展开查看详情
1 .Hongbin Ma| PMC member of Apache Kylin
info@kyligence.io
�
2 .What is Apache Kylin
Apache Kylin is an open source distributed analytics engine that
provides a SQL interface for multi-dimensional analysis on
Hadoop
• Works well with extremely large datasets
• Provides REST API, ODBC and JDBC as user interface
• Widely adopted by many companies like eBay, JD, Baidu,
NetEase, VIP.com, etc.
Apache Kylin pre-calculates OLAP cubes with a horizontal
scalable computation framework(MapReduce, Spark, etc.) and
store the cubes into a reliable & scalable data store(HBase, Druid,
etc.)
1 0, . ,
�
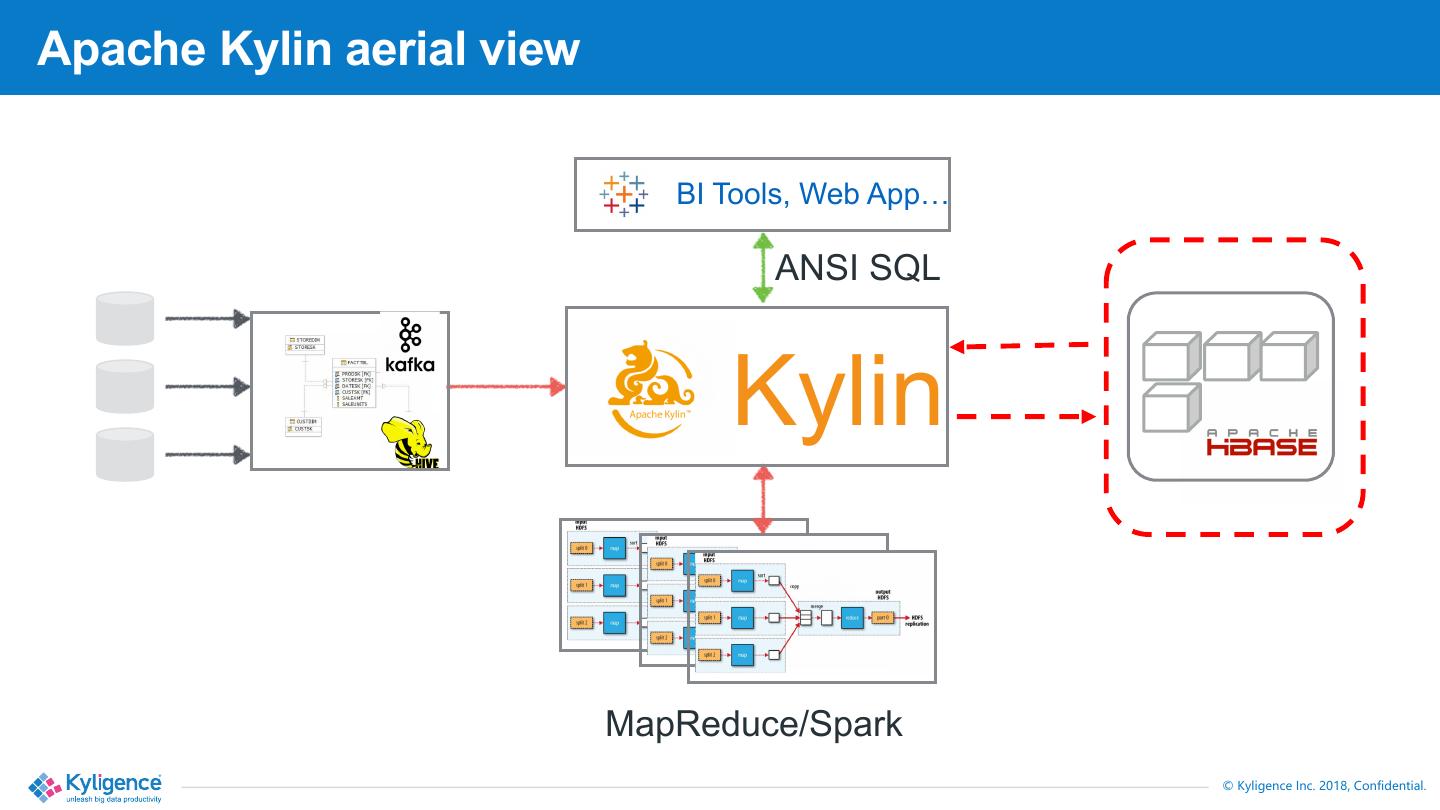
3 .Apache Kylin aerial view
BI Tools, Web App…
ANSI SQL
Kylin
MapReduce/Spark
1 0, . ,
�
4 .Architecture Design
3rd Party App SQL-Based Ø Online Analysis Data Flow
Ø Offline Data Flow
(Web App, Mobile…) Tool
(BI Tools: Tableau…) Ø Clients/Users interactive with
REST API JDBC/ODBC Kylin via SQL
Ø OLAP Cube is transparent to
users
SQ SQ
L L
REST Server
Query Engine
Low Latency -
Routing Seconds
Abstraction
Engine
Data Source
Abstraction
Storage
Hadoop Abstraction Data
OLAP
Hive Cube
Cubes
Metadata (HBase)
Cube Builder
Star Schema Data (MapReduce, Spark, etc…) Key Value Data
1 0, . ,
�
5 .Cube explained
dimensions cuboid lattice cuboid
1 0, . ,
�
6 .Cubes stored in HBase
Let’s take a looks at
cuboid (D1,D3,D5)
where all dimensions are:
(D1,D2,D3,D4,D5)
This cuboid is donated as “cuboid 00010101”
1 0, . ,
�
7 .Why HBase as the first choice?
• Well integrated with Hadoop
• Block encoding to reduce storage footprint
• Good at both seeking and scanning
• Coprocessors to move computation to data
• Scalable and flexible as a data store
1 0, . ,
�
8 .How Kylin queries HBase
Region server
region
1. Filter/Aggregation push
Kylin Query down coprocess
or
Server
3. Half baked results
2. Scan with Fuzzy Key
Filter
CuboidID SellerID Date Country Metrics…
1 0, . ,
�
9 .May still be slow when
• The cuboid is large because there’s really lots of
dimension combinations in it
• Cuboid layout is not friendly to query, e.g. filter on
suffix dimensions while group by prefix dimensions.
• The filter in query is very complex
• Regions are returning too many half-baked results
1 0, . ,
�
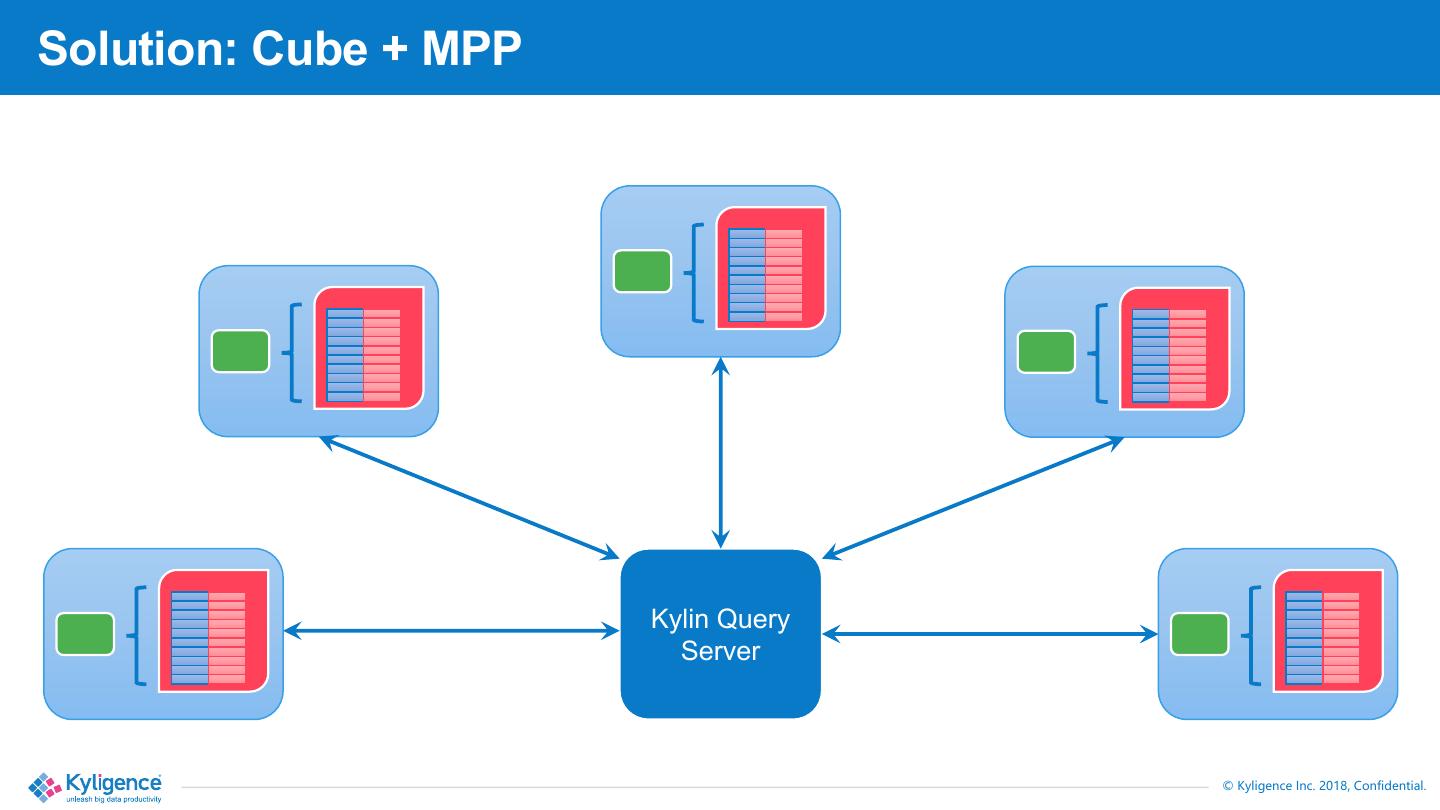
10 .Solution: Cube + MPP
Kylin Query
Server
1 0, . ,
�
11 .Novelty
§ Compared with “pure” MPP solutions
§ Cube data is more query-friendly because it is pre-
aggregated and sorted.
§ Faster speed
§ Less CPU consumption
§ Less storage read
§ Able to leverage column storage and inverted index just like
typical MPP
§ Compared with “pure” Cubing technologies
§ Overcome the bottleneck in cube size
§ Overcome the bottleneck in cube visiting speed
1 0, . ,
�
12 .Problem
§ The sizes of different cuboids in the
same cube may vary
§ Too many parallelism for small cuboids is
harmful
§ A RPC is required for each shard, we don’t
want to abuse network/CPU resource
1 0, . ,
�
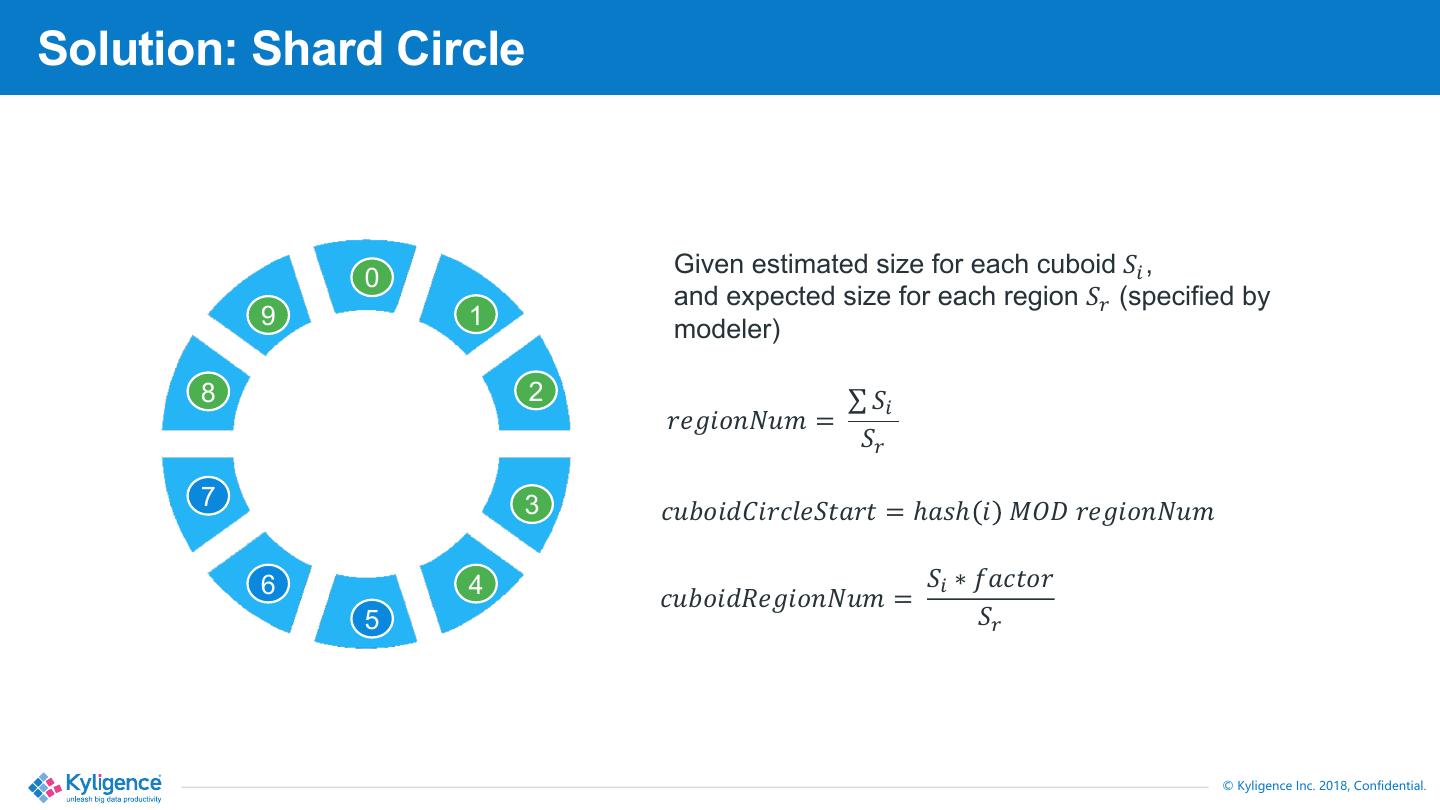
13 .Solution: Shard Circle
Given estimated size for each cuboid !" ,
0
and expected size for each region !# (specified by
9 1 modeler)
8 2 ∑ !"
$%&'()*+, =
!#
7 3 /+0('17'$/8%!65$6 = ℎ5:ℎ ' ;<= $%&'()*+,
6 4 !" ∗ 45/6($
/+0('12%&'()*+, =
5 !#
1 0, . ,
�
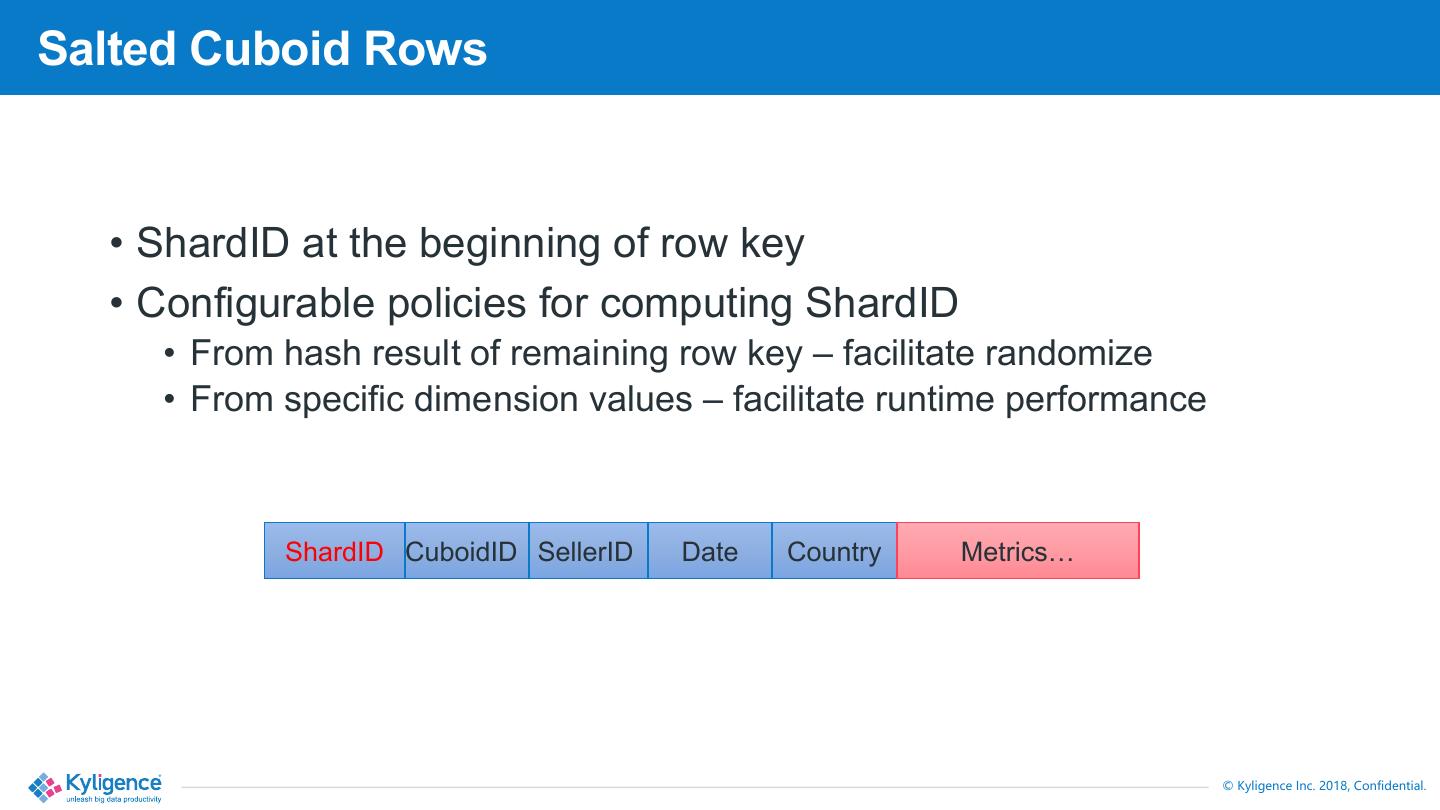
14 .Salted Cuboid Rows
• ShardID at the beginning of row key
• Configurable policies for computing ShardID
• From hash result of remaining row key – facilitate randomize
• From specific dimension values – facilitate runtime performance
ShardID CuboidID SellerID Date Country Metrics…
1 0, . ,
�
15 .Compute ShardID from SellerID
§ For queries those group by SellerID
§ Each shard aggregating non-joint subset
of SellerIDs
§ No further aggregation at merge side
§ For queries those filter by SellerID
§ The push down SellerID filter can be
trimmed to contain only interested
SellerIDs
1 0, . ,
�
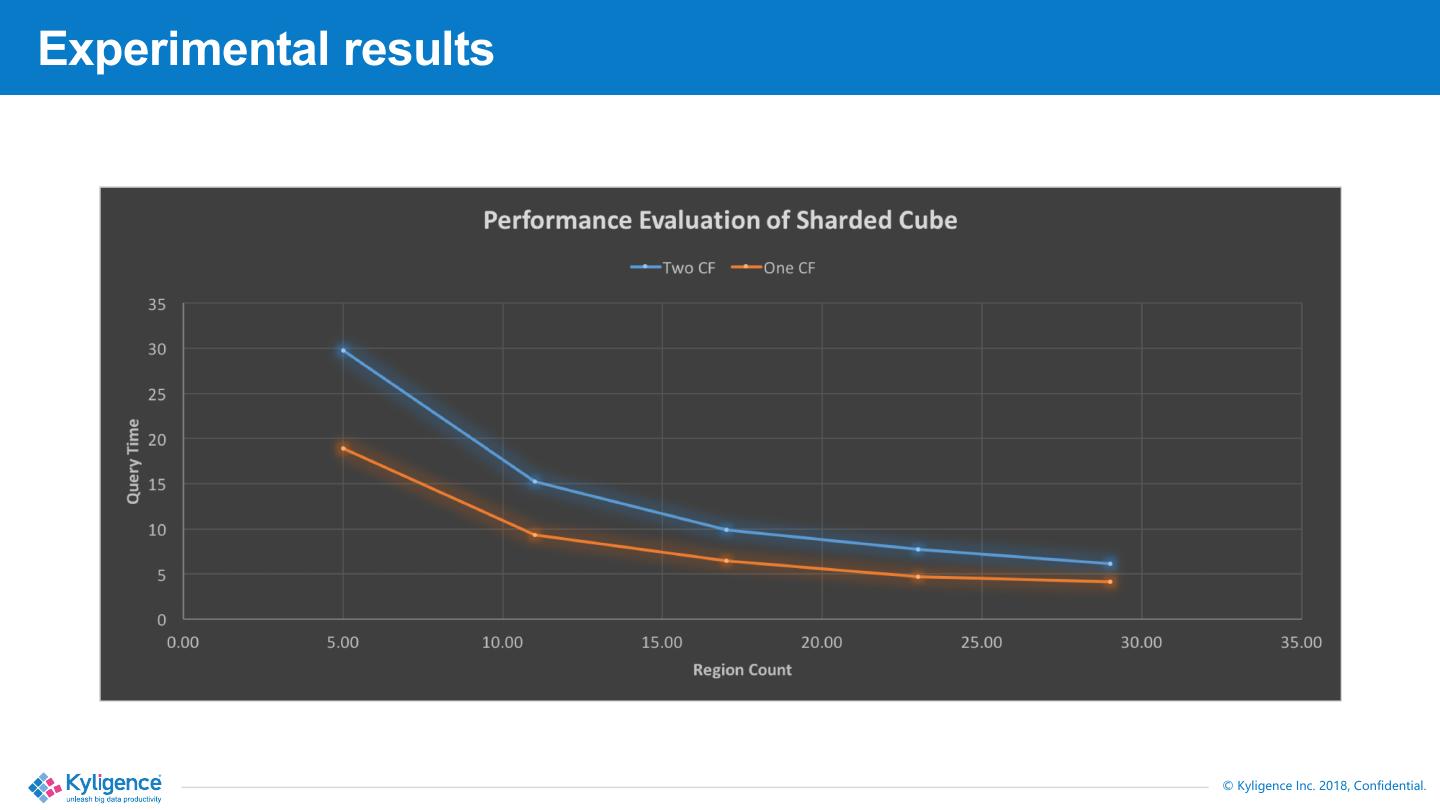
16 .Experimental results
1 0, . ,
�
17 .Small cuboids getting less shards
13 regions 23 regions
1.2
1.005586592
1
0.794117647
0.8
0.678571429
0.625 0.625
0.6
0.4
0.2
0
SQL 1 SQL 2 SQL 3 SQL 4 SQL 5
1 0, . ,
�
18 .Q&A
§ To get more information about
Apache Kylin:
§ Apache Kylin Website:
http://kylin.apache.org
§ Kyligence Website: http://kyligence.io
§ Twitter: @ApacheKylin
§ Mail list: dev@kylin.apache.org
1 0, . ,
�
19 .THANK YOU
K
Kyligence
Kyligence
1 0, . ,
�