















































































































































































































































































































































































































































































































































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
The.Way.To.Go
The.Way.To.Go
展开查看详情
1 .THE WAY TO GO A Thorough Introduction to the Go Programming Language IVO BALBAERT
2 .The Way to Go
3 .Also by Ivo Balbaert: “Handboek Programmeren met Ruby en Rails.”, 2009, Van Duuren Media, ISBN: 978-90-5940-365-9
4 .The Way to Go A Thorough Introduction to the Go Programming Language Ivo Balbaert iUniverse, Inc. Bloomington
5 .The Way to Go A Thorough Introduction to the Go Programming Language Copyright © 2012 by Ivo Balbaert. All rights reserved. No part of this book may be used or reproduced by any means, graphic, electronic, or mechanical, including photocopying, recording, taping or by any information storage retrieval system without the written permission of the publisher except in the case of brief quotations embodied in critical articles and reviews. iUniverse books may be ordered through booksellers or by contacting: iUniverse 1663 Liberty Drive Bloomington, IN 47403 www.iuniverse.com 1-800-Authors (1-800-288-4677) Because of the dynamic nature of the Internet, any web addresses or links contained in this book may have changed since publication and may no longer be valid. The views expressed in this work are solely those of the author and do not necessarily reflect the views of the publisher, and the publisher hereby disclaims any responsibility for them. Any people depicted in stock imagery provided by Thinkstock are models, and such images are being used for illustrative purposes only. Certain stock imagery © Thinkstock. ISBN: 978-1-4697-6916-5 (sc) ISBN: 978-1-4697-6917-2 (ebk) Printed in the United States of America iUniverse rev. date: 03/05/2012
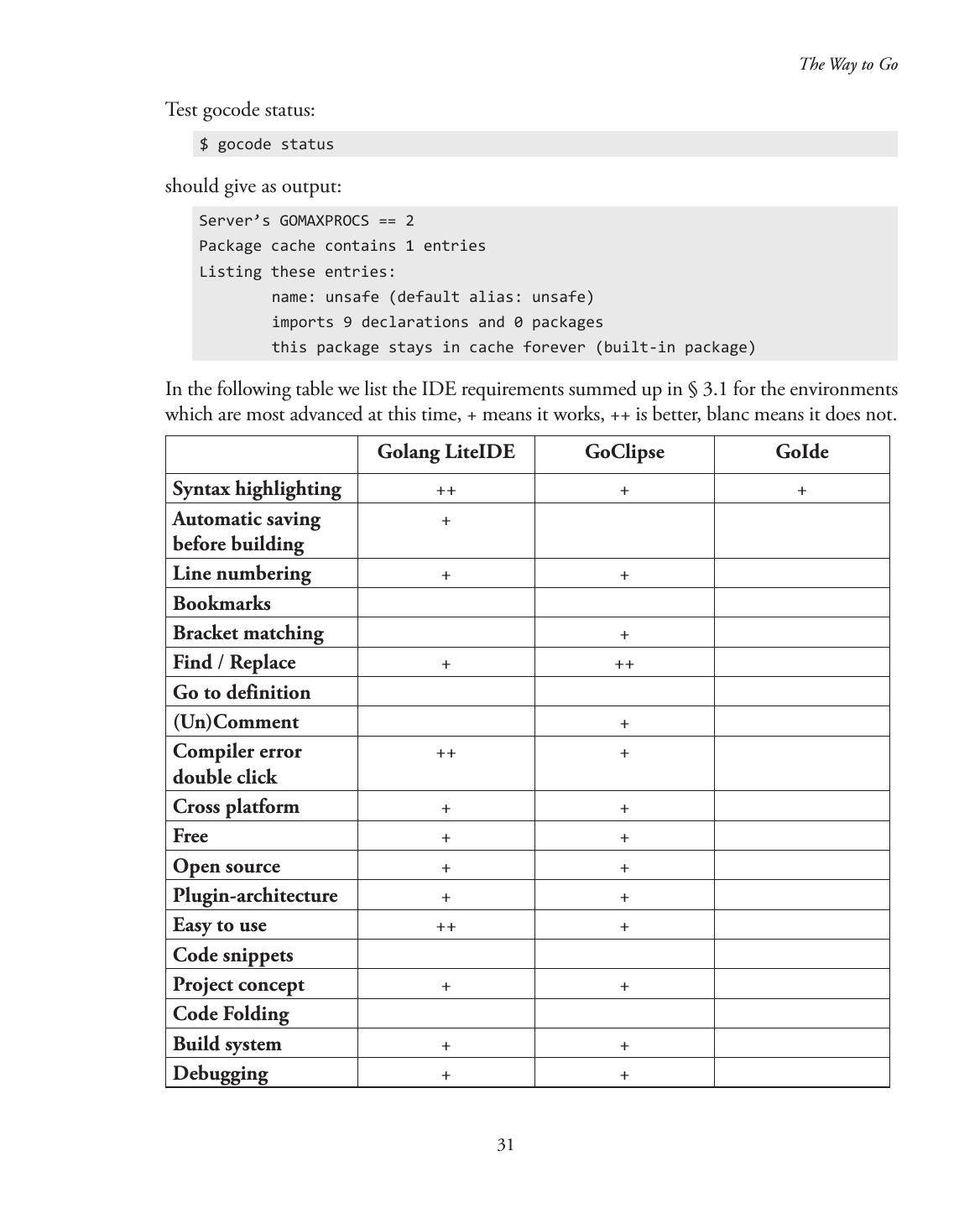
6 . Contents Preface................................................................................................................................. xix PART 1—WHY LEARN GO—GETTING STARTED Chapter 1—Origins, Context and Popularity of Go...............................................................1 1.1 Origins and evolution................................................................................................1 1.2 Main characteristics, context and reasons for developing a new language....................4 1.2.1 Languages that influenced Go.........................................................................4 1.2.2 Why a new language?......................................................................................5 1.2.3 Targets of the language....................................................................................5 1.2.4 Guiding design principles...............................................................................7 1.2.5 Characteristics of the language........................................................................7 1.2.6 Uses of the language........................................................................................8 1.2.7 Missing features?.............................................................................................9 1.2.8 Programming in Go......................................................................................10 1.2.9 Summary......................................................................................................10 Chapter 2—Installation and Runtime Environment............................................................11 2.1 Platforms and architectures.....................................................................................11 (1) The gc Go-compilers:..................................................................................11 (2) The gccgo-compiler:....................................................................................13 (3) File extensions and packages:.......................................................................14 2.2 Go Environment variables........................................................................................14 2.3 Installing Go on a Linux system...............................................................................16 2.4 Installing Go on an OS X system.............................................................................21 2.5 Installing Go on a Windows system.........................................................................21 2.6 What is installed on your machine? .........................................................................26 2.7 The Go runtime.......................................................................................................27 2.8 A Go interpreter . ....................................................................................................27
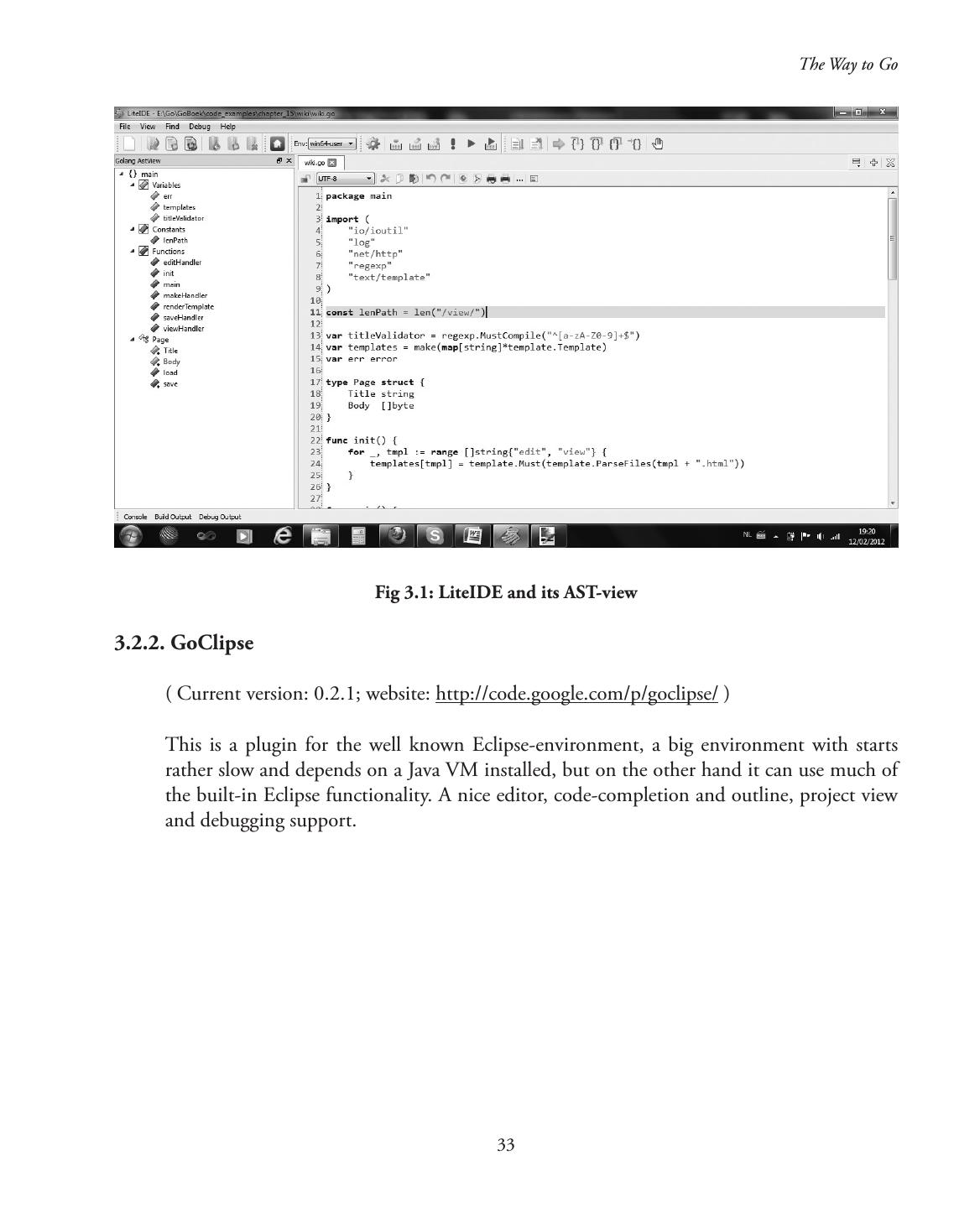
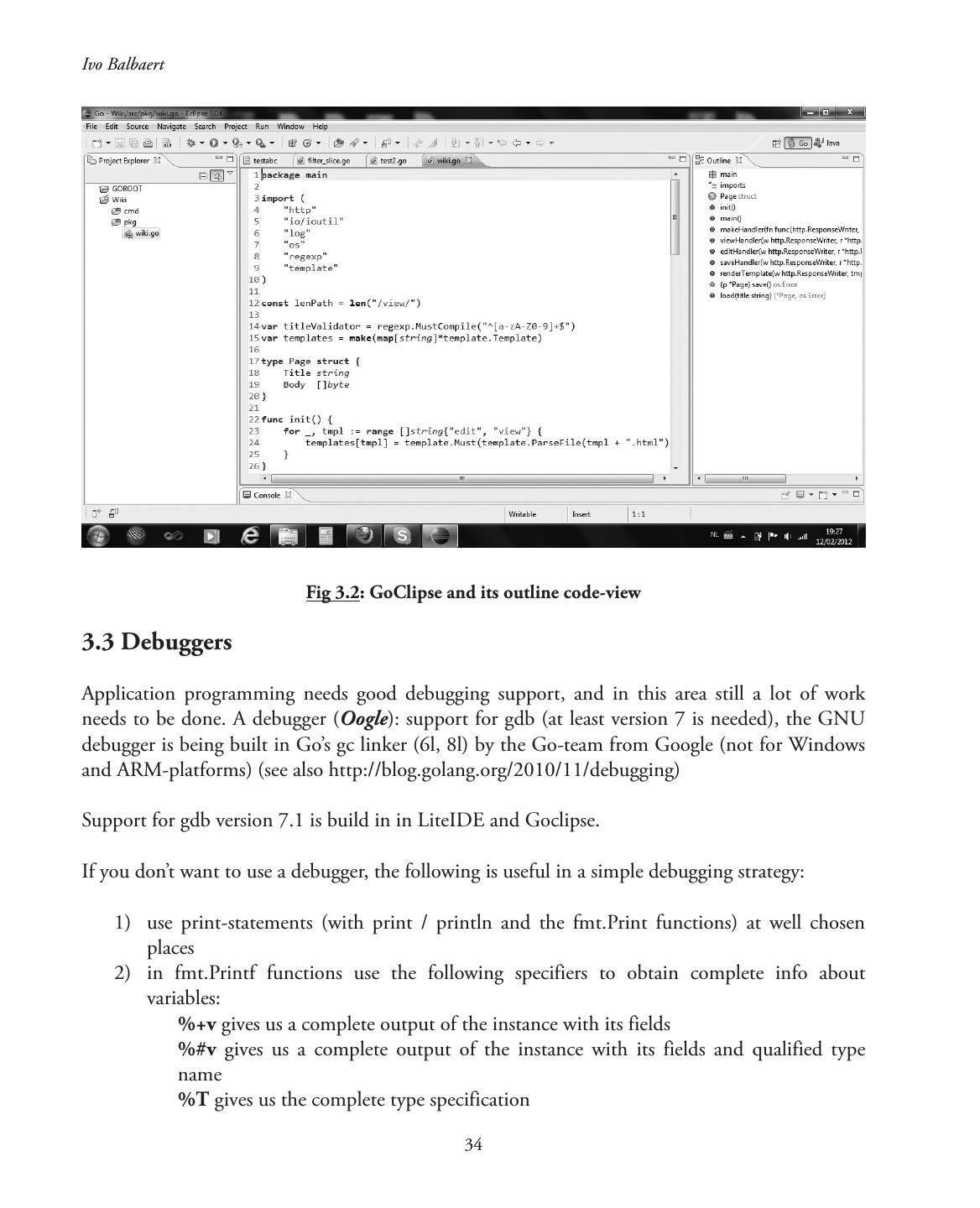
7 .Chapter 3—Editors, IDE’s and Other tools.........................................................................28 3.1 Basic requirements for a decent Go development environment.................................28 3.2 Editors and Integrated Development Environments.................................................29 3.2.1. Golang LiteIDE ..........................................................................................32 3.2.2. GoClipse......................................................................................................33 3.3 Debuggers................................................................................................................34 3.4 Building and running go-programs with command- and Makefiles..........................35 3.5 Formatting code: go fmt or gofmt............................................................................39 3.6 Documenting code: go doc or godoc........................................................................40 3.7 Other tools...............................................................................................................41 3.8 Go’s performance.....................................................................................................41 3.9 Interaction with other languages...............................................................................43 3.9.1. Interacting with C ......................................................................................43 3.9.2. Interacting with C++....................................................................................45 PART 2—CORE CONSTRUCTS AND TECHNIQUES OF THE LANGUAGE Chapter 4—Basic constructs and elementary data types.......................................................49 4.1. Filenames—Keywords—Identifiers..........................................................................49 4.2. Basic structure and components of a Go-program...................................................50 4.2.1 Packages, import and visibility......................................................................51 4.2.3 Comments....................................................................................................56 4.2.4 Types............................................................................................................57 4.2.5 General structure of a Go-program...............................................................58 4.2.6 Conversions..................................................................................................60 4.2.7 About naming things in Go..........................................................................60 4.3. Constants................................................................................................................60 4.4. Variables..................................................................................................................63 4.4.1 Introduction.................................................................................................63 4.4.2 Value types and reference types.....................................................................66 4.4.3 Printing........................................................................................................68 4.4.4 Short form with the := assignment operator..................................................69 4.4.5 Init-functions................................................................................................70 4.5. Elementary types and operators...............................................................................73 4.5.1. Boolean type bool........................................................................................73 4.5.2. Numerical types...........................................................................................75 4.5.2.1 ints and floats.............................................................................................75 4.5.2.2 Complex numbers.....................................................................................79 4.5.2.3 Bit operators..............................................................................................79 4.5.2.4 Logical operators........................................................................................81
8 . 4.5.2.5 Arithmetic operators.................................................................................82 4.5.2.6 Random numbers......................................................................................82 4.5.3. Operators and precedence............................................................................84 4.5.4. Aliasing types...............................................................................................84 4.5.5. Character type.............................................................................................85 4.6. Strings.....................................................................................................................86 4.7. The strings and strconv package..............................................................................88 4.7.1—Prefixes and suffixes:...................................................................................88 4.7.2—Testing whether a string contains a substring:.............................................89 4.7.3—Indicating at which position (index) a substring or character occurs in a string:...................................................................................................89 4.7.4—Replacing a substring:................................................................................90 4.7.5—Counting occurrences of a substring:..........................................................90 4.7.6—Repeating a string:.....................................................................................90 4.7.7—Changing the case of a string:....................................................................91 4.7.8—Trimming a string:.....................................................................................92 4.7.9—Splitting a string:........................................................................................92 4.7.10—Joining over a slice:..................................................................................92 4.7.11—Reading from a string:..............................................................................93 4.8. Times and dates.......................................................................................................95 4.9. Pointers...................................................................................................................96 Chapter 5—Control structures...........................................................................................101 5.1—The if else construct............................................................................................101 5.2—Testing for errors on functions with multiple return values..................................106 5.3—The switch keyword............................................................................................110 5.4—The for construct................................................................................................114 5.4.1 Counter-controlled iteration.......................................................................114 Character on position 2 is:...........................................................................................116 5.4.2 Condition-controlled iteration . .................................................................117 5.4.3 Infinite loops .............................................................................................118 5.4.4 The for range construct...............................................................................119 5.5—Break / continue..................................................................................................121 5.6—Use of labels with break and continue—goto.......................................................123 Chapter 6—Functions.......................................................................................................126 6.1 Introduction...........................................................................................................126 6.2 Parameters and return values..................................................................................129 6.2.1 Call by value / Call by reference..................................................................129 6.2.2 Named return variables...............................................................................131
9 . 6.2.3 Blank identifier...........................................................................................133 6.2.4 Changing an outside variable......................................................................134 6.3 Passing a variable number of parameters.................................................................135 6.4 Defer and tracing...................................................................................................137 6.5 Built-in functions...................................................................................................142 6.6 Recursive functions................................................................................................143 6.8 Closures (function literals).....................................................................................147 6.9 Applying closures: a function returning another function ......................................150 6.10 Debugging with closures......................................................................................153 6.11 Timing a function ...............................................................................................154 6.12 Using memoization for performance....................................................................154 Chapter 7—Arrays and Slices.............................................................................................157 7.1 Declaration and initialization.................................................................................157 7.1.1 Concept......................................................................................................157 7.1.2 Array literals................................................................................................161 7.1.3 Multidimensional arrays..............................................................................162 7.1.4 Passing an array to a function......................................................................163 7.2 Slices......................................................................................................................164 7.2.1 Concept......................................................................................................164 7.2.2 Passing a slice to a function.........................................................................168 7.2.3 Creating a slice with make()........................................................................168 7.2.4 Difference between new() and make().........................................................170 7.2.5 Multidimensional slices...............................................................................171 7.2.6 The bytes package.......................................................................................171 7.3 For range construct................................................................................................172 7.4 Reslicing.................................................................................................................175 7.5 Copying and appending slices................................................................................176 7.6 Applying strings, arrays and slices...........................................................................178 7.6.1 Making a slice of bytes from a string...........................................................178 7.6.2 Making a substring of a string.....................................................................179 7.6.3 Memory representation of a string and a slice..............................................179 7.6.4 Changing a character in a string..................................................................180 7.6.5 Comparison function for byte arrays...........................................................180 7.6.6 Searching and sorting slices and arrays.......................................................181 7.6.7 Simulating operations with append.............................................................182 7.6.8 Slices and garbage collection.......................................................................182
10 .Chapter 8—Maps..............................................................................................................185 8.1 Declaration, initialization and make.......................................................................185 8.1.1 Concept......................................................................................................185 8.1.2 Map capacity..............................................................................................188 8.1.3 Slices as map values.....................................................................................188 8.2 Testing if a key-value item exists in a map—Deleting an element...........................188 8.3 The for range construct..........................................................................................190 8.4 A slice of maps......................................................................................................191 8.5 Sorting a map.........................................................................................................192 8.6 Inverting a map......................................................................................................194 Chapter 9—Packages.........................................................................................................196 A The standard library..................................................................................................196 9.1 Overview of the standard library.............................................................................196 9.2 The regexp package................................................................................................199 9.3 Locking and the sync package................................................................................200 9.4 Accurate computations and the big package...........................................................202 B Custom and external packages: use, build, test, document, install.............................203 9.5 Custom packages and visibility...............................................................................203 9.6 Using godoc for your custom packages...................................................................208 9.7 Using go install for installing custom packages.......................................................210 9.8 Custom packages: map structure, go install and go test..........................................212 9.8.1 Map-structure for custom packages.............................................................212 9.8.2 Locally installing the package......................................................................215 9.8.3 OS dependent code.....................................................................................216 9.9 Using git for distribution and installation...............................................................216 9.9.1 Installing to github.....................................................................................216 9.9.2 Installing from github.................................................................................217 9.10 Go external packages and projects. ......................................................................218 9.11 Using an external library in a Go program............................................................219 Chapter 10—Structs and Methods.....................................................................................224 10.1 Definition of a struct............................................................................................224 10.2 Creating a struct variable with a Factory method..................................................232 10.2.1 A factory for structs..................................................................................232 10.2.2 new() and make() revisited for maps and structs:.......................................234 10.3 Custom package using structs...............................................................................235 10.4 Structs with tags...................................................................................................236 10.5 Anonymous fields and embedded structs..............................................................237 10.5.1 Definition.................................................................................................237
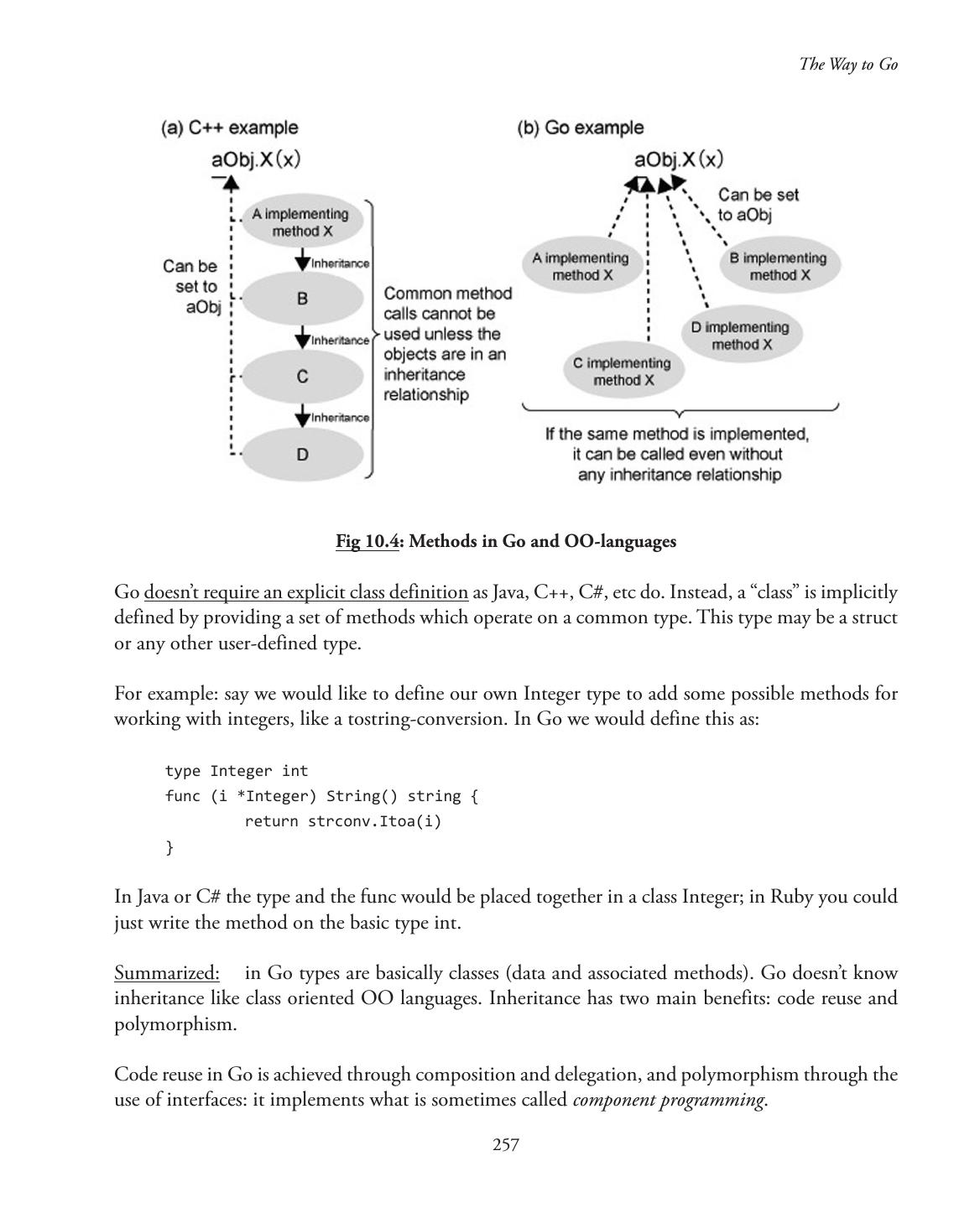
11 . 10.5.2 Embedded structs.....................................................................................238 10.5.3 Conflicting names.....................................................................................239 10.6 Methods...............................................................................................................240 10.6.1 What is a method?....................................................................................240 10.6.2 Difference between a function and a method............................................244 10.6.3 Pointer or value as receiver........................................................................245 10.6.4 Methods and not-exported fields..............................................................247 10.6.5 Methods on embedded types and inheritance............................................248 10.6.6 How to embed functionality in a type.......................................................251 10.6.7 Multiple inheritance..................................................................................253 10.6.8 Universal methods and method naming....................................................256 10.6.9 Comparison between Go types and methods and other object-oriented languages...........................................................................256 10.7 The String()-method and format specifiers for a type...........................................258 10.8 Garbage collection and SetFinalizer......................................................................261 Chapter 11—Interfaces and reflection................................................................................263 11.1 What is an interface?............................................................................................263 11.2 Interface embedding interface(s)...........................................................................270 11.3 How to detect and convert the type of an interface variable: type assertions.........270 11.4 The type switch....................................................................................................273 11.5 Testing if a value implements an interface.............................................................274 11.6 Using method sets with interfaces.........................................................................275 11.7 1st example: sorting with the Sorter interface........................................................277 11.8 2nd example: Reading and Writing......................................................................282 11.9 Empty Interface...................................................................................................284 11.9.1 Concept....................................................................................................284 11.9.2 Constructing an array of a general type or with variables of different types............................................................................................286 11.9.3 Copying a data-slice in a slice of interface{}...............................................287 11.9.4 Node structures of general or different types.............................................288 11.9.5 Interface to interface.................................................................................289 11.10 The reflect package.............................................................................................290 11.10.1 Methods and types in reflect...................................................................290 11.10.2 Modifying (setting) a value through reflection........................................293 11.10.3 Reflection on structs...............................................................................294 11.11 Printf and reflection...........................................................................................296 11.12 Interfaces and dynamic typing............................................................................298 11.12.1 Dynamic typing in Go............................................................................298 11.12.2 Dynamic method invocation...................................................................300
12 . 11.12.3 Extraction of an interface........................................................................301 11.12.4 Explicitly indicating that a type implements an interface........................303 11.12.5 Empty interface and function overloading..............................................304 11.12.6 Inheritance of interfaces..........................................................................304 11.13 Summary: the object-orientedness of Go............................................................306 11.14 Structs, collections and higher order functions...................................................306 PART 3—ADVANCED GO Chapter 12—Reading and writing.....................................................................................313 12.1 Reading input from the user.................................................................................313 12.2 Reading from and writing to a file........................................................................317 12.2.1 Reading from a file....................................................................................317 12.2.2 The package compress: reading from a zipped file.....................................321 12.2.3 Writing to a file.........................................................................................322 12.3 Copying files........................................................................................................324 12.4 Reading arguments from the command-line.........................................................325 12.4.1 With the os-package..................................................................................325 12.4.2 With the flag-package...............................................................................326 12.5 Reading files with a buffer....................................................................................328 12.6 Reading and writing files with slices.....................................................................330 12.7 Using defer to close a file.....................................................................................332 12.8 A practical example of the use of interfaces: fmt.Fprintf......................................332 12.9 The json dataformat.............................................................................................334 12.10 The xml dataformat............................................................................................340 12.11 Datatransport through gob.................................................................................342 12.12 Cryptography with go........................................................................................345 Chapter 13—Error-handling and Testing...........................................................................348 13.1 Error-handling.....................................................................................................349 13.1.1 Defining errors..........................................................................................349 13.1.2 Making an error-object with fmt..............................................................353 13.2 Run-time exceptions and panic............................................................................353 13.4 Error-handling and panicking in a custom package..............................................357 13.5 An error-handling scheme with closures...............................................................360 13.6 Starting an external command or program...........................................................363 13.7 Testing and benchmarking in Go.........................................................................364 13.8 Testing: a concrete example..................................................................................367 13.9 Using table-driven tests........................................................................................369 13.10 Investigating performance: tuning and profiling Go programs............................371
13 . 13.10.1 Time and memory consumption.............................................................371 13.10.2 Tuning with go test.................................................................................371 13.10.3 Tuning with pprof...................................................................................371 Chapter 14—Goroutines and Channels.............................................................................375 14.1 Concurrency, parallelism and goroutines..............................................................375 14.1.1 What are goroutines?................................................................................375 14.1.2 The difference between concurrency and parallelism.................................377 14.1.3 Using GOMAXPROCS............................................................................378 14.1.4 How to specify the number of cores to be used on the command-line?.....379 14.1.5 Goroutines and coroutines........................................................................381 14.2 Channels for communication between goroutines................................................381 14.2.1 Concept....................................................................................................381 14.2.2 Communication operator <-.....................................................................383 14.2.3 Blocking of channels.................................................................................385 14.2.4 Goroutines synchronize through the exchange of data on one (or more) channel(s)........................................................................................387 14.2.5 Asynchronous channels—making a channel with a buffer.........................387 14.2.6 Goroutine using a channel for outputting result(s)....................................388 14.2.7 Semaphore pattern....................................................................................389 14.2.8 Implementing a parallel for-loop...............................................................391 14.2.9 Implementing a semaphore using a buffered channel................................391 14.2.10 For—range applied to channels...............................................................394 14.2.11 Channel directionality............................................................................396 14.3 Synchronization of goroutines: closing a channel—testing for blocked channels..400 14.4 Switching between goroutines with select.............................................................403 14.5 Channels, Timeouts and Tickers...........................................................................408 14.6 Using recover with goroutines..............................................................................412 14.7 Comparing the old and the new model: Tasks and Worker processes....................413 14.8 Implementing a lazy generator..............................................................................416 14.9 Implementing Futures..........................................................................................420 14.10 Multiplexing......................................................................................................421 14.10.1 A typical client-server pattern..................................................................421 14.10.2 Teardown: shutdown the server by signaling a channel............................424 14.11 Limiting the number of requests processed concurrently....................................427 14.12 Chaining goroutines...........................................................................................428 14.13 Parallelizing a computation over a number of cores............................................429 14.14 Parallelizing a computation over a large amount of data.....................................430 14.15 The leaky bucket algorithm................................................................................431
14 . 14.16 Benchmarking goroutines...................................................................................433 14.17 Concurrent acces to objects by using a channel..................................................434 Chapter 15—Networking, templating and web-applications..............................................436 15.1 A tcp-server .........................................................................................................436 15.2 A simple webserver...............................................................................................445 15.3 Polling websites and reading in a web page...........................................................448 15.4 Writing a simple web application.........................................................................452 15.5 Making a web application robust..........................................................................454 15.6 Writing a web application with templates.............................................................456 15.7 Exploring the template package............................................................................461 15.7.1. Field substitution: {{.FieldName}}............................................................462 15.7.2. Validation of the templates.......................................................................463 15.7.3 If-else........................................................................................................464 15.7.4 Dot and with-end.....................................................................................465 15.7.5 Template variables $..................................................................................466 15.7.6 Range-end.................................................................................................467 15.7.7 Predefined template functions...................................................................467 15.8 An elaborated webserver with different functions.................................................468 (works only on Unix because calls /bin/date)........................................................474 15.9 Remote procedure calls with rpc...........................................................................474 15.10 Channels over a network with netchan...............................................................477 15.11 Communication with websocket........................................................................478 15.12 Sending mails with smtp....................................................................................480 PART 4—APPLYING GO Chapter 16—Common Go Pitfalls or Mistakes..................................................................485 16.1 Hiding (shadowing) a variable by misusing short declaration...............................486 16.2 Misusing strings...................................................................................................486 16.3 Using defer for closing a file in the wrong scope...................................................487 16.4 Confusing new() and make()................................................................................488 16.5 No need to pass a pointer to a slice to a function..................................................488 16.6 Using pointers to interface types...........................................................................488 16.7 Misusing pointers with value types.......................................................................489 16.8 Misusing goroutines and channels........................................................................489 16.9 Using closures with goroutines.............................................................................490 16.10 Bad error handling.............................................................................................491 16.10.1 Don’t use booleans:.................................................................................491 16.10.2 Don’t clutter your code with error-checking:...........................................492
15 .Chapter 17—Go Language Patterns...................................................................................494 17.1 The comma, ok pattern........................................................................................494 17.2 The defer pattern..................................................................................................495 17.3 The visibility pattern............................................................................................497 17.4 The operator pattern and interface.......................................................................497 17.4.1 Implement the operators as functions.......................................................497 17.4.2 Implement the operators as methods.........................................................498 17.4.3 Using an interface.....................................................................................499 Chapter 18—Useful Code Snippets—Performance Advice.................................................500 18.1 Strings..................................................................................................................500 18.2 Arrays and slices...................................................................................................501 18.3 Maps....................................................................................................................502 18.4 Structs..................................................................................................................502 18.5 Interfaces..............................................................................................................503 18.6 Functions.............................................................................................................503 18.7 Files......................................................................................................................504 18.8 Goroutines and channels......................................................................................505 18.9 Networking and web applications.........................................................................507 18.9.1. Templating:......................................................................................................507 18.10 General..............................................................................................................508 18.11 Performance best practices and advice................................................................508 Chapter 19—Building a complete application....................................................................509 19.1 Introduction.........................................................................................................509 19.2 Introducing Project UrlShortener.........................................................................509 19.3 Data structure......................................................................................................510 19.4 Our user interface: a web server frontend.............................................................515 19.5 Persistent storage: gob..........................................................................................519 19.6 Using goroutines for performance........................................................................524 19.7 Using json for storage...........................................................................................527 19.8 Multiprocessing on many machines......................................................................528 19.9 Using a ProxyStore...............................................................................................532 19.10 Summary and enhancements..............................................................................536 Chapter 20—Go in Google App Engine............................................................................538 20.1 What is Google App Engine ?...............................................................................538 20.2 Go in the cloud ...................................................................................................540 20.3 Installation of the Go App Engine SDK: the development environment for Go...540
16 . 20.3.1. Installation...............................................................................................540 20.3.2. Checking and testing...............................................................................542 20.4 Building your own Hello world app ....................................................................543 20.4.1 Map structure—Creating a simple http-handler........................................543 20.4.2 Creating the configuration file app.yaml...................................................544 20.4.3 Iterative development................................................................................548 20.4.4. Integrating with the GoClipse IDE..........................................................548 20.5 Using the Users service and exploring its API.......................................................549 20.6 Handling forms....................................................................................................551 20.7 Using the datastore...............................................................................................552 20.8 Uploading to the cloud.......................................................................................556 Chapter 21—Real World Uses of Go.................................................................................559 21.1 Heroku—a highly available consistent data store in Go. ......................................559 21.2 MROffice—a VOIP system for call centers in Go................................................561 21.3 Atlassian—a virtual machine cluster management system.....................................562 21.4 Camlistore—a content addressable storage system................................................563 21.5 Other usages of the Go language..........................................................................563 APPENDICES...................................................................................................................567 (A) CODE REFERENCE...........................................................................................567 (B)CUTE GO QUOTES.............................................................................................571 GO QUOTES: TRUE BUT NOT SO CUTE....................................................572 (C) LIST OF CODE EXAMPLES (Listings)...............................................................572 (E) References in the text to Go—packages..................................................................583 (F) References in the text to Go—tools........................................................................586 (G) Answers to Questions............................................................................................586 (H) ANSWERS TO EXERCISES................................................................................590 (I) BIBLIOGRAPHY (Resources and References)........................................................593 Index..............................................................................................................................597
17 .
18 . List of Illustrations Chapter 1—Origins, Context and Popularity of Go...............................................................1 Fig 1.1: The designers of Go: Griesemer, Thompson and Pike..........................................1 Fig 1.2: The logo’s of Go..................................................................................................3 Fig 1.3: Influences on Go.................................................................................................5 Chapter 3—Editors, IDE’s and Other tools.........................................................................28 Fig 3.1: LiteIDE and its AST-view..................................................................................33 Fig 3.2: GoClipse and its outline code-view...................................................................34 Chapter 4—Basic constructs and elementary data types.......................................................49 Fig 4.1: Value type..........................................................................................................67 Fig 4.2: Assignment of value types..................................................................................67 Fig 4.3: Reference types and assignment.........................................................................67 Fig 4.4: Pointers and memory usage...............................................................................98 Fig 4.5: Pointers and memory usage, 2...........................................................................99 Chapter 7—Arrays and Slices.............................................................................................157 Fig 7.1: Array in memory.............................................................................................158 Fig 7.2: Slice in memory..............................................................................................166 Chapter 9—Packages.........................................................................................................196 Fig 9.1: Package documentation with godoc.................................................................210 Chapter 10—Structs and Methods.....................................................................................224 Fig 10.1: Memory layout of a struct.............................................................................227 Fig 10.2: Memory layout of a struct of structs..............................................................229 Fig. 10.3: Linked list as recursive struct........................................................................230 Fig 10.4: Binary tree as recursive struct.........................................................................230 Chapter 11—Interfaces and reflection................................................................................263 Fig 11.1: Interface value in memory.............................................................................264
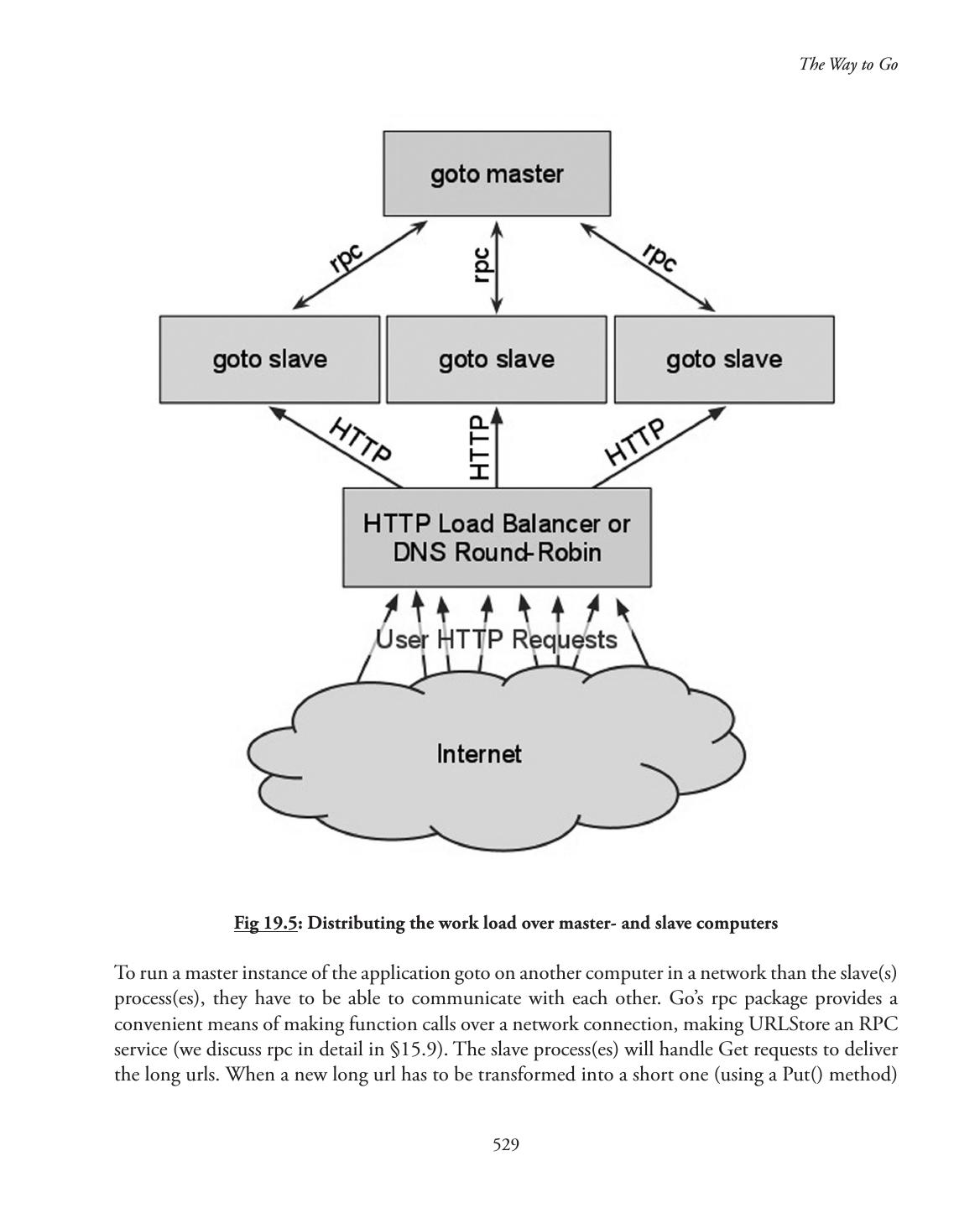
19 .Chapter 14—Goroutines and Channels.............................................................................375 Fig 14.1: Channels and goroutines...............................................................................382 Fig 14.2: The sieve prime-algorithm.............................................................................397 Chapter 15—Networking, templating and web-applications..............................................436 Fig 15.1—Screen of exercise 15.6.................................................................................454 Chapter 19—Building a complete application....................................................................509 Fig 19.1: Handler functions in goto.............................................................................515 Fig 19.2: The Add handler...........................................................................................518 Fig 19.3: The response of the Add handler...................................................................519 Fig 19.4: The response of the Redirect handler.............................................................519 Fig 19.5: Distributing the work load over master- and slave computers........................529 Chapter 20—Go in Google App Engine............................................................................538 Fig 20.1: The Application Control Panel......................................................................558
20 .Preface Code less, compile quicker, execute faster => have more fun! This text presents the most comprehensive treatment of the Go programming language you can find. It draws on the whole spectrum of Go sources available: online documentation and blogs, books, articles, audio and video, and my own experience in software engineering and teaching programming languages and databases, organizing the concepts and techniques in a systematic way. Several researchers and developers at Google experienced frustration with the software development processes within the company, particularly using C++ to write large server software. The binaries tended to be huge and took a long time to compile, and the language itself was quite old. A lot of the ideas and changes in hardware that have come about in the last couple of decades haven’t had a chance to influence C++. So the researchers sat down with a clean sheet of paper and tried to design a language that would solve the problems they had: 1. software needs to built quickly, 2. the language should run well on modern multi-core hardware, 3. the language should work well in a networked environment, 4. the language should be a pleasure to use. And so was born “Go”, a language that has the feel of a dynamic language like Python or Ruby, but has the performance and safety of languages like C or Java. Go seeks to reinvent programming in the most practical of ways: its not a fundamentally new language with strange syntax and arcane concepts; instead it builds and improves a lot on the existing C/Java/C#-style syntax. It proposes interfaces for object-oriented programming and goroutines / channels for concurrent and parallel programming. This book is intended for developers who want to learn this new, fascinating and promising language. Some basic knowledge of programming and some experience with a programming language and environment is assumed, but a thorough knowledge of C or Java or the like is not needed. xix
21 .Ivo Balbaert For those of you who are familiar with C or the current object oriented languages, we will compare the concepts in Go with the corresponding concepts in these languages (throughout the book we will use the well known OO abrevation, to mean object-oriented). This text explains everything from the basic concepts onwards, but at the same time we discuss advanced concepts and techniques such as a number of different patterns when applying goroutines and channels, how to use the google api from Go, how to apply memoization, how to use testing in Go and how to use templating in web applications. In Part I we discuss the origins of the language (ch 1) and get you started with the installation of Go (ch 2) and a development environment (ch 3). Part 2 then guides you through the core concepts of Go: the simple and composite types (ch 4, 7, 8), control structures (ch 5), functions (ch 6), structs with their methods (ch 10), and interfaces (ch 11). The functional and object-oriented aspects of Go are thoroughly discussed, as well as how Go code in larger projects is structured (ch 9). Part 3 learns you how to work with files in different formats (ch 12) and how to leverage the error-handling mechanism in Go (ch 13). It also contains a thorough treatment of Go’s crown jewel: goroutines and channels as basic technique for concurrent and multicore applications (ch 14). Then we discuss the networking techniques in Go and apply this to distributed and web applications (ch 15). Part 4 shows you a number of Go language patterns and idioms (ch 16, 17), together with a collection of useful code snippets (ch 18). With all of the techniques which you have learned in the previous chapters, a complete Go project is built (ch 19) and you get an introduction in how to use Go in the cloud (Google App Engine) (ch 20). In the last chapter (ch 21) we discuss some real world uses of go in businesses and organizations all over the world. The text is concluded with quotes of users, listings, references to Go packages and tools, answers to questions and exercises, and a bibliography of all resources and references. Go has very much a ‘no nonsense’ approach to it: extreme care has gone into making things easy and automatic; it adheres to the KISS principle from Agile programming: Keep It Short and Simple! Solving or leaving out many of the ‘open’ features in C, C++ or Java makes the developer’s life much easier! A few examples are: default initializations of variables; memory is allocated and freed automatically; fewer, but more powerful control constructs. As we will see Go also aims to prevent unnecessary typing, often Go code is shorter and easier to read than code from the classic object-oriented languages. xx
22 . The Way to Go Go is simple enough to fit in your head, which can’t be said from C++ or Java; the barrier to entry is low, compared to e.g. Scala (the Java concurrent language). Go is a modern day C. Most of the code-examples and exercises provided interact with the console, which is not a surprise since Go is in essence a systems language. Providing a graphical user interface (GUI) framework which is platform-independent is a huge task. Work is under way in the form of a number of 3rd party projects, so somewhere in the near future there probable will be a usable Go GUI framework. But in this age the web and its protocols are all pervasive, so to provide a GUI in some examples and exercises we will use Go’s powerful http and template packages. We will always use and indicate what is called idiomatic Go-code, by which we mean code which is accepted as being best practice. We try to make sure that examples never use concepts or techniques which were not covered up until that point in the text. There are a few exceptions where it seemed better to group it with the discussion of the basic concept: in that case the advanced concept is referenced and the § can be safely skipped. All concepts and techniques are thoroughly explained through 227 working code examples (on a grey background), printed out and commented in the text and available online for execution and experimenting. The book is cross-referenced as much as possible, forward as well as backward. And of course this is what you must do: after setting up a Go environment with a decent editor, start experimenting with the code examples and try the exercises: mastering a new language and new concepts can only be achieved through exercising and experimenting, so the text contains 130 exercises, with downloadable solutions. We have used the famous Fibonacci algorithm in examples and exercises in 13 versions to illustrate different concepts and coding techniques in Go. The book has an website (https://sites.google.com/site/thewaytogo2012/) from where the code examples can be downloaded and on which complementary material and updates are available. For your convenience and further paving your path to become a Go master, special chapters are dedicated to the best practices and language patterns in Go, and another to the pitfalls for the Go beginner. Handy as a desktop-reference while coding is chapter 18, which is a collection of the most useful code snippets, with references to the explanations in the text. And last but not least, a comprehensive index leads you quickly to the page you need at the moment. All code has been tested to work with the stable Go-release Go 1. Here are the words of Bruce Eckel, a well known authority on C++, Java and Python: xxi
23 .Ivo Balbaert “Coming from a background in C/C++, I find Go to be a real breath of fresh air. At this point, I think it would be a far better choice than C++ for doing systems programming because it will be much more productive and it solves problems that would be notably more difficult in C++. This is not to say that I think C++ was a mistake -- on the contrary, I think it was inevitable. At the time, we were deeply mired in the C mindset, slightly above assembly language and convinced that any language construct that generated significant code or overhead was impractical. Things like garbage collection or language support for parallelism were downright ridiculous and no one took them seriously. C++ took the first baby steps necessary to drag us into this larger world, and Stroustrup made the right choices in making C++ comprehensible to the C programmer, and able to compile C. We needed that at the time. We’ve had many lessons since then. Things like garbage collection and exception handling and virtual machines, which used to be crazy talk, are now accepted without question. The complexity of C++ (even more complexity has been added in the new C++), and the resulting impact on productivity, is no longer justified. All the hoops that the C++ programmer had to jump through in order to use a C-compatible language make no sense anymore -- they’re just a waste of time and effort. Now, Go makes much more sense for the class of problems that C++ was originally intended to solve.” I would like to express my sincere gratitude to the Go team for creating this superb language, especially “Commander” Rob Pike, Russ Cox and Andrew Gerrand for their beautiful and illustrative examples and explanations. I also thank Miek Gieben, Frank Müller, Ryanne Dolan and Satish V.J. for the insights they have given me, as well as countless other members of the Golang-nuts mailing list. Welcome to the wonderful world of developing in Go! xxii
24 . PART 1 WHY LEARN GO—GETTING STARTED
25 .
26 .Chapter 1—Origins, Context and Popularity of Go 1.1 Origins and evolution Go’s year of genesis was 2007, and the year of its public launch was 2009. The initial design on Go started on September 21, 2007 as a 20% part-time project at Google Inc. by three distinguished IT-engineers: Robert Griesemer (known for his work at the Java HotSpot Virtual Machine), Rob ‘Commander’ Pike (member of the Unix team at Bell Labs, worked at the Plan 9 and Inferno operating systems and the Limbo programming language) and Ken Thompson (member of the Unix team at Bell Labs, one of the fathers of C, Unix and Plan 9 operating systems, co-developed UTF-8 with Rob Pike). By January 2008 Ken Thompson had started working on a compiler to explore the ideas of the design; it produced C as output. This is a gold team of ‘founding fathers’ and experts in the field, who have a deep understanding of (systems) programming languages, operating systems and concurrency. Fig 1.1: The designers of Go: Griesemer, Thompson and Pike By mid 2008, the design was nearly finished, and full-time work started on the implementation of the compiler and the runtime. Ian Lance Taylor joins the team, and in May 2008 builds a gcc-frontend. 1
27 .Ivo Balbaert Russ Cox joins the team and continues the work on the development of the language and the libraries, called packages in Go. On October 30 2009 Rob Pike gave the first talk on Go as a Google Techtalk. On November 10 2009, the Go-project was officially announced, with a BSD-style license (so fully open source) released for the Linux and Mac OS X platforms. A first Windows-port by Hector Chu was announced on November 22. Being an open-source project, from then on a quickly growing community formed itself which greatly accelerated the development and use of the language. Since its release, more than 200 non-Google contributors have submitted over 1000 changes to the Go core; over the past 18 months 150 developers contributed new code. This is one of the largest open-source teams in the world, and is in the top 2% of all project teams on Ohloh (source: www.ohloh.net ). Around April 2011 10 Google employees worked on Go full-time. Open-sourcing the language certainly contributed to its phenomenal growth. In 2010 Andrew Gerrand joins the team as a co-developer and Developer Advocate. Go initiated a lot of stir when it was publicly released and on January 8, 2010 Go was pronounced ‘language of the year 2009’ by Tiobe ( www.tiobe.com, well-known for its popularity ranking of programming languages). In this ranking it reached its maximum (for now) in Feb 2010, being at the 13th place, with a popularity of 1,778 %. Year Winner 2010 Python 2009 Go 2008 C 2007 Python 2006 Ruby 2005 Java 2004 PHP 2003 C++ Go Programming Language of the year 2009 at Tiobe 2
28 . The Way to Go TIMELINE: Initial design Public release Language of the Used at Go in Google year 2009 Google App Engine 2007 Sep 21 2009 Nov 10 2010 Jan 8 2010 May 2011 May 5 Since May 2010 Go is used in production at Google for the back-end infrastructure, e.g. writing programs for administering complex environments. Applying the principle: ‘Eat your own dog food’: this proves that Google wants to invest in it, and that the language is production-worthy. The principal website is http://golang.org/: this site runs in Google App Engine with godoc (a Go-tool) serving (as a web server) the content and a Python front-end. The home page of this site features beneath the title Check it out! the so called Go-playground, a sandbox which is a simple editor for Go-code, which can then be compiled and run, all in your browser without having installed Go on your computer. A few examples are also provided, starting with the canonical “Hello, World!”. Some more info can be found at http://code.google.com/p/go/, it hosts the issue-tracker for Go bugs and -wishes: http://code.google.com/p/go/issues/list Go has the following logo which symbolizes its speed: =GO, and has a gopher as its mascot. Fig 1.2: The logo’s of Go The Google discussion-group Go Nuts (http://groups.google.com/group/golang-nuts/) is very active, delivering tens of emails with user questions and discussions every day. For Go on Google App Engine a separate group exists (https://groups.google.com/forum/#!forum/ google-appengine-go) although the distinction is not always that clear. The community has a Go language resource site at http://go-lang.cat-v.org/ and #go-nuts on irc.freenode.net is the official Go IRC channel. @go_nuts at Twitter (http://twitter.com/#!/go_nuts) is the Go project’s official Twitter account, with #golang as the tag most used. 3
29 .Ivo Balbaert There is also a Linked-in group: http://www.linkedin.com/groups?gid=2524765&trk=myg_ ugrp_ovr The Wikipedia page is at http://en.wikipedia.org/wiki/Go_(programming_language) A search engine page specifically for Go language code can be found at http://go-lang.cat-v.org/ go-search Go can be interactively tried out in your browser via the App Engine application Go Tour: http:// go-tour.appspot.com/ (To install it on your local machine, use: go install go-tour.googlecode.com/ hg/gotour). 1.2 Main characteristics, context and reasons for developing a new language 1.2.1 Languages that influenced Go Go is a language designed from the ground up, as a ‘C for the 21st century’.It belongs to the C-family, like C++, Java and C#, and is inspired by many languages created and used by its designers. There was significant input from the Pascal / Modula / Oberon family (declarations, packages) For its concurrency mechanism it builds on experience gained with Limbo and Newsqueak, which themselves were inspired by Tony Hoare’s CSP theory (Communicating Sequential Processes); this is essentially the same mechanism as used by the Erlang language. It is a completely open-source language, distributed with a BSD license, so it can be used by everybody even for commercial purposes without a fee, and it can even be changed by others. The resemblance with the C-syntax was maintained so as to be immediately familiar with a majority of developers, however comparing with C/C++ the syntax is greatly simplified and made more concise and clean. It also has characteristics of a dynamic language, so Python and Ruby programmers feel more comfortable with it. The following figure shows some of the influences: 4
相关推荐

加关注
3秒后跳转登录页面
去登陆

