



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Intel傲腾数据中心持久化内存技术加速Spark应用程序
Apache Spark作为分布式内存计算引擎,内存使用的优化对于性能提升至关重要,Intel的Optane(傲腾)技术,让内存和SSD之间架设了个新的数据缓存/存储层,并通过PMDK等特殊的API绕过文件系统,系统调用,内存拷贝等一系列额外操作,让性能有极大的提升。Intel开源的OAP(Optimized Analytics Package)for Apache Spark项目,也是基于这个前体,构建即席查询引擎,以及在机器学习算法诸如KMeans算法上也获得了不错的性能回报。
展开查看详情
1 .Cheng Xu, Intel cheng.a.xu@intel.com Nov, 2018
2 . Legal Disclaimer & Optimization Notice Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks. INFORMATION IN THIS DOCUMENT IS PROVIDED “AS IS”. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO THIS INFORMATION INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Copyright © 2018, Intel Corporation. All rights reserved. Intel, Pentium, Xeon, Xeon Phi, Core, VTune, Cilk, and the Intel logo are trademarks of Intel Corporation in the U.S. and other countries. Optimization Notice Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 2
3 .Agenda Challenges in Data Analytics Intel® Optane™ DC Persistent Memory (DCPMM) Introduction to PMDK library Spark DCPMM optimizations Future And Other DCPMM Optimization Work 3
4 .Let’s talk about Storage 4
5 .Let’s talk about Memory 5
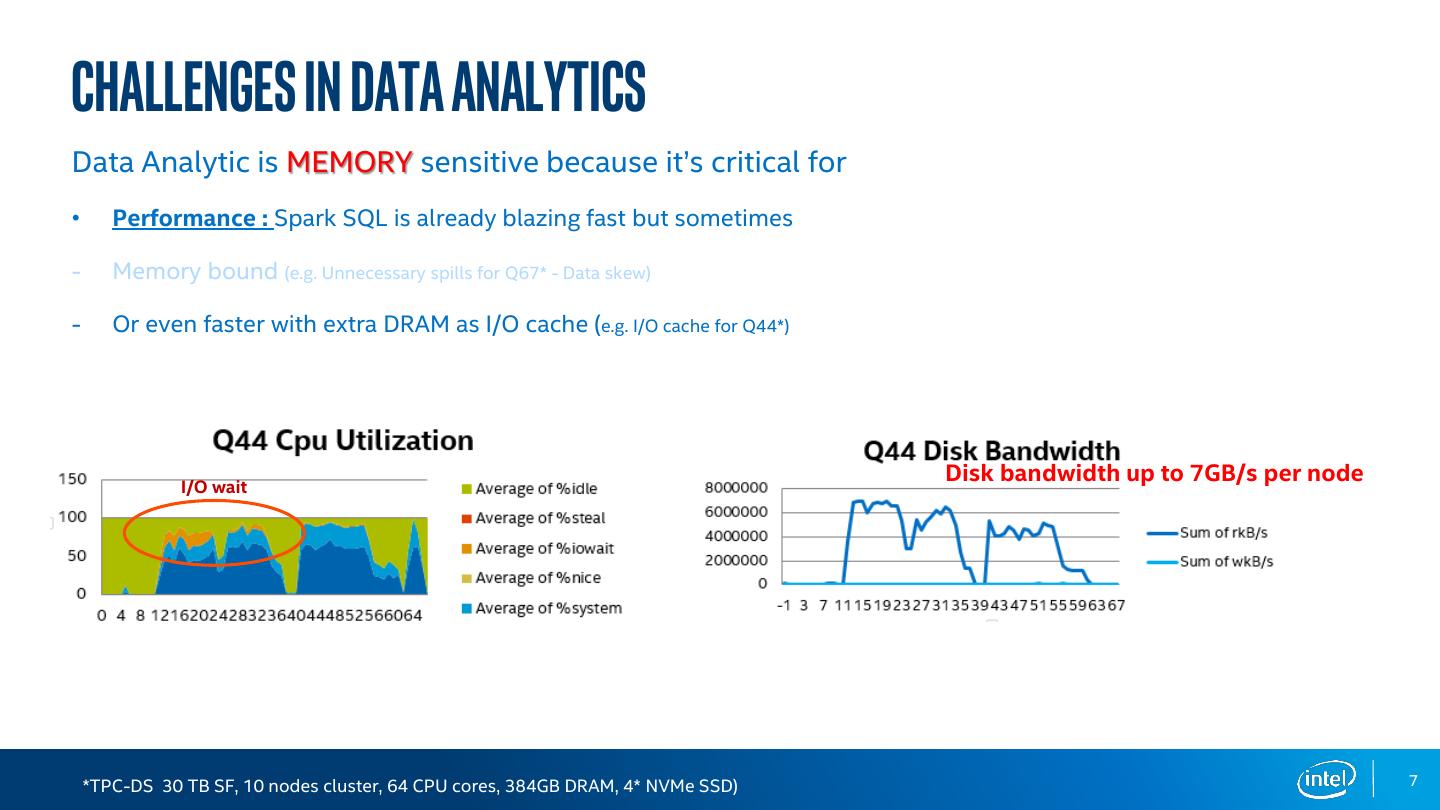
6 .challenges in data analytics 6000000 Disk Bandwidth Data Analytic is MEMORY sensitive because it’s critical for 5000000 4000000 • Performance : Spark SQL is already blazing fast but sometimes Axis Title 3000000 Sum of rkB/s Spills - Memory bound (e.g. Unnecessary spills for Q67* - Data skew) 2000000 Sum of wkB/s 1000000 - Or even faster with extra DRAM as I/O cache (e.g. I/O cache for Q44* or avoid) 0 1167 1390 1613 1837 2060 2283 2507 2732 2955 222 450 706 938 -1 *TPC-DS 30 TB SF, 10 nodes cluster, 64 CPU cores, 384GB DRAM, 4* NVMe SSD) 6
7 .challenges in data analytics Data Analytic is MEMORY sensitive because it’s critical for • Performance : Spark SQL is already blazing fast but sometimes - Memory bound (e.g. Unnecessary spills for Q67* - Data skew) - Or even faster with extra DRAM as I/O cache (e.g. I/O cache for Q44*) Disk bandwidth up to 7GB/s per node I/O wait *TPC-DS 30 TB SF, 10 nodes cluster, 64 CPU cores, 384GB DRAM, 4* NVMe SSD) 7
8 .challenges in data Analytics Data Analytics is facing DILEMMA and tradeoff for • Performance VS. Durable: Persistent! Performance! - Checkpoint for iterative computation (e.g. Persisted checkpoint in Spark) - Or Recovery Log Flush Frequency (e.g. Kafka recovery log flush frequency) • Scale out VS. Scale up: Cheaper! - Better TCO - Extra cost for scale out, sometimes lower utilization • On heap VS. off heap Easy to use! - GC VS. Self-managed memory *TPC-DS 30 TB SF, 10 nodes cluster, 64 CPU cores, 384GB DRAM, 4* NVMe SSD) 8
9 .Answer? 9
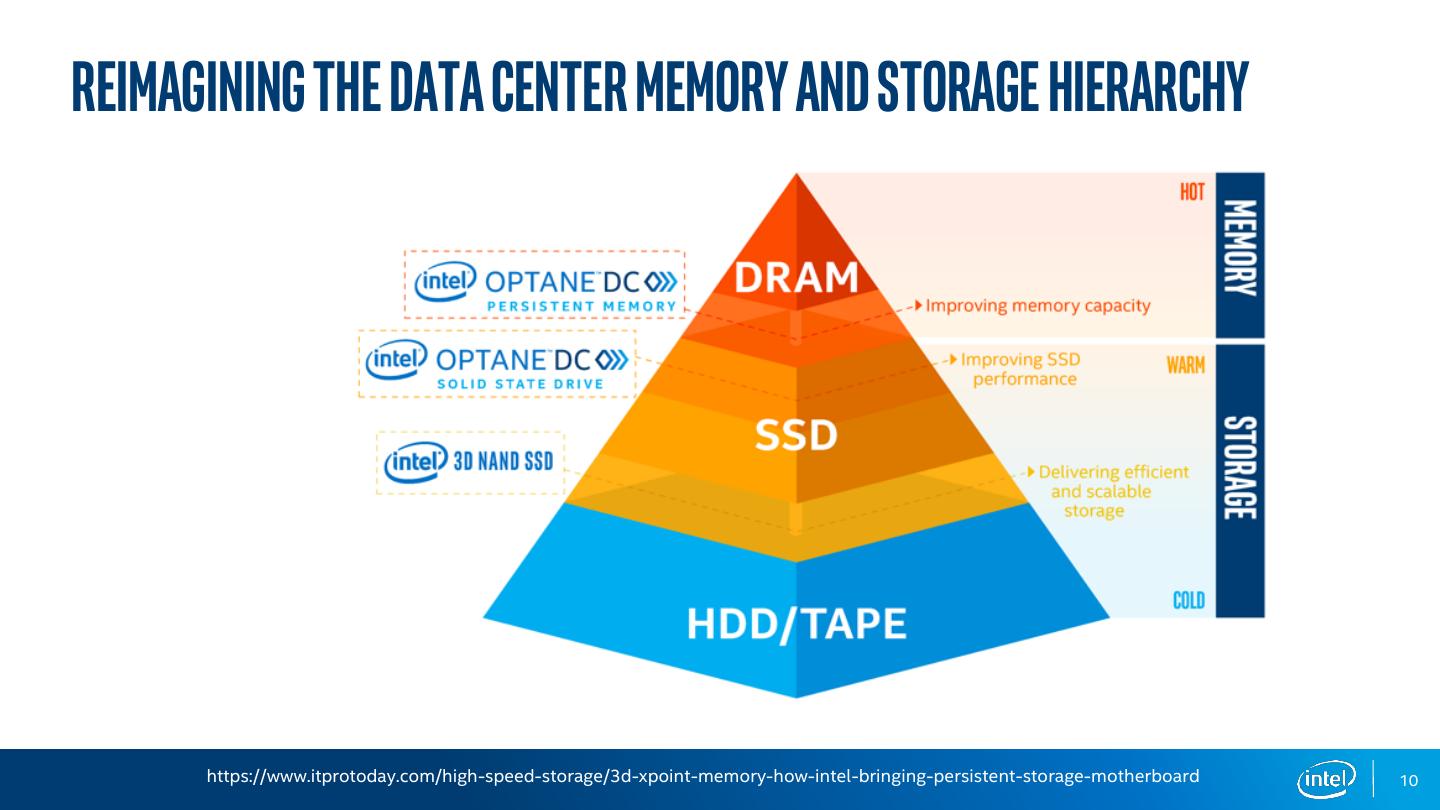
10 .Reimagining the data center memory and storage hierarchy https://www.itprotoday.com/high-speed-storage/3d-xpoint-memory-how-intel-bringing-persistent-storage-motherboard 10
11 . Intel optane dc persistent memory Big and Affordable Memory 128, 256, 512GB High Performance Storage DDR4 Pin Compatible Direct Load/Store Access Hardware Encryption Native Persistence High Reliability
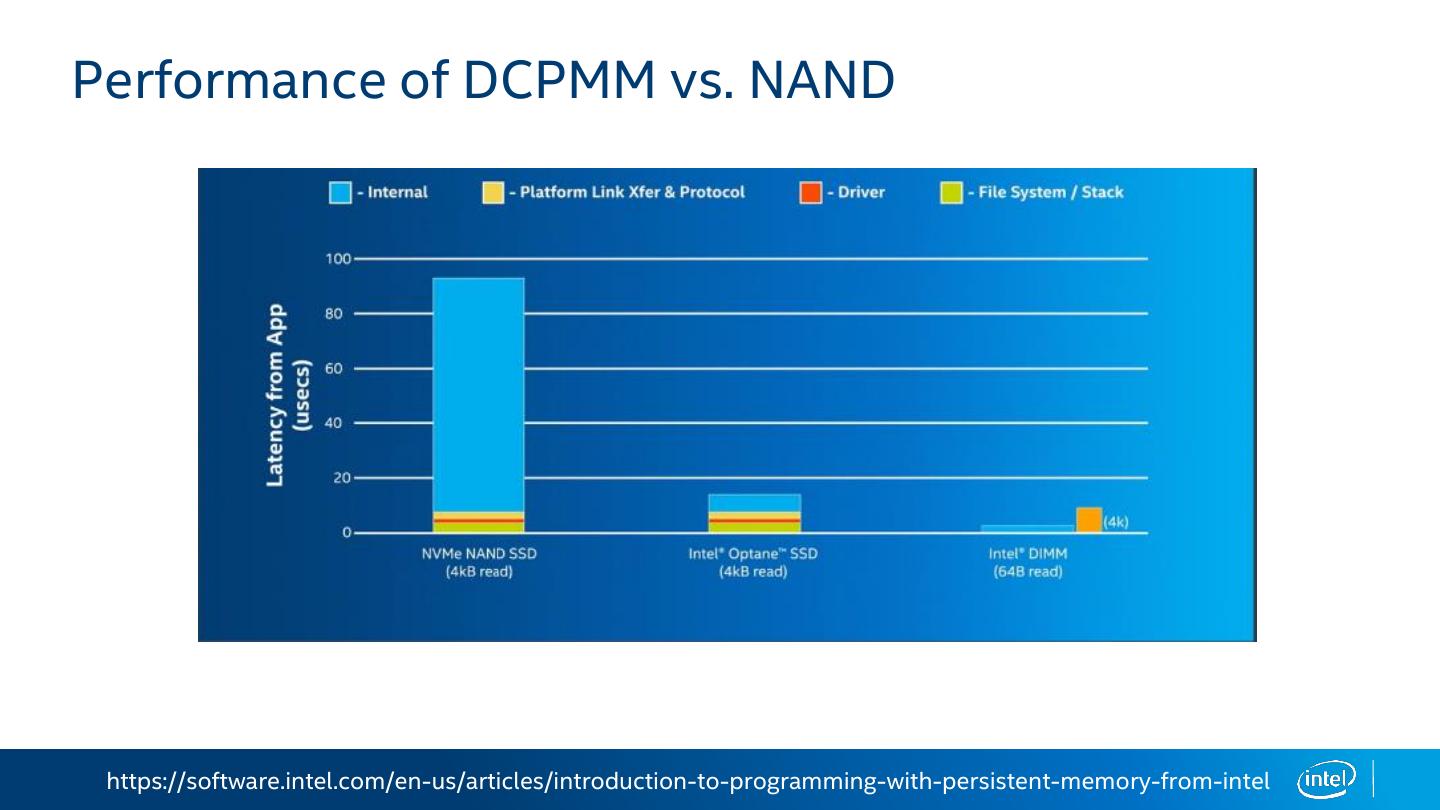
12 .Performance of DCPMM vs. NAND https://software.intel.com/en-us/articles/introduction-to-programming-with-persistent-memory-from-intel
13 .Then how to use it? 13
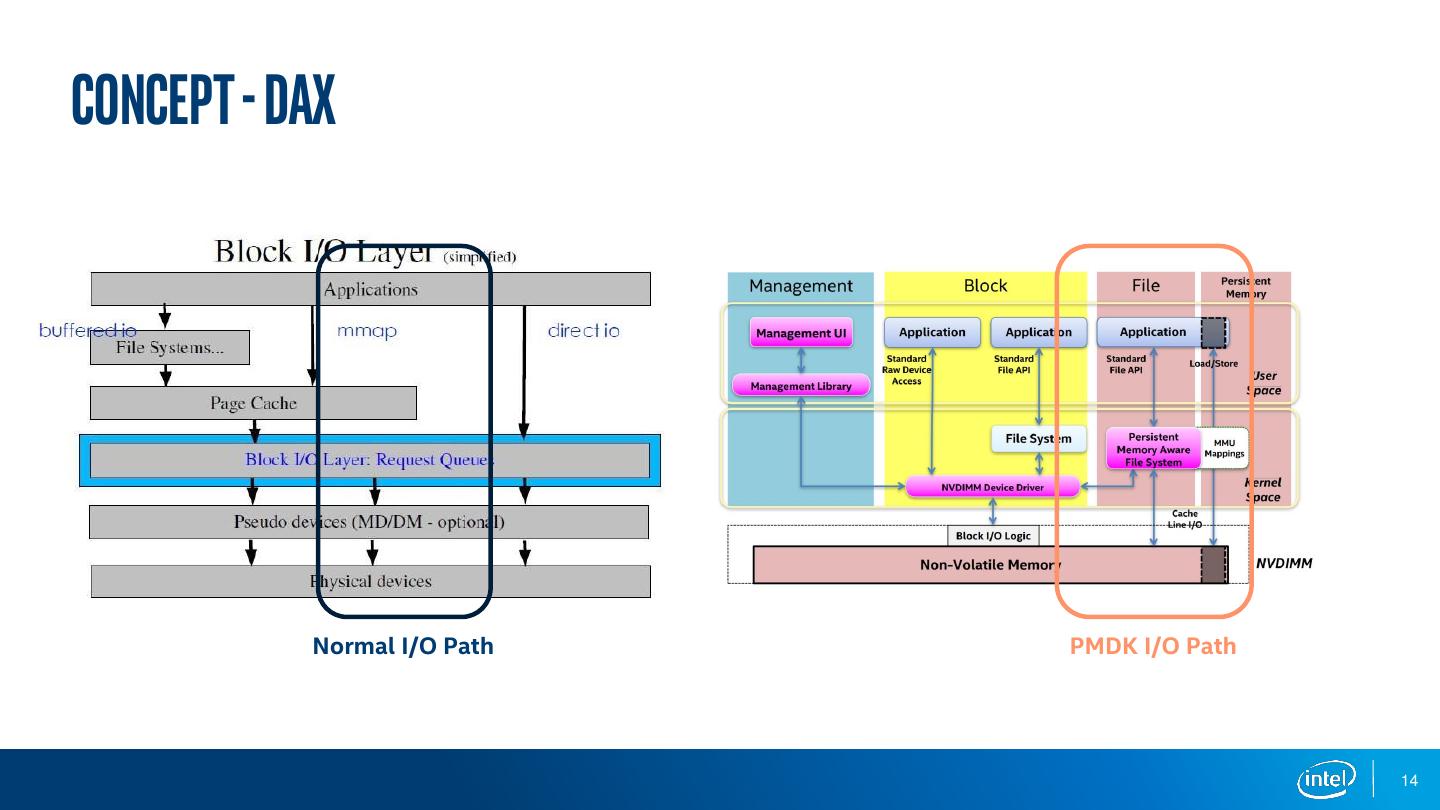
14 .Concept - DAX Normal I/O Path PMDK I/O Path 14
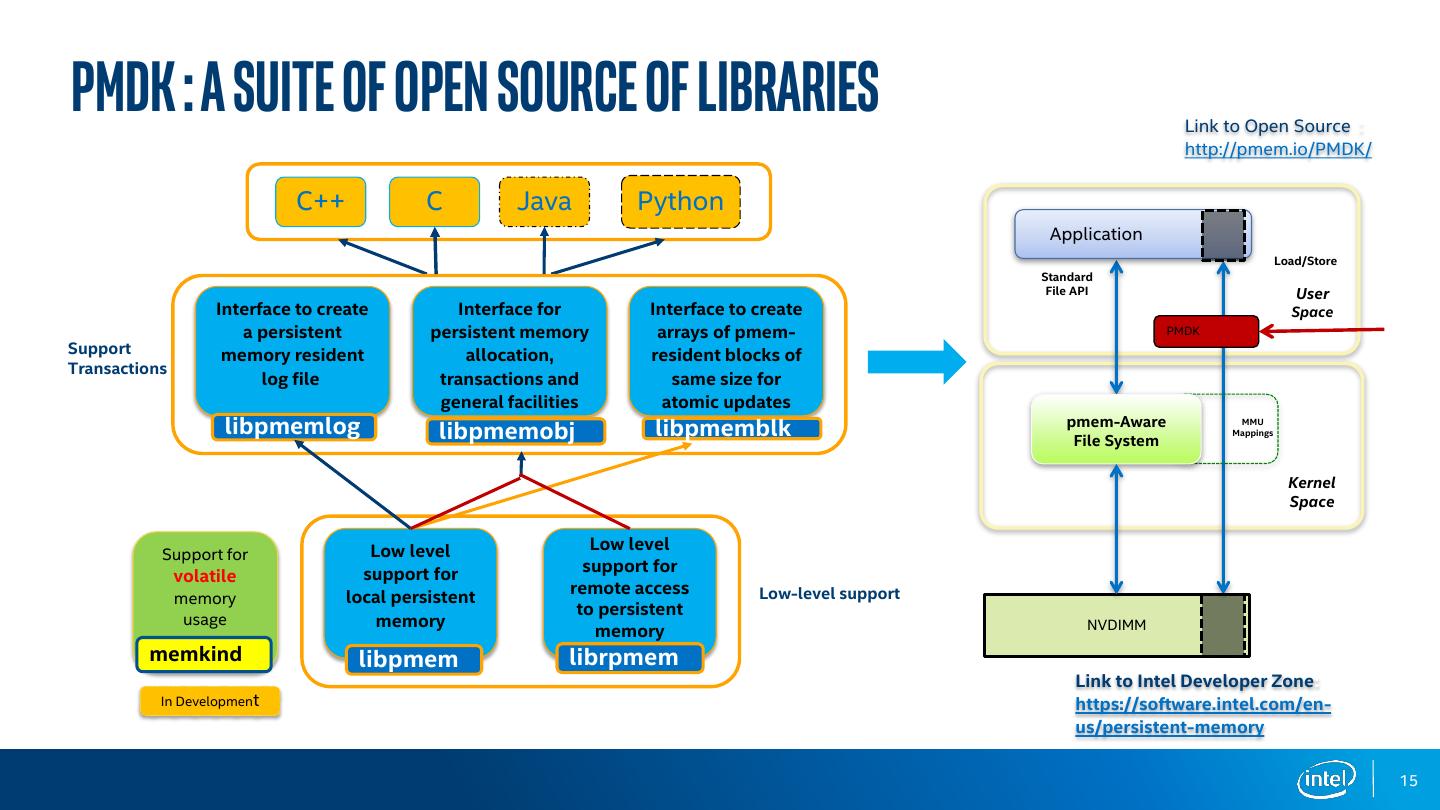
15 .PMDK : A Suite of Open Source of Libraries Link to Open Source : http://pmem.io/PMDK/ C++ C Java Python Application Load/Store Standard File API User Interface to create Interface for Interface to create Space a persistent persistent memory arrays of pmem- PMDK Support memory resident allocation, resident blocks of Transactions log file transactions and same size for general facilities atomic updates libpmemlog libpmemobj libpmemblk pmem-Aware File System MMU Mappings Kernel Space Low level Low level Support for support for support for volatile remote access Low-level support memory local persistent to persistent usage memory NVDIMM memory memkind libpmem librpmem Link to Intel Developer Zone: In Development https://software.intel.com/en- us/persistent-memory 15
16 .Memkind library #include <stdio.h> #include <stdlib.h> #include <string.h> #include <libvmem.h> - Memkind supports the traditional malloc/free interfaces on a int memory mapped file main(int argc, char *argv[]) { VMEM *vmp; - Use persistent memory as volatile memory char *ptr; /* create minimum size pool of memory */ - Old name was libmem if ((vmp = vmem_create("/pmem-fs", VMEM_MIN_POOL)) == NULL) { perror("vmem_create"); exit(1); } if ((ptr = vmem_malloc(vmp, 100)) == NULL) { perror("vmem_malloc"); exit(1); } strcpy(ptr, "hello, world"); /* give the memory back */ vmem_free(vmp, ptr); /* ... */ }
17 .Why PMDK • Built on top of SNIA Programming Model • Provides API to • Simplifies/Facilitates Persistent Memory • Allocate/Manage Persistent Memory Pools Programming Adoption with Higher • Uses memory-mapping Level Language Support • In-place update • C, C++, Java • Transactional Operations • No Changes to Compiler or Programming • Keeps Data Consistent and Durable Language during Application Crashes • Flushes processor caches • Abstracts details about • Power Fail Atomicity • Types of Flush commands supported by CPU • Builds on DAX capabilities in both Linux and • Size of Atomic Stores Windows https://www.snia.org/ 17
18 .How About Spark? 18
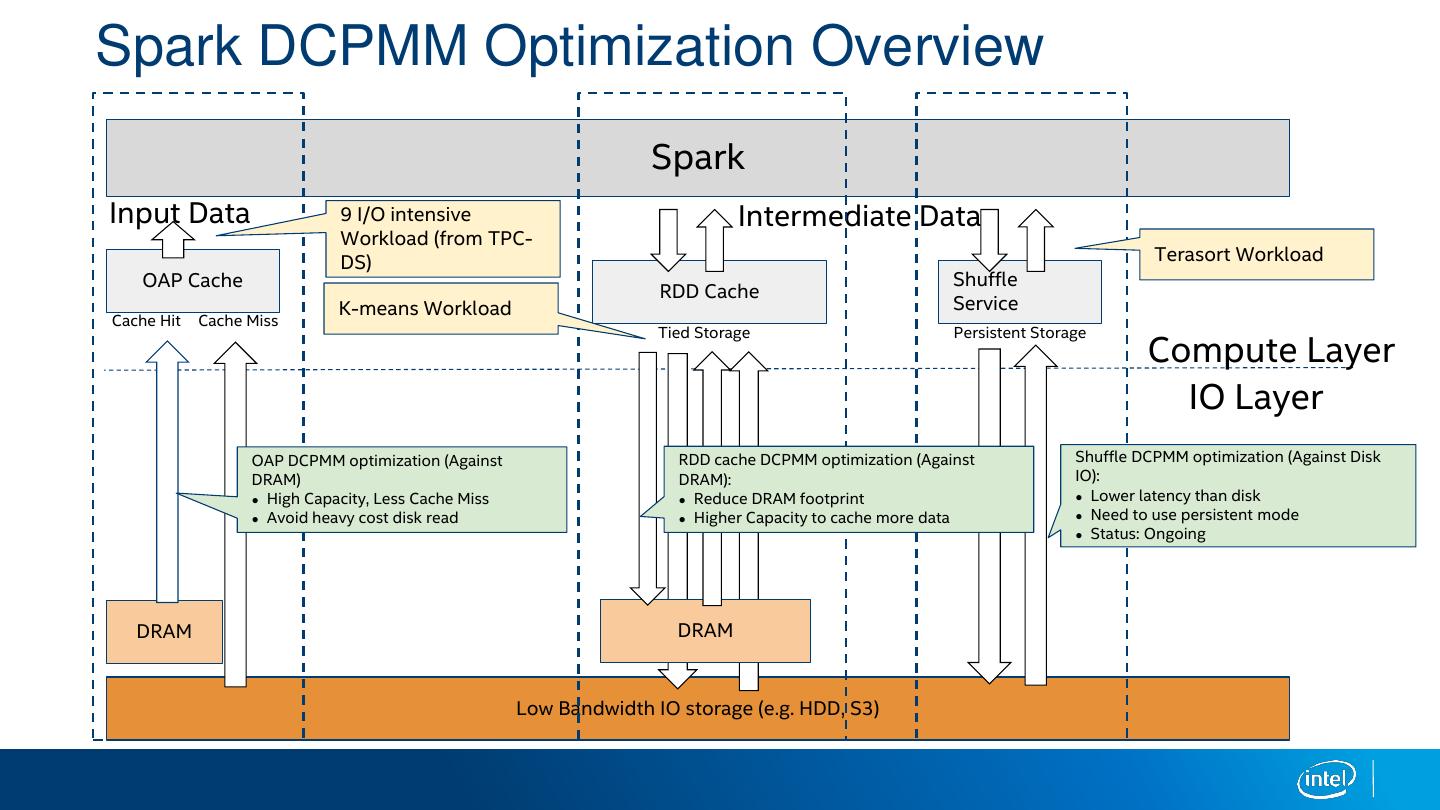
19 .Spark DCPMM Optimization Overview Spark Input Data 9 I/O intensive Intermediate Data Workload (from TPC- DS) Terasort Workload OAP Cache Shuffle RDD Cache K-means Workload Service Cache Hit Cache Miss Tied Storage Persistent Storage Compute Layer IO Layer OAP DCPMM optimization (Against RDD cache DCPMM optimization (Against Shuffle DCPMM optimization (Against Disk DRAM) DRAM): IO): ● High Capacity, Less Cache Miss ● Reduce DRAM footprint ● Lower latency than disk ● Avoid heavy cost disk read ● Higher Capacity to cache more data ● Need to use persistent mode ● Status: Ongoing DRAM DRAM Low Bandwidth IO storage (e.g. HDD, S3)
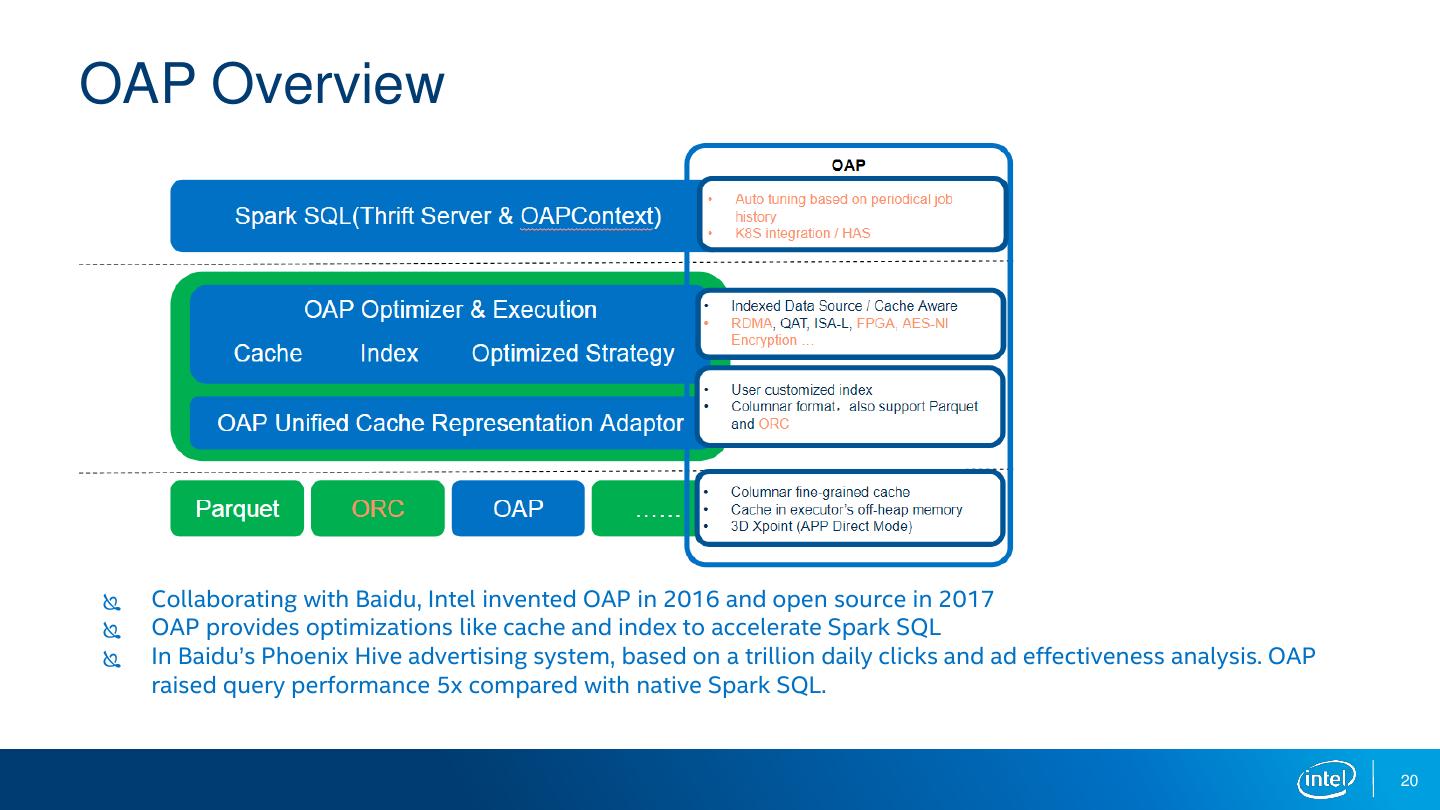
20 .OAP Overview Collaborating with Baidu, Intel invented OAP in 2016 and open source in 2017 OAP provides optimizations like cache and index to accelerate Spark SQL In Baidu’s Phoenix Hive advertising system, based on a trillion daily clicks and ad effectiveness analysis. OAP raised query performance 5x compared with native Spark SQL. 20
21 .OAP Architecture Spark Driver (OAPContext) Index & Cache aware OAP Data Source Strategy OAP DDL Fiber Sensor & Metrics Optimization Strategy (index/cache/metric) Spark Executor (1) IA Accelerated / Cache / Index / Cost aware Operators Spark Executor (2) Order By Aggregation Join …… OAP EndPoint Spark Executor (3) Unified Representation Cache Metrics Fiber CacheManager Cache Statistic & Spark Executor (….) Control Data Source Adapter Index OAP File Read/Write BitMap Index Parquet File Reader Btree Index Index Sample / ORC File Reader Statistic 21
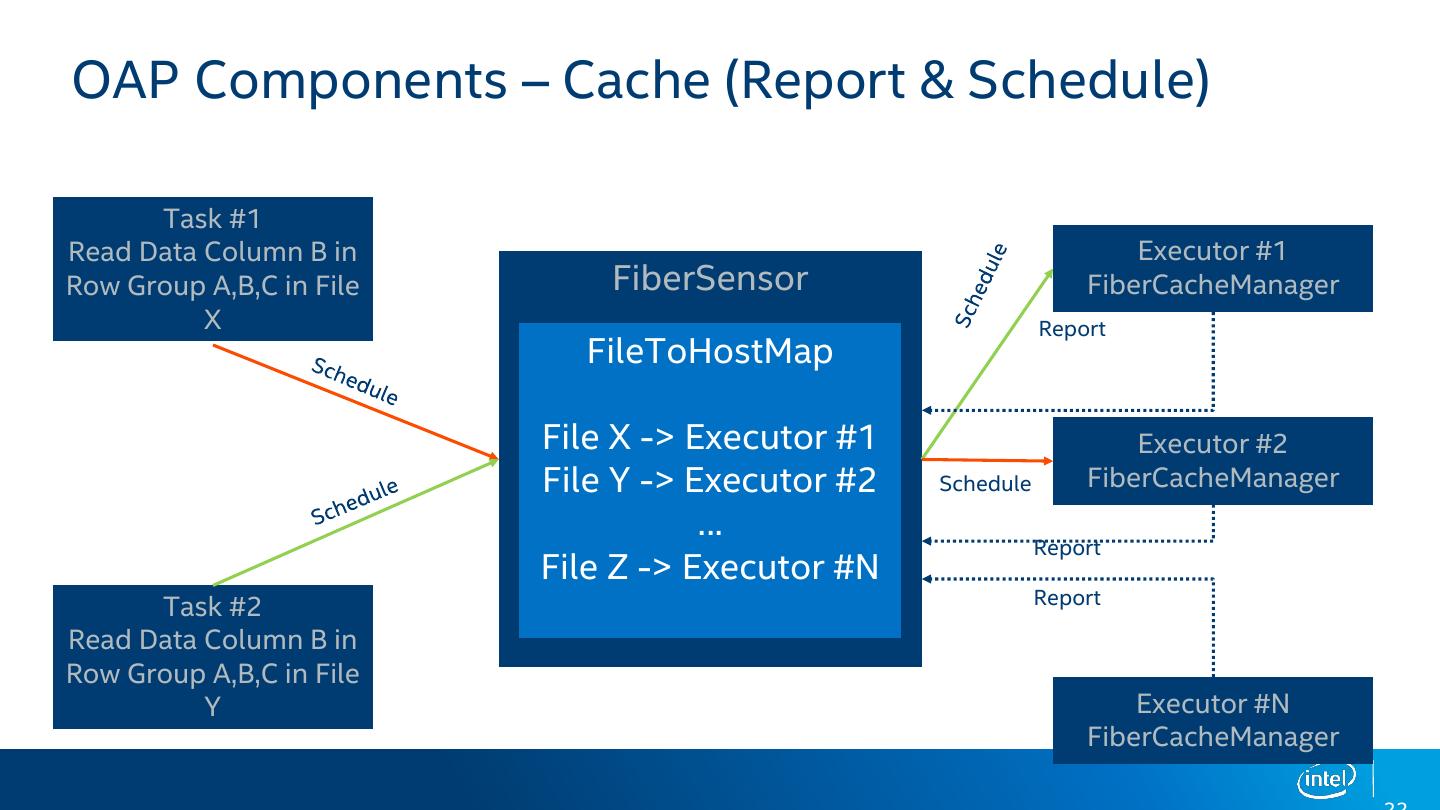
22 .OAP Components – Cache (Report & Schedule) Task #1 Read Data Column B in Executor #1 Row Group A,B,C in File FiberSensor FiberCacheManager X Report FileToHostMap File X -> Executor #1 Executor #2 File Y -> Executor #2 Schedule FiberCacheManager … Report File Z -> Executor #N Report Task #2 Read Data Column B in Row Group A,B,C in File Y Executor #N FiberCacheManager
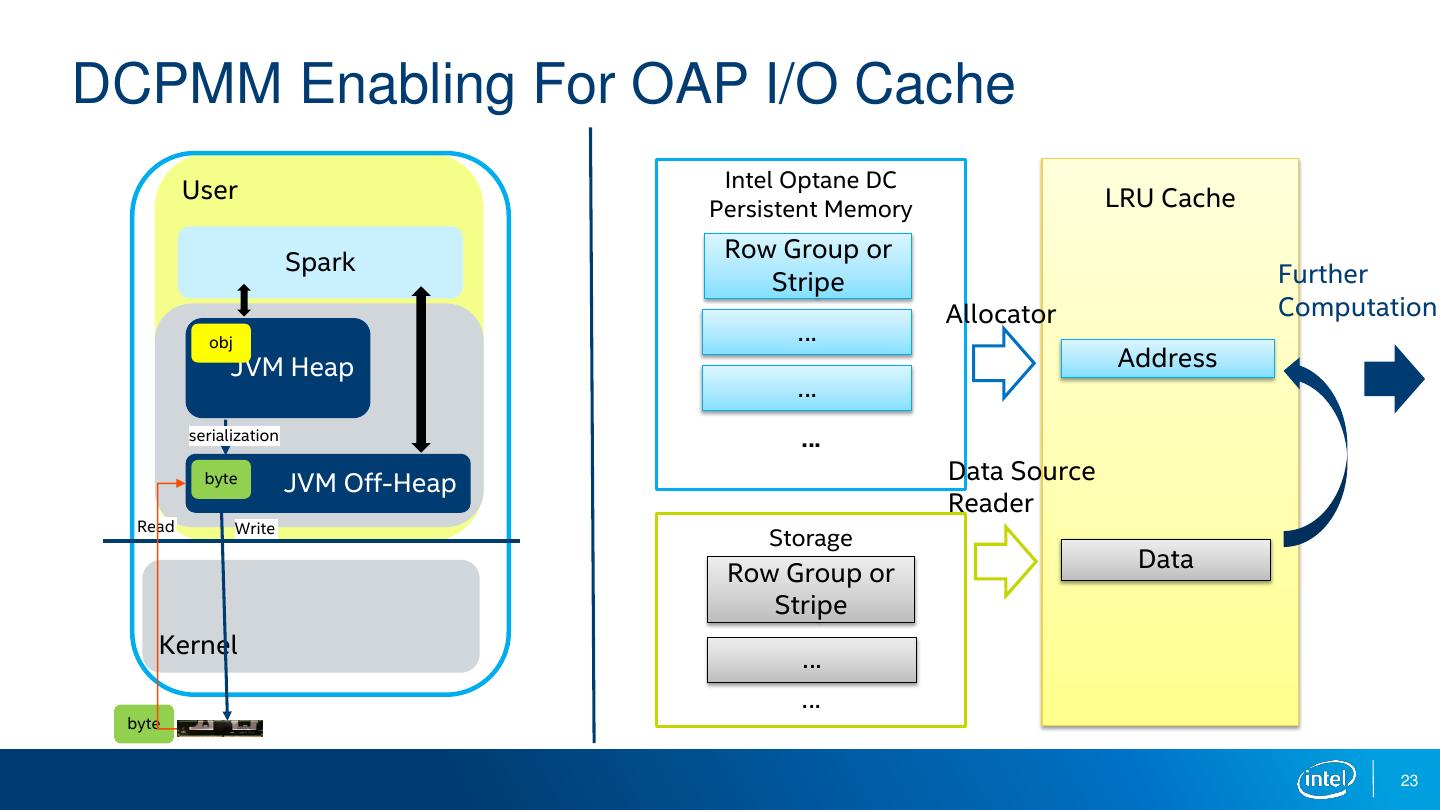
23 .DCPMM Enabling For OAP I/O Cache User Intel Optane DC Persistent Memory LRU Cache Spark Row Group or Stripe Further Allocator Computation obj … JVM Heap Address … serialization … byte JVM Off-Heap Data Source Reader Read Write Storage Data Row Group or Stripe Kernel … … byte 23
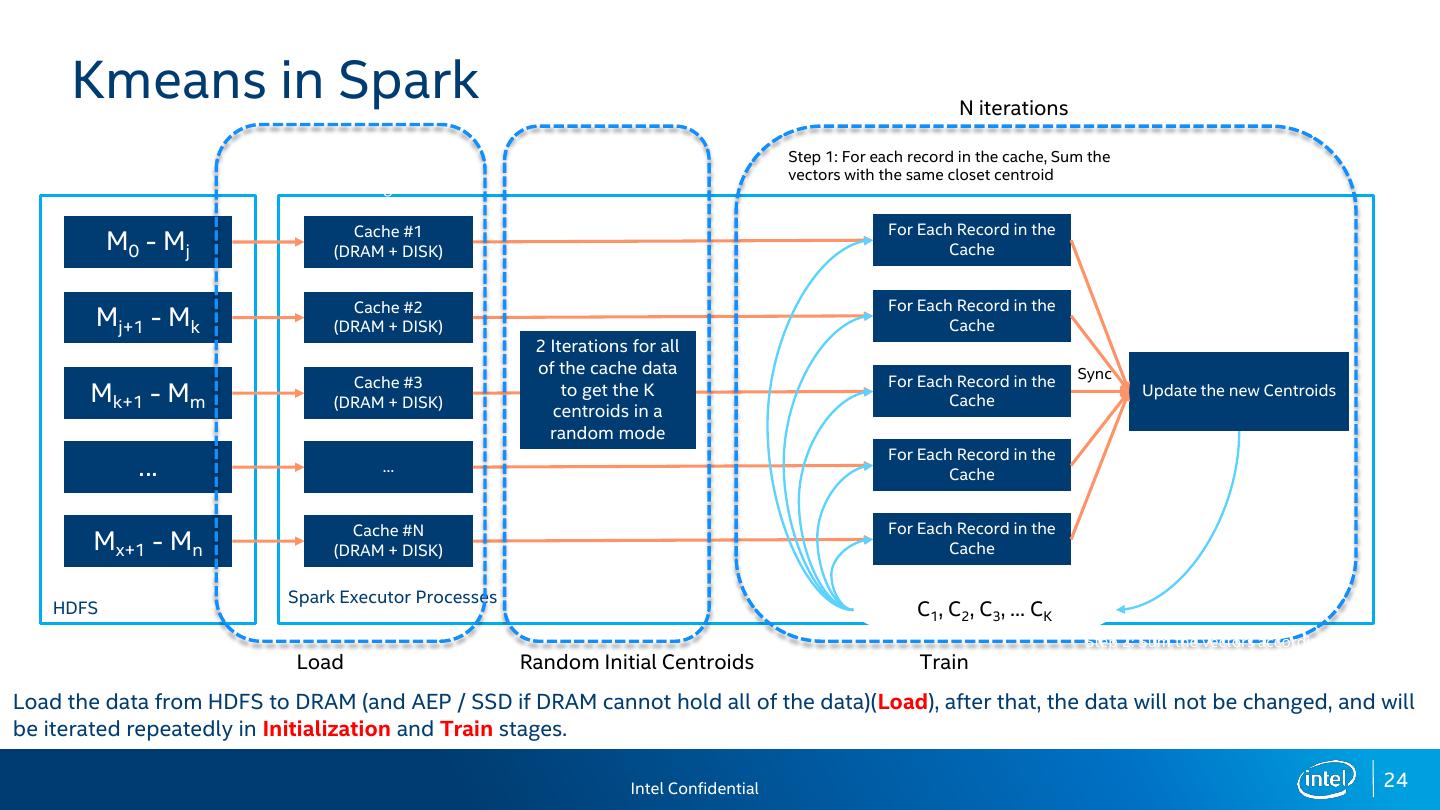
24 . Kmeans in Spark N iterations Loading Step 1: For each record in the cache, Sum the Normalization vectors with the same closet centroid Caching Cache #1 For Each Record in the M0 - Mj (DRAM + DISK) Cache Cache #2 For Each Record in the Mj+1 - Mk (DRAM + DISK) Cache 2 Iterations for all of the cache data Sync Cache #3 For Each Record in the Mk+1 - Mm (DRAM + DISK) to get the K Cache Update the new Centroids centroids in a random mode For Each Record in the … … Cache Cache #N For Each Record in the Mx+1 - Mn (DRAM + DISK) Cache Spark Executor Processes HDFS C1, C2, C3, … CK Step 2: Sum the vectors according to Load Random Initial Centroids Train the centroids and find out the new centroids globally Load the data from HDFS to DRAM (and AEP / SSD if DRAM cannot hold all of the data)(Load), after that, the data will not be changed, and will be iterated repeatedly in Initialization and Train stages. Intel Confidential 24
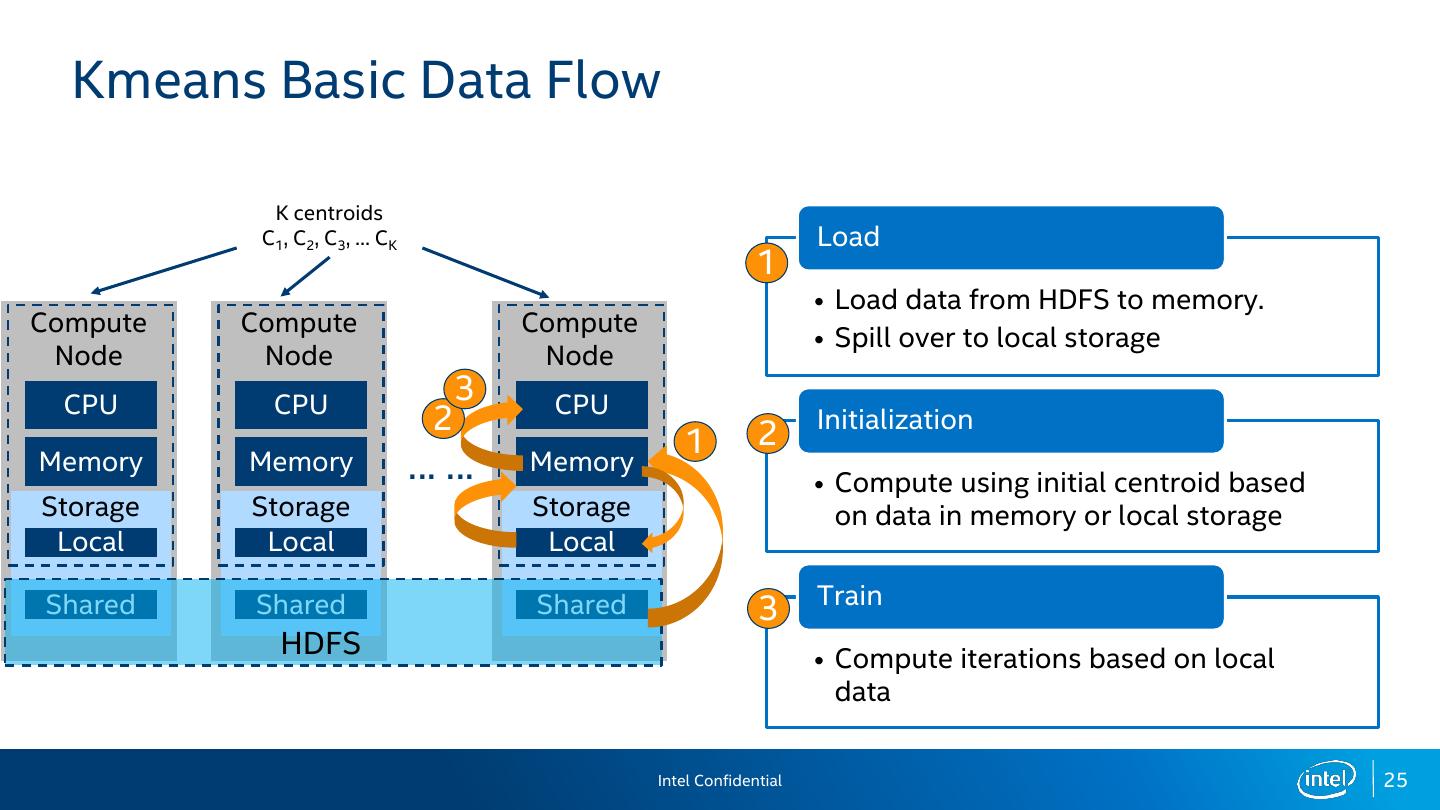
25 . Kmeans Basic Data Flow K centroids C1, C2, C3, … CK Load 1 • Load data from HDFS to memory. Compute Compute Compute • Spill over to local storage Node Node Node CPU CPU 3 CPU 2 2 Initialization 1 Memory Memory …… Memory • Compute using initial centroid based Storage Storage Storage on data in memory or local storage Local Local Local Train Shared Shared Shared 3 HDFS • Compute iterations based on local data Intel Confidential 25
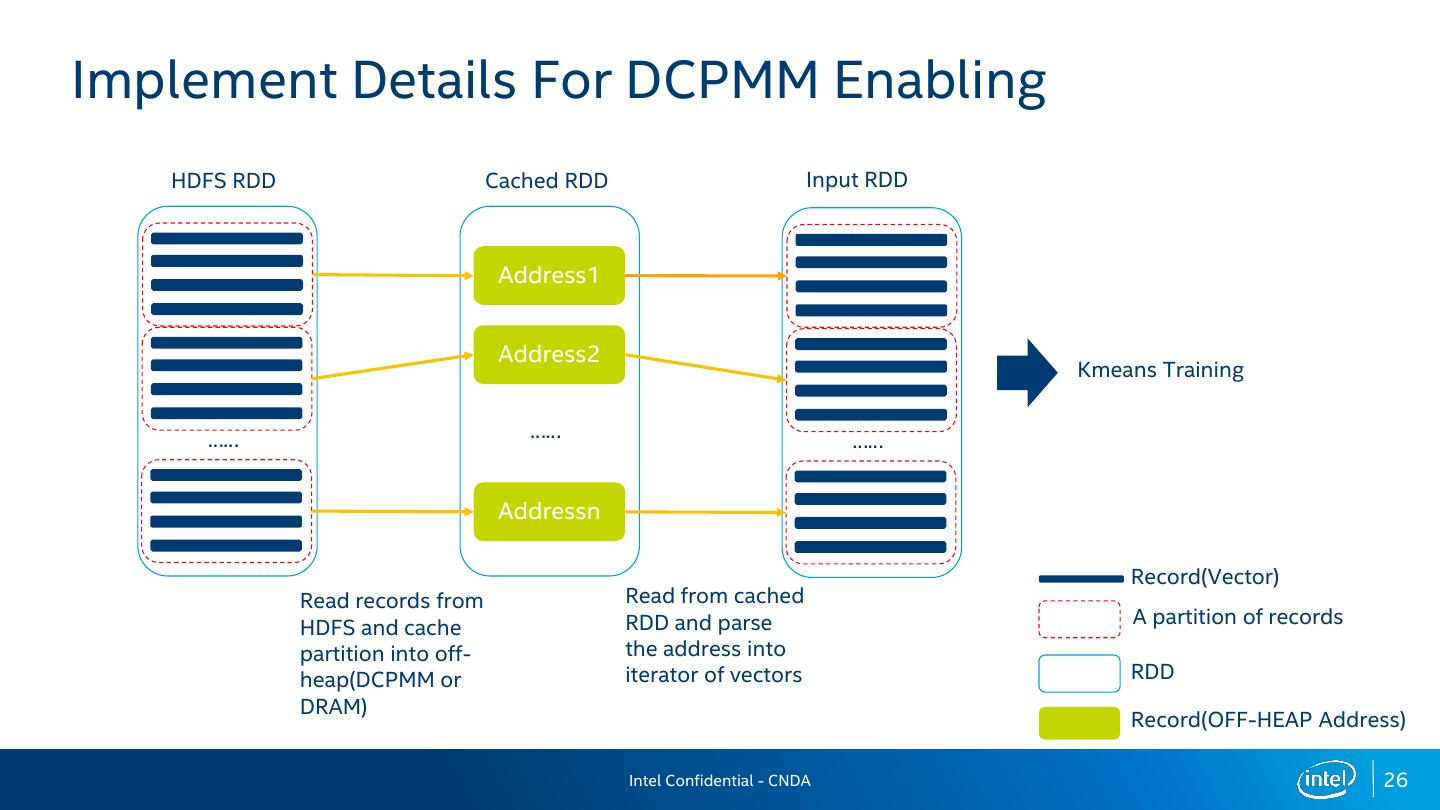
26 .Implement Details For DCPMM Enabling HDFS RDD Cached RDD Input RDD Address1 Address2 Kmeans Training …… …… …… Addressn Record(Vector) Read records from Read from cached HDFS and cache RDD and parse A partition of records partition into off- the address into heap(DCPMM or iterator of vectors RDD DRAM) Record(OFF-HEAP Address) Intel Confidential - CNDA 26
27 .Future Or Other related Work 27
28 .Future or Other DCPMM Optimization Work • Spark • HBase • Intel Optane DC persistent based • WALess with DCPMM checkpoint • Block cache • Broadcast join • Kudu • Push based shuffle DCPMM • block cache using DCPMM optimization • Hadoop • DCPMM based cache 28
29 .
相关推荐
3秒后跳转登录页面
去登陆

