



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase at XiaoMi
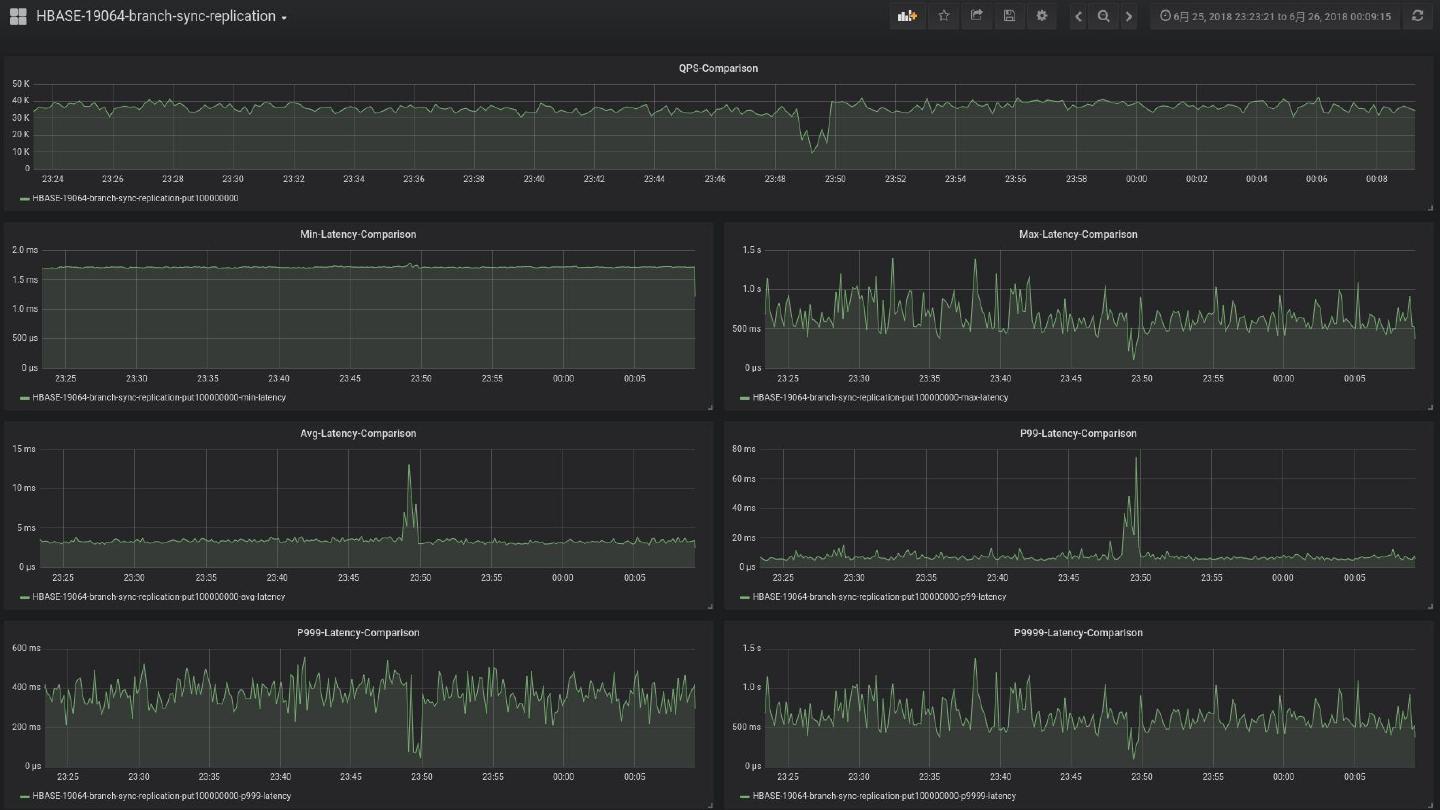
作为国内应用HBase技术最早的公司之一,来自小米的工程师先介绍了HBase在小米内部的总体架构设计和数据量级,然后介绍在保证SLA前提下,对于RPC Throttling,配额管理,同步异步数据复制和核心服务器当机等情况下的解决方案。
展开查看详情
1 .hosted by HBase at Xiaomi Guanghao Zhang zghao@apache.org
2 . hosted by About Xiaomi ● Founded in 2010 ● Worldwide smartphone No.4 shipments, Q2 2018 ● 300+ million global users ● Products: smart phone, TV, AI speaker, smart band…
3 . hosted by Our HBase Team ● 2 PMC members ● 1 Committer ● 3 HBase Contributers
4 . hosted by Content 01 Xiaomi HBase 02 Quota and Throttling 03 Synchronous Replication
5 . hosted by 01 Xiaomi HBase
6 . hosted by Architecture SDS FDS EMQ OpenTSDB MR Spark HBase Yarn Zookeeper HDFS
7 . hosted by Clusters IDC ● 5 data centers (China), 30+ online clusters / 3 offline clusters AWS / Alibaba Cloud / KS Cloud / Azure ● 16 clusters (China/Singapore/US/Europe/India/Russia)
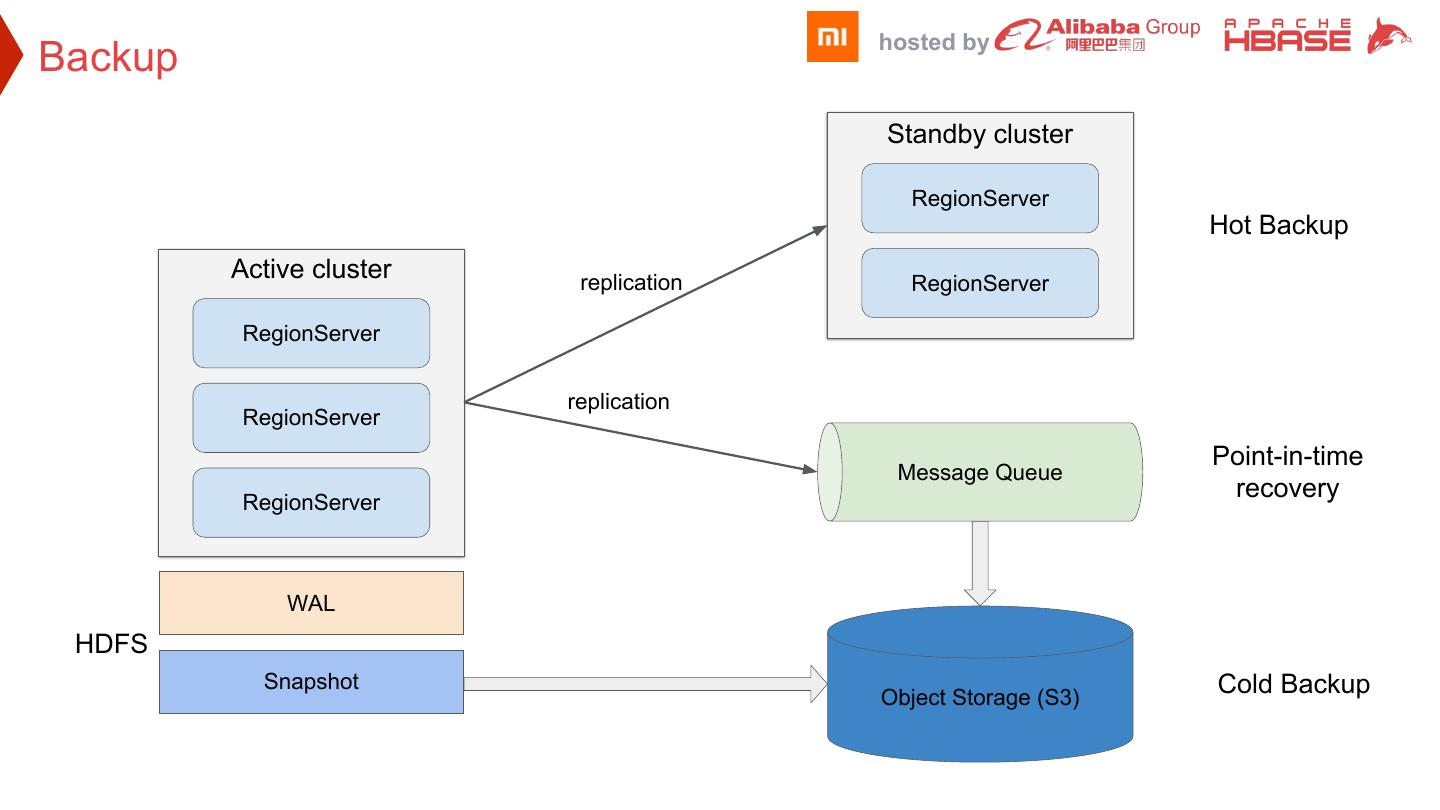
8 . hosted by Backup Standby cluster RegionServer Hot Backup Active cluster replication RegionServer RegionServer replication RegionServer Point-in-time Message Queue RegionServer recovery WAL HDFS Snapshot Cold Backup Object Storage (S3)
9 . hosted by Multi-tenancy Physical isolation ● Independent HDFS cluster for HBase ● Independent HBase cluster for important business ● Online serving cluster: SSD vs HDD ● Offline processing cluster Quota and throttling
10 . hosted by 02 Quota and throttling
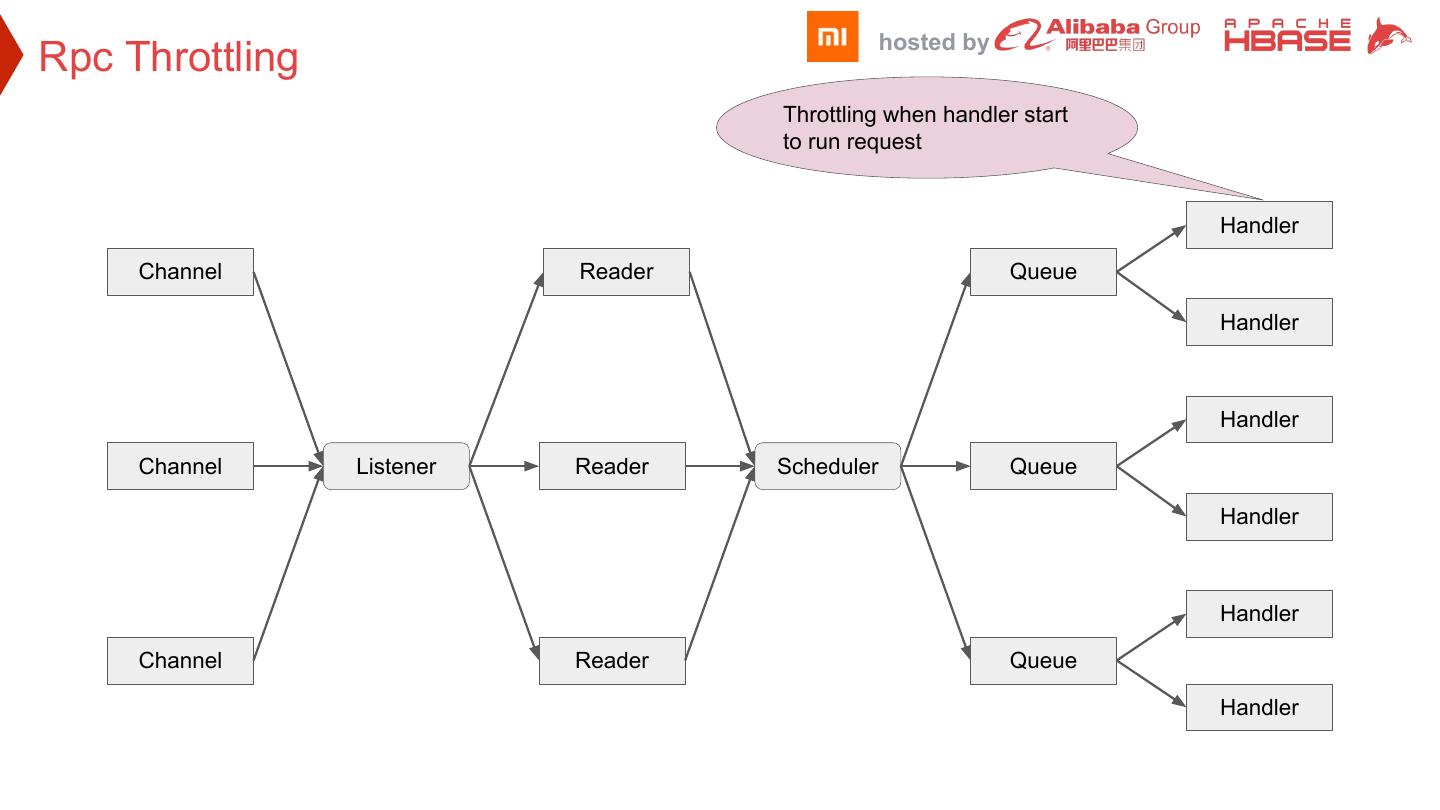
11 . hosted by Rpc Throttling Throttling when handler start to run request Handler Channel Reader Queue Handler Handler Channel Listener Reader Scheduler Queue Handler Handler Channel Reader Queue Handler
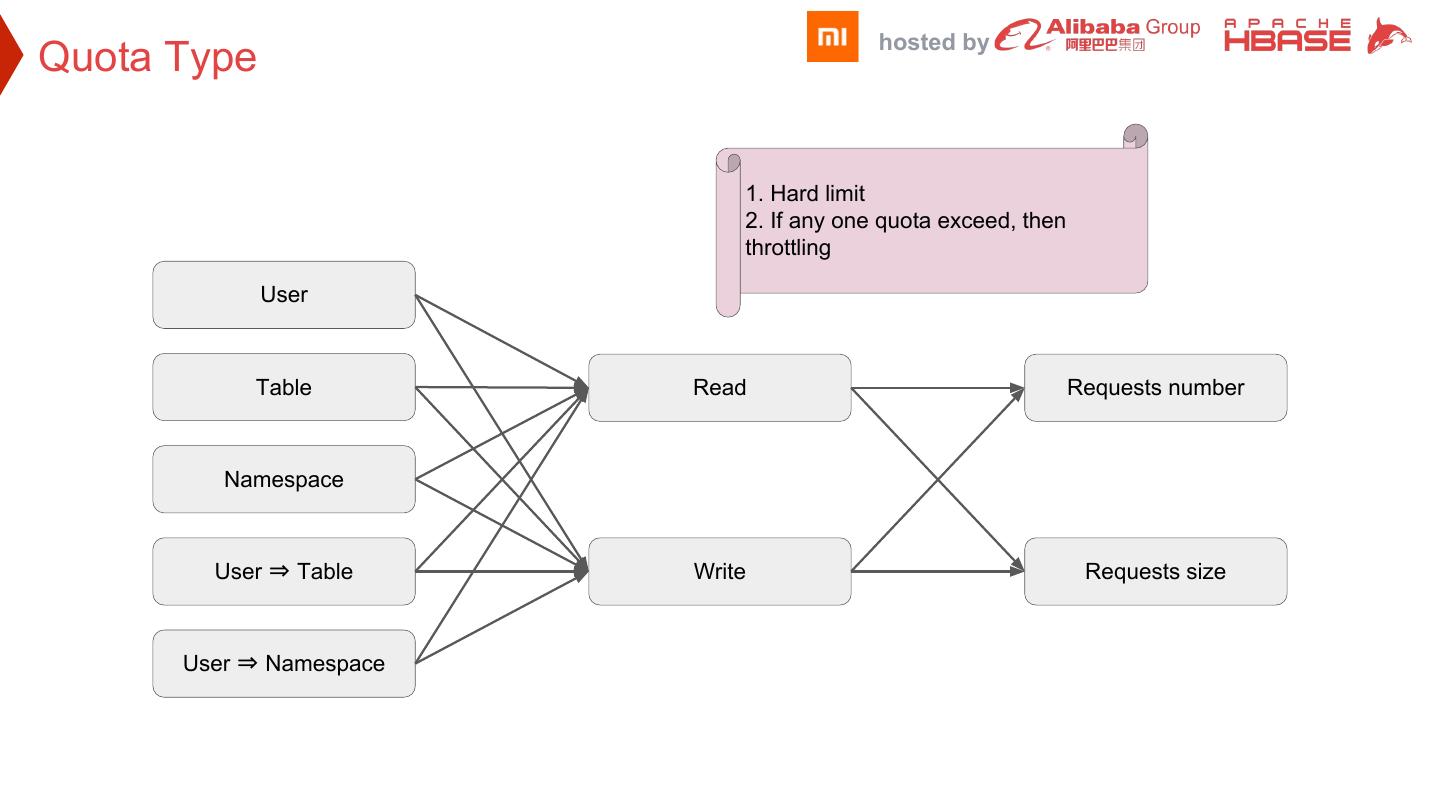
12 . hosted by Quota Type 1. Hard limit 2. If any one quota exceed, then throttling User Table Read Requests number Namespace User ⇒ Table Write Requests size User ⇒ Namespace
13 . hosted by More Quota Types at Xiaomi RegionServer Quota: hard limit Request Unit: calculate both number and size ● Read capacity unit: 1KB/sec ● Write capacity unit: 1KB/sec Soft limit: allow to exceed user’s quota when regionserver quota not exceed
14 . hosted by Other Improvements Switch to start/stop throttling Metrics and UI support Handle ThrottlingException in client ● DoNotRetryNowException ● Avoid MR/Spark job failed by throttling Punishment mechanism for huge requests
15 . hosted by 03 Synchronous Replication
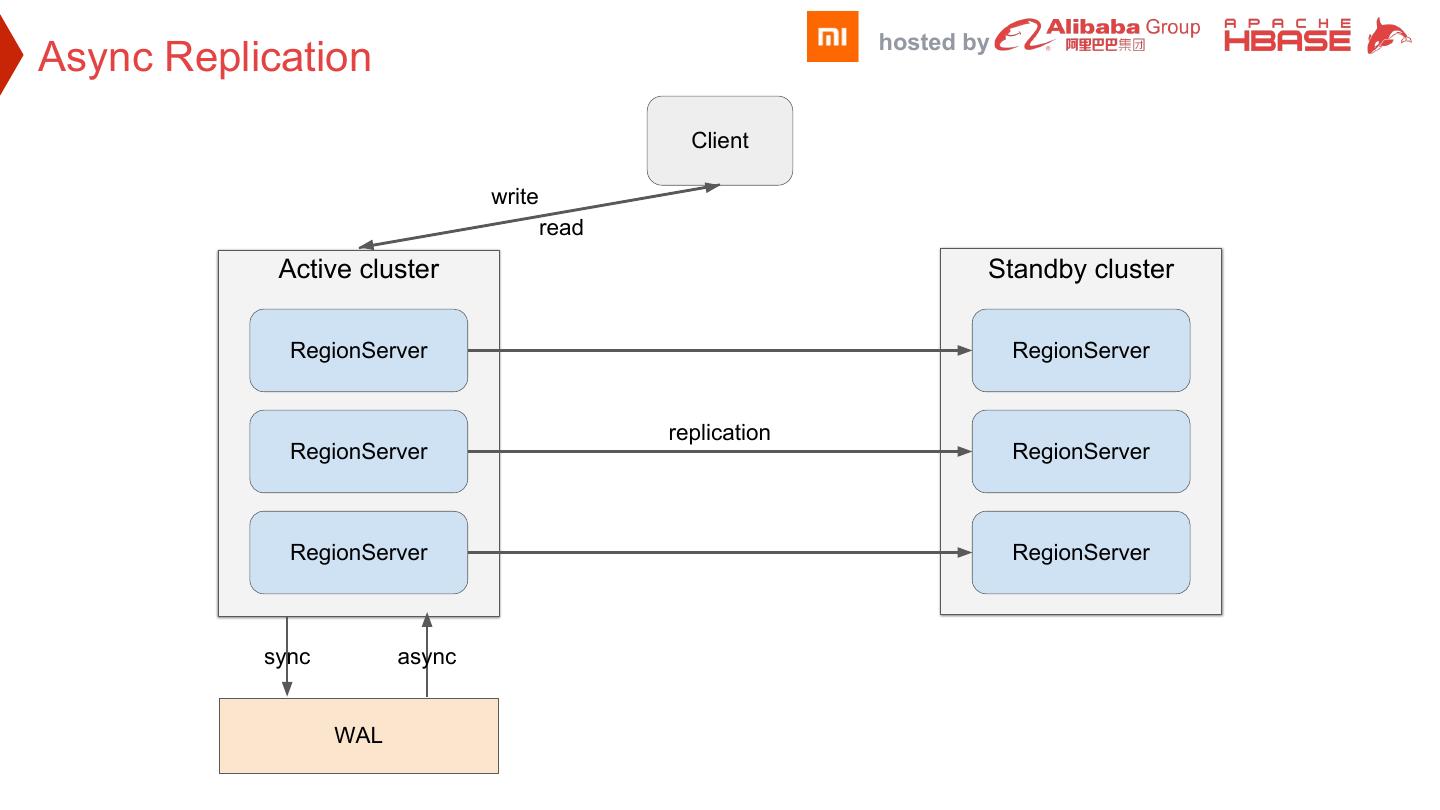
16 . hosted by Async Replication Client write read Active cluster Standby cluster RegionServer RegionServer replication RegionServer RegionServer RegionServer RegionServer sync async WAL
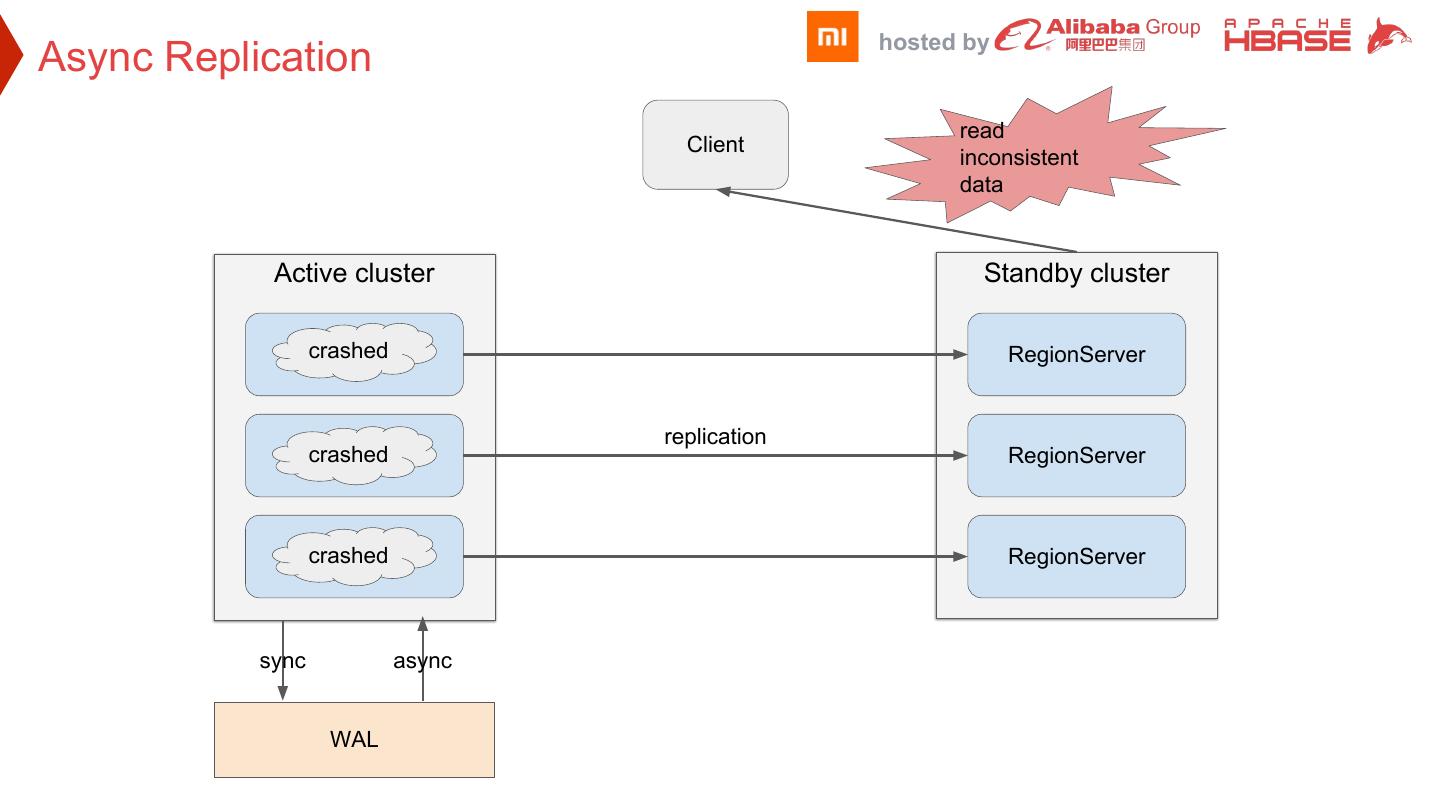
17 . hosted by Async Replication read Client inconsistent data Active cluster Standby cluster crashed RegionServer RegionServer replication crashed RegionServer RegionServer crashed RegionServer RegionServer sync async WAL
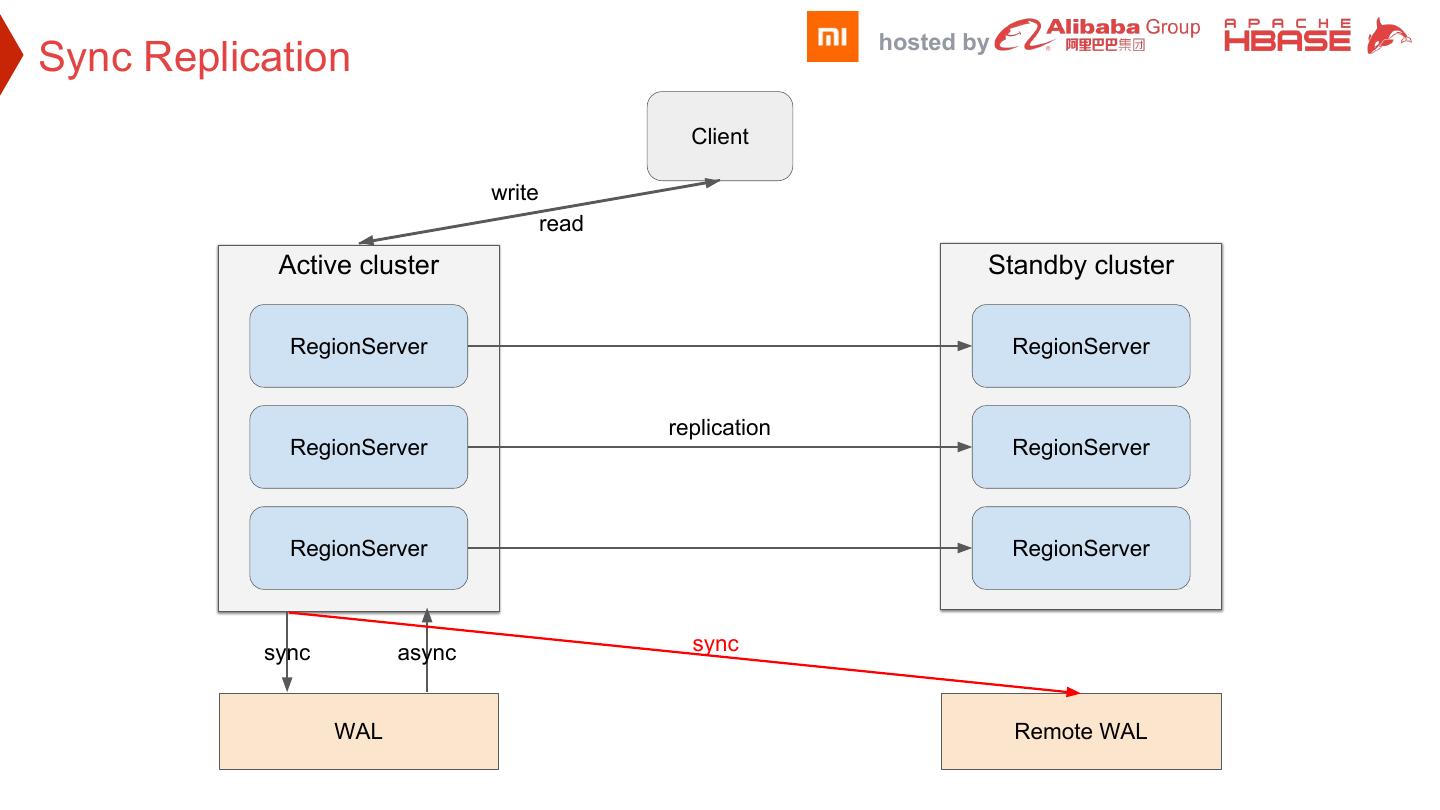
18 . hosted by Sync Replication Client write read Active cluster Standby cluster RegionServer RegionServer replication RegionServer RegionServer RegionServer RegionServer sync async sync WAL Remote WAL
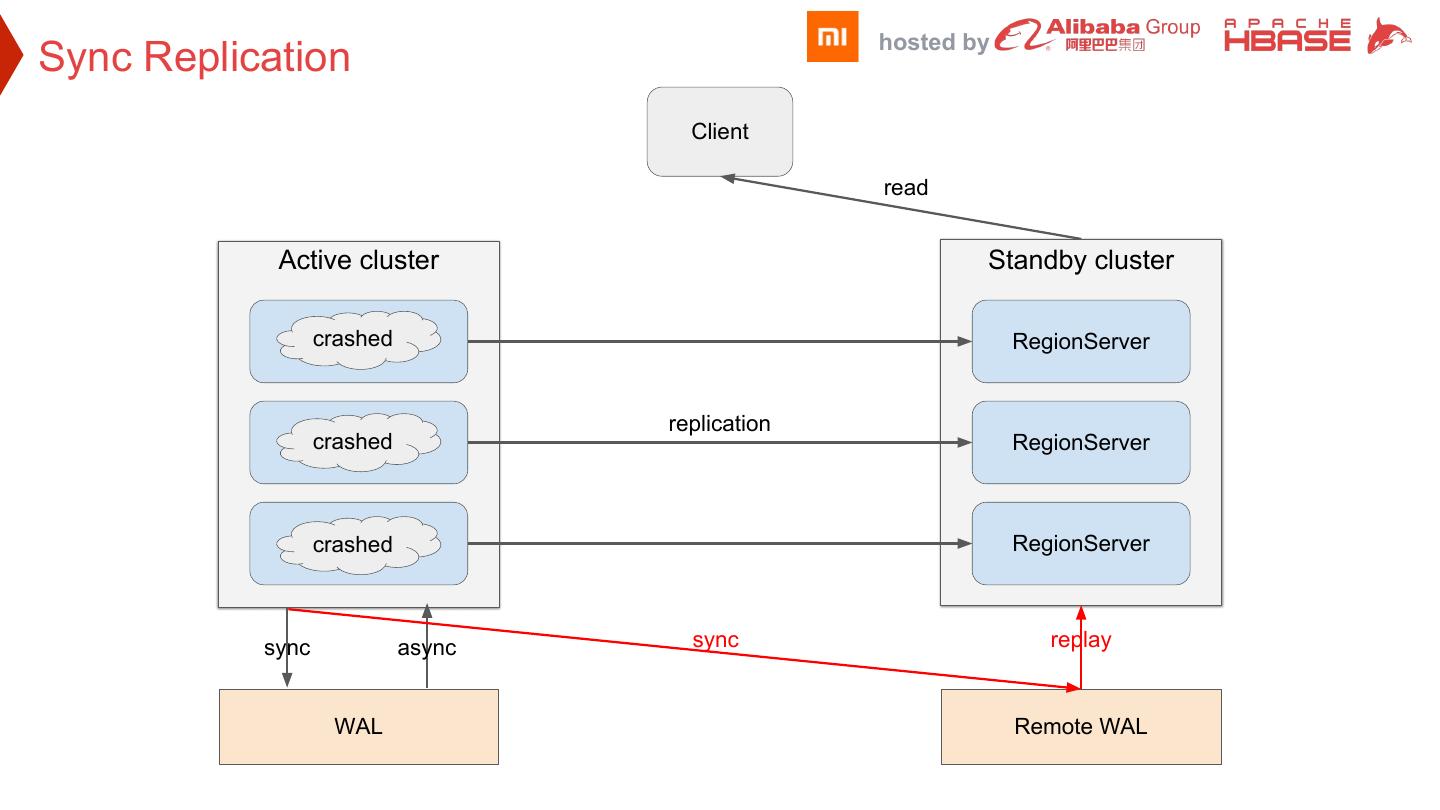
19 . hosted by Sync Replication Client read Active cluster Standby cluster crashed RegionServer RegionServer replication crashed RegionServer RegionServer RegionServer crashed RegionServer sync async sync replay WAL Remote WAL
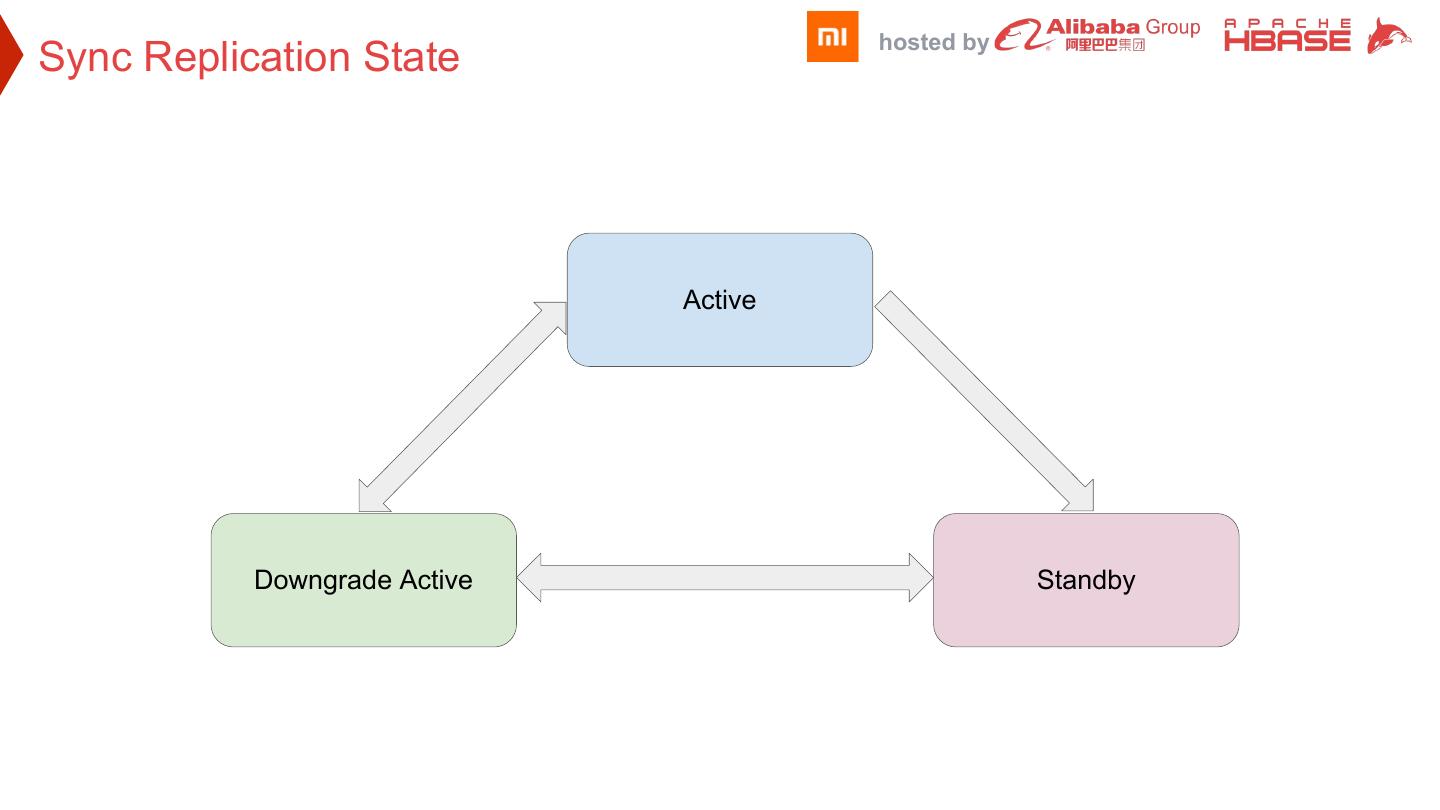
20 . hosted by Sync Replication State Active Downgrade Active Standby
21 . hosted by Setup Sync Replication source cluster peer cluster replication Step 1 Downgrade Active Downgrade Active replication 1. Client read/write active cluster Step 2 Downgrade Active Standby 2. Standby cluster accept async replication request replication Step 3 Active Standby
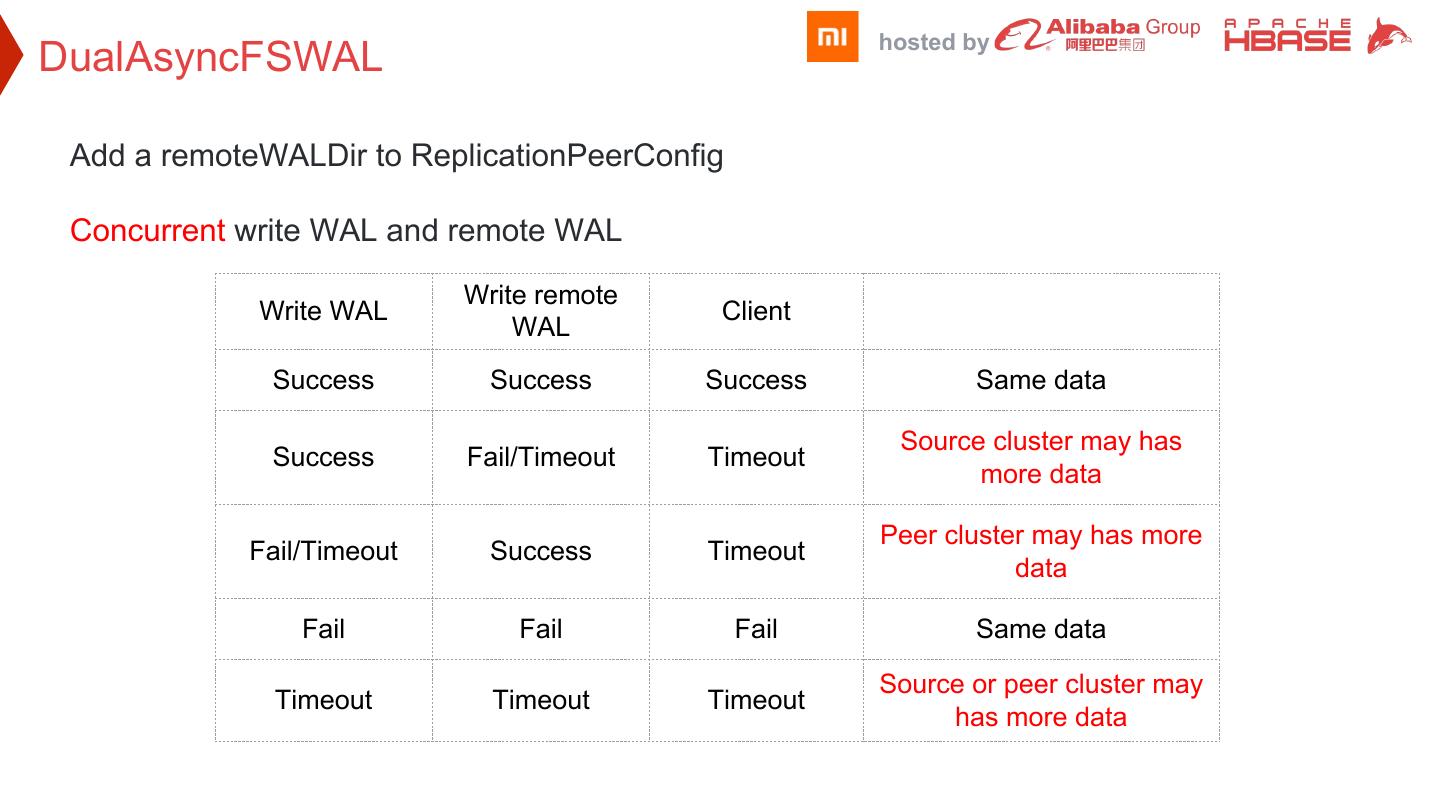
22 . hosted by DualAsyncFSWAL Add a remoteWALDir to ReplicationPeerConfig Concurrent write WAL and remote WAL Write remote Write WAL Client WAL Success Success Success Same data Source cluster may has Success Fail/Timeout Timeout more data Peer cluster may has more Fail/Timeout Success Timeout data Fail Fail Fail Same data Source or peer cluster may Timeout Timeout Timeout has more data
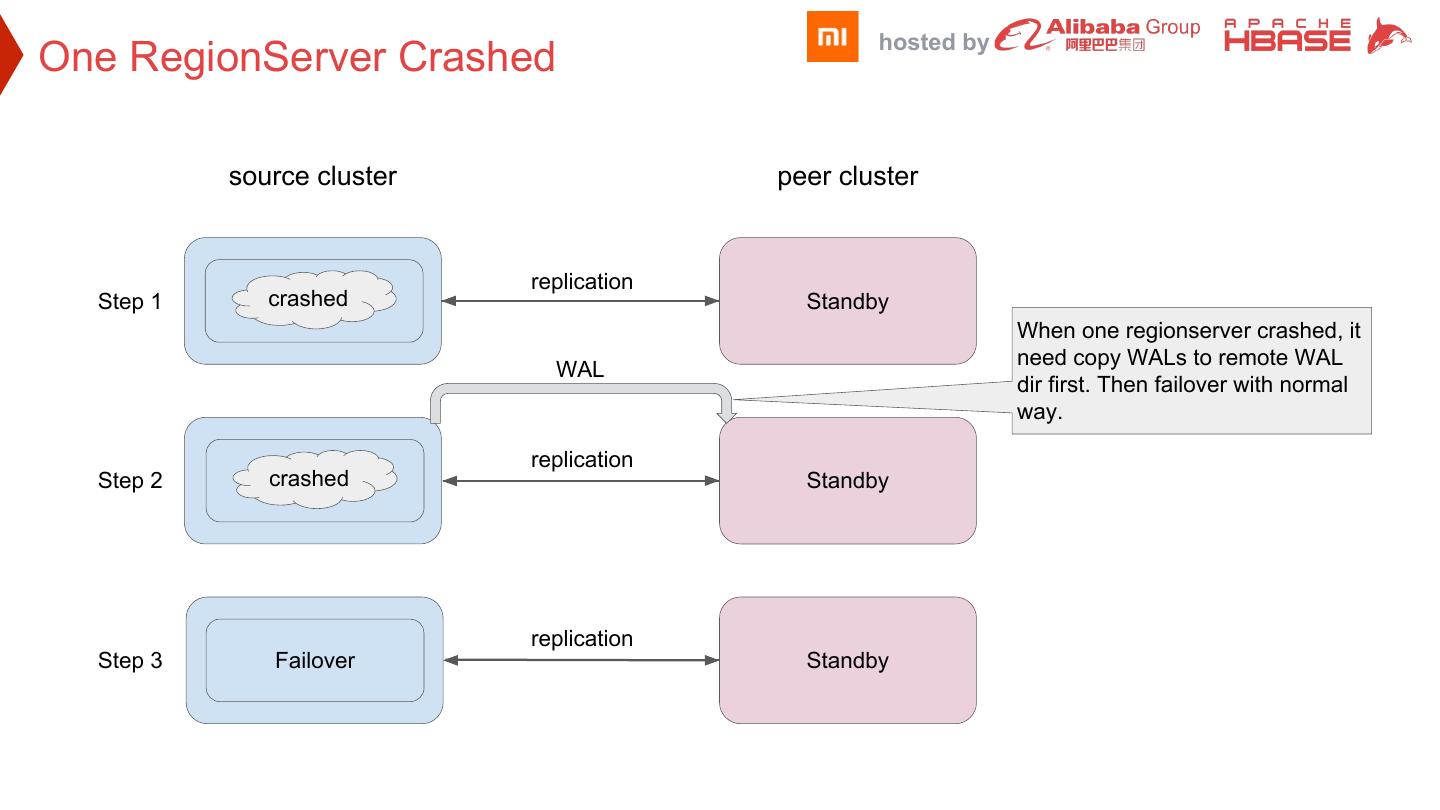
23 . hosted by One RegionServer Crashed source cluster peer cluster replication Step 1 crashed Active RegionServer Standby When one regionserver crashed, it need copy WALs to remote WAL WAL dir first. Then failover with normal way. replication Step 2 crashed Active RegionServer Standby replication Step 3 Failover Active Standby
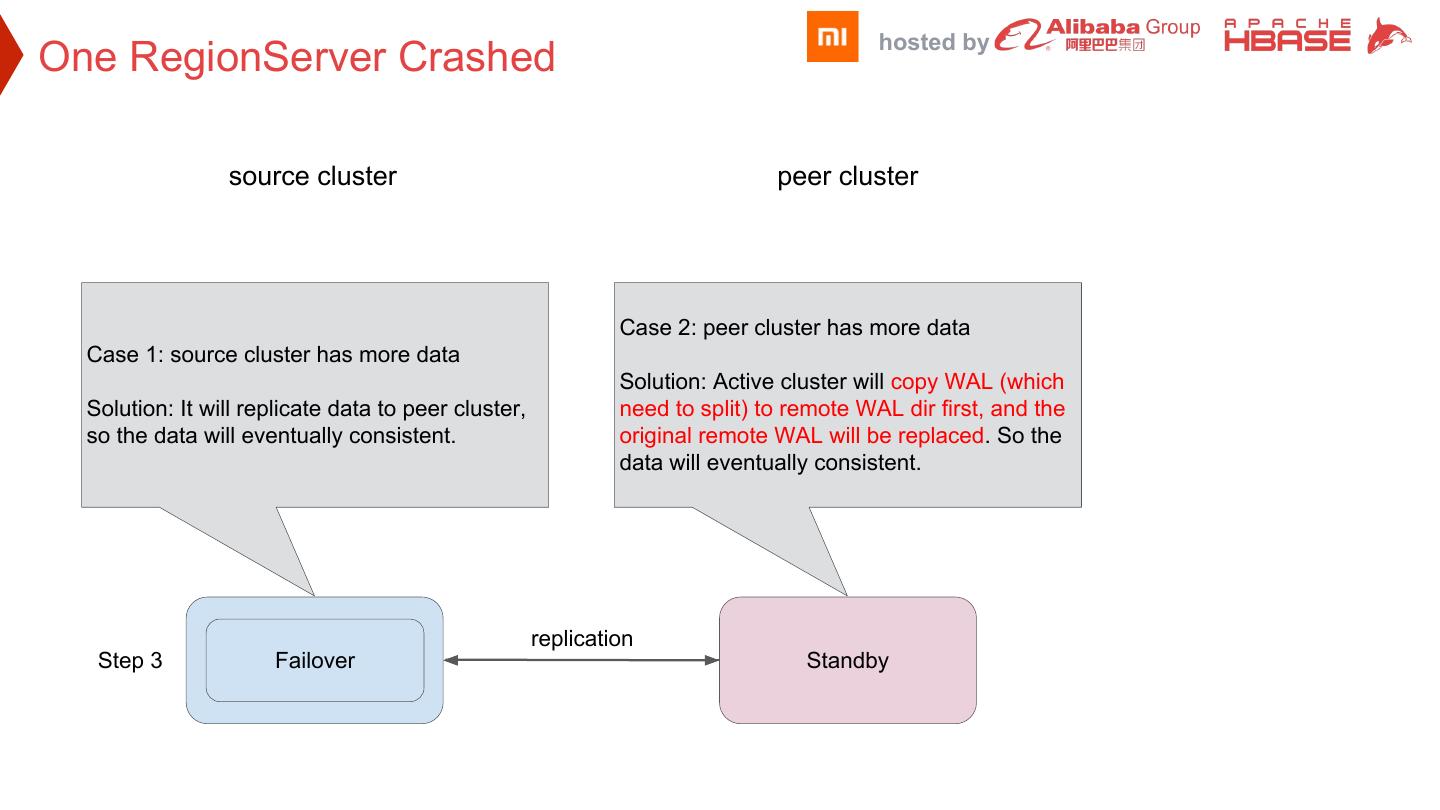
24 . hosted by One RegionServer Crashed source cluster peer cluster Case 2: peer cluster has more data Case 1: source cluster has more data Solution: Active cluster will copy WAL (which Solution: It will replicate data to peer cluster, need to split) to remote WAL dir first, and the so the data will eventually consistent. original remote WAL will be replaced. So the data will eventually consistent. replication Step 3 Failover Active Standby
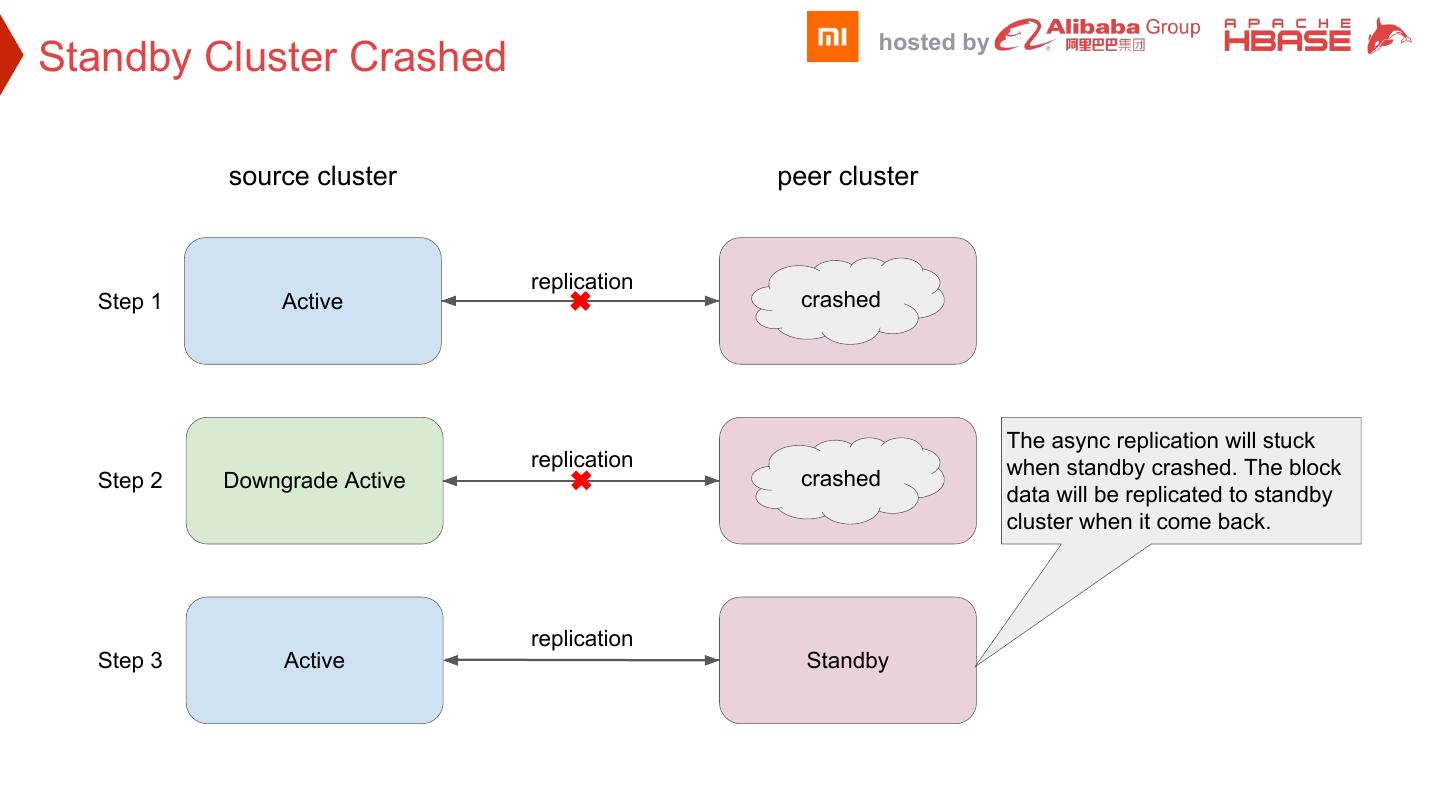
25 . hosted by Standby Cluster Crashed source cluster peer cluster replication Step 1 Active crashed Standby The async replication will stuck replication when standby crashed. The block Step 2 Downgrade Active crashed Standby data will be replicated to standby cluster when it come back. replication Step 3 Active Standby
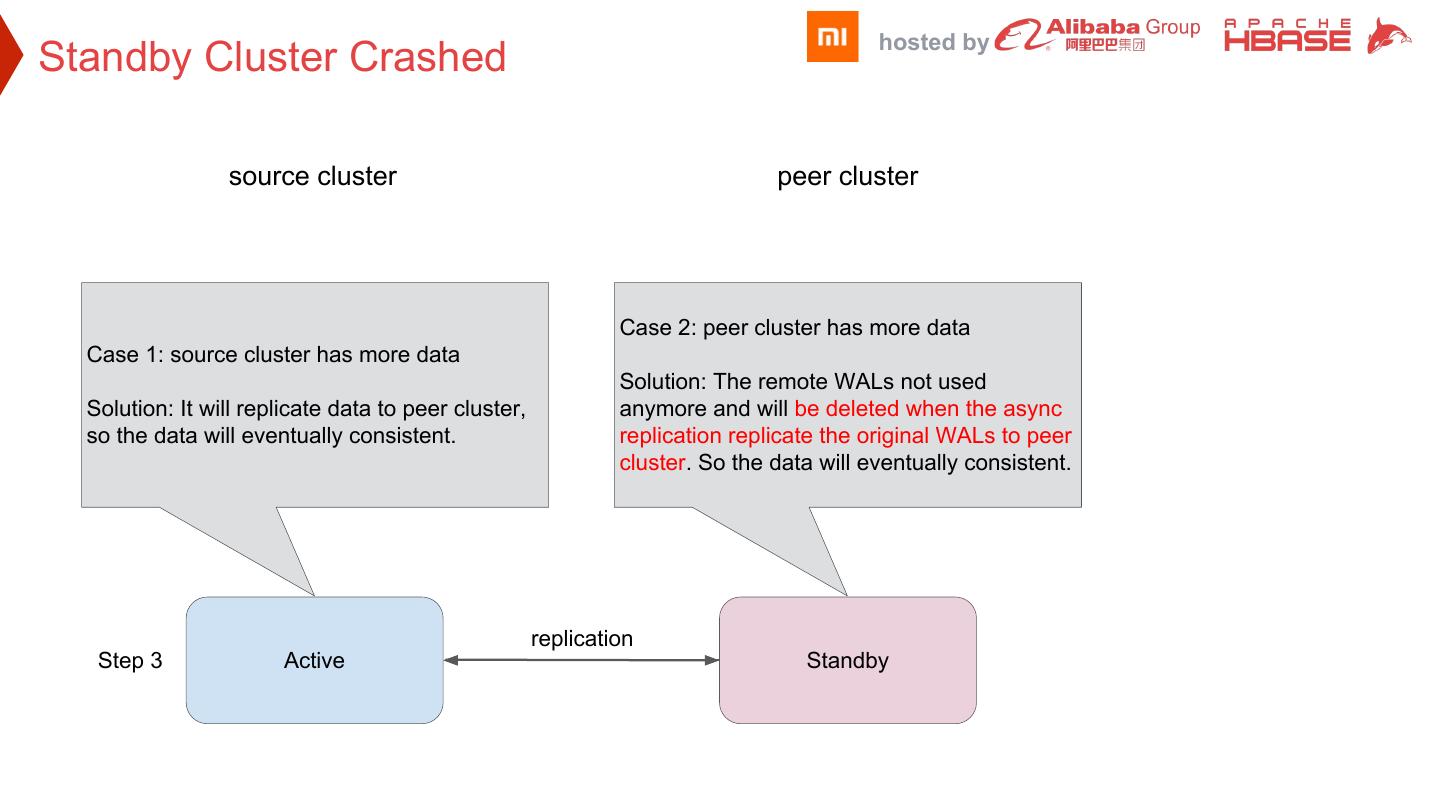
26 . hosted by Standby Cluster Crashed source cluster peer cluster Case 2: peer cluster has more data Case 1: source cluster has more data Solution: The remote WALs not used Solution: It will replicate data to peer cluster, anymore and will be deleted when the async so the data will eventually consistent. replication replicate the original WALs to peer cluster. So the data will eventually consistent. replication Step 3 Active Standby
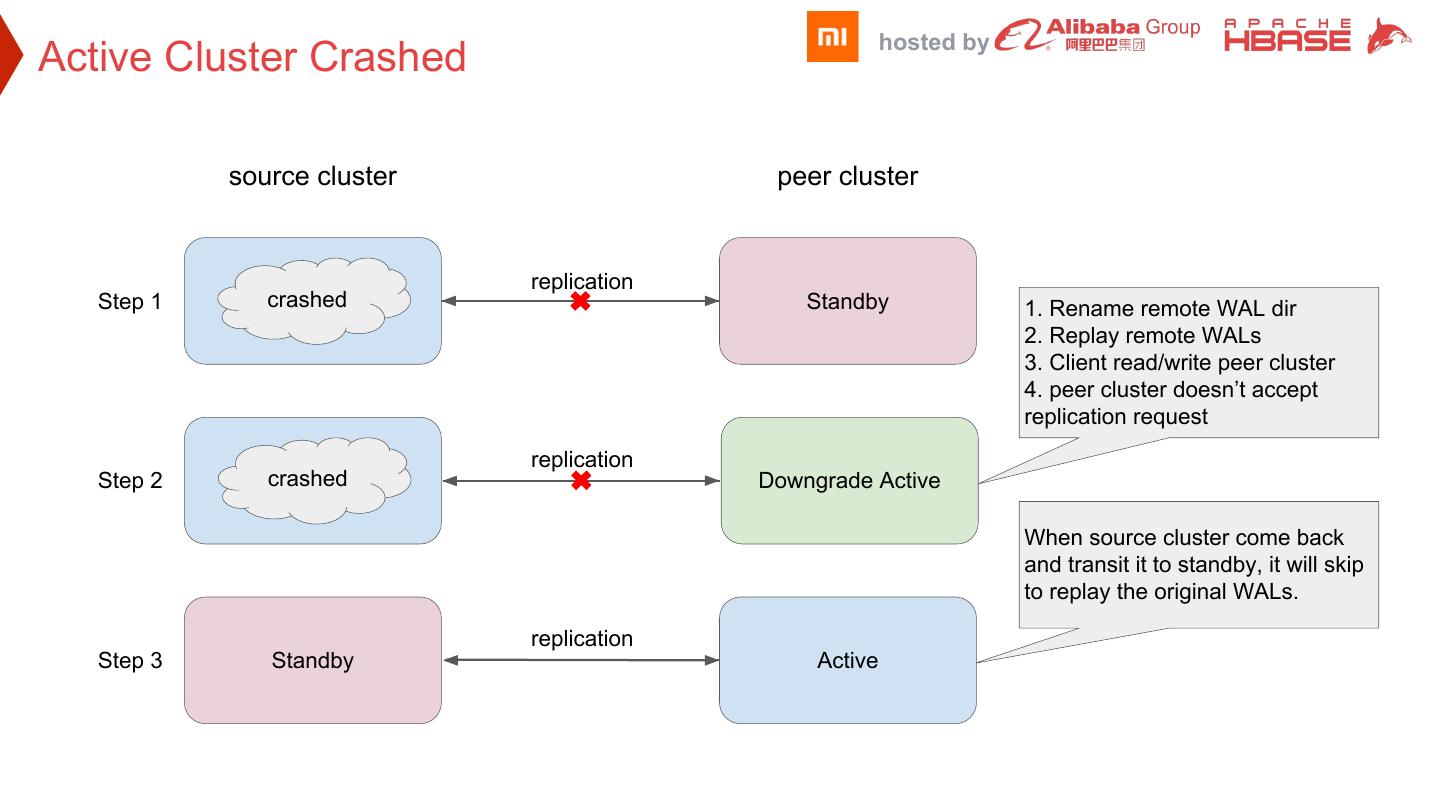
27 . hosted by Active Cluster Crashed source cluster peer cluster replication Step 1 crashed Active Standby 1. Rename remote WAL dir 2. Replay remote WALs 3. Client read/write peer cluster 4. peer cluster doesn’t accept replication request replication Step 2 crashed Active Downgrade Active When source cluster come back and transit it to standby, it will skip to replay the original WALs. replication Step 3 Standby Active
28 . hosted by Active Cluster Crashed source cluster peer cluster Case 1: source cluster has more data Case 2: peer cluster has more data Solution: It will skip to replay the original WALs(which has been replayed in peer Solution: It will replay the remote WALs and cluster) and accept replication request which replicate it to source cluster. So the data will from peer cluster. So the data will eventually eventually consistent. consistent. replication Step 3 Standby Active
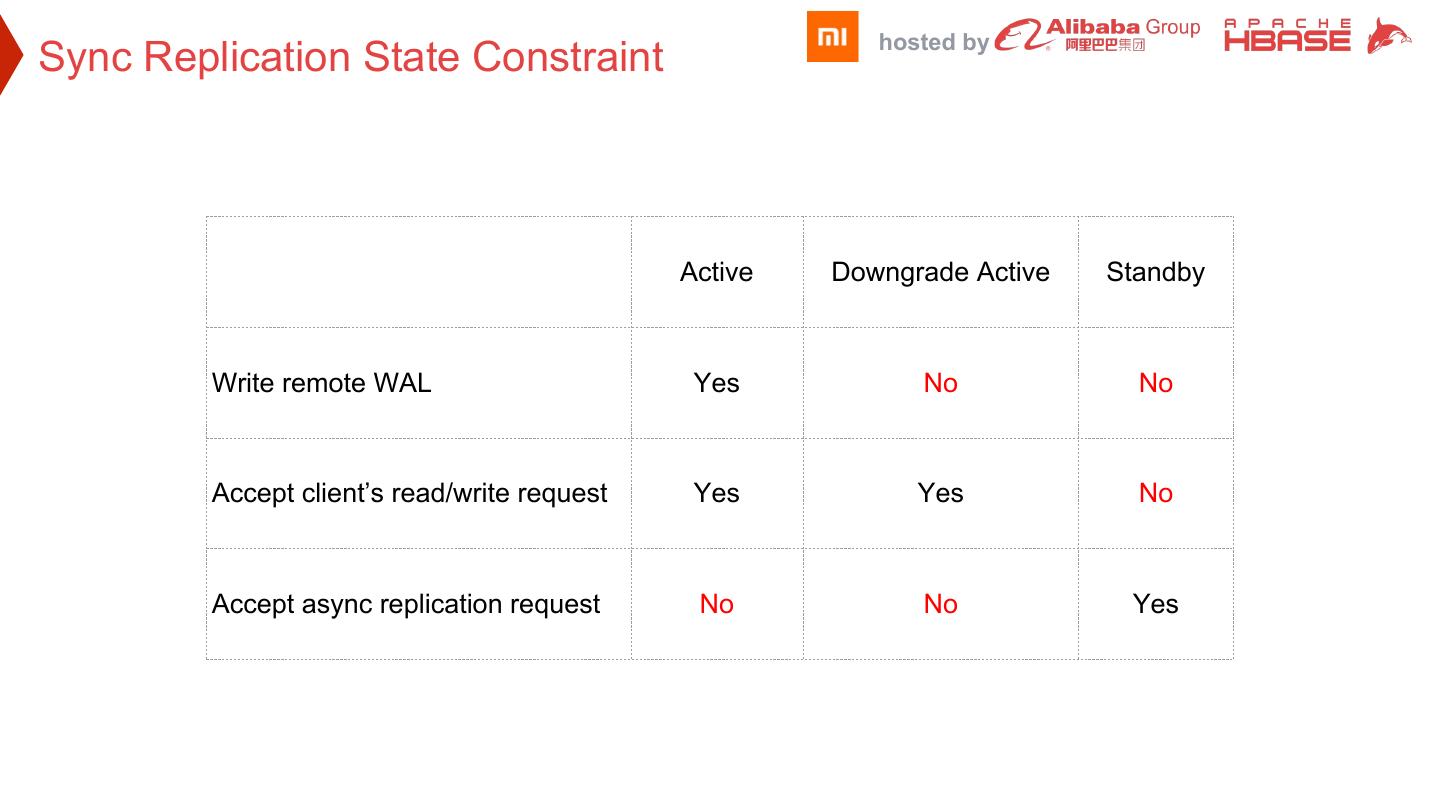
29 . hosted by Sync Replication State Constraint Active Downgrade Active Standby Write remote WAL Yes No No Accept client’s read/write request Yes Yes No Accept async replication request No No Yes
3秒后跳转登录页面
去登陆

