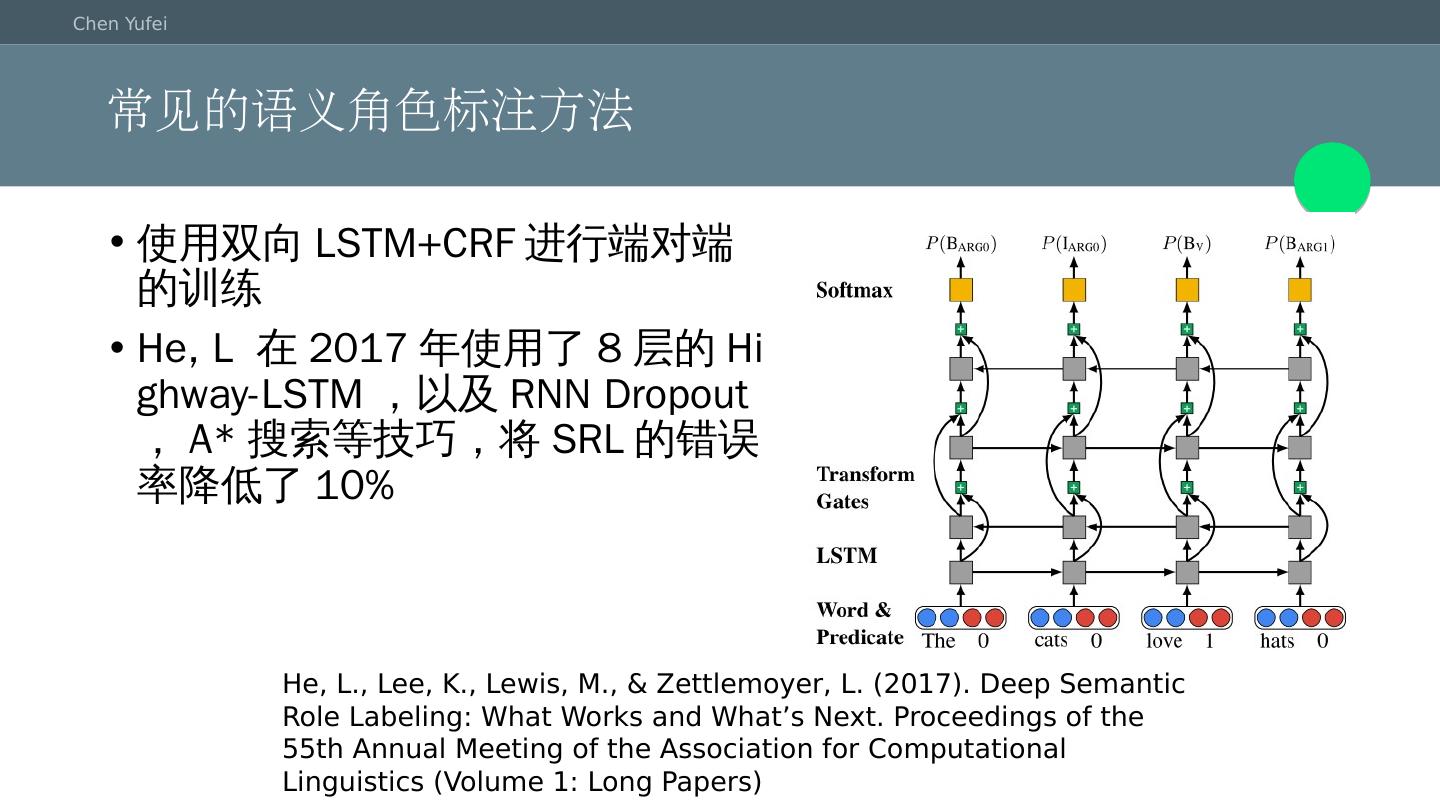
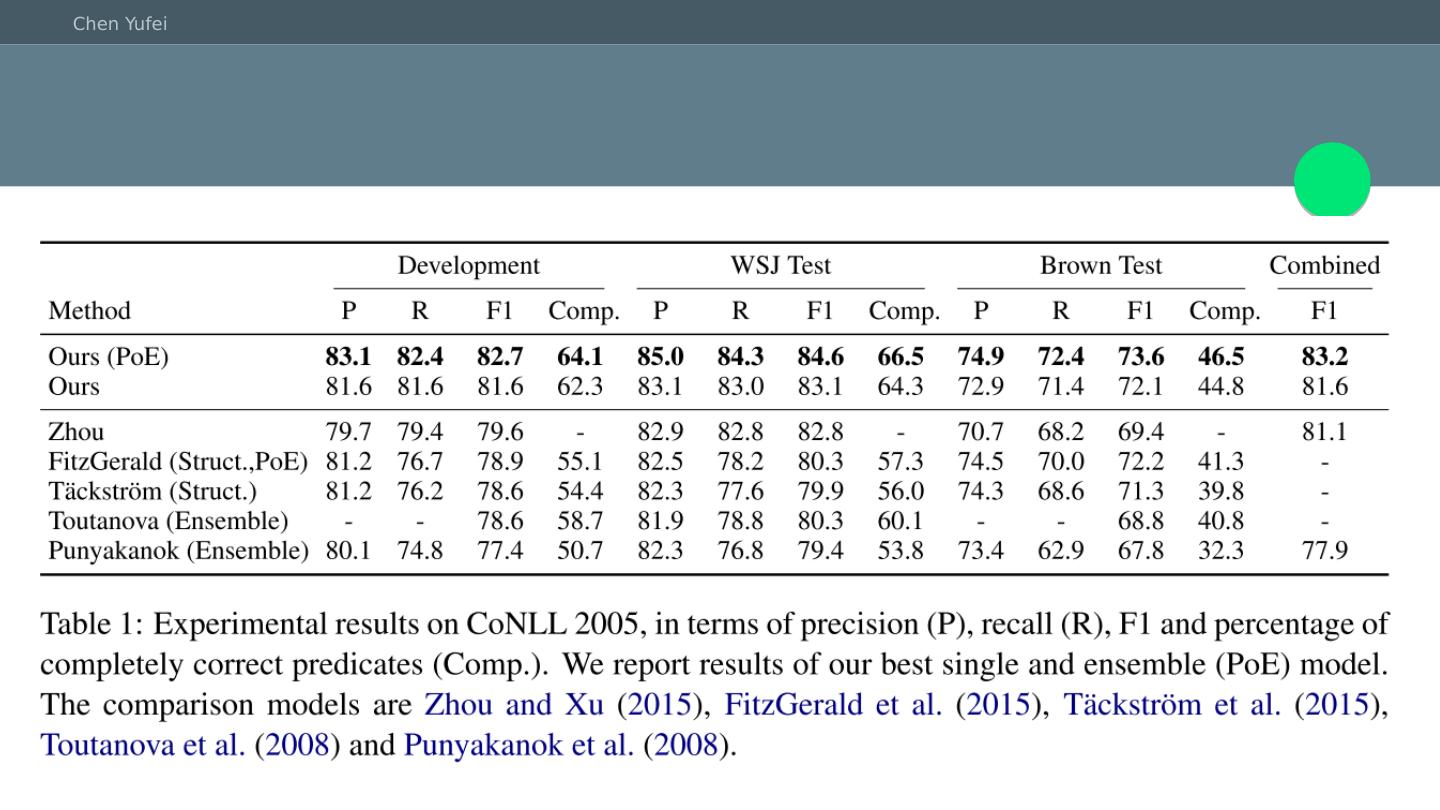
5 .常见的语义角色标注方法 使用双向LSTM+CRF进行端对端的训练 He, L 在2017年使用了8层的Highway-LSTM,以及RNN Dropout,A*搜索等技巧,将SRL的错误率降低了10% He, L., Lee, K., Lewis, M., & Zettlemoyer, L. (2017). Deep Semantic Role Labeling: What Works and What’s Next. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
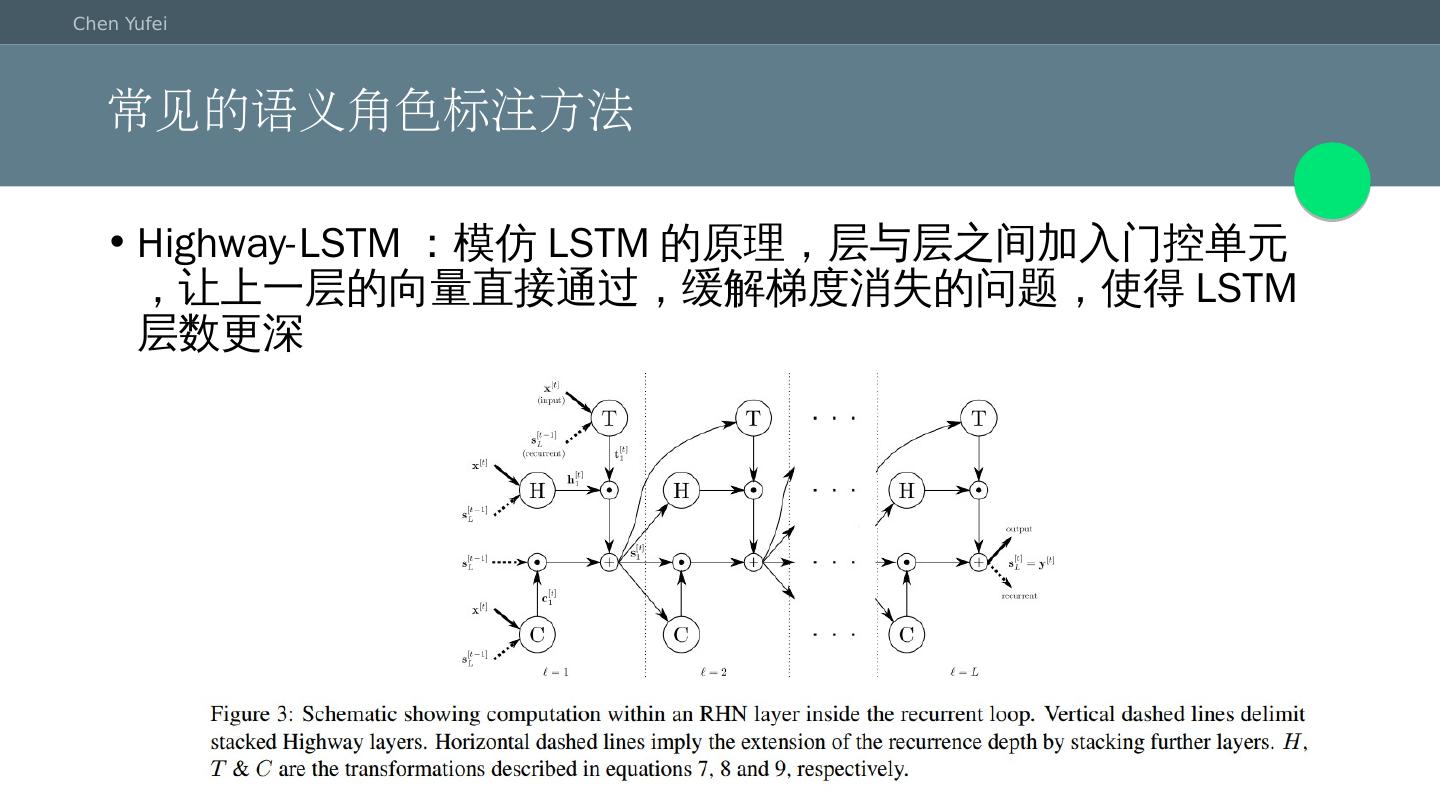
6 .常见的语义角色标注方法 Highway-LSTM:模仿LSTM的原理,层与层之间加入门控单元,让上一层的向量直接通过,缓解梯度消失的问题,使得LSTM层数更深
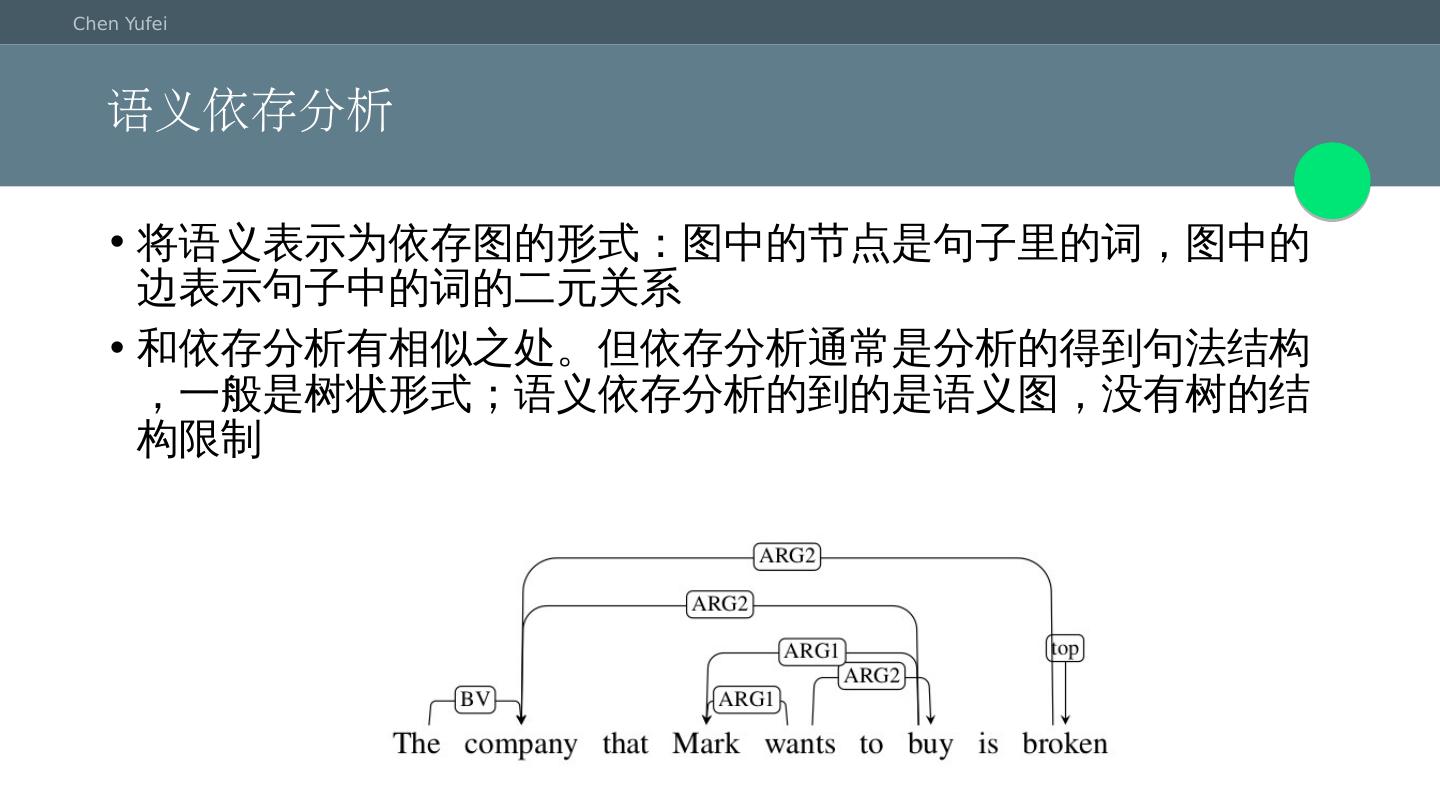
8 .语义依存分析 将语义表示为依存图的形式:图中的节点是句子里的词,图中的边表示句子中的词的二元关系 和依存分析有相似之处。但依存分析通常是分析的得到句法结构,一般是树状形式;语义依存分析的到的是语义图,没有树的结构限制
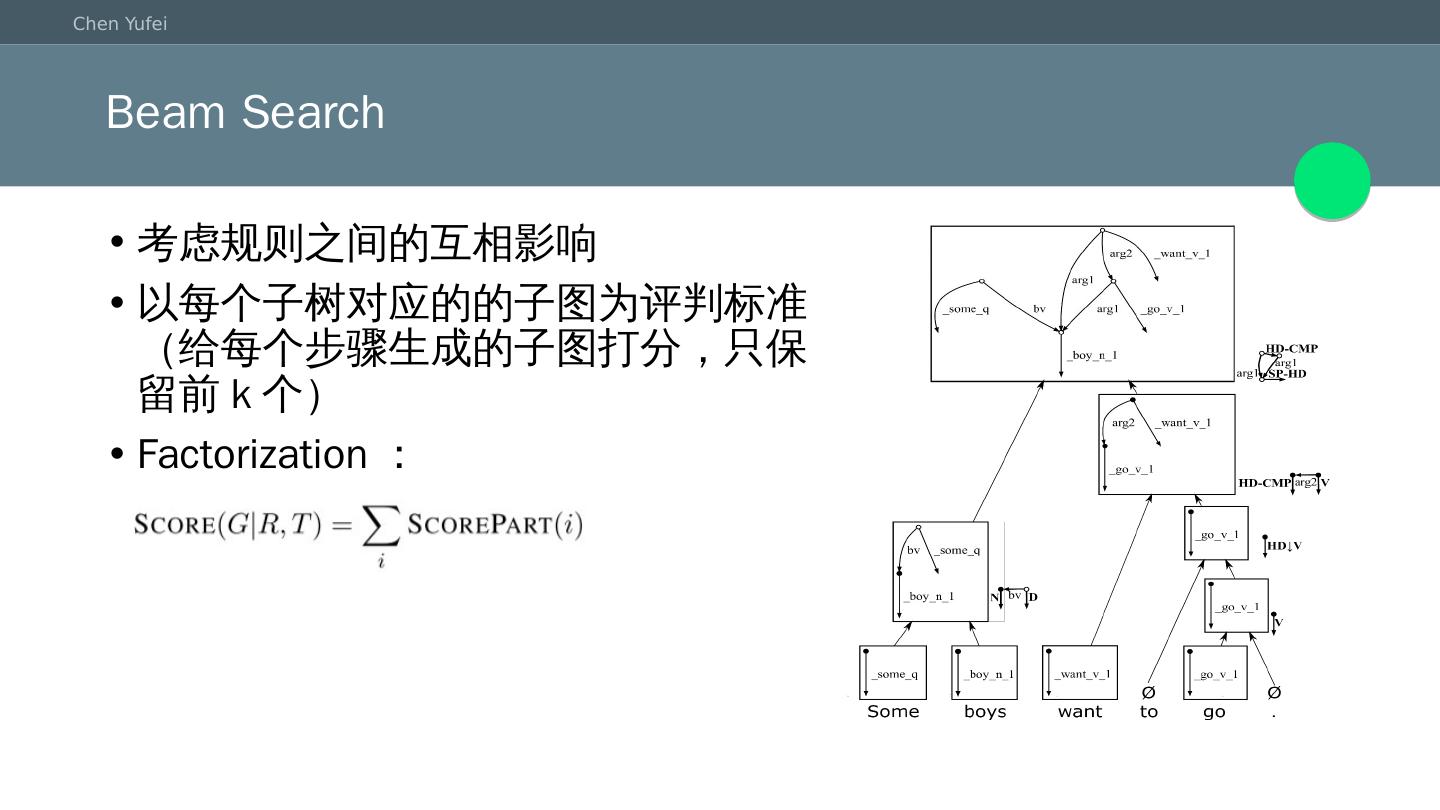
9 .语义依存分析 分析方法和依存分析类似 基于状态转移的方法: 基本模式: 将建立一个依存图分成许多步,每步基于之前构造好的部分子图,决定剩余的子图应该如何构建。
10 .语义依存分析 分析方法和依存分析类似 基于状态转移的方法: 基本模式: 将建立一个依存图分成许多步,每步基于之前构造好的部分子图,决定剩余的子图应该如何构建。
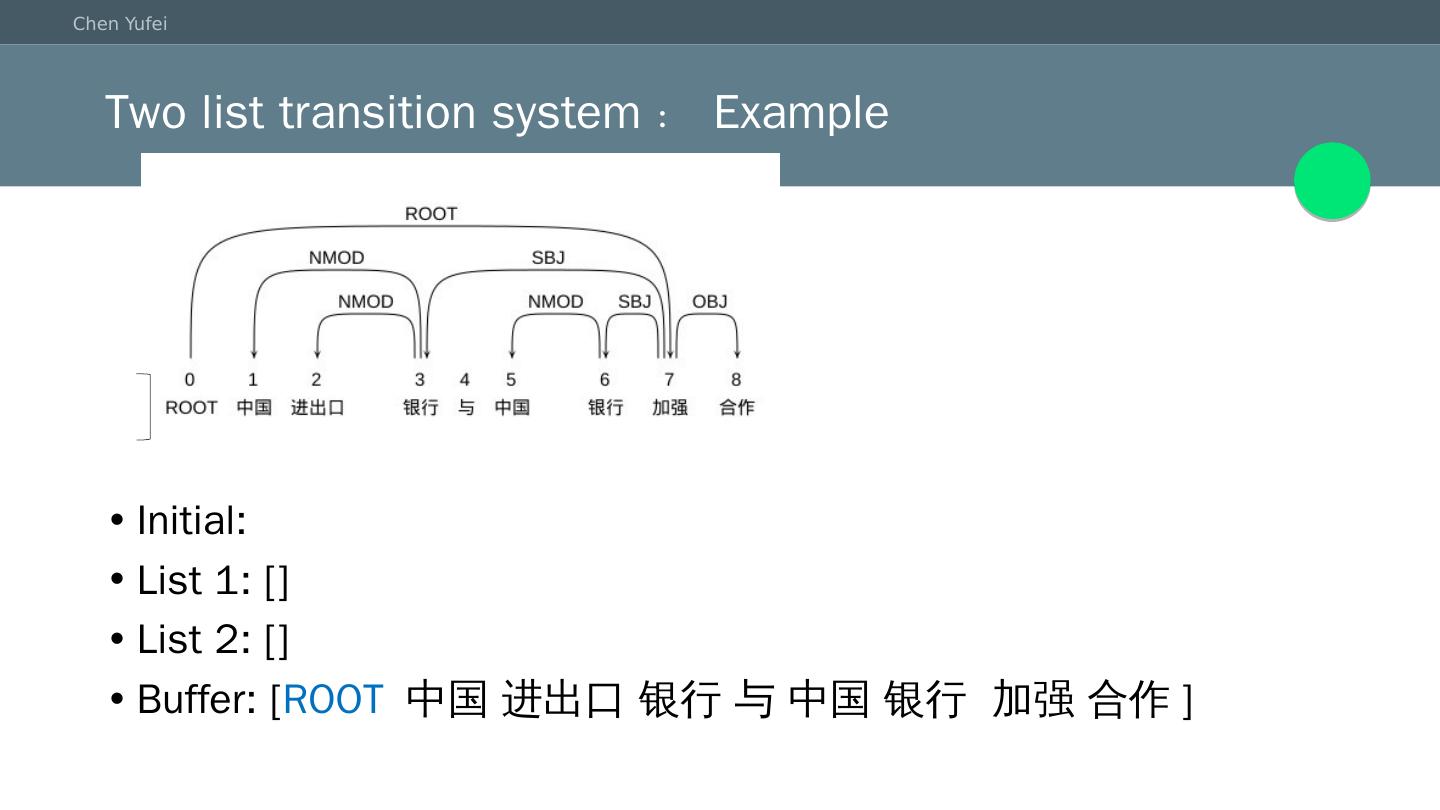
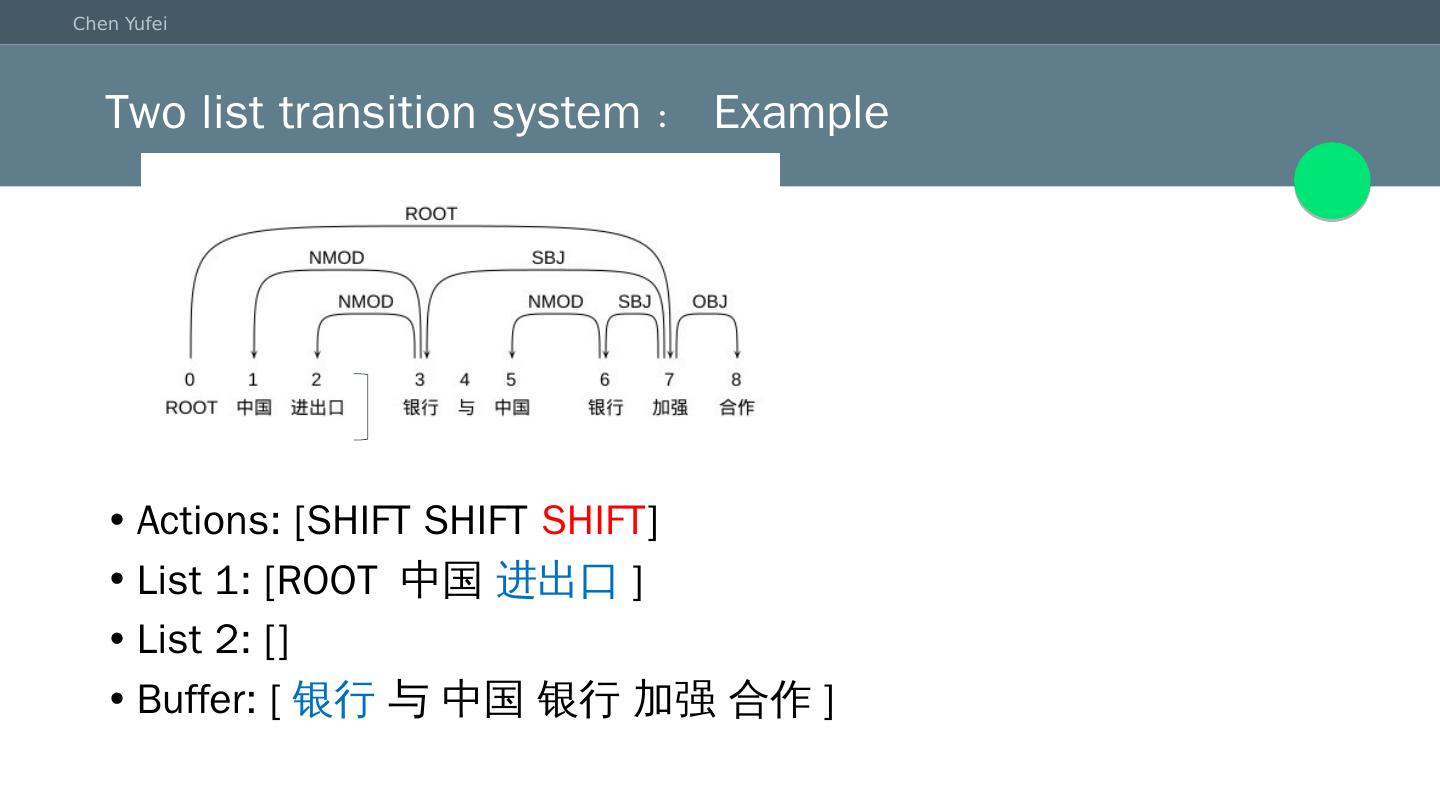
11 .Two list transition system:Example Initial: List 1: [] List 2: [] Buffer: [ ROOT 中国 进出口 银行 与 中国 银行 加强 合作]
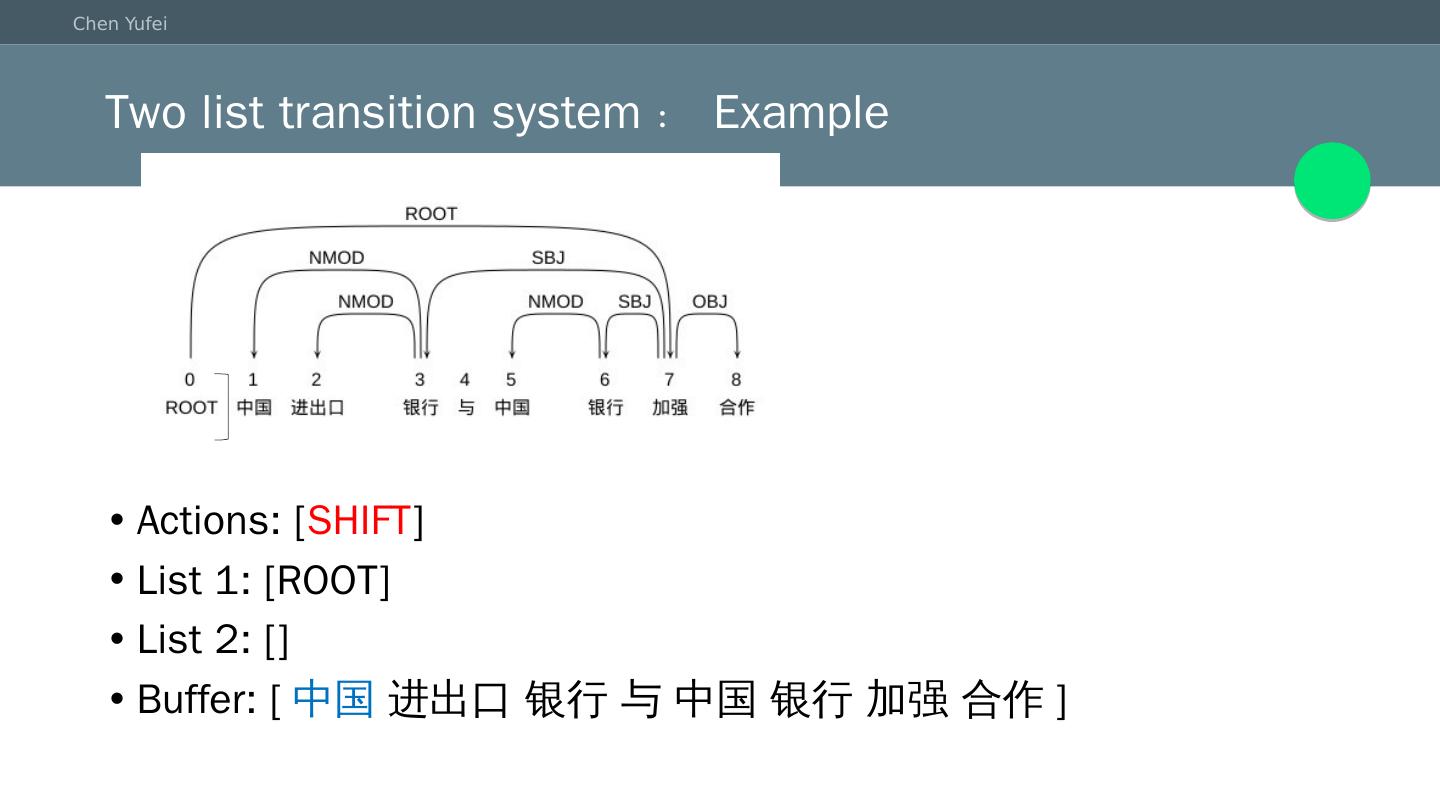
12 .Two list transition system:Example Actions: [ SHIFT ] List 1: [ROOT] List 2: [] Buffer: [ 中国 进出口 银行 与 中国 银行 加强 合作]
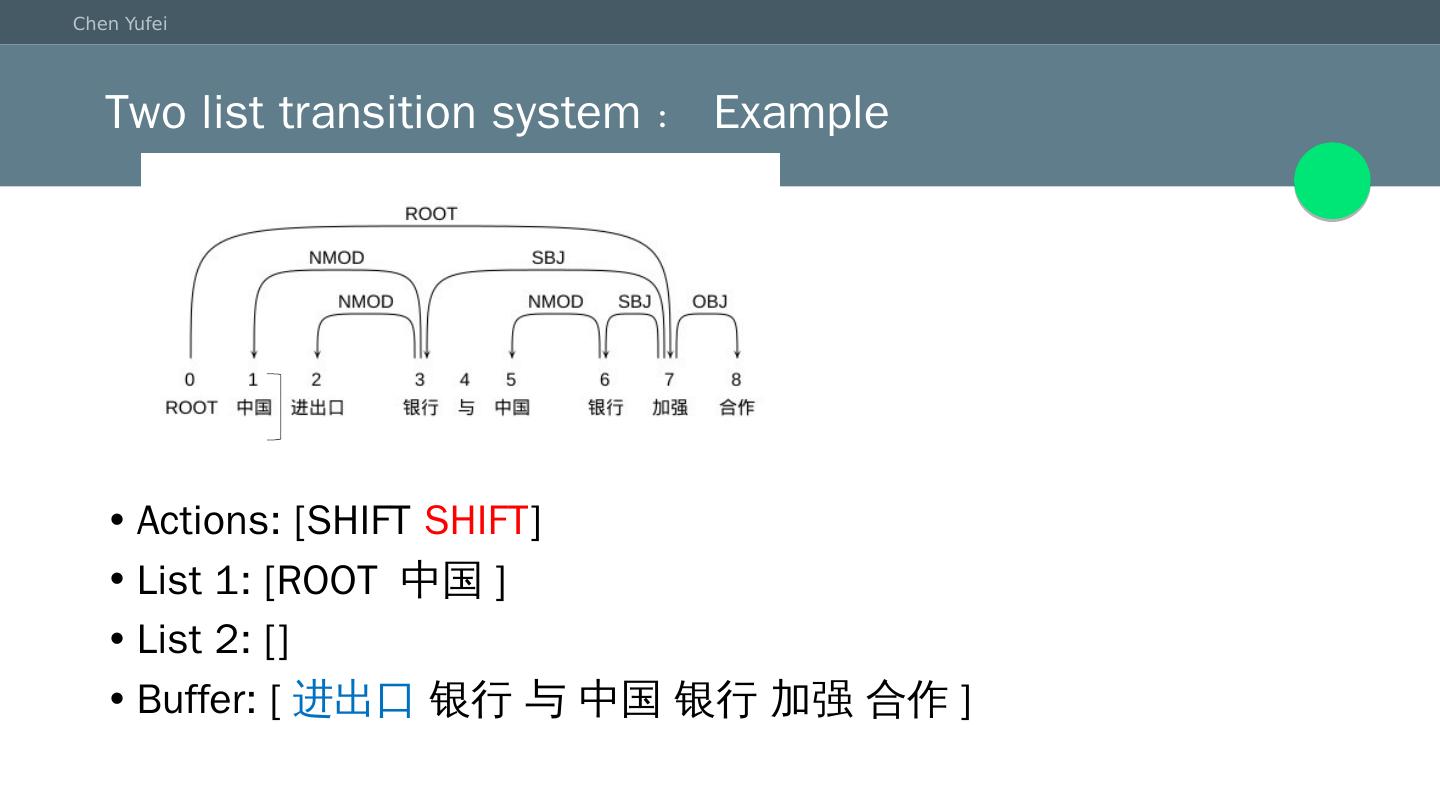
13 .Two list transition system:Example Actions: [SHIFT SHIFT ] List 1: [ROOT 中国 ] List 2: [] Buffer: [ 进出口 银行 与 中国 银行 加强 合作]
14 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ] List 1: [ROOT 中国 进出口 ] List 2: [] Buffer: [ 银行 与 中国 银行 加强 合作]
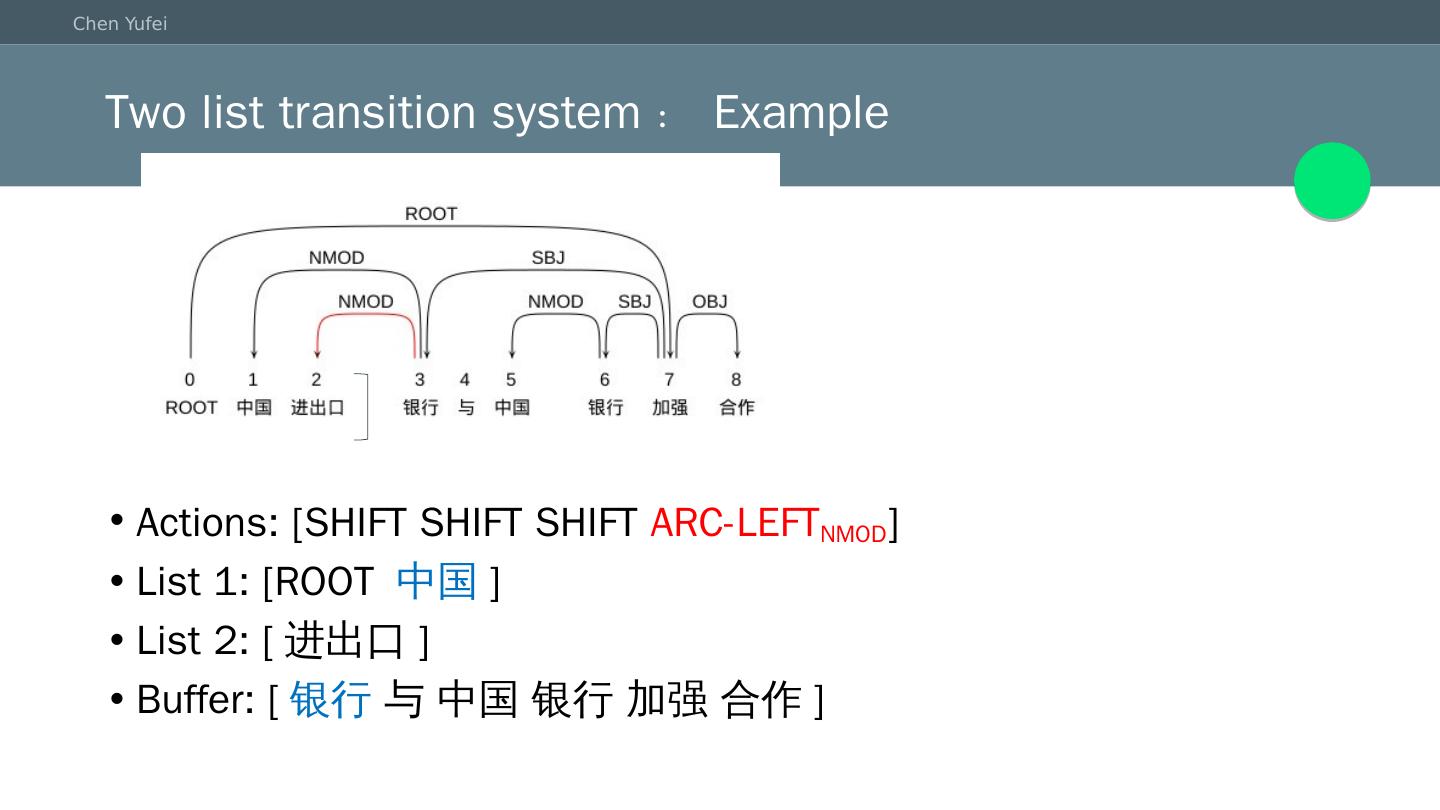
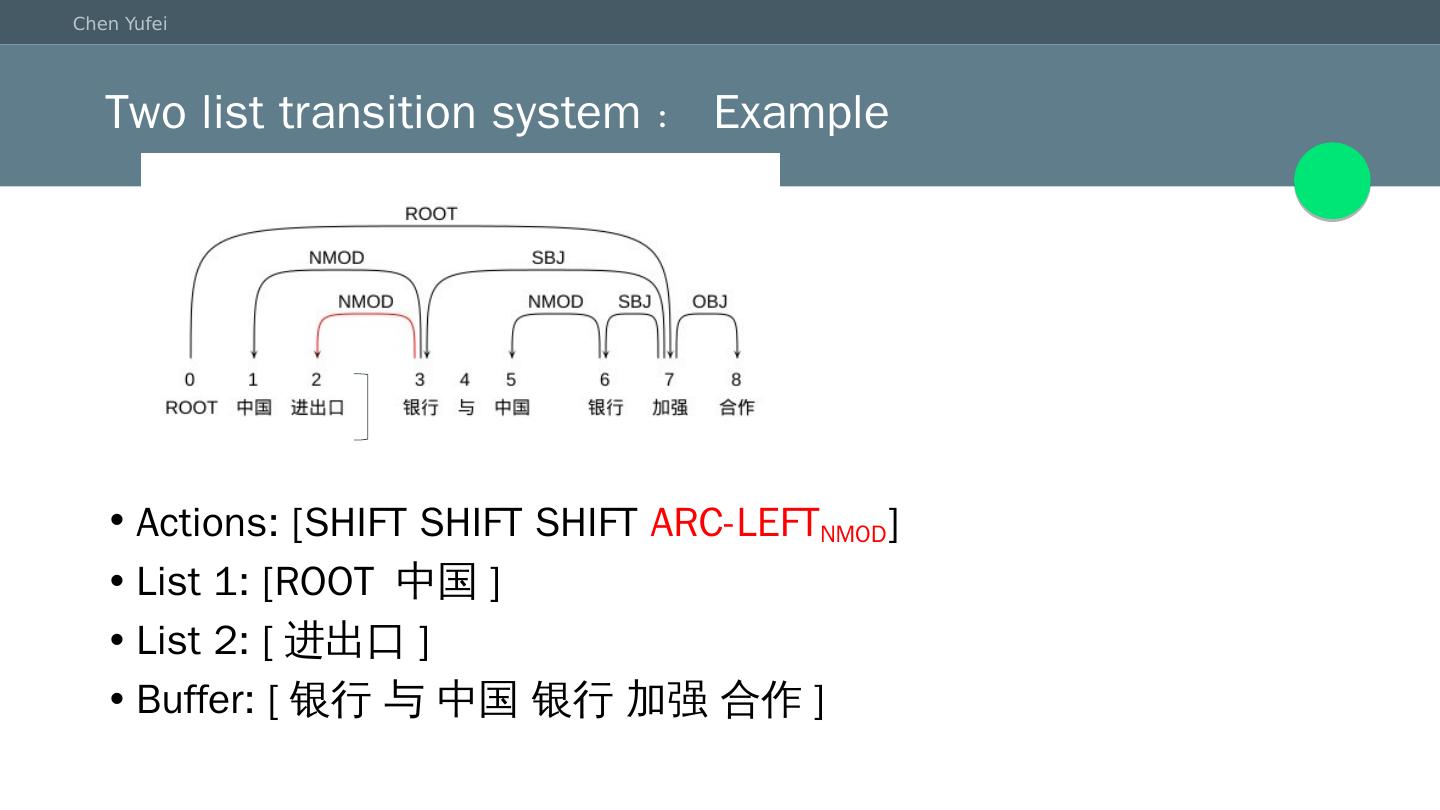
15 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ] List 1: [ROOT 中国 ] List 2: [ 进出口 ] Buffer: [ 银行 与 中国 银行 加强 合作]
16 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ] List 1: [ROOT 中国 ] List 2: [ 进出口 ] Buffer: [银行 与 中国 银行 加强 合作]
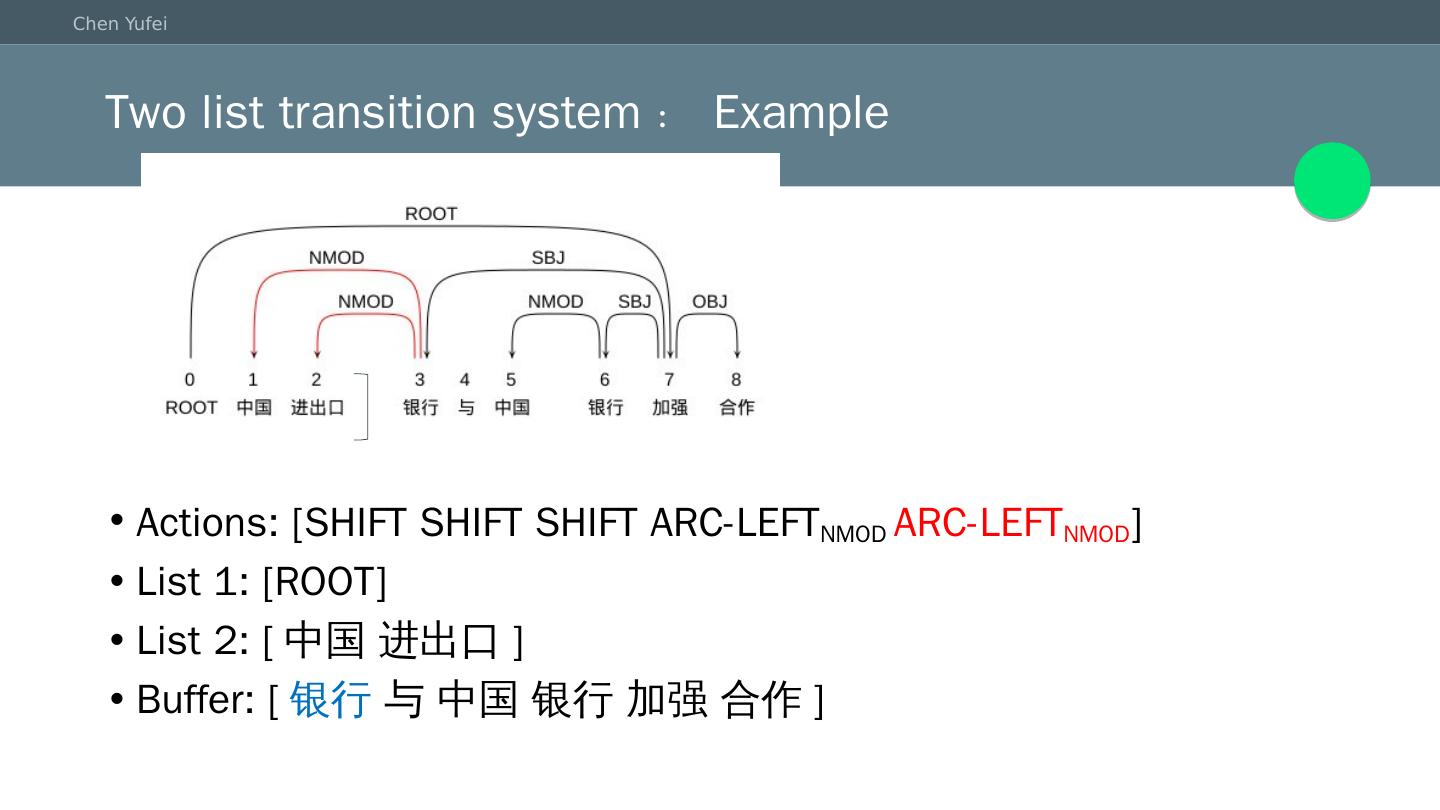
17 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ARC-LEFT NMOD ] List 1: [ROOT] List 2: [ 中国 进出口 ] Buffer: [ 银行 与 中国 银行 加强 合作]
18 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ARC-LEFT NMOD SHIFT ] List 1: [ROOT 中国 进出口 银行 ] List 2: [] Buffer: [与 中国 银行 加强 合作]
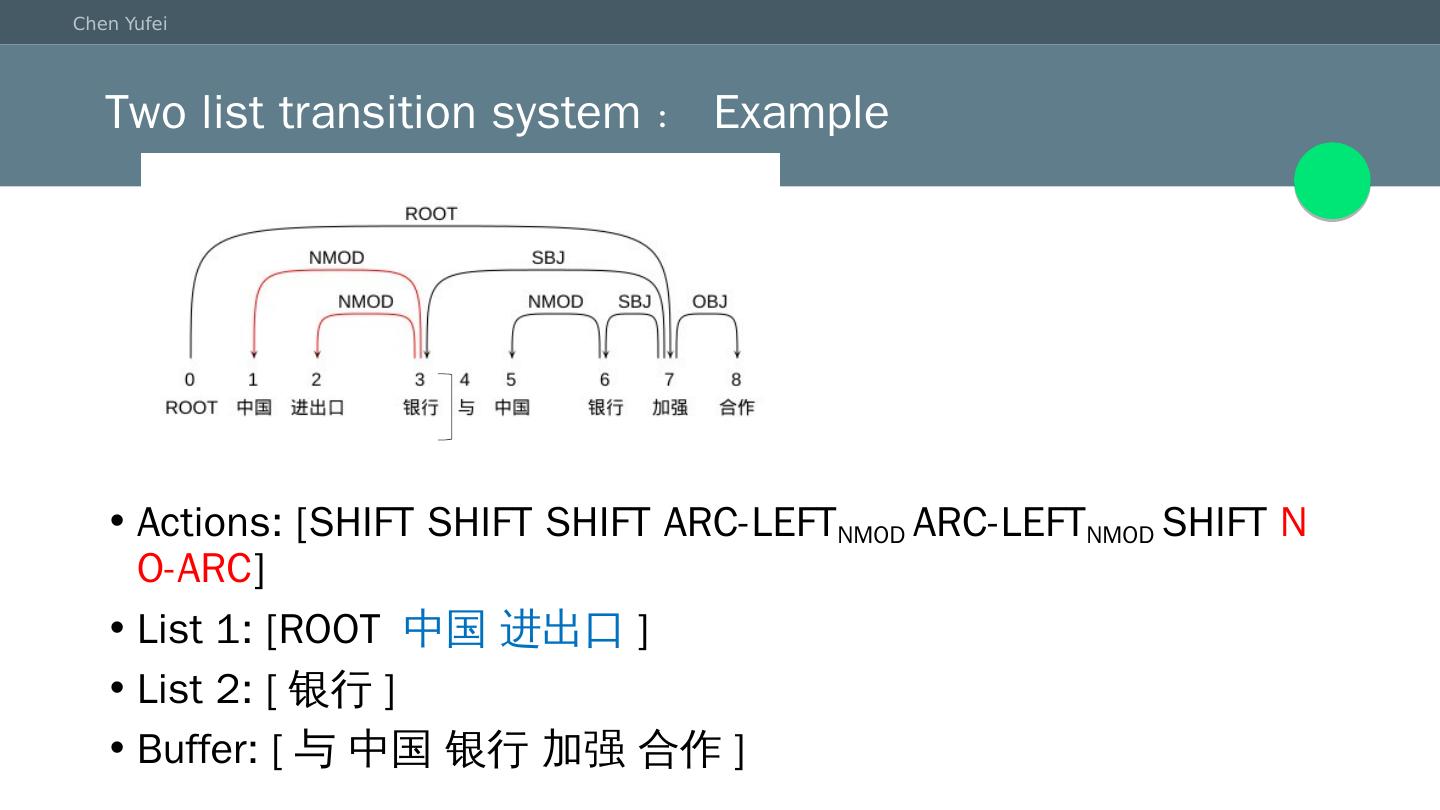
19 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ARC-LEFT NMOD SHIFT NO-ARC ] List 1: [ROOT 中国 进出口 ] List 2: [ 银行 ] Buffer: [与 中国 银行 加强 合作]
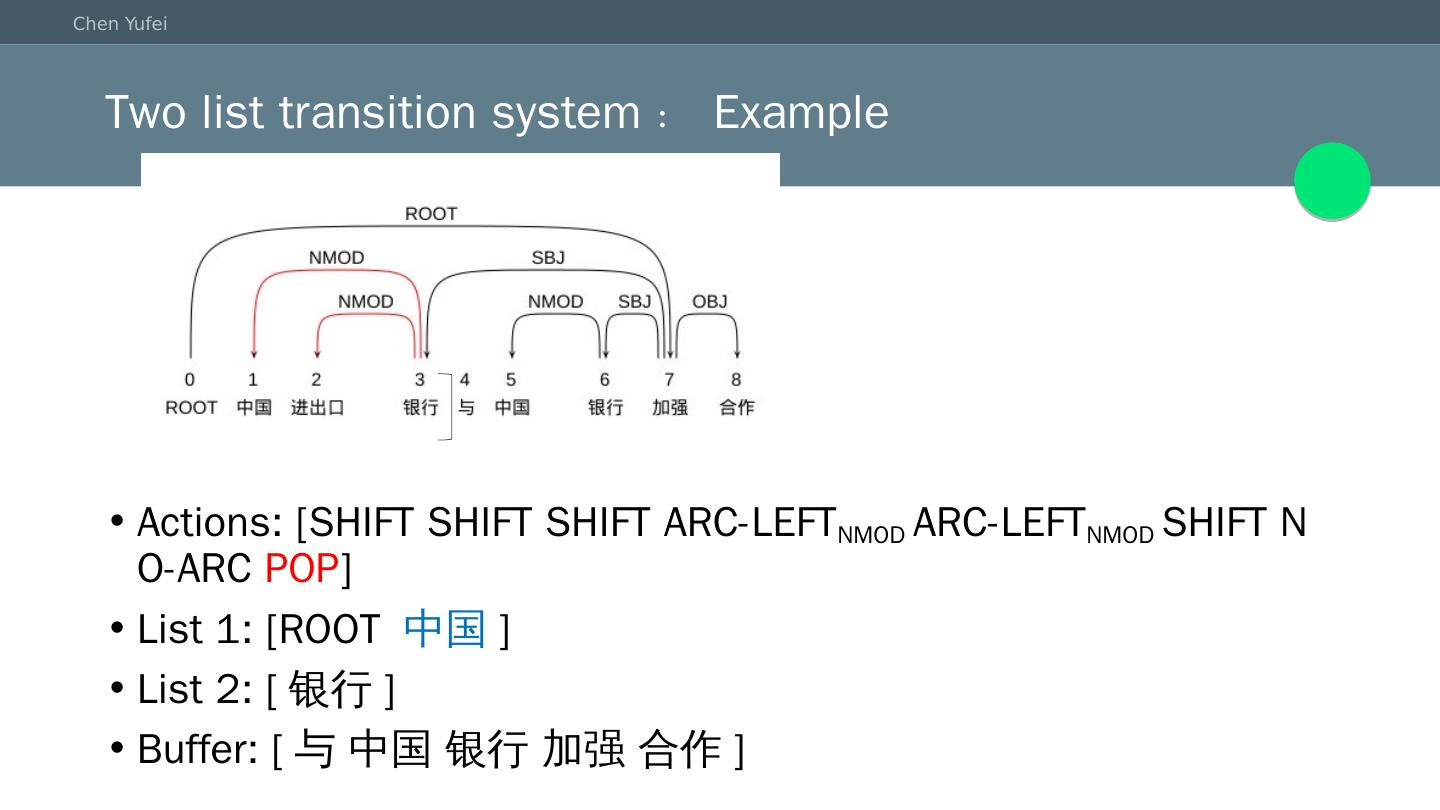
20 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ARC-LEFT NMOD SHIFT NO-ARC POP ] List 1: [ROOT 中国 ] List 2: [ 银行 ] Buffer: [与 中国 银行 加强 合作]
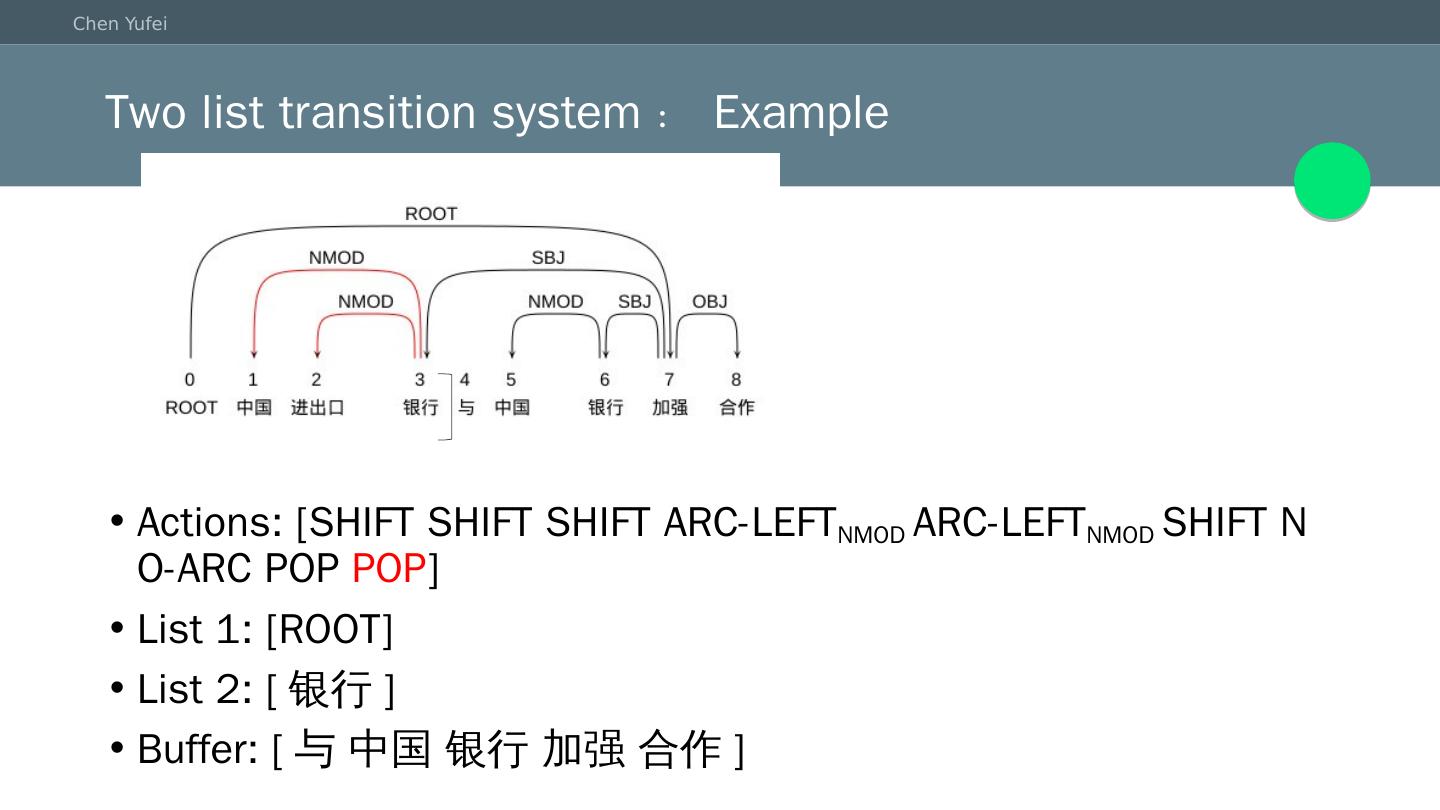
21 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ARC-LEFT NMOD SHIFT NO-ARC POP POP ] List 1: [ROOT] List 2: [ 银行 ] Buffer: [与 中国 银行 加强 合作]
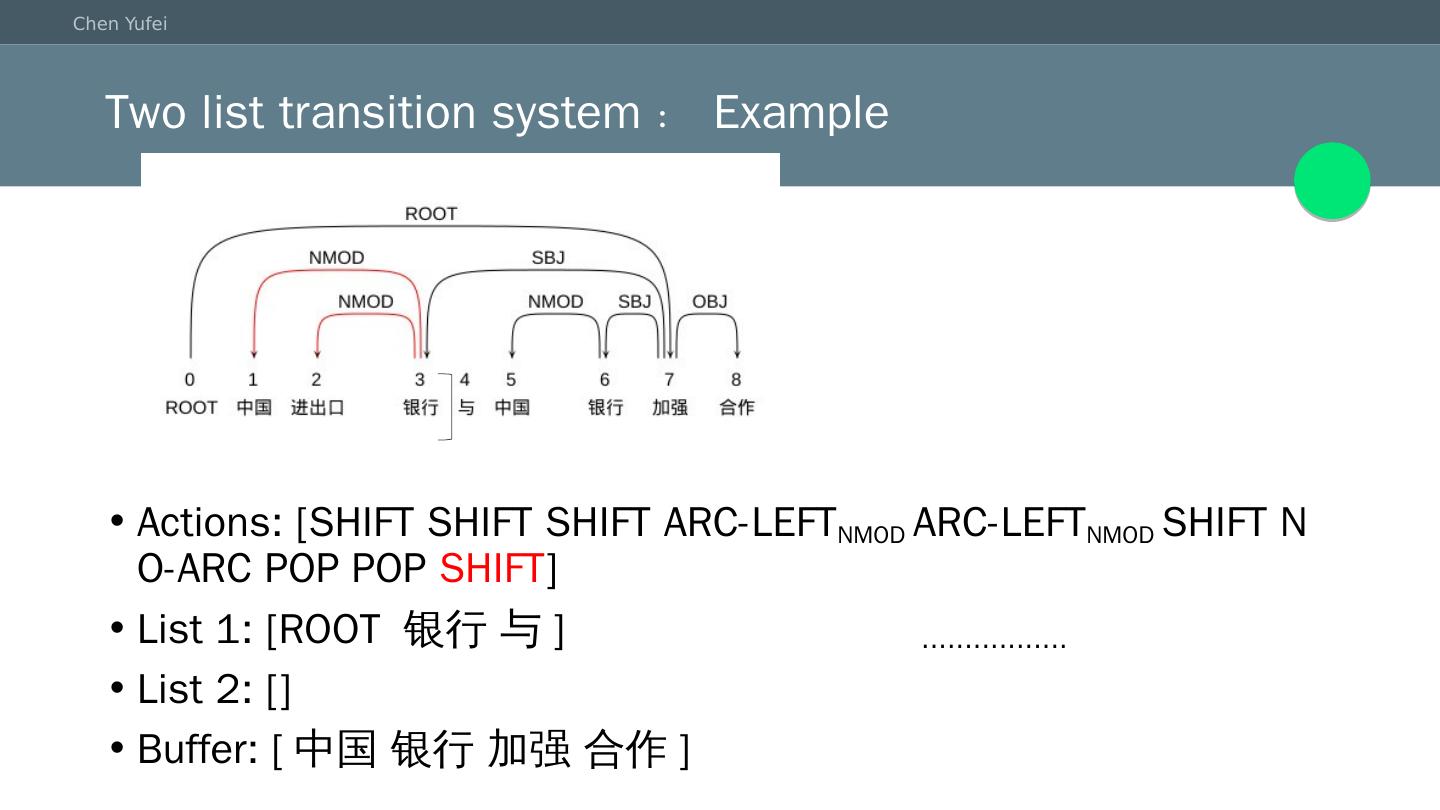
22 .Two list transition system:Example Actions: [SHIFT SHIFT SHIFT ARC-LEFT NMOD ARC-LEFT NMOD SHIFT NO-ARC POP POP SHIFT ] List 1: [ROOT 银行 与 ] List 2: [] Buffer: [中国 银行 加强 合作] .................
23 .1. 基于 手工特征提取 的消歧模型 通常 使用简单的线性模型 作为分类器。 以基于 状态转移 的依存分析为例。 当List1顶部为"中国",List2顶部为"进出口","Buffer"顶部为"银行"时,应该倾向于做"ARC LEFT"动作 从List和Buffer中 抽取多种特征 ,例如 List1顶部为"中国" List1顶部的POSTag为"NN" List2顶部为"进出口" List1顶部的POSTag为"NN"且List2顶部的POSTag为"NN" ( 组合特征 ) 较依赖于先验知识 。特征数量很多,速度慢。
24 .Two list transition system: action claassifier 1. Kiperwasser E, Goldberg Y. Simple and Accurate Dependency Parsing Using Bidirectional LSTM Feature Representations. Acl. 2016;4:313-327. http://arxiv.org/abs/1603.04351.
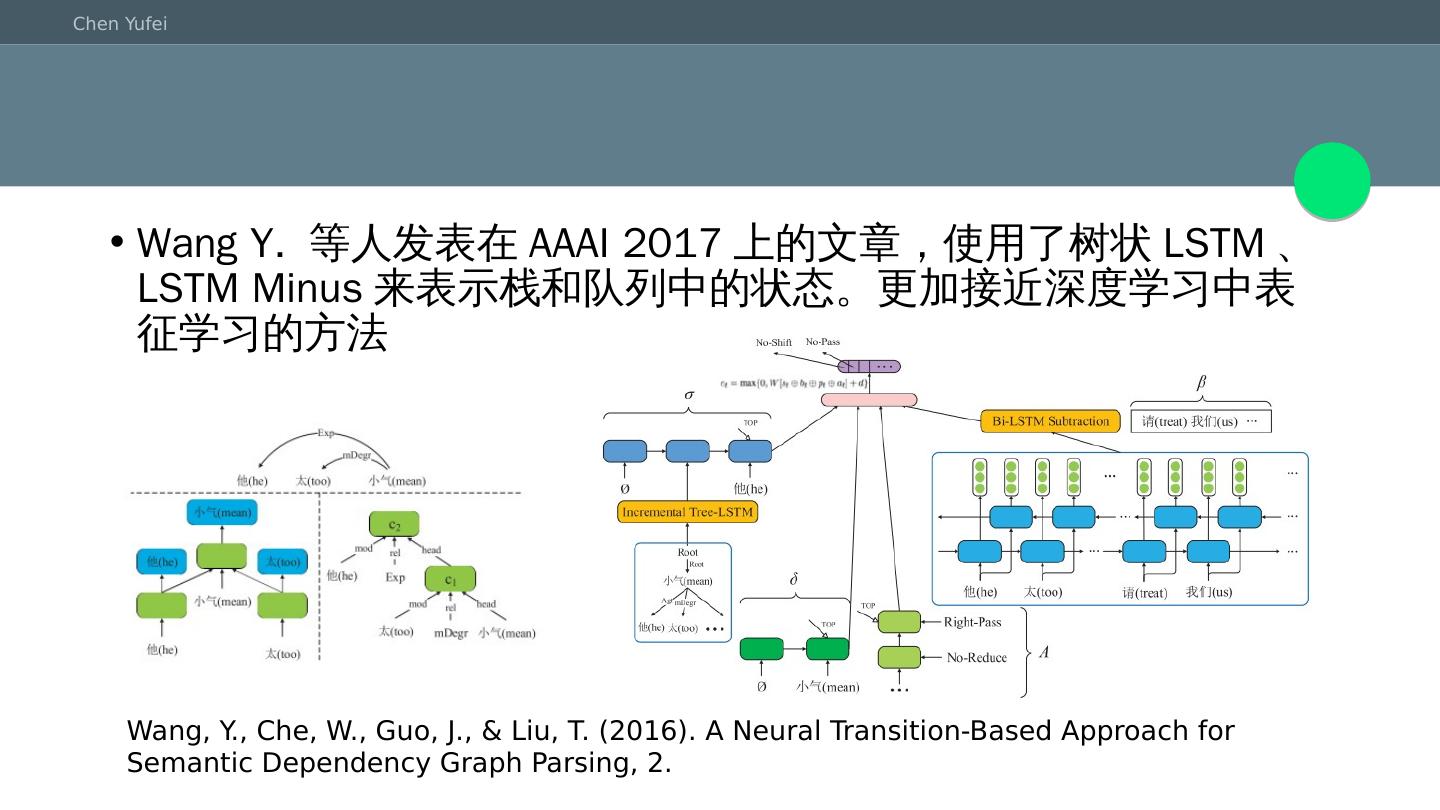
25 .Wang Y. 等人发表在AAAI 2017上的文章,使用了树状LSTM、LSTM Minus来表示栈和队列中的状态。更加接近深度学习中表征学习的方法 Wang, Y., Che, W., Guo, J., & Liu, T. (2016). A Neural Transition-Based Approach for Semantic Dependency Graph Parsing, 2.
26 .Graph-based method 基本模式: 假设依存树中,每条边的存在与否相互独立 (一阶近似) 。 将句子中的n个词视为图的n个节点,建立一个有n*(n-1)条边的完全图。给每条边分别赋予一个权重。 通过最大 子图 算法,从完全图中抽取分数最大的 子图 ,作为 语义图 。 最简单的最大子图算法:若分数大于0则这条边存在,分数小于0则这条边存在
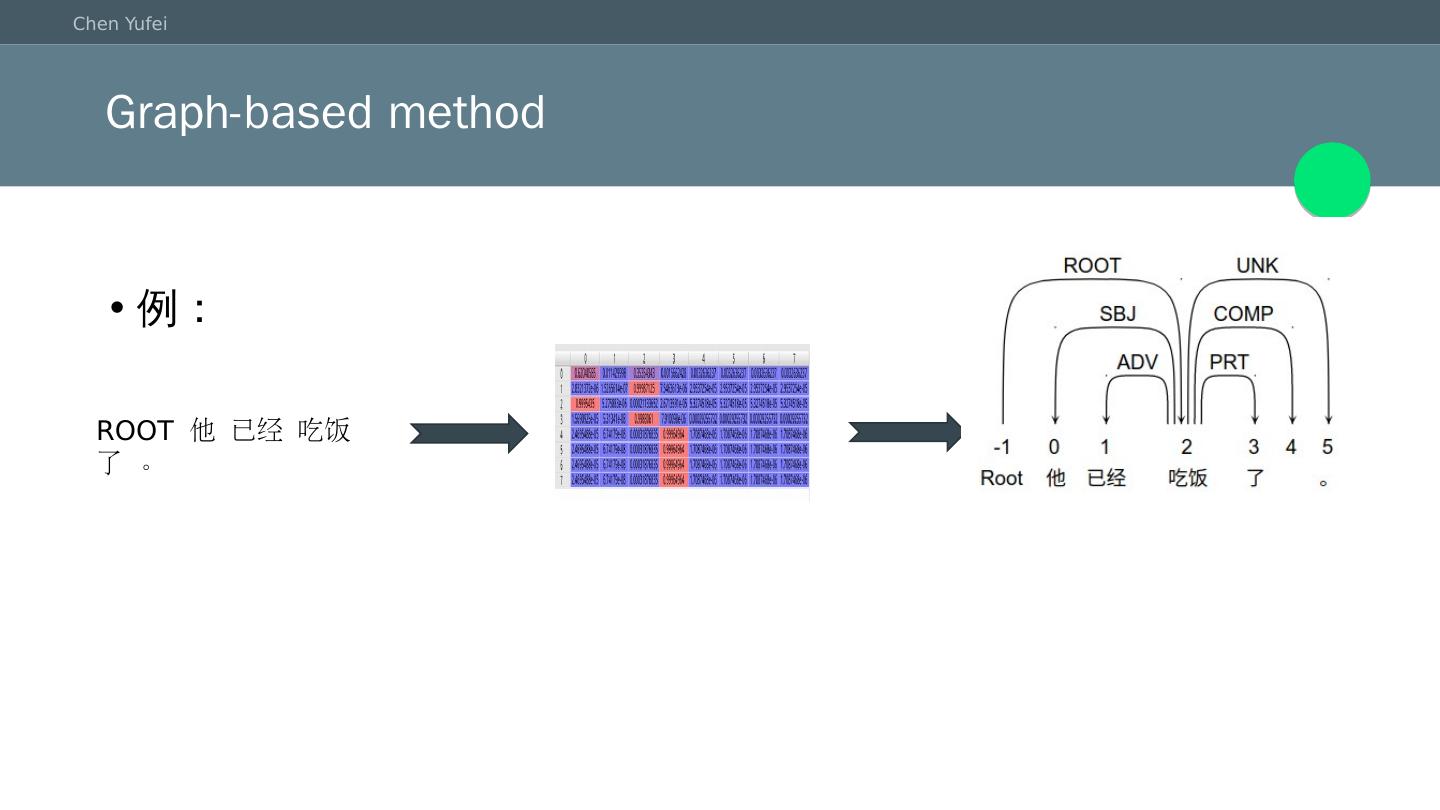
27 .Graph-based method 例: ROOT 他 已经 吃饭 了 。
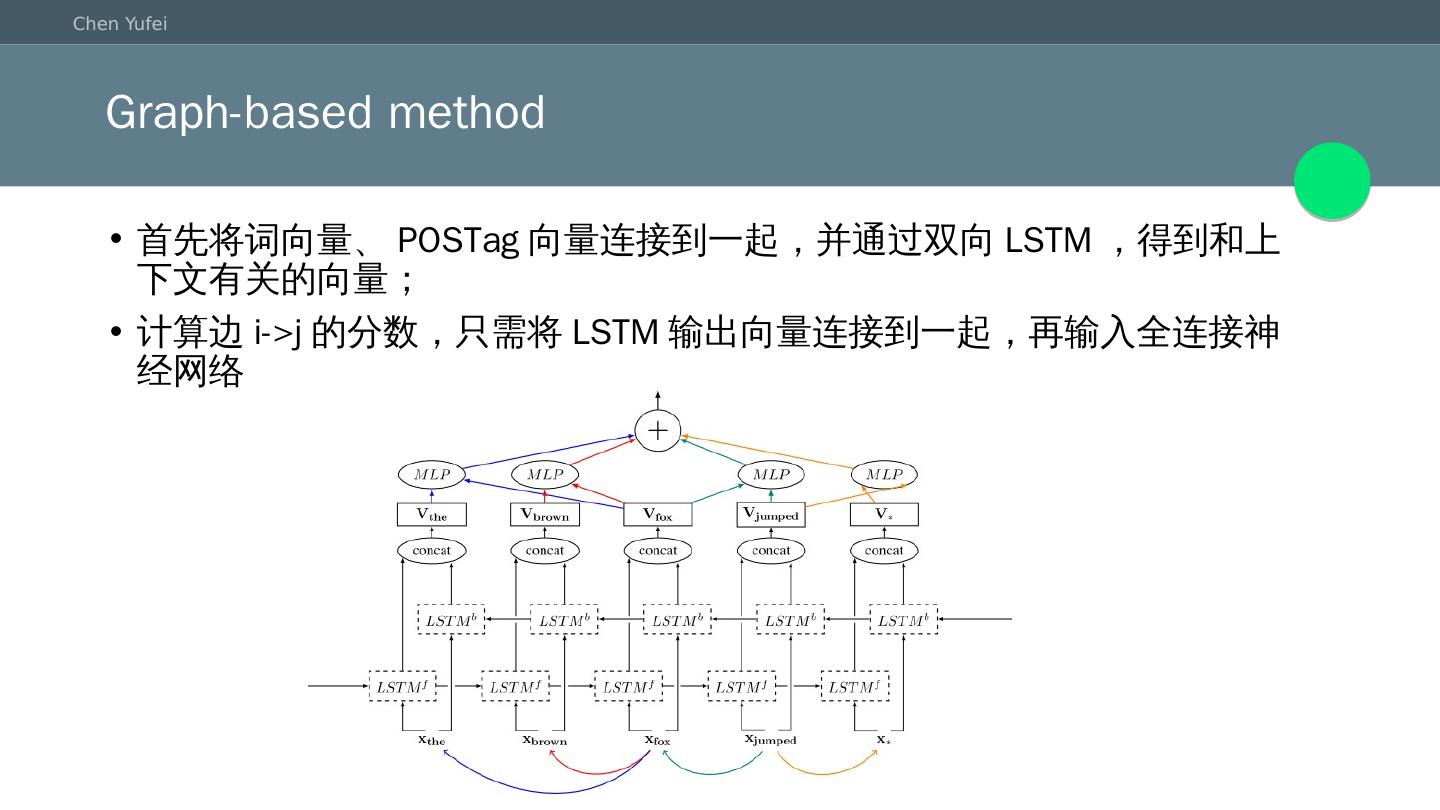
28 .Graph-based method 首先将词向量、POSTag向量连接到一起,并通过双向LSTM,得到和上下文有关的向量; 计算边i->j的分数,只需将LSTM输出向量连接到一起,再输入全连接神经网络
29 .三、抽象语义图 和语义依存图一样,用有向图来表示语义。但是图中的节点不再是句子里的词,而是某种抽象概念。 希望得到抽象的语义表示,不受表面句法形式的影响。 常见的抽象语义图形式: Abstract Meaning Representation(AMR) 缺点:过于抽象,标注一致度不高