













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Vertica分析数据库
本文介绍了Vertica的系统架构 分析数据库(Vertica),一个商业化的 C-Store研究原型设计。Vertica演示 一个现代的商业RDBMS系统 一个经典的关系接口同时实现 现代“网络尺度”所期望的高性能 通过作出适当的体系结构选择来分析系统.
展开查看详情
1 . The Vertica Analytic Database: C-Store 7 Years Later Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan Nga Tran, Ben Vandiver, Lyric Doshi, Chuck Bear Vertica Systems, An HP Company Cambridge, MA {alamb, mfuller, rvaradarajan, ntran, bvandiver, ldoshi, cbear} @vertica.com ABSTRACT that they were designed for transactional workloads on late- This paper describes the system architecture of the Ver- model computer hardware 40 years ago. Vertica is designed tica Analytic Database (Vertica), a commercialization of the for analytic workloads on modern hardware and its success design of the C-Store research prototype. Vertica demon- proves the commercial and technical viability of large scale strates a modern commercial RDBMS system that presents distributed databases which offer fully ACID transactions a classical relational interface while at the same time achiev- yet efficiently process petabytes of structured data. ing the high performance expected from modern “web scale” This main contributions of this paper are: analytic systems by making appropriate architectural choices. 1. An overview of the architecture of the Vertica Analytic Vertica is also an instructive lesson in how academic systems Database, focusing on deviations from C-Store. research can be directly commercialized into a successful product. 2. Implementation and deployment lessons that led to those differences. 1. INTRODUCTION 3. Observations on real-world experiences that can in- The Vertica Analytic Database (Vertica) is a distributed1 , form future research directions for large scale analytic massively parallel RDBMS system that commercializes the systems. ideas of the C-Store[21] project. It is one of the few new commercial relational database systems that is widely used We hope that this paper contributes a perspective on com- in business critical systems. At the time of this writing, mercializing research projects and emphasizes the contribu- there are over 500 production deployments of Vertica, at tions of the database research community towards large scale least three of which are substantially over a petabyte in size. distributed computing. Despite the recent interest in academia and industry about so called “NoSQL” systems [13, 19, 12], the C-Store project 2. BACKGROUND anticipated the need for web scale distributed processing and Vertica was the direct result of commercializing the C- these new NoSQL systems use many of the same techniques Store research system. Vertica Systems was founded in 2005 found in C-Store and other relational systems. Like any by several of the C-Store authors and was acquired in 2011 language or system, SQL is not perfect, but it has been by Hewlett-Packard (HP) after several years of commercial a transformational abstraction for application developers, development. [2]. Significant research and development ef- freeing them from many implementation details of storing forts continue on the Vertica Analytic Database. and finding their data to focus their efforts on using the information effectively. 2.1 Design Overview Vertica’s experience in the marketplace and the emergence of other technologies such as Hive [7] and Tenzing [9] validate 2.1.1 Design Goals that the problem is not SQL. Rather, the unsuitability of Vertica utilizes many (but not all) of the ideas of C-Store, legacy RDBMs systems for massive analytic workloads is but none of the code from the research prototype. Vertica 1 was explicitly designed for analytic workloads rather than We use the term distributed database to mean a shared- for transactional workloads. nothing, scale-out system as opposed to a set of locally au- tonomous (own catalog, security settings, etc.) RDBMS sys- Transactional workloads are characterized by a large tems. number of transactions per second (e.g. thousands) where each transaction involves a handful of tuples. Most of the transactions take the form of single row insertions or modifi- Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are cations to existing rows. Examples are inserting a new sales not made or distributed for profit or commercial advantage and that copies record and updating a bank account balance. bear this notice and the full citation on the first page. To copy otherwise, to Analytic workloads are characterized by smaller trans- republish, to post on servers or to redistribute to lists, requires prior specific action volume (e.g. tens per second), but each transaction permission and/or a fee. Articles from this volume were invited to present examines a significant fraction of the tuples in a table. Ex- their results at The 38th International Conference on Very Large Data Bases, amples are aggregating sales data across time and geography August 27th - 31st 2012, Istanbul, Turkey. Proceedings of the VLDB Endowment, Vol. 5, No. 12 dimensions and analyzing the behavior of distinct users on Copyright 2012 VLDB Endowment 2150-8097/12/08... $ 10.00. a web site. 1790
2 . As typical table sizes, even for small companies, have 3.1 Projections grown to millions and billions of rows, the difference be- Like C-Store, Vertica physically organizes table data into tween the transactional and analytic workloads has been projections, which are sorted subsets of the attributes of a increasing. As others have pointed out [26], it is possible to table. Any number of projections with different sort orders exceed the performance of existing one-size-fits-all systems and subsets of the table columns are allowed. Because Ver- by orders of magnitudes by focusing specifically on analytic tica is a column store and has been optimized so heavily for workloads. performance, it is NOT required to have one projection for Vertica is a distributed system designed for modern com- each predicate that a user might restrict. In practice, most modity hardware. In 2012, this means x86 64 servers, Linux customers have one super projection (described below) and and commodity gigabit Ethernet interconnects. Like C- between zero and three narrow, non-super projections. Store, Vertica is designed from the ground up to be a dis- Each projection has a specific sort order on which the data tributed database. When nodes are added to the database, is totally sorted as shown in Figure 1. Projections may be the system’s performance should scale linearly. To achieve thought of as a restricted form of materialized view [11, 25]. such scaling, using a shared disk (often referred to as network- They differ from standard materialized views because they attached storage) is not acceptable as it almost immediately are the only physical data structure in Vertica, rather than becomes a bottleneck. Also, the storage system’s data place- auxiliary indexes. Classical materialized views also contain ment, the optimizer and execution engine should avoid con- aggregation, joins and other query constructs that Vertica suming large amounts of network bandwidth to prevent the projections do not. Experience has shown that the main- interconnect from becoming the bottleneck. tenance cost and additional implementation complexity of In analytic workloads, while transactions per second is rel- maintaining materialized views with aggregation and filter- atively low by Online-Transaction-Processing (OLTP) stan- ing is not practical in real world distributed systems. Vertica dards, rows processed per second is incredibly high. This does support a special case to physically denormalize certain applies not only to querying but also to loading the data joins within prejoin projections as described below. into the database. Special care must be taken to support high ingest rates. If it takes days to load your data, a super- 3.2 Join Indexes fast analytic query engine will be of limited use. Bulk load C-Store uses a data structure called a join index to recon- must be fast and must not prevent or unduly slow down stitute tuples from the original table using different partial queries ongoing in parallel. projections. While the authors expected only a few join in- For a real production system, all operations must be “on- dices in practice, Vertica does not implement join indices line”. Vertica can not require stopping or suspending queries at all, instead requiring at least one super projection con- for storage management or maintenance tasks. Vertica also taining every column of the anchoring table. In practice aims to ease the management burden by making ease of use and experiments with early prototypes, we found that the an explicit goal. We trade CPU cycles (which are cheap) for costs of using join indices far outweighed their benefits. Join human wizard cycles (which are expensive) whenever pos- indices were complex to implement and the runtime cost of sible. This takes many forms such as minimizing complex reconstructing full tuples during distributed query execution networking and disk setup, limiting performance tuning re- was very high. In addition, explicitly storing row ids con- quired, and automating physical design and management. sumed significant disk space for large tables. The excellent All vendors claim management ease, though success in the compression achieved by our columnar design helped keep real world is mixed. the cost of super projections to a minimum and we have no Vertica was written entirely from scratch with the fol- plans to lift the super projection requirement. lowing exceptions, which are based on the PostgreSQL [5] implementation: 3.3 Prejoin Projections Like C-Store, Vertica supports prejoin projections which 1. The SQL parser, semantic analyzer, and standard SQL permit joining the projection’s anchor table with any num- rewrites. ber of dimension tables via N:1 joins. This permits a normal- ized logical schema, while allowing the physical storage to be 2. Early versions of the standard client libraries, such as denormalized. The cost of storing physically denormalized JDBC and ODBC and the command line interface. data is much less than in traditional systems because of the available encoding and compression. Prejoin projections are All other components were custom written from the ground not used as often in practice as we expected. This is because up. While this choice required significant engineering effort Vertica’s execution engine handles joins with small dimen- and delayed the initial introduction of Vertica to the mar- sion tables very well (using highly optimized hash and merge ket, it means Vertica is positioned to take full advantage of join algorithms), so the benefits of a prejoin for query exe- its architecture. cution are not as significant as we initially predicted. In the case of joins involving a fact and a large dimension table or two large fact tables where the join cost is high, most cus- 3. DATA MODEL tomers are unwilling to slow down bulk loads to optimize Like all SQL based systems, Vertica models user data as such joins. In addition, joins during load offer fewer opti- tables of columns (attributes), though the data is not phys- mization opportunities than joins during query because the ically arranged in this manner. Vertica supports the full database knows nothing apriori about the data in the load range of standard INSERT, UPDATE, DELETE constructs stream. for logically inserting and modifying data as well as a bulk loader and full SQL support for querying. 1791
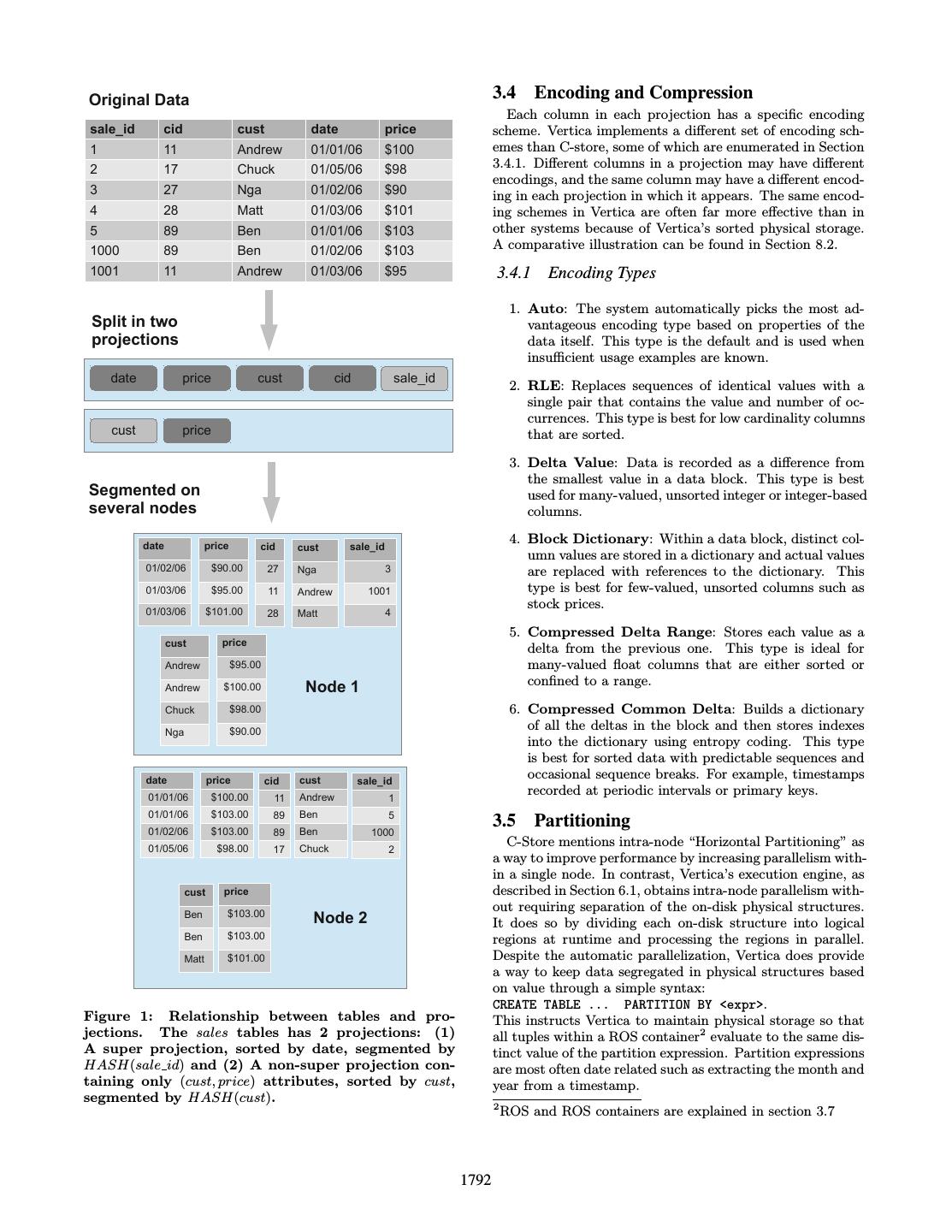
3 . A 3.4 Encoding and Compression Each column in each projection has a specific encoding AA AA BC C scheme. Vertica implements a different set of encoding sch- D DD EF C DDD D D emes than C-store, some of which are enumerated in Section D DD 3.4.1. Different columns in a projection may have different encodings, and the same column may have a different encod- DD ing in each projection in which it appears. The same encod- ! AA DD D D ing schemes in Vertica are often far more effective than in " F DDD D D other systems because of Vertica’s sorted physical storage. D " F DD D A comparative illustration can be found in Section 8.2. D D DD EF C DD 3.4.1 Encoding Types 1. Auto: The system automatically picks the most ad- BC A ADE vantageous encoding type based on properties of the C EF A E data itself. This type is the default and is used when insufficient usage examples are known. A BC A 2. RLE: Replaces sequences of identical values with a single pair that contains the value and number of oc- currences. This type is best for low cardinality columns A BC that are sorted. 3. Delta Value: Data is recorded as a difference from the smallest value in a data block. This type is best B A E used for many-valued, unsorted integer or integer-based E columns. A C 4. Block Dictionary: Within a data block, distinct col- A umn values are stored in a dictionary and actual values D # are replaced with references to the dictionary. This D # DD EF C D D type is best for few-valued, unsorted columns such as D D D# stock prices. ! AA 5. Compressed Delta Range: Stores each value as a A C delta from the previous one. This type is ideal for EF C # many-valued float columns that are either sorted or EF C D # E confined to a range. # 6. Compressed Common Delta: Builds a dictionary # of all the deltas in the block and then stores indexes into the dictionary using entropy coding. This type is best for sorted data with predictable sequences and A C A occasional sequence breaks. For example, timestamps D D D # DD EF C D recorded at periodic intervals or primary keys. D D D # " F D D # " F 3.5 Partitioning D D # D C-Store mentions intra-node “Horizontal Partitioning” as a way to improve performance by increasing parallelism with- in a single node. In contrast, Vertica’s execution engine, as A C described in Section 6.1, obtains intra-node parallelism with- " F D # out requiring separation of the on-disk physical structures. E It does so by dividing each on-disk structure into logical " F D # regions at runtime and processing the regions in parallel. ! AA D D# Despite the automatic parallelization, Vertica does provide a way to keep data segregated in physical structures based on value through a simple syntax: CREATE TABLE ... PARTITION BY <expr>. Figure 1: Relationship between tables and pro- This instructs Vertica to maintain physical storage so that jections. The sales tables has 2 projections: (1) all tuples within a ROS container2 evaluate to the same dis- A super projection, sorted by date, segmented by tinct value of the partition expression. Partition expressions HASH(sale id) and (2) A non-super projection con- are most often date related such as extracting the month and taining only (cust, price) attributes, sorted by cust, year from a timestamp. segmented by HASH(cust). 2 ROS and ROS containers are explained in section 3.7 1792
4 . The first reason for partitioning, as in other RDBMS sys- This is a classic ring style segmentation scheme. The most tems, is fast bulk deletion. It is common to keep data sepa- common choice is HASH(col1 ..coln ), where coli is some rated into files based on a combination of month and year, suitably high cardinality column with relatively even value so removing a specific month of data from the system is as distributions, commonly a primary key column. Within each simple as deleting files from a filesystem. This arrangement node, in addition to the specified partitioning, Vertica keeps is very fast and reclaims storage immediately. The alter- tuples physically segregated into “local segments” to facili- native, if the data is not pre-separated, requires searching tate online expansion and contractions of the cluster. When all physical files for rows matching the delete predicate and nodes are added or removed, data is quickly transferred by adding delete vectors (further explained in Section 3.7.1) assigning one or more of the existing local segments to a for deleted records. It is much slower to find and mark new node and transferring the segment data wholesale in deleted records than deleting files, and this procedure actu- its native format, without any rearrangement or splitting ally increases storage requirements and degrades query per- necessary. formance until the tuple mover’s next merge-out operation is performed (see Section 4). Because bulk deletion is only 3.7 Read and Write Optimized Stores fast if all projections are partitioned the same way, parti- Like C-Store, Vertica has a Read Optimized Store (ROS) tioning is specified at the table level and not the projection and a Write Optimized Store (WOS). Data in the ROS is level. physically stored in multiple ROS containers on a standard The second way Vertica takes advantage of physical stor- file system. Each ROS container logically contains some age separation is improving query performance. As de- number of complete tuples sorted by the projection’s sort scribed here [22], Vertica stores the minimum and maximum order, stored as a pair of files per column. Vertica is a true values of the column data in each ROS to quickly prune con- column store – column files may be independently retrieved tainers at plan time that can not possibly pass query pred- as the storage is physically separate. Vertica stores two files icates. Partitioning makes this technique more effective by per column within a ROS container: one with the actual col- preventing intermixed column values in the same ROS. umn data, and one with a position index. Data is identified within each ROS container by a position which is simply 3.6 Segmentation: Cluster Distribution its ordinal position within the file. Positions are implicit C-Store separates physical storage into segments based and are never stored explicitly. The position index is ap- 1 on the first column in the sort order of a projection and proximately 1000 the size of the raw column data and stores the authors briefly mention their plan to design a storage metadata per disk block such as start position, minimum allocator for assigning segments to nodes. Vertica has a value and maximum value that improve the speed of the ex- fully implemented distributed storage system that assigns ecution engine and permits fast tuple reconstruction. Unlike tuples to specific computation nodes. We call this inter- C-Store, this index structure does not utilize a B-Tree as the node (splitting tuples among nodes) horizontal partitioning ROS containers are never modified. Complete tuples are re- segmentation to distinguish it from the intra-node (segre- constructed by fetching values with the same position from gating tuples within nodes) partitioning described in Section each column file within a ROS container. Vertica also sup- 3.5. Segmentation is specified for each projection, which can ports grouping multiple columns together into the same file be (and most often is) different from the sort order. Projec- when writing to a ROS container. This hybrid row-column tion segmentation provides a deterministic mapping of tuple storage mode is very rarely used in practice because of the value to node and thus enables many important optimiza- performance and compression penalty it exacts. tions. For example, Vertica uses segmentation to perform Data in the WOS is solely in memory, where column or fully local distributed joins and efficient distributed aggre- row orientation doesn’t matter. The WOS’s primary pur- gations, which is particularly effective for the computation pose is to buffer small data inserts, deletes and updates so of high-cardinality distinct aggregates that writes to physical structures contain a sufficient num- Projections can either be replicated or segmented on some bers of rows to amortize the cost of the writing. The WOS or all cluster nodes. As the name implies, a replicated has changed over time from row orientation to column ori- projection stores a copy of each tuple on every projection entation and back again. We did not find any significant node. Segmented projections store each tuple on exactly performance differences between these approaches and the one specific projection node. The node on which the tuple changes were driven primarily by software engineering con- is stored is determined by a segmentation clause in the pro- siderations. Data is not encoded or compressed when it is jection definition: CREATE PROJECTION ... SEGMENTED BY in the WOS. However, it is segmented according to the pro- <expr> where <expr> is an arbitrary 3 integral expression. jection’s segmentation expression. Nodes are assigned to store ranges of segmentation ex- pression values, starting with the following mapping where 3.7.1 Data Modifications and Delete Vectors CM AX is the maximum integral value (264 in Vertica). Data in Vertica is never modified in place. When a tuple CM AX 0 ≤ expr < N ⇒ N ode1 is deleted or updated from either the WOS or ROS, Vertica 1∗CM AX 2∗CM AX N ≤ expr < N ⇒ N ode2 creates a delete vector. A delete vector is a list of positions of ... ... rows that have been deleted. Delete vectors are stored in the (N −2)∗CM AX N ≤ expr < (N −1)∗C N M AX ⇒ N odeN −1 same format as user data: they are first written to a DVWOS (N −1)∗CM AX ≤ expr < CM AX ⇒ N odeN in memory, then moved to DVROS containers on disk by the N tuple mover (further explained in section 4) and stored using 3 While it is possible to manually specify segmentation, most efficient compression mechanisms. There may be multiple users let the Database Designer determine an appropriate delete vectors for the WOS and multiple delete vectors for segmentation expression for projections. any particular ROS container. SQL UPDATE is supported by 1793
5 . deleting the row being updated and then inserting a row containing the updated column values. AE%DCC ABCCDCC AEFDCC AECDCC ABC DCC ABC"DCC AE DCC 4. TUPLE MOVER The tuple mover is an automatic system which oversees A BCDE F ABCCDCC AEFDCC and rearranges the physical data files to increase data stor- AECDCC AEEDCC ED age and ingest efficiency during query processing. Its work ABC DCC ABCBDCC A B can be grouped into two main functions: AEEDCC AEED C AEEDCC ABCB 1. Moveout: asynchronously moves data from the WOS to the ROS D AEFDCC AECDCC 2. Mergeout: merges multiple ROS files together into larger ones. ABCCDCC ABCCDCC AEFDCC AEFDCC AECDCC AECDCC As the WOS fills up, the tuple mover automatically exe- A BCDE F AEEDCC ABC DCC ABCBDCC ABCCDCC cutes a moveout operation to move data from WOS to ROS. AEFDCC AECDCC In the event that the WOS becomes saturated before move- AEEDCC ABC DCC out is complete, subsequently loaded data is written directly to new ROS Containers until the WOS regains sufficient ca- pacity. The tuple mover must balance its moveout work so ABCCDCC AEFDCC ABCCDCC AEFDCC that it is not overzealous (creating too many little ROS con- AECDCC tainers) but also not too lazy (resulting in WOS overflow D AECDCC ABBCDCC which also creates too many little files). Mergeout decreases the number of ROS containers on disk. Numerous small ROS containers decrease compression op- AD C D portunities and slow query processing. Many files require ABCCDCC AEFDCC ABCCDCC ! AECDCC D AEFDCC more file handles, more seeks, and more merges of the sorted A BCDE F & '( AECDCC & '( AEEDCC files. The tuple mover merges smaller files together into AC & '( ABC DCC larger ones, and it reclaims storage by filtering out tuples ! ABC DCC ABCCDCC which were deleted prior to the Ancient History Mark (fur- ! ABC"DCC AEFDCC AECDCC ther explained in section 5.1) as there is no way a user can & '( & '( AEEDCC ABC DCC query them. Unlike C-Store, the tuple mover does not in- & '( & '( ABCBDCC AEEDCC termix data from the WOS and ROS in order to strongly ! AEED C bound the number of times a tuple is (re)merged. When a D ! AEEDCC ! ABCB tuple is part of a mergeout operation, it is read from disk once and written to disk once. The tuple mover periodically quantizes the ROS contain- "# CB $# CB # CB %# CB ers into several exponential sized strata based on file size. The output ROS container from a mergeout operation are B A planned such that the resulting ROS container is in at least one strata larger than any of the input ROS containers. Figure 2: Physical storage layout within a node. Vertica does not impose any size restrictions on ROS con- This figure illustrates how columns are stored in tainers, but the tuple mover will not create ROS contain- projections using files on disk. The table is par- ers greater than some maximum (currently 2TB) so as to titioned by EXTRACT MONTH, YEAR FROM TIMESTAMP and strongly bound the number of strata and thus the number segmented by HASH(cid). There are 14 ROS con- of merges. The maximum ROS container size is chosen to be tainers, each with two columns. Each column’s data sufficiently large that any per-file overhead is amortized to within its ROS container is stored as a single file for irrelevance and yet the files are not too unwieldy to manage. a total of 28 files of user data. The data has four par- By choosing strata sizes exponentially, the number of times tition keys: 3/2012, 4/2012, 5/2012 and 6/2012. As any tuple is rewritten is bounded to the number of strata. the projection is segmented by HASH(cid), this node The tuple mover takes care to preserve partition and local is responsible for storing all data that satisfies the segment boundaries when choosing merge candidates. It condition Cnmin < hash(cid) ≤ Cnmax , for some value has also been tuned to maximize the system’s tuple ingest of Cnmin and Cnmax . This node has divided the data rate while preventing an explosion in the number of ROS into three local segments such that: Local Segment containers. An important design point of the tuple mover 1 has Cnmin < hash(cid) ≤ Cnmax 3 , Local Segment 2 is that operations are not centrally coordinated across the has Cnmin < hash(cid) ≤ 2∗Cnmax and Local Segment cluster. The specific ROS container layouts are private to 3 3 3 has 2∗Cnmin < hash(cid) ≤ C . every node, and while two nodes might contain the same 3 nmax tuples, it is common for them to have a different layout of ROS containers due to factors such as different patterns of merging, available resources, node failure and recovery. 1794
6 . Granted Mode Granted Mode Requested Mode S I SI X T U O Requested Mode S I SI X T U O S Yes No No No Yes Yes No S S SI SI X S S O I No Yes No No Yes Yes No I SI I SI X I I O SI No No No No Yes Yes No SI SI SI SI X SI SI O X No No No No No Yes No X X X X X X X O T Yes Yes Yes No Yes Yes No T S I SI X T T O U Yes Yes Yes Yes Yes Yes No U S I SI X T U O O No No No No No No No O O O O O O O O Table 1: Lock Compatibility Matrix Table 2: Lock Conversion Matrix 5. UPDATES AND TRANSACTIONS Vertica does not employ traditional two-phase commit[15]. Every tuple in Vertica is timestamped with the logical Rather, once a cluster transaction commit message is sent, time at which it was committed. Each delete marker is nodes either successfully complete the commit or are ejected paired with the logical time the row was deleted. These log- from the cluster. A commit succeeds on the cluster if it suc- ical timestamps are called epochs and are implemented as ceeds on a quorum of nodes. Any ROS or WOS created by implicit 64-bit integral columns on the projection or delete the committing transaction becomes visible to other trans- vector. All nodes agree on the epoch in which each trans- actions when the commit completes. Nodes that fail during action commits, thus an epoch boundary represents a glob- the commit process leave the cluster and rejoin the cluster in ally consistent snapshot. In concert with Vertica’s policy a consistent state via the recovery mechanism described in of never modifying storage, a query executing in the recent section 5.2. Transaction rollback simply entails discarding past needs no locks and is assured of a consistent snapshot. any ROS container or WOS data created by the transaction. The default transaction isolation in Vertica is READ COM- MITTED, where each query targets the latest epoch (the 5.1 Epoch Management current epoch - 1). Originally, Vertica followed the C-store epoch model: epo- Because most queries, as explained above, do not require chs contained all transactions committed in a given time any locks, Vertica has an analytic-workload appropriate ta- window. However, users running in READ COMMITTED ble locking model. Lock compatibility and conversion ma- were often confused because their commits did not become trices are shown in Table 1 and Table 2 respectively, both “visible” until the epoch advanced. Now Vertica automati- adapted from [15]. cally advances the epoch as part of commit when the com- mitting transaction includes DML or certain data-modifying • Shared lock: while held, prevents concurrent modifica- DDL. In addition to reducing user confusion, automatic tion of the table. Used to implement SERIALIZABLE epoch advancement simplifies many of the internal manage- isolation. ment processes (like the tuple mover). • Insert lock: required to insert data into a table. An Vertica tracks two epoch values worthy of mention: the Insert lock is compatible with itself, enabling multiple Last Good Epoch (LGE) and the Ancient History Mark inserts and bulk loads to occur simultaneously which (AHM). The LGE for a node is the epoch for which all data is critical to maintain high ingest rates and parallel has been successfully moved out of the WOS and into ROS loads yet still offer transactional semantics. containers on disk. The LGE is tracked per projection be- cause data that exists only in the WOS is lost in the event of • SharedInsert lock: required for read and insert, but a node failure. The AHM is an analogue of C-store’s low wa- not update or delete. ter mark where Vertica discards historical information prior to the AHM when data reorganization occurs. Whenever • EXclusive lock: required for deletes and updates. the tuple mover observes a row deleted prior to the AHM, it • Tuple mover lock: required for certain tuple mover elides the row from the output of the operation. The AHM operations. This lock is compatible with every lock advances automatically according to a user-specified policy. except X and is used by the tuple mover during certain The AHM normally does not advance when nodes are down short operations on delete vectors. so as to preserve the history necessary to incrementally re- play DML operations during recovery (described in Section • Usage lock: required for parts of moveout and merge- 5.2). out operations. • Owner lock: required for significant DDL such as drop- ping partitions and adding columns. 5.2 Tolerating Failures Vertica replicates data to provide fault tolerance by em- Vertica employs a distributed agreement and group mem- ploying the projection segmentation mechanism explained bership protocol to coordinate actions between nodes in the in section 3.6. Each projection must have at least one buddy cluster. The messaging protocol uses broadcast and point- projection containing the same columns and a segmentation to-point delivery to ensure that any control message is suc- method that ensures that no row is stored on the same node cessfully received by every node. Failure to receive a message by both projections. When a node is down, the buddy pro- will cause a node to be ejected from the cluster and the re- jection is employed to source the missing rows from the down maining nodes will be informed of the loss. Like C-Store, node. Like any distributed database, Vertica must grace- 1795
7 .fully handle failed nodes rejoining the cluster. In Vertica, the catalog is implemented using a custom memory resident this process is called recovery. Vertica has no need of tradi- data structure and transactionally persisted to disk via its tional transaction logs because the data+epoch itself serves own mechanism, both of which are beyond the scope of this as a log of past system activity. Vertica implements efficient paper. incremental recovery by utilizing this historical record to re- As in C-Store, Vertica provides the notion of K-safety: play DML the down node has missed. When a node rejoins With K or fewer nodes down, the cluster is guaranteed to the cluster after a failure, it recovers each projection segment remain available. To achieve K-Safety, the database projec- from a corresponding buddy projection segment. First, the tion design must ensure at least K +1 copies of each segment node truncates all tuples that were inserted after its LGE, are present on different nodes such that a failure of any K ensuring that it starts at a consistent state. Then recovery nodes leaves at least one copy available. The failure of K +1 proceeds in two phases to minimize operational disruption. nodes does not guarantee a database shutdown. Only when node failures actually cause data to become unavailable will • Historical Phase: recovers committed data from the the database shutdown until the failures can be repaired and LGE to some previous epoch Eh . No locks are held consistency restored via recovery. A Vertica cluster will also while data between the recovering node’s LGE and Eh perform a safety shutdown if N2 nodes are lost where N is is copied from the buddy projection. When complete, the number of nodes in the cluster. The agreement protocol the projection’s LGE is advanced to Eh and either requires a N2 + 1 quorum to protect against network parti- the historical phase continues or the current phase is tions and avoid a split brain effect where two halves of the entered, depending on the amount of data between the cluster continue to operate independently. new LGE and the current epoch. • Current Phase: recovers committed data from the 6. QUERY EXECUTION LGE until the current epoch. The current phase takes Vertica supports the standard SQL declarative query lan- a Shared lock on the projection’s tables and copies any guage along with its own proprietary extensions. Vertica’s remaining data. After the current phase, recovery is extensions are designed for cases where easily querying time- complete and the projection participates in all future series and log style data in SQL was overly cumbersome or DML transactions. impossible. Users submit SQL queries using an interactive If the projection and its buddy have matching sort or- vsql command prompt or via standard JDBC, ODBC, or ders, recovery simply copies whole ROS containers and their ADO .net drivers. Rather than continuing to add more pro- delete vectors from one node to another. Otherwise, an ex- prietary extensions, Vertica has chosen to add an SDK with ecution plan similar to INSERT ... SELECT ... is used to hooks for users to extend various parts of the execution en- move rows (including deleted rows) to the recovering node. gine. A separate plan is used to move delete vectors. The re- fresh and rebalance operations are similar to the recovery 6.1 Query Operators and Plan Format mechanism. Refresh is used to populate new projections The data processing of the plan is performed by the Ver- which were created after the table was loaded with data. tica Execution Engine (EE). A Vertica query plan is a stan- Rebalance redistributes segments between nodes to rebal- dard tree of operators where each operator is responsible for ance storage as nodes are added and removed. Both have performing a certain algorithm. The output of one operator a historical phase where older data is copied and a current serves as the input to the following operator. A simple sin- phase where a Shared lock is held while any remaining data gle node plan is illustrated in figure 3. Vertica’s execution is transferred. engine is multi-threaded and pipelined: more than one op- Backup is handled completely differently by taking advan- erator can be running at any time and more than one thread tage of Vertica’s read-only storage system. A backup oper- can be executing the code for any individual operator. As ation takes a snapshot of the database catalog and creates in C-store, the EE is fully vectorized and makes requests for hard-links for each Vertica data file on the file system. The blocks of rows at a time instead of requesting single rows hard-links ensure that the data files are not removed while at a time. Vertica’s operators use a pull processing model: the backup image is copied off the cluster to the backup the most downstream operator requests rows from the next location. Afterwards, the hard-links are removed, ensuring operator upstream in the processing pipeline. This operator that storage used by any files artificially preserved by the does the same until a request is made of an operator that backup is reclaimed. The backup mechanism supports both reads data from disk or the network. The available operator full and incremental backup. types in the EE are enumerated below. Each operator can Recovery, refresh, rebalance and backup are all online op- use one of several possible algorithms which are automati- erations; Vertica continues to load and query data while cally chosen by the query optimizer. they are running. They impact ongoing operations only to 1. Scan: Reads data from a particular projection’s ROS the extent that they require computational and bandwidth containers, and applies predicates in the most advan- resources to complete. tageous manner possible. 2. GroupBy: Groups and aggregates data. We have 5.3 Cluster Integrity several different hash based algorithms depending on The primary state managed between the nodes is the what is needed for maximal performance, how much metadata catalog, which records information about tables, memory is allotted, and if the operator must produce users, nodes, epochs, etc. Unlike other databases, the cat- unique groups. Vertica also implements classic pipe- alog is not stored in database tables, as Vertica’s table de- lined (one-pass) aggregates, with a choice to keep the sign is inappropriate for catalog access and update. Instead, incoming data encoded or not. 1796
8 . 3. Join: Performs classic relational join. Vertica sup- ports both hash join and merge join algorithms which are capable of externalizing if necessary. All flavors of INNER, LEFT OUTER, RIGHT OUTER, FULL E OUTER, SEMI, and ANTI joins are supported. C BC C C E 4. ExprEval: Evaluate an expression 5. Sort: Sorts incoming data, externalizing if needed. 6. Analytic: Computes SQL-99 Analytics style windowed aggregates ED F E E 7. Send/Recv: Sends tuples from one node to another. Both broadcast and sending to nodes based on segmen- tation expression evaluation is supported. Each Send and Recv pair is capable of retaining the sortedness of the input stream. ABC Vertica’s operators are optimized for the sorted data that DECDE BC the storage system maintains. Like C-Store, significant care F E EDEF has been taken and implementation complexity has been added to ensure operators can operate directly on encoded data, which is especially important for scans, joins and cer- tain low level aggregates. The EE has several techniques to achieve high perfor- mance. Sideways Information Passing (SIP) has been ef- E fective in improving join performance by filtering data as C BC C C E early as possible in the plan. It can be thought of as an E E E DEC BC advanced variation of predicate push down since the join is being used to do filtering [27]. For example, consider a HashJoin that joins two tables using simple equality predi- cates. The HashJoin will first create a hash table from the inner input before it starts reading data from the outer input ABC to do the join. Special SIP filters are built during optimizer ABCD E planning and placed in the Scan operator. At run time, the F D E Scan has access to the Join’s hash table and the SIP filters are used to evaluate whether the outer key values exist in DECDE BC the hash table. Rows that do not pass these filters are not F E EDEF output by the Scan thus increaseing performance since we are not unnecessarily bringing the data through the plan only to be filtered away later by the join. Depending on the join type, we are not always able to push the SIP filter to the Scan, but we do push the filters down as far as possi- ble. We can also perform SIP for merge joins with a slightly different type of SIP filter beyond the scope of this paper. A BC The EE also switches algorithms during runtime as it ob- serves data flowing through the system. For example, if Vertica determines at runtime the hash table for a hash join A B CDE F will not fit into memory, we will perform a sort-merge join C E instead. We also institute several “prepass” operators to CD A compute partial results in parallel but which are not required AE CDE F for correctness (see Figure 3). The results of prepass opera- tors are fed into the final operator to compute the complete Figure 3: Plan representing a SQL query. The query result. For example, the query optimizer plans grouping op- plan contains a scan operator for reading data fol- erations in several stages for maximal performance. In the lowed by operators for grouping and aggregation fi- first stage, it attempts to aggregate immediately after fetch- nally followed by a filter operation. The StorageU- ing columns off the disk using an L1 cache sized hash table. nion dispatches threads for processing data on a set When the hash table fills up, the operator outputs its cur- of ROS containers. The StorageUnion also locally rent contents, clears the hash table, and starts aggregating resegments the data for the above GroupBys. The afresh with the next input. The idea is to cheaply reduce the ParallelUnion dispatches threads for processing the amount of data before sending it through other operators in GroupBys And Filters in parallel. the pipeline. Since there is still a small, but non-zero cost to run the prepass operator, the EE will decide at runtime to 1797
9 .stop if it is not actually reducing the number of rows which snowflake designs. The information of a star schema is of- pass. ten requested through (star) queries that join fact tables During query compile time, each operator is given a mem- with their dimensions. Efficient plans for star queries are to ory budget based on the resources available given a user de- join a fact table with its most highly selective dimensions fined workload policy and what each operator is going to do. first. Thus, the most important process in planning a Ver- All operators are capable of handling arbitrary sized inputs, tica StarOpt query is choosing and joining projections with regardless of the memory allocated, by externalizing their highly compressed and sorted predicate and join columns, buffers to disk. This is critical for a production database to to make sure that not only fast scans and merge joins on ensure users queries are always answered. One challenge of a compressed columns are applied first, but also that the car- fully pipelined execution engine such as Vertica’s is that all dinality of the data for later joins is reduced. operators must share common resources, potentially causing Besides the described StarOpt and columnar-specific tech- unnecessary spills to disk. In Vertica, the plan is separated niques described above, StartOpt and two other Vertica op- into multiple zones that can not be executing at the same timizers described later also employ other techniques to take time4 . Downstream operators are able to reclaim resources advantage of the specifics of sorted columnar storage and previously used by upstream operators, allowing each oper- compression, such as late materialization[8], compression- ator more memory than if we pessimistically to assumed all aware costing and planning, stream aggregation, sort elimi- operators would need their resources at the same time. nation, and merge joins. Many computations are data type dependent and require Although Vertica has been a distributed system since the the code to branch to type specific implementations at query beginning, StarOpt was designed only to handle queries whose runtime. To improve performance and reduce control flow tables have data with co-located projections. In other words, overhead, Vertica uses just in time compilation of certain projections of different tables in the query must be either expression evaluations to avoid branching by compiling the replicated on all nodes, or segmented on the same range of necessary assembly code on the fly. data on their join keys, so the plan can be executed locally Although the simplest implementation of a pull execution on each node and the results sent to to the node that the engine is a single thread, Vertica uses multiple threads for client is connected to. Even with this limitation, StarOpt processing the same plan. For example, multiple worker still works well with star schemas because only the data of threads are dispatched to fetch data from disk and perform large fact tables needs to be segmented throughout the clus- initial aggregations on non overlapping sections of ROS con- ter. Data of small dimension tables can be replicated every- tainers. The Optimizer and EE work together to combine where without performance degradation. As many Vertica the data from each pipeline at the required locations to get customers demonstrated their increasing need for non-star correct answers. It is necessary to combine partial results queries, Vertica developed its second generation optimizer, because alike values are not co-located in the same pipeline. StarfiedOpt 5 as a modication to StarOpt. By forcing non- The Send and Recv operators ship data to the nodes in star queries to look like a star, Vertica could run the StarOpt the cluster. The send operator is capable of segmenting the algorithm on the query to optimize it. StarifiedOpt is far data in such as way that all alike values are sent to the same more effective for non-star queries than we could have rea- node in the cluster. This allows each node’s operator to sonably hoped, but, more importunately, it bridged the gap compute the full results independently of the other nodes. to optimize both star and non-star queries while we designed In the same way we fully utilize the cluster of nodes by and implemented the third generation optimizer: the custom dividing the data in advantageous ways, we can divide the built V2Opt. data locally on each node to process data in parallel and The distribution aware V2Opt 6 , which allows data to be keep the all the cores fully utilized. As shown in Figure 3, transferred on-the-fly between nodes of the cluster during multiple GroupBy operators are run in parallel requesting query execution, is designed from the start as a set of exten- data from the StorageUnion which resegments the data such sible modules. In this way, the brains of the optimizer can that the GroupBy is able to compute complete results. be changed without rewriting lots of the code. In fact, due to the inherent extensible design, knowledge gleaned from 6.2 Query Optimization end-user experiences has already been incorporated into the C-Store has a minimal optimizer, in which the projections V2Opt optimizer without a lot of additional engineering ef- it reaches first are chosen for tables in the query, and the join fort. V2Opt plans a query by categorizing and classifying order of the projections is completely random. The Vertica the query’s physical-properties, such as column selectivity, Optimizer has evolved through three generations: StarOpt, projection column sort order, projection data segmentation, StarifiedOpt, and V2Opt. prejoin projection availability, and integrity constraint avail- StarOpt, the initial Vertica optimizer, was a Kimball-style ability. These physical-property heuristics, combined with a optimizer[18] which assumed that any interesting warehouse pruning strategy using a cost-model, based on compression schema could be modeled as a classic star or snowflake. A aware I/O, CPU and Network transfer costs, help the opti- star schema classifies attributes of an event into fact tables mizer (1) control the explosion in search space while contin- and descriptive attributes into dimension tables. Usually, a uing to explore optimal plans and (2) account for data dis- fact table is much larger than a dimension table and has a tribution and bushy plans during the join order enumeration many-to-one relationship with its associated descriptive di- phase. While innovating on the V2Opt core algorithms, we mension tables. A snowflake schema is an extension of a star also incorporated many of the best practices developed over schema, where one or more dimension tables has many-to- one relationships with further descriptive dimension tables. 5 This paper uses the term star to represent both star and US patent 8,086,598, Query Optimizer with Schema Con- version 4 6 Separated by operators such as Sort Pending patent, Modular Query Optimizer 1798
10 .the past 30 years of optimizer research such as using equi- to projection-segmentation, select-list or sort-list based on height histograms to calculate selectivity, applying sample- their specific knowledge of their data or use cases which may based estimates of the number of distinct values [16], intro- be unavailable to the DBD. It is extremely rare for any user ducing transitive predicates based on join keys, converting to override the column encoding choices of the DBD, which outer joins to inner joins, subquery de-correlation, subquery we credit to the empirical measurement during the storage- flattening [17] , view flattening, optimizing queries to favor optimization phase. co-located joins where possible, and automatically pruning out unnecessary parts of the query. 7. USER EXPERIENCE The Vertica Database Designer described in Section 6.3 works hand-in-glove with the optimizer to produce a phys- In this section we highlight some of the features of our ical design that takes advantage of the numerous optimiza- system which have led to its wide adoption and commercial tion techniques available to the optimizer. Furthermore, success, as well as the observations which led us to those when one or more nodes in the database cluster goes down, features. the optimizer replans the query by replacing and then re- costing the projections on unavailable nodes with their cor- • SQL: First and foremost, standard SQL support was responding buddy projections on working nodes. This can critical for commercial success as most customer orga- lead to a new plan with a different join order from the orig- nizations have large skill and tool investments in the inal one. language. Despite the temptation to invent new lan- guages or dialects to avoid pet peeves, 7 standard SQL 6.3 Automatic Physical Design provides a data management system of much greater Vertica features an automatic physical design tool called reach than a new language that people must learn. the Database Designer (DBD). The physical design problem • Resource Management: Specifying how a cluster’s in Vertica is to determine sets of projections that optimize a resources are to be shared and reporting on the cur- representative query workload for a given schema and sam- rent resource allocation with many concurrent users ple data while remaining within a certain space budget. The is critical to real world deployments. We initially un- major tensions to resolve during projection design are opti- der appreciated this point early in Vertica’s lifetime mizing query performance while reducing data load overhead and we believe it is still an understudied problem in and minimizing storage footprint. academic data management research. The DBD design algorithm has two sequential phases: 1. Query Optimization: Chooses projection sort order • Automated Tuning: Database users by and large and segmentation to optimize the performance of the wish to remain ignorant of a database’s inner workings query workload. During this phase, the DBD enumer- and focus on their application logic. Legacy RDBMS ates candidate projections based on heuristics such as systems often require heroic tuning efforts, which Ver- predicates, group by columns, order by columns, ag- tica has largely avoided by significant engineering ef- gregate columns, and join predicates. The optimizer fort and focus. For example, performance of early beta is invoked for each input query and given a choice of versions was a function of the physical storage layout the candidate projections. The resulting plan is used and required users to learn how to tune and control the to choose the best projections from amongst the can- storage system. Automating storage layout manage- didates. The DBD’s system to resolve conflicts when ment required Vertica to make significant and interre- different queries are optimized by different projections lated changes to the storage system, execution engine is important, but beyond the scope of this paper. The and tuple mover. DBD’s direct use of the optimizer and cost model guar- antees that it remains synchronized as the optimizer • Predictability vs. Special Case Optimizations: evolves over time. It was tempting to pick low hanging performance op- timization fruit that could be delivered quickly, such 2. Storage Optimization: Finds the best encoding sche- as transitive predicate creation for INNER but not mes for the designed projections via a series of empiri- OUTER joins or specialized filter predicates for Hash cal encoding experiments on the sample data, given the joins but not Merge joins. To our surprise, such special sort orders chosen in the query optimization phase. case optimizations caused almost as many problems as they solved because certain user queries would go su- The DBD provides different design policies so users can per fast and some would not in hard to predict ways, trade off query optimization and storage footprint: (a) load- often due to some incredibly low level implementation optimized, (b) query-optimized and (c) balanced. These detail. To our surprise, users didn’t accept the ratio- policies indirectly control the number of projections pro- nale that it was better that some queries got faster posed to achieve the desired balance between query per- even though not all did. formance and storage/load constraints. Other design chal- lenges include monitoring changes in query workload, schema, • Direct Loading to the ROS: While appealing in and cluster layout and determining the incremental impact theory, directing all newly-inserted data to the WOS on the design. wastefully consumes memory. Especially while ini- As our user base has expanded, the DBD is now univer- tially loading a system, the amount of data in a single sally used for a baseline physical design. Users can then bulk load operation was likely to be many tens of giga- manually modify the proposed design before deployment. bytes in size and thus not memory resident. Users are Especially in the case of the largest (and thus most impor- 7 tant) tables, expert users sometimes make minor changes Which at least one author admits having done in the past 1799
11 . Metric C-Store Vertica Size (MB) Comp. Bytes Per Q1 30 ms 14 ms Ratio Row Q2 360 ms 71 ms Rand. Integers Q3 4900 ms 4833 ms Raw 7.5 1 7.9 Q4 2090 ms 280 ms gzip 3.6 2.1 3.7 Q5 310 ms 93 ms gzip+sort 2.3 3.3 2.4 Q6 8500 ms 4143 ms Vertica 0.6 12.5 0.6 Q7 2540 ms 161 ms Customer Data Total Query Time 18.7 s 9.6s Raw CSV 6200 1 32.5 Disk Space Required 1,987 MB 949 MB gzip 1050 5.9 5.5 Vertica 418 14.8 2.2 Table 3: Performance of Vertica compared with C- Store on single node Pentium 4 hardware using the Table 4: Compression achieved in Vertica for 1M queries and test harness of the C-Store paper. Random Integers and Customer Data. more than happy to explicitly tag such loads to target subset of all byte representations. Sorting the data before the ROS in exchange for improved resource usage. applying gzip makes it much more compressible resulting in a compressed size of 2.2 MB. However, by avoiding strings • Bulk Loading and Rejected Records: Handling and using a suitable encoding, Vertica stores the same data input data from the bulk loader that did not conform in 0.6 MB. to the defined schema in a large distributed system turned out to be important and complex to implement. 8.2.2 200M Customer Records Vertica has a customer that collects metrics from some 8. PERFORMANCE MEASUREMENTS meters. There are 4 columns in the schema: Metric: There are a few hundred metrics collected. Meter: There are 8.1 C-Store a couple of thousand meters. Collection Time Stamp: One of the early concerns of the Vertica investors was that Each meter spits out metrics every 5 minutes, 10 minutes, the demands of a product-grade feature set would degrade hour, etc., depending on the metric. Metric Value: A performance, or that the performance claims of the C-Store 64-bit floating point value. prototype would otherwise not generalize to a full commer- A baseline file of 200 million comma separated values cial database implementation. In fact, there were many fea- (CSV) of the meter/metric/time/value rows takes 6200 MB, tures to be added, any of which could have degraded per- for 32 bytes per row. Compressing with gzip reduces this to formance such as support for: (1) multiple data types, such 1050 MB. By sorting the data on metric, meter, and collec- as FLOAT and VARCHAR, where C-Store only supported tion time, Vertica not only optimizes common query predi- INTEGER, (2) processing SQL NULLs, which often have cates (which specify the metric or a time range), but exposes to be special cased, (3) updating/deleting data, (4) multiple great compression opportunities for each column. The total ROS and WOS stores, (5) ACID transactions, query opti- size for all the columns in Vertica is 418MB (slightly over mization, resource management, and other overheads, and 2 bytes per row). Metric: There aren’t many. With RLE, (6) 64-bit instead of 32-bit for integral data types. it is as if there are only a few hundred rows. Vertica com- Vertica reclaims any performance loss using software en- pressed this column to 5 KB. Meter: There are quite a few, gineering methods such as vectorized execution and more and there is one record for each meter for each metric. With sophisticated compression algorithms. Any remaining over- RLE, Vertica brings this down to a mere 35 MB. Collec- head is amortized across the query, or across all rows in a tion Time Stamp: The regular collection intervals present data block, and turns out to be negligible. Hence, Vertica a great compression opportunity. Vertica compressed this is roughly twice as fast as C-Store on a single-core machine, column to 20 MB. Metric Value: Some metrics have trends as shown in table 3. 8 (like lots of 0 values when nothing happens). Others change gradually with time. Some are much more random, and less 8.2 Compression compressible. However, Vertica compressed the data to only This section describes experiments that show Vertica’s 363MB. storage engine achieves significant compression with both contrived and real customer data. Table 4 summarizes our 9. RELATED WORK results which were first presented here [6]. The contributions of Vertica and C-Store are their unique combination of previously documented design features ap- 8.2.1 1M Random Integers plied to a specific workload. The related work section in [21] In this experiment, we took a text file containing a million provides a good overview of the research roots of both C- random integers between 1 and 10 million. The raw data Store and Vertica prior to 2005. Since 2005, several other re- is 7.5 MB because each line is on average 7 digits plus a search projects have been or are being commercialized such newline. Applying gzip, the data compresses to about 3.6 as InfoBright [3], Brighthouse [24], Vectorwise [1], and Mon- MB, because the numbers are made of digits, which are a etDB/X100 [10]. These systems apply techniques similar 8 Comparison on a cluster of modern multicore machines was to those of Vertica such as column oriented storage, multi- deemed unfair, as the C-Store prototype is a single-threaded core execution and automatic storage pruning for analytical program and cannot take advantage of MPP hardware. workloads. The SAP HANA [14] system takes a different 1800
12 .approach to analytic workloads and focuses on columnar in- Tenzing: A SQL Implementation On The MapReduce memory storage and tight integration with other business framework. PVLDB, 4(12):1318–1327, 2011. applications. Blink [23] also focuses on in-memory execu- [10] P. A. Boncz, M. Zukowski, and N. Nes. tion as well as being a distributed shared-nothing system. MonetDB/X100: Hyper-Pipelining Query Execution. In addition, the success of Vertica and other native column In CIDR, pages 225–237, 2005. stores has led legacy RDBMS vendors to add columnar stor- [11] S. Ceri and J. Widom. Deriving Production Rules for age options [20, 4] to their existing engines. Incremental View Maintenance. In VLDB, pages 577–589, 1991. 10. CONCLUSIONS [12] J. Dean and S. Ghemawat. MapReduce: Simplified In this paper, we described the system architecture of the Data Processing on Large Clusters. In OSDI, pages Vertica Analytic Database, pointing out where our design 137–150, 2004. differs or extends that of C-Store. We have also shown some [13] G. DeCandia, D. Hastorun, M. Jampani, quantitative and qualitative advantages afforded by that ar- G. Kakulapati, A. Lakshman, A. Pilchin, chitecture. S. Sivasubramanian, P. Vosshall, and W. Vogels. Vertica is positive proof that modern RDBMS systems Dynamo: Amazon’s Highly Available Key-value Store. can continue to present a familiar relational interface yet In SOSP, pages 205–220, 2007. still achieve the high performance expected from modern [14] F. F¨arber, S. K. Cha, J. Primsch, C. Bornh¨ovd, analytic systems. This performance is achieved with ap- S. Sigg, and W. Lehner. SAP HANA Database: Data propriate architectural choices drawing on the rich database Management for Modern Business Applications. ACM research of the last 30 years. SIGMOD Record, 40(4):45–51, 2012. Vertica would not have been possible except for new in- [15] J. Gray and A. Reuter. Transaction Processing: novations from the research community since the last major Concepts and Techniques. Morgan Kaufmann commercial RBDMs were designed. We emphatically believe Publishers Inc., 1992. that database research is not and should not be about incre- [16] P. J. Haas, J. F. Naughton, S. Seshadri, and L. Stokes. mental changes to existing paradigms. Rather, the commu- Sampling-Based Estimation of the Number of Distinct nity should focus on transformational and innovative engine Values of an Attribute. In VLDB, pages 311–322, designs to support the ever expanding requirements placed 1995. on such systems. It is an exciting time to be a database [17] W. Kim. On Optimizing a SQL-like Nested Query. implementer and researcher. ACM TODS, 7(3):443–469, 1982. [18] R. Kimball and M. Ross. The Data Warehouse 11. ACKNOWLEDGMENTS Toolkit: The Complete Guide to Dimensional The Vertica Analytic Database is the product of the hard Modeling. Wiley, John & Sons, Inc., 2002. work of many great engineers. Special thanks to Goetz [19] A. Lakshman and P. Malik. Cassandra: A Graefe, Kanti Mann, Pratibha Rana, Jaimin Dave, Stephen Decentralized Structured Storage System. SIGOPS Walkauskas, and Sreenath Bodagala who helped review this Operating Systems Review, 44(2):35–40, 2010. paper and contributed many interesting ideas. [20] P.-˚ A. Larson, E. N. Hanson, and S. L. Price. Columnar Storage in SQL Server 2012. IEEE Data 12. REFERENCES Engineering Bulletin, 35(1):15–20, 2012. [1] Actian Vectorwise. [21] M. Stonebraker, D. J. Abadi, A. Batkin, X. Chen, M. http://www.actian.com/products/vectorwise. Cherniack, M. Ferreira, E. Lau, A. Lin, S. Madden [2] HP Completes Acquisition of Vertica Systems, Inc. and E. J. O’Neil et.al. C-Store: A Column-oriented http://www.hp.com/hpinfo/newsroom/press/ DBMS. In VLDB, pages 553–564, 2005. 2011/110322c.html. [22] G. Moerkotte. Small Materialized Aggregates: A Light [3] Infobright. http://www.infobright.com/. Weight Index Structure for data warehousing. In [4] Oracle Hybrid Columnar Compression on Exadata. VLDB, pages 476–487, 1998. http://www.oracle.com/technetwork/middleware/bi- [23] R. Barber, P. Bendel, M. Czech, O. Draese, F. Ho, N. foundation/ehcc-twp-131254.pdf. Hrle, S. Idreos, M.S. Kim, O. Koeth and J.G. Lee [5] PostgreSQL. http://www.postgresql.org/. et.al. Business Analytics in (a) Blink. IEEE Data [6] Why Verticas Compression is Better. Engineering Bulletin, 35(1):9–14, 2012. http://www.vertica.com/2010/05/26/ [24] D. Slezak, J. Wroblewski, V. Eastwood, and P. Synak. why-verticas-compression-is-better. Brighthouse: An Analytic Data Warehouse for Ad-hoc [7] A. Thusoo, J.S. Sarma, N. Jain, Z. Shao, P. Chakka, Queries. PVLDB, 1(2):1337–1345, 2008. S. Anthony, H. Liu, P. Wyckoff and R. Murthy. Hive - [25] M. Staudt and M. Jarke. Incremental Maintenance of A Warehousing Solution Over a MapReduce Externally Materialized Views. In VLDB, pages Framework. PVLDB, 2(2):1626–1629, 2009. 75–86, 1996. [8] D. J. Abadi, D. S. Myers, D. J. Dewitt, and S. R. [26] M. Stonebraker. One Size Fits All: An Idea Whose Madden. Materialization Strategies in a Time has Come and Gone. In ICDE, pages 2–11, 2005. Column-Oriented DBMS. In ICDE, pages 466–475, [27] J. D. Ullman. Principles of Database and 2007. Knowledge-Base Systems, Volume II. Computer [9] B. Chattopadhyay, L. Lin, W. Liu, S. Mittal, P. Science Press, 1989. Aragonda, V. Lychagina, Y. Kwon and M. Wong. 1801
3秒后跳转登录页面
去登陆

