

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Separating hot-cold data into heterogeneous storage
Apache HBase Committer Allan Yang介绍基于层次化数据规整,完成冷热数据分离并保存在异构存储中。
展开查看详情
1 . Separating hot-cold data into heterogeneous storage based on layered compaction Allan Yang(HBase Committer)
2 .Content 01 Typical Scenarios at Alibaba 02 Hot-cold Data Separation — Hot-cold Data Recognition — Layered Compaction — Query Optimizations 03 Conclusions
3 .01 Typical Scenarios at Alibaba
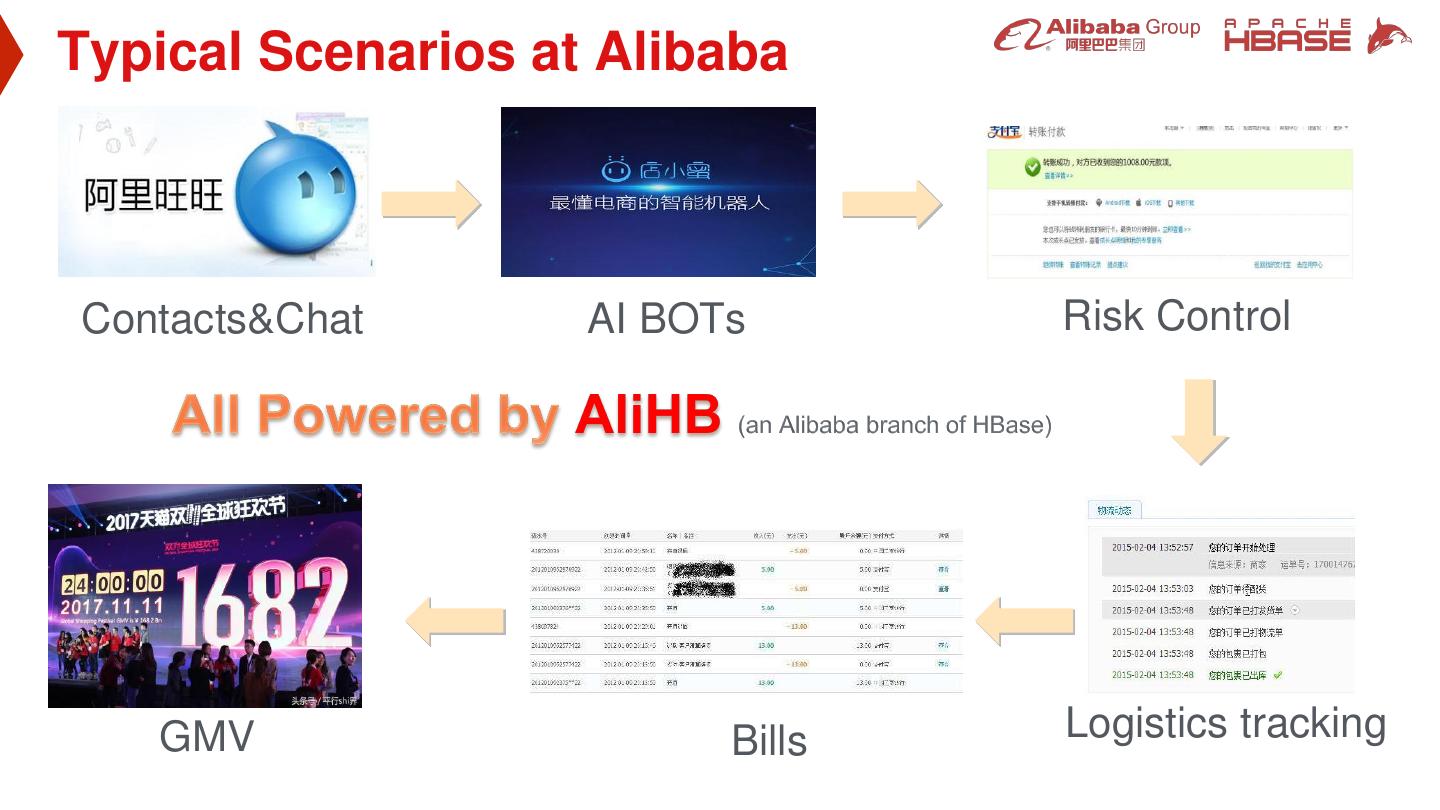
4 .Typical Scenarios at Alibaba Contacts&Chat AI BOTs Risk Control GMV Bills Logistics tracking
5 .Typical Scenarios Commonality in some Scenarios Mass data No TTLs Only very small parts of data is frequently visited Hotspots change as time goes by
6 .Definitions Hot DataHot Data HOT • Access very frequently • Access very frequently • Relatively small amount • Relatively small amount • Low latency is very critical • Low latency is very critical Cold Data COLD • Access rarely • Big amount • Cost is more concerned
7 .02 Hot-cold Data Separation
8 .Old Architecture Pros Client • Simple, no HBase code change needed Write Cold query Hot query Coprocessor Cons CopyTable Replication …… • High maintenance cost Hot Table Cold Table • Client aware • Hard to keep consistency
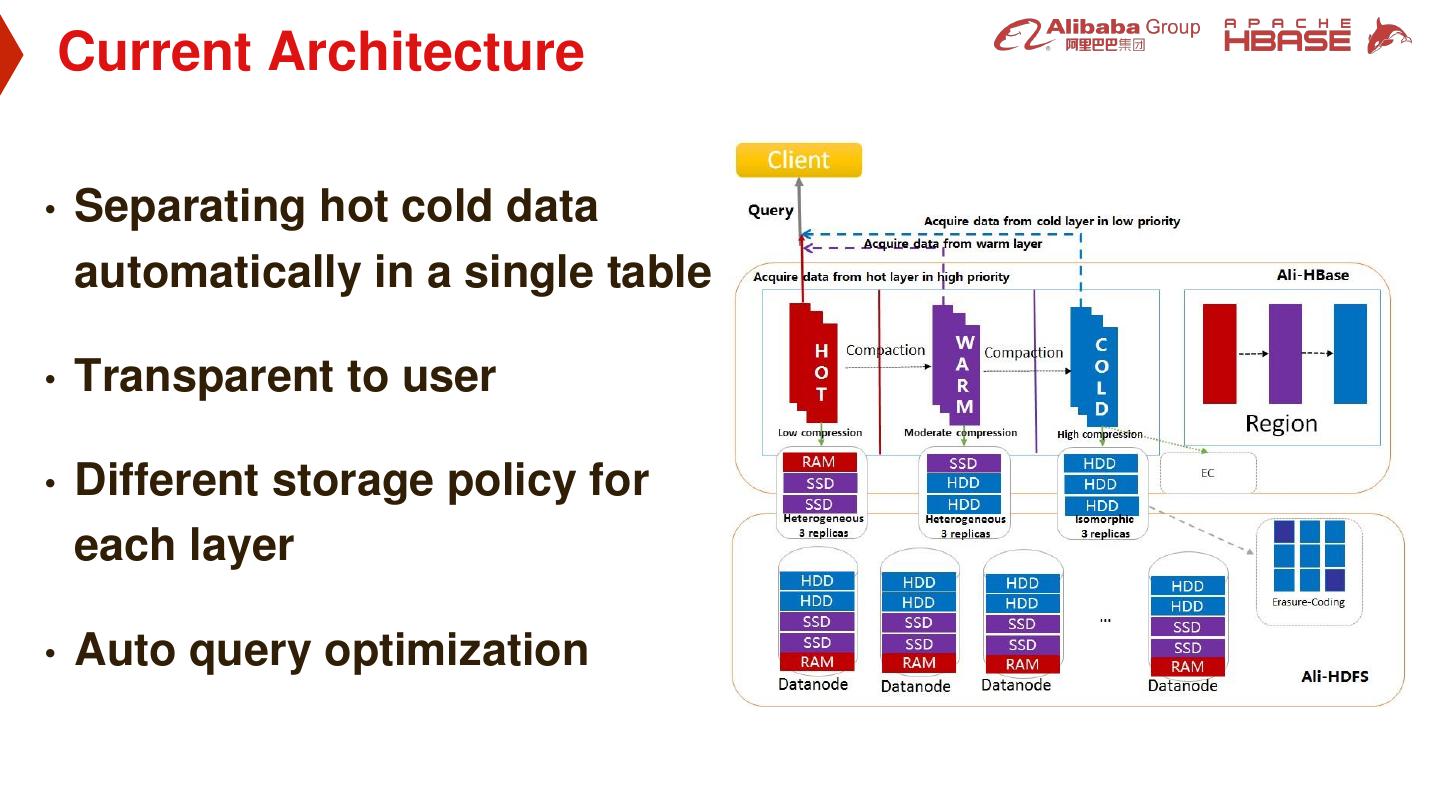
9 . Current Architecture • Separating hot cold data automatically in a single table • Transparent to user • Different storage policy for each layer • Auto query optimization
10 .Hot-cold Data Separation — Hot-cold Data Recognition — Layered Compaction — Query Optimizations
11 .Separating hot cold data The Problems of separating data by KV timestamp • Timestamp may not represents the heat of business data very well e.g. Write an order ID advance in current ts e.g. Data Source(Kafka, Spark…) delayed, resulting ts lag • KeyValue’s timestamp is also used as version number in HBase
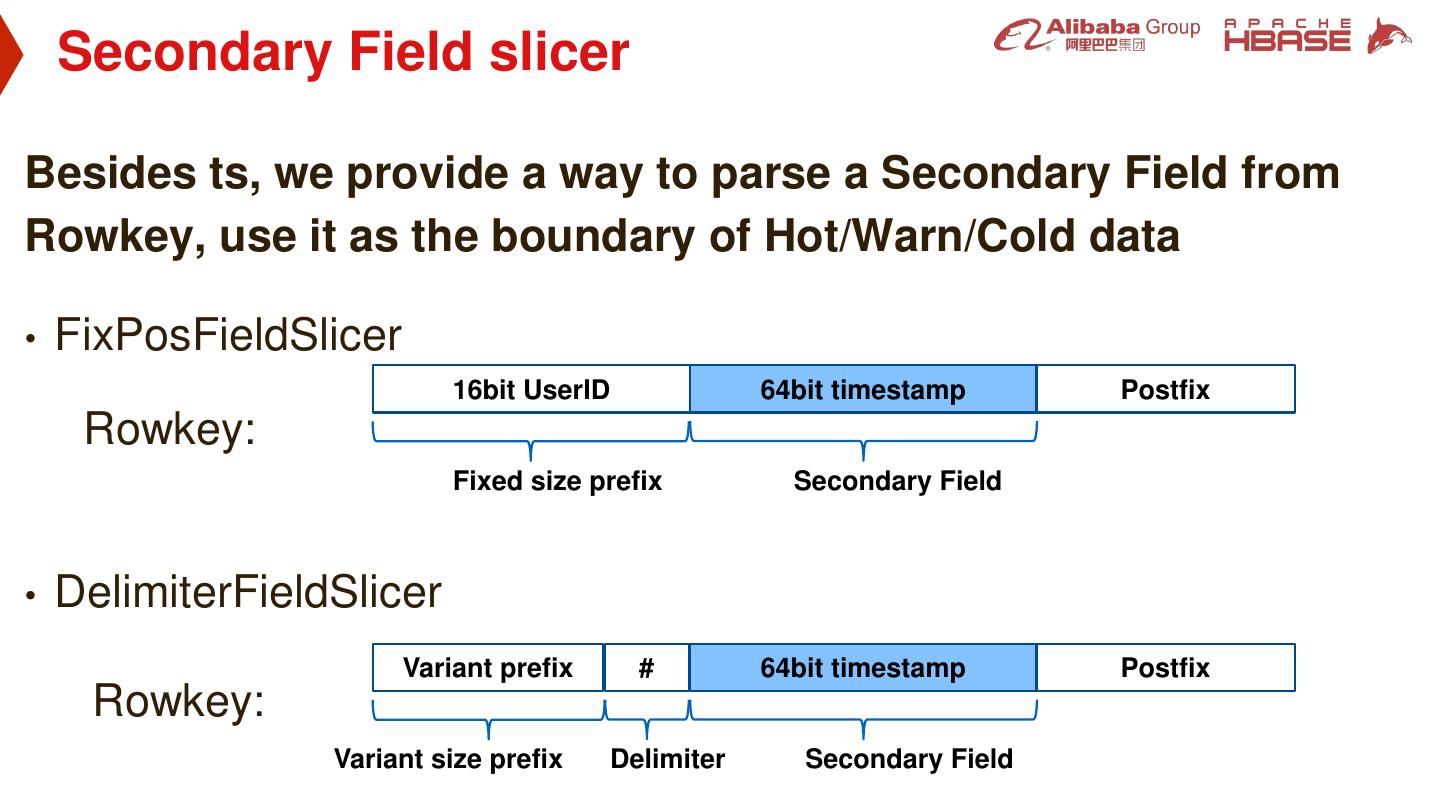
12 . Secondary Field slicer Besides ts, we provide a way to parse a Secondary Field from Rowkey, use it as the boundary of Hot/Warn/Cold data • FixPosFieldSlicer 16bit UserID 64bit timestamp Postfix Rowkey: Fixed size prefix Secondary Field • DelimiterFieldSlicer Variant prefix # 64bit timestamp Postfix Rowkey: Variant size prefix Delimiter Secondary Field
13 .Hot-cold Data Separation — Hot-cold Data Recognition — Layered Compaction — Query Optimizations
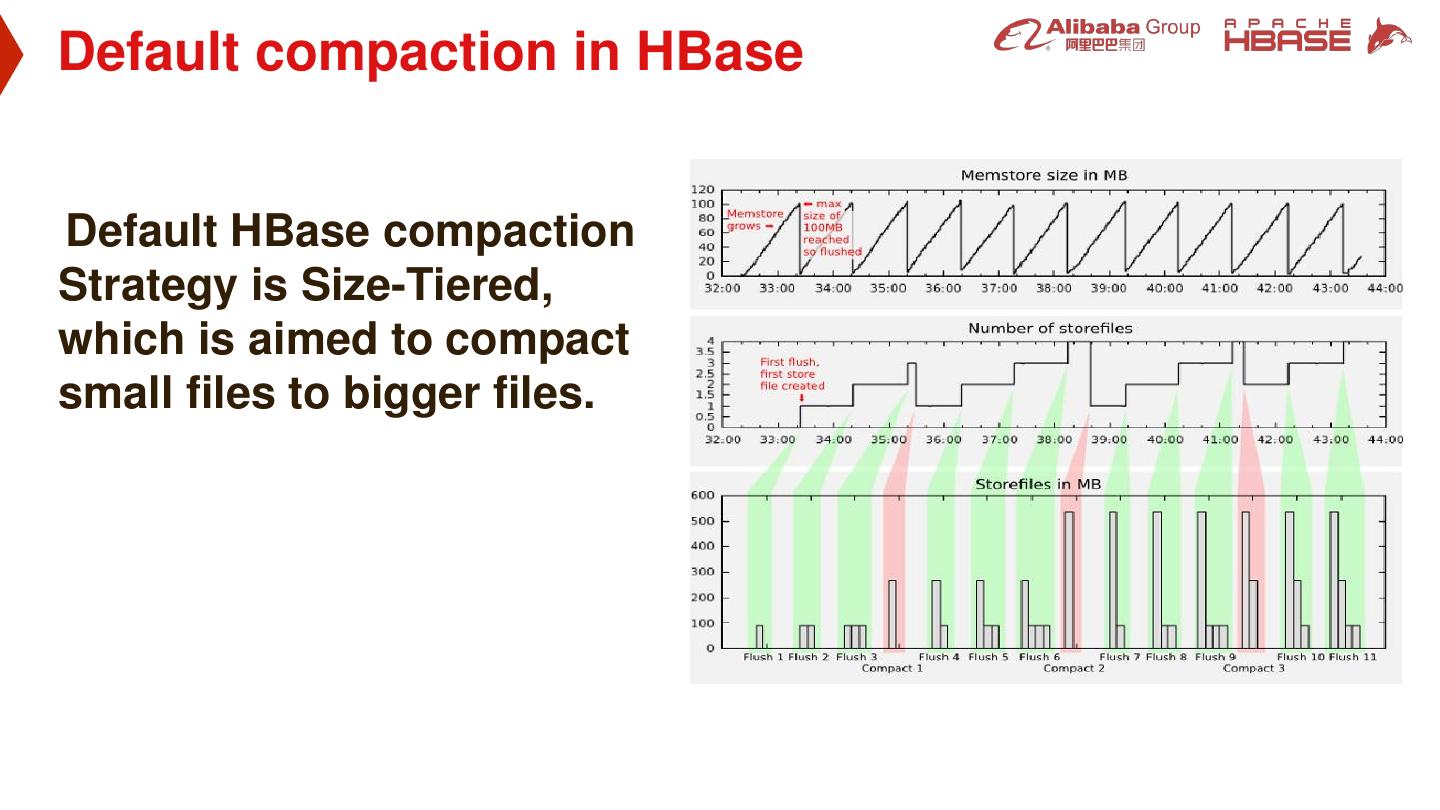
14 .Default compaction in HBase Default HBase compaction Strategy is Size-Tiered, which is aimed to compact small files to bigger files.
15 .Size-Tiered Compaction Strategy Time range of HFile • Size is the only concern • Old data and new data will spread around all HFiles • Can’t be used for Separating hot cold data Time range we want
16 .Date-Tiered Compaction Strategy Date-Tiered Compaction Strategy(HBASE-15181) Time Window Compact multiple time windows in to one tier when time goes by. The older, the bigger tier is. Logic view Physical view
17 .Separating hot cold data Our layered compaction is inspired by Date-tiered Compaction. • Only Cold/Warm/Hot window is needed • Data will move from hot to warn then to Cold window • Secondary Filed or timestamp is used
18 . Layered Compaction • HFile flushed by Memstore is always in L0 • Hot/Warm/Cold layer have their own compaction Strategy • Data is separated by secondary field or timestamp • Data out of boundary will be compacted out to next layer
19 .Layered Compaction • Compactor will output multiple HFiles HFile HFile according to the separation boundary HFile • Secondary Field range will be written into the FileInfo section of HFile Compactor e.g. Rowkey:userid+ts UserA002 HFile HFile (hot) (cold) UserA005 Secondary Secondary UserB003 Field Field Range Range UserB007 Secondary Field Range: 002…007
20 .Heterogeneous storage RAM SSD RAM SSD We can specify Data encoding, RAM SSD Compression, and storage type for All_RAM All_SSD each layer Here is an example: Data Erasure-Coding Type Compression Storage Encoding SSD HDD Hot None None SSD/RAM HDD HDD HDD HDD Warn DIFF LZO One_SSD One_SSD All_HDD Cold DIFF LZ4 HDD/EC
21 . Storage Computing Separation • Apsara HBase Provide a Architecture of storage computing separation • High density HDD will be available in Apsara HBase about this September. Apsara HBase Welcome to try Apsara HBase at https://www.aliyun.com/product/hbase
22 .Hot-cold Data Separation — Hot-cold Data Recognition — Layered Compaction — Query Optimizations
23 .HBase Read Path A quick tour of HBase read path Region Scan Start Store Memstore HFile 2 Memstore HFile 1 HFile 2 HFile 2 HFile 1 HFile3 HFile3 HFile4 Scan End HFile3 Memstore KeyValue Heap HFile4 is filtered out by: •Bloom filter •Time range •Key range
24 . Goal of Query Optimization Client • Query optimization is only for hot Query queries KeyValue Heap • We have to try our best to filter out the cold HFiles, avoid seek in them. HFile HFile (hot) (cold) • Seeking in cold HFiles can tremendously increase RT for hot queries
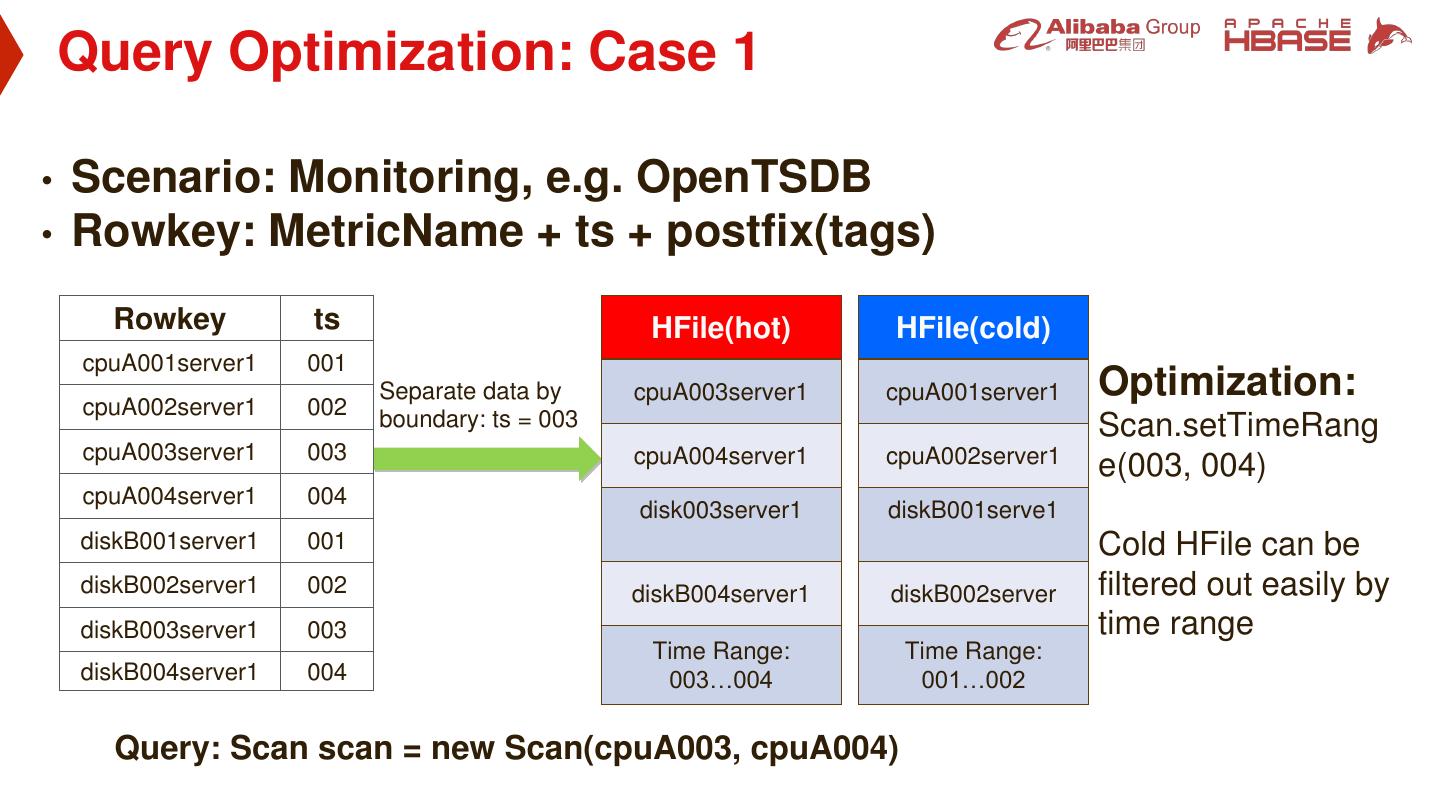
25 . Query Optimization: Case 1 • Scenario: Monitoring, e.g. OpenTSDB • Rowkey: MetricName + ts + postfix(tags) Rowkey ts HFile(hot) HFile(cold) cpuA001server1 001 Separate data by cpuA003server1 cpuA001server1 Optimization: cpuA002server1 002 boundary: ts = 003 Scan.setTimeRang cpuA003server1 003 cpuA004server1 cpuA002server1 e(003, 004) cpuA004server1 004 disk003server1 diskB001serve1 diskB001server1 001 Cold HFile can be diskB002server1 002 diskB004server1 diskB002server filtered out easily by diskB003server1 003 time range Time Range: Time Range: diskB004server1 004 003…004 001…002 Query: Scan scan = new Scan(cpuA003, cpuA004)
26 . Query Optimization: Case 2 • Scenario: Tracing system • Rowkey: TraceID (events are recorded in different column) Rowkey ts HFile(hot) HFile(cold) traceid1 001 traceid2 002 traceid5 traceid1 Optimization: Separate data by Cold HFile can be filtered traceid3 003 traceid6 traceid2 out by Bloom Filter boundary: ts = 004 traceid4 004 traceid7 traceid3 Problem: traceid5 005 false positive of bloom filter traceid6 006 can cause spikes traceid8 traceid4 traceid7 007 Bloom Filter Bloom Filter traceid8 008 Query: Get get= new Get(“traceid7”)
27 .Lazy Seek (HBASE-4465) Lazy Seek KeyValue Heap KeyValue Heap Create a fake row with biggest ts possible Row,column,ts Row,column,ts ① Fake row: ① Fake row: row2,f:q,008 row2,f:q,004 Row1,f:q,008 Row1,f:q,001 ① ① Row1,f:q,008 Row1,f:q,001 Row2,f:q,007 Row2,f:q,003 ② Row2,f:q,007 Row2,f:q,002 Row2,f:q,006 Row2,f:q,002 Row2,f:q,006 Row2,f:q,003 Row3,f:q,005 Row3,f:q,004 Row3,f:q,005 Row3,f:q,004 Time Range: Time Range: 005…007 001…004 Time Range: Time Range: 005…008 001…004 HFile1 HFile2 HFile1 HFile2 Query: Select row >= Row2,f:q and limit =1
28 . Scenario: KV Store Query Optimization: Case 3 Rowkey: key(with only one qualifier) • Scenario: KV Store • Rowkey: key(with only one qualifier) Row,Column ts HFile(hot) HFile(cold) Optimization: Fake row: Fake row: Cold HFile will not be Row1,f:q1 001 Separate data by boundary: ts = 004 Row5,f:q1, 006 Row5,f:q1, 003 seeked because of Row2,f:q1 002 lazy seek Row4,f:q1 Row1,f:q1 Row3,f:q1 003 Row5,f:q1 Row2,f:q1 Row4,f:q1 004 Row6,f:q1 Row3,f:q1 Row5,f:q1 005 False positive of Bloom Filter Bloom Filter Row6,f:q1 006 bloom filter Time Range: Time Range: 004…006 001…003 Query: Get get= new Get(“Row5,f:q1”) 28
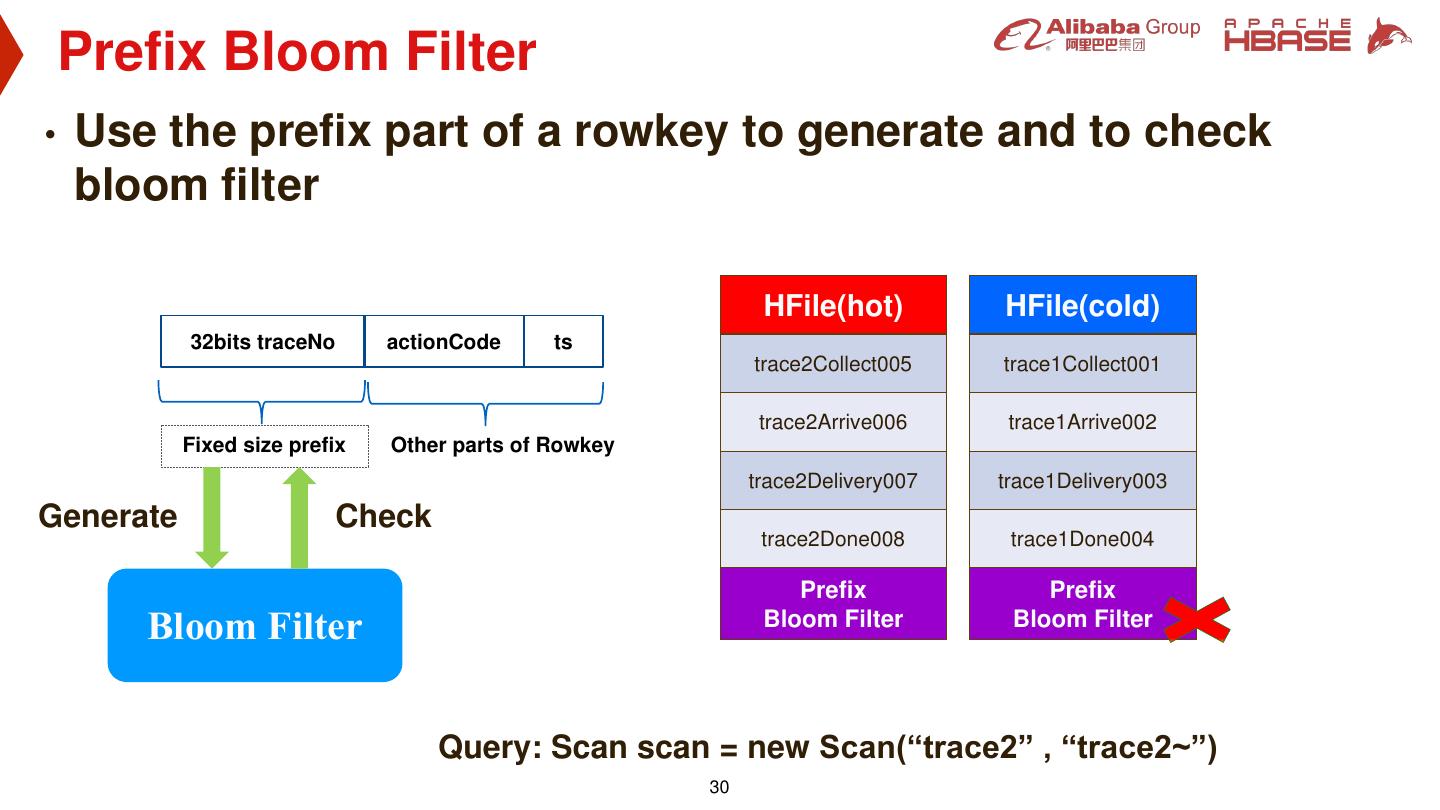
29 . Query Optimization: Case 4 • Scenario: Logistics tracking in Alibaba • Rowkey: traceNo + actionCode + ts Rowkey ts HFile(hot) HFile(cold) Problem: trace1Collect001 001 Scan with prefix, no time trace2Collect005 trace1Collect001 Separate data by range can be provided trace1Arrive002 002 boundary: ts = 004 trace2Arrive006 trace1Arrive002 trace1Delivery003 003 trace1Done004 004 trace2Delivery007 trace1Delivery003 trace2Collect005 005 trace2Done008 trace1Done004 trace2Arrive006 006 Time Range: Time Range: trace2Delivery007 007 005…008 001…004 trace2Done008 008 Query: Scan scan = new Scan(“trace2” , “trace2~”) 29
3秒后跳转登录页面
去登陆

