



































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HTAP DB: ApsaraDB / HBase / Phoenix / Spark
HTAP DB: ApsaraDB Introduction,构建一站式的数据分析栈,对于内部组件和作用进行了详细介绍。
展开查看详情
1 . hosted by HTAP DB—System : ApsaraDB HBase Phoenix and Spark Yun Zhang & Wei Li August 17,2018
2 . hosted by Content Phoenix Over ApsaraDB 01 HBase Spark & ApsaraDB 02 HBase/Phoenix
3 . hosted by 1 Phoenix Over ApsaraDB HBase
4 . hosted by Content 1.1 Architecture 1.2 Use Cases 1.3 Best Practice 1.4 Challenges & Improvements
5 . hosted by 1.1 Phoenix Over ApsaraDB HBase
6 . hosted by Phoenix-As-A-Service Phoenix-as-a-service over ApsaraDB HBase ● Orientations ○ Provides OLTP and Operational analytics over ApsaraDB HBASE ● Targets ○ Make HBASE easier to use ■ JDBC API/SQL ○ Other functions ■ Secondary Index ■ Transaction ■ Multi tenancy ■ …
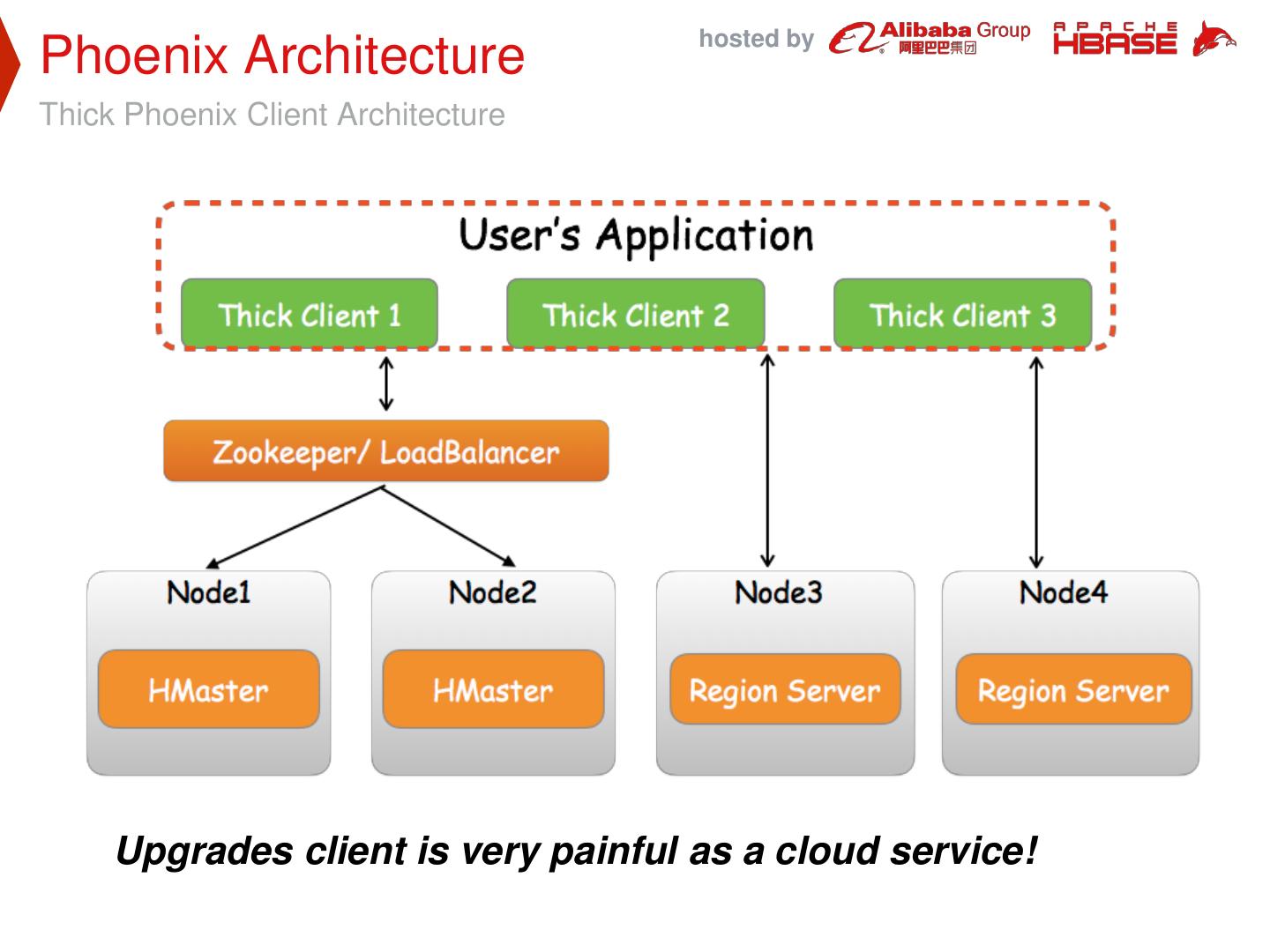
7 . hosted by Phoenix Architecture Thick Phoenix Client Architecture Upgrades client is very painful as a cloud service!
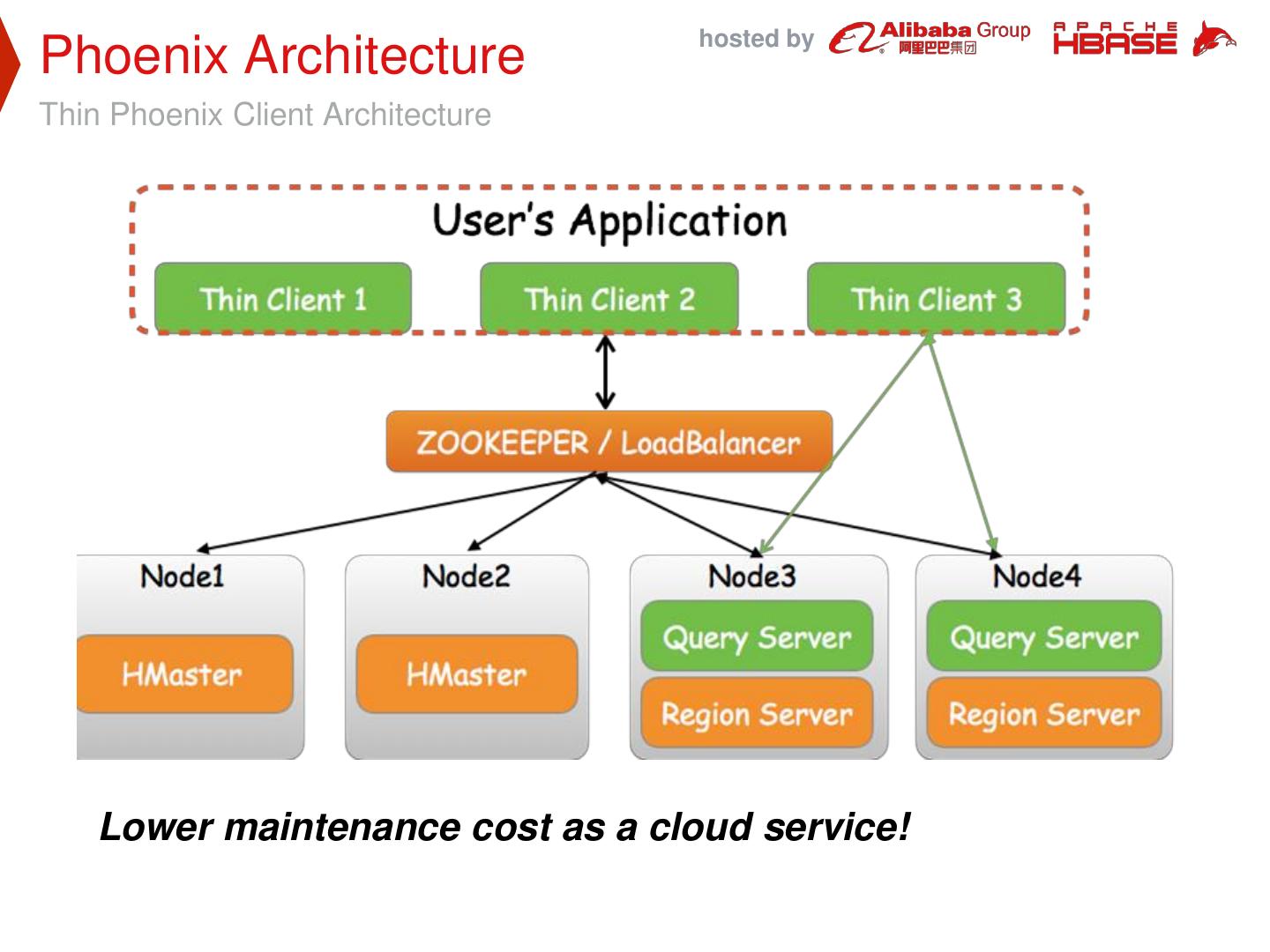
8 . hosted by Phoenix Architecture Thin Phoenix Client Architecture Lower maintenance cost as a cloud service!
9 . hosted by 1.2 Use Cases
10 . hosted by Use Case 1 LOT Scenario ● Data ○ Big table(Spatial Temporal Data) 100 million+ ○ Small table(User Information) less than 1 million ● Functional Requirements ○ Hash join(big table join small table) ○ Staled table (avoid hot spotting) ○ Secondary index ● Other Requirements ○ Latency less than 2 seconds (100 vertices of polygon) ○ Scale out
11 . hosted by Use Case 1 Architecture
12 . hosted by Use Case 1 Query
13 . hosted by Use Case 2 Internet Company Scenario ● Data ○ 350+ million/per day ○ 500G+/per day(uncompress) ● Functional Requirements ○ Staled table (avoid hot spotting) ○ Secondary index(multidimensional analytics) ● Other Requirements ○ Latency less than 200 Millisecond ○ 6+ index tables ○ Scale out
14 . hosted by Use Case 2 Architecture
15 . hosted by 1.3 Best Practices
16 . hosted by Best Practices Table Properties 1. Recommend to set UPDATE_CACHE_FREQUENCY when create table (120000ms as a default value) 2. Used pre-splitting keys is better than slated table.(Range scan is limited when use slate buckets) 3. Pre-splitting region for index table(if your data tables are salted table, index tables will inherit this property). 4. SALT_BUCKETS is not equal split keys(pre-splitting region)!!!
17 . hosted by Best Practices Query Hint 1. Use USE_SORT_MERGE_JOIN when join bigger tables. 2. Use NO_CACHE will avoid caching any HBase blocks loaded, which can reduce GC overhead and get better performance. it is used export data query, such as UPSERT…SELECT clause. 3. Use SMALL will save an RPC call on the scan, Which can reduce network overhead. it is used hit the small amount of data of query.
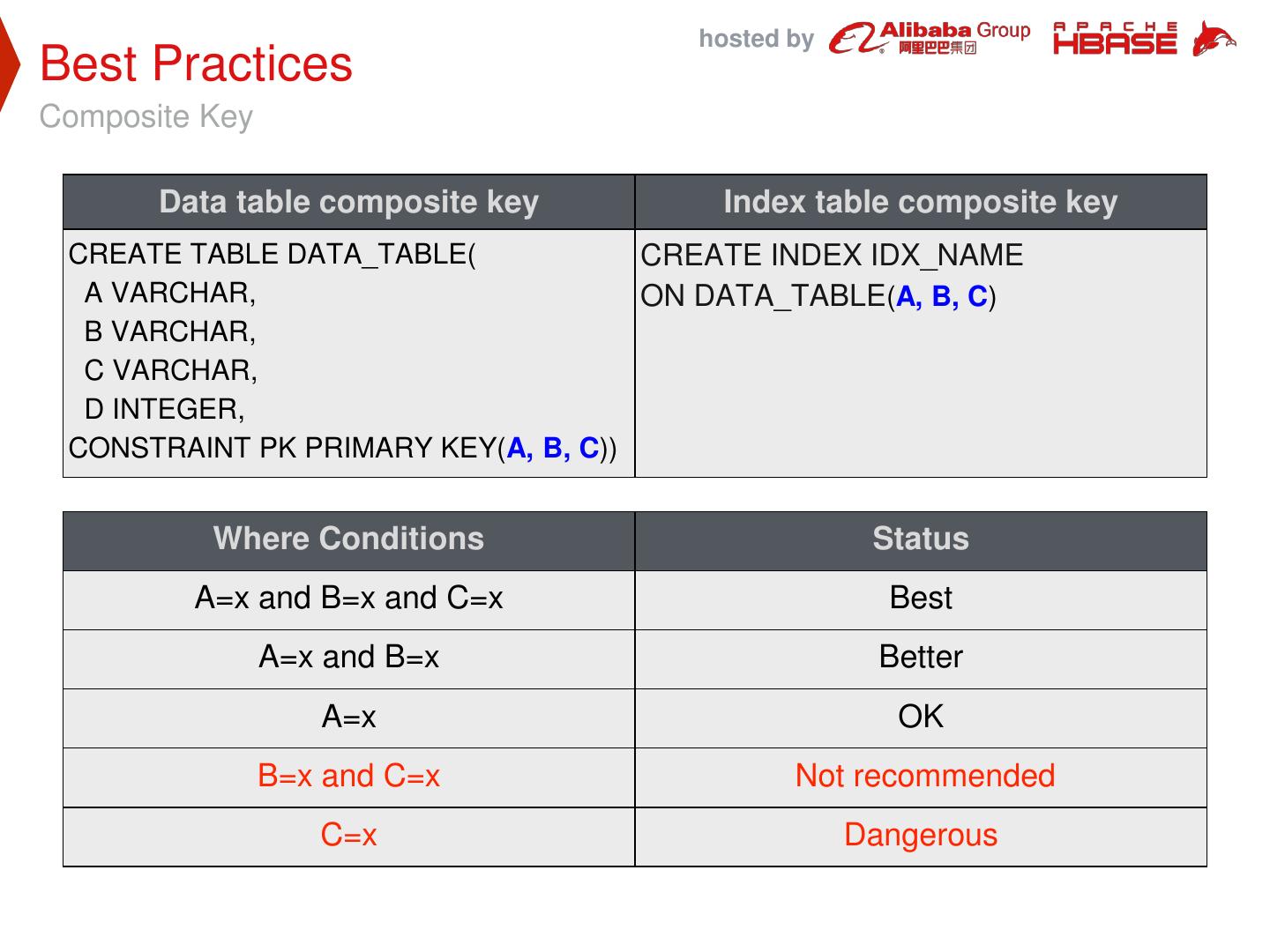
18 . hosted by Best Practices Composite Key Data table composite key Index table composite key CREATE TABLE DATA_TABLE( CREATE INDEX IDX_NAME A VARCHAR, ON DATA_TABLE(A, B, C) B VARCHAR, C VARCHAR, D INTEGER, CONSTRAINT PK PRIMARY KEY(A, B, C)) Where Conditions Status A=x and B=x and C=x Best A=x and B=x Better A=x OK B=x and C=x Not recommended C=x Dangerous
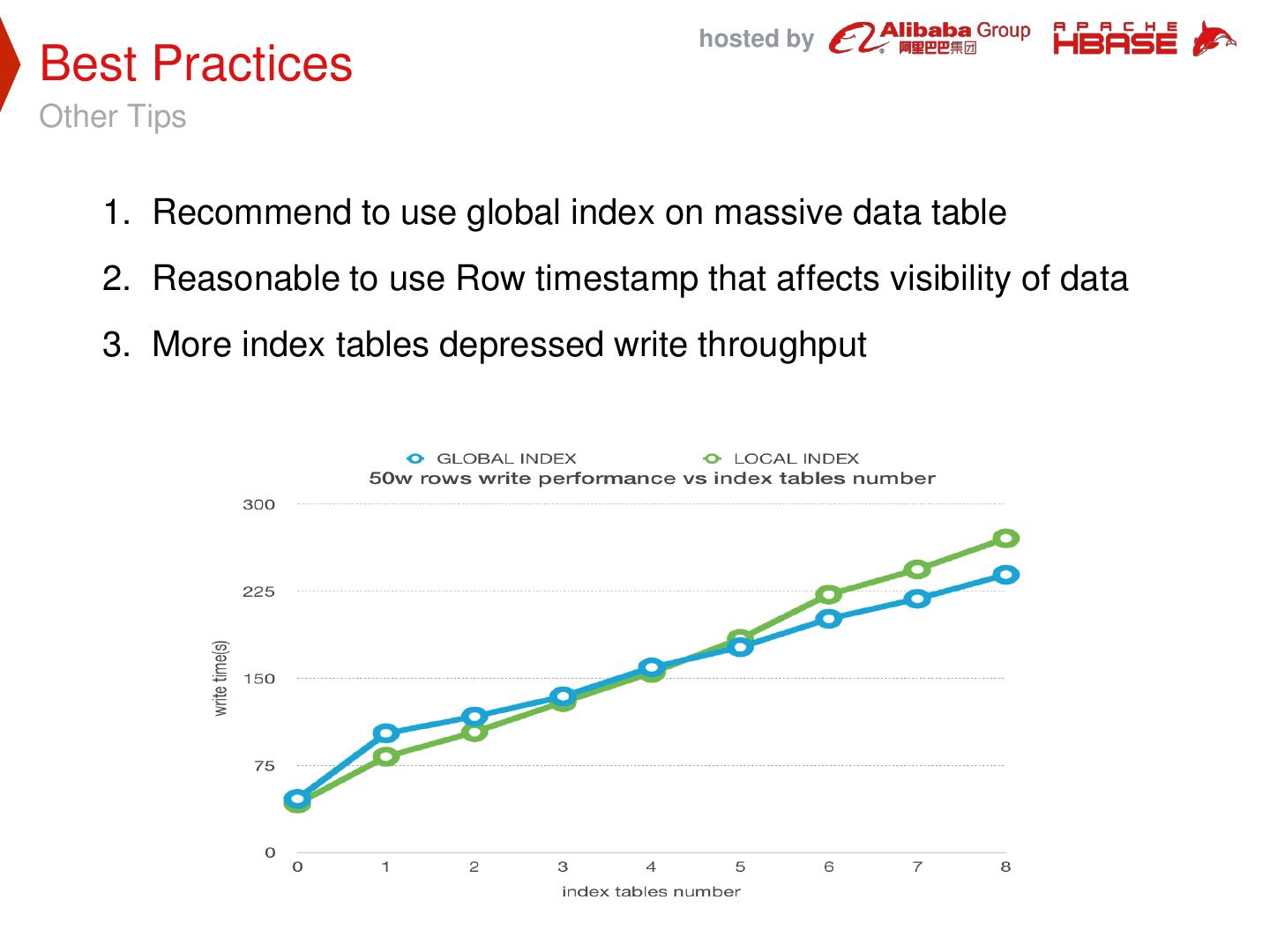
19 . hosted by Best Practices Other Tips 1. Recommend to use global index on massive data table 2. Reasonable to use Row timestamp that affects visibility of data 3. More index tables depressed write throughput
20 . hosted by 1.4 Challenges & Improvements
21 . hosted by Challenges ● Availability ○ Sometimes index table become unavailable. ● Stability ○ Full scan/complex queries affects cluster’s stability ● Users Complaints ○ queries can’t automatically choose the best index table ○ Using Python client get worse performance. ○ Lack of data transferring tools (data import/export) ○ Scarce monitor metrics ○ ...
22 . hosted by Improvements ● Stability ○ Phoenix Chaos Monkey test framework ● Availability ○ Support infinite retry policy when writing index failures to avoid degrade to full scan data table. ● Producibility ○ Recognizes some full scan/complex queries and reject on the Server(Query Server) side ○ Integrate monitor platform ○ Other new features ■ Alter modify column/rename ■ Reports rate of progress When creating index
23 . hosted by Spark & ApsaraDB 2 HBase/Phoenix
24 . hosted by Spark & ApsaraDB HBase 2.1 Overview Architecture & 2.2 Implementation 2.3 Scenario
25 . hosted by 2.1 Overview
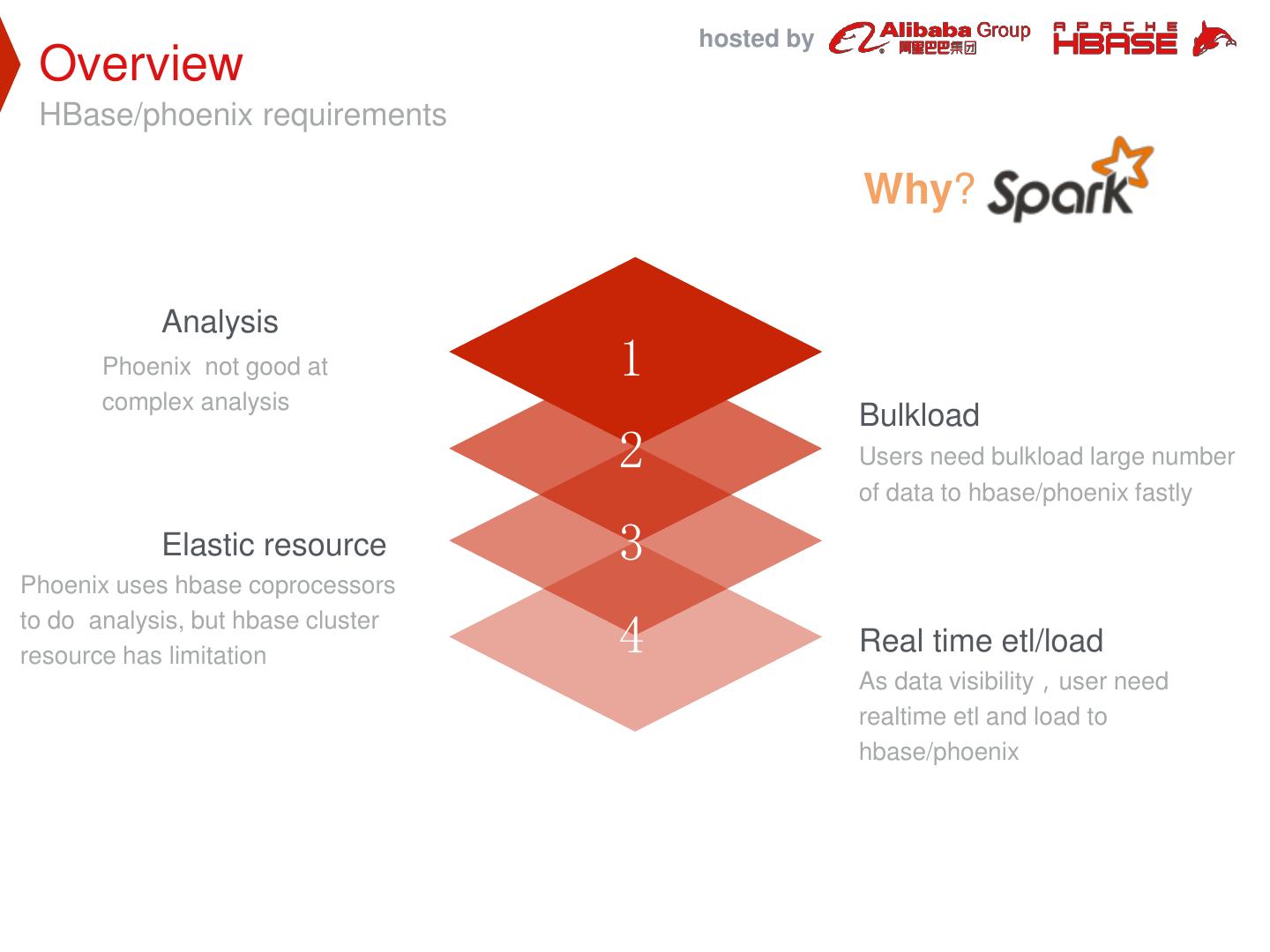
26 . hosted by Overview HBase/phoenix requirements Why? Analysis Phoenix not good at 1 complex analysis Bulkload 2 Users need bulkload large number of data to hbase/phoenix fastly Elastic resource 3 Phoenix uses hbase coprocessors to do analysis, but hbase cluster resource has limitation 4 Real time etl/load As data visibility,user need realtime etl and load to hbase/phoenix
27 . hosted by Overview what can spark bring to ApsaraDB HBase ➢ Analysis: • spark as a unified analytics engine,support SQL 2003 • Use dag support complex analysis ➢ Bulkload:spark can support multi datasource like jdbc, csv, elasticsearch, mongo; have elastic resource ➢ Realtime load:struct streaming easy to do etl, and load to hbase realtime analysis bulkload build index load HBase/ Phoenix spark Spark Compute resources
28 . hosted by 2.2 Architecture & Implementation
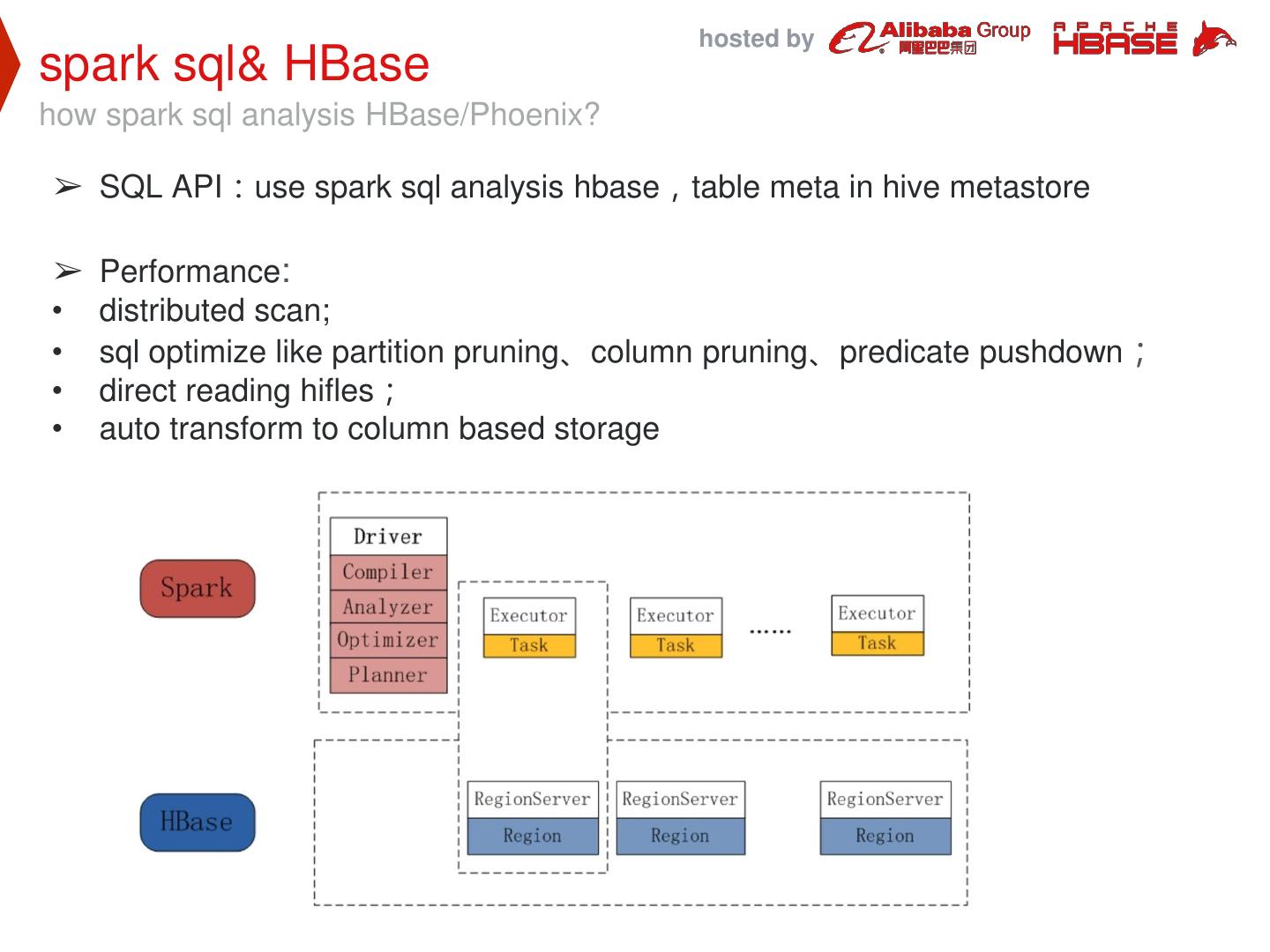
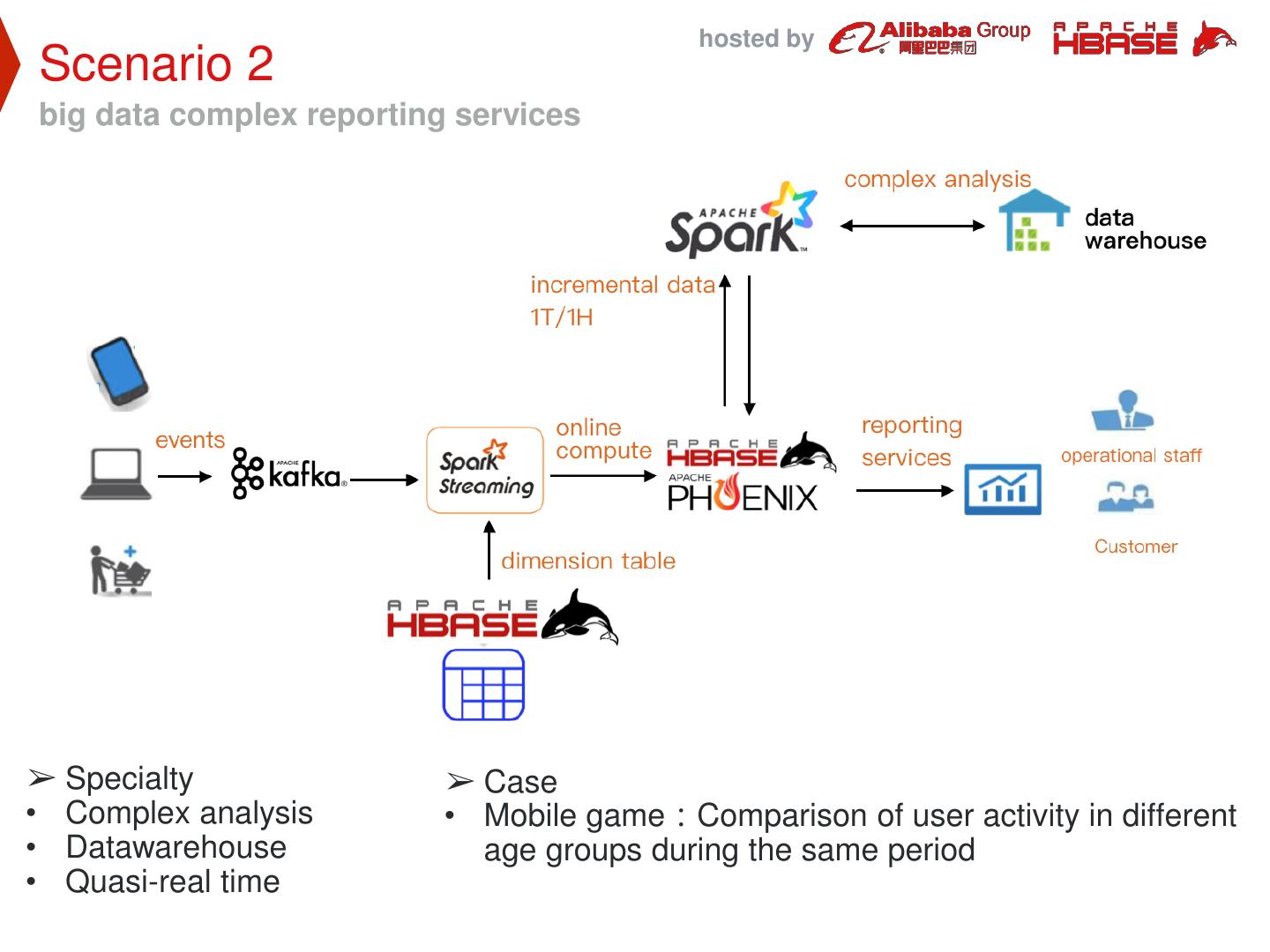
29 . hosted by Architecture & implementation Use ApsaraDB HBase and spark construct big data platform ➢ BATCH LAYER : use spark sql/dataset analysis HBase/Phoenix, also bulkload other datasources to HBase ➢ SPEED LAYER : use struct streaming etl data from kafka, and increment load into HBase ➢ SERVING LAYER : User query result data from HBase/Phoenix
3秒后跳转登录页面
去登陆

