MLSQL,一种基于Spark平台上的SQL方言
分享
点赞
67
收藏
7
下载 65
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
StreamingPro is mainly designed to run on Apache Spark but it also supports Apache Flink for the runtime. Thus, it can be considered as a cross,distributed platform which is the combination of BigData platform and AI platform where you can run both Big Data Processing and Machine Learning script.
MLSQL is a DSL akin to SQL but more powerfull based on StreamingPro platform. Since StreamingPro have already intergrated many ML frameworks including Spark MLLib, DL4J and Python ML framework eg. Sklearn, Tensorflow(supporting cluster mode) this means you can use MLSQL to operate all these popular Machine Learning frameworks.
展开查看详情
1 . MLSQL 一种基于Spark平台上的SQL方言
2 .自我 简介 祝海林,丁香园大数据资深架构师 技术博客: http://www.jianshu.com/u/59d5607f1400 开源项目: https://github.com/allwefantasy
3 .演讲 目录 为什么开发MLSQL 01 MLSQL使用演示 02 Skone平台介绍 04 Please Keep Quiet 机器学习平台MLSQL实践 MLSQL原理剖析 03
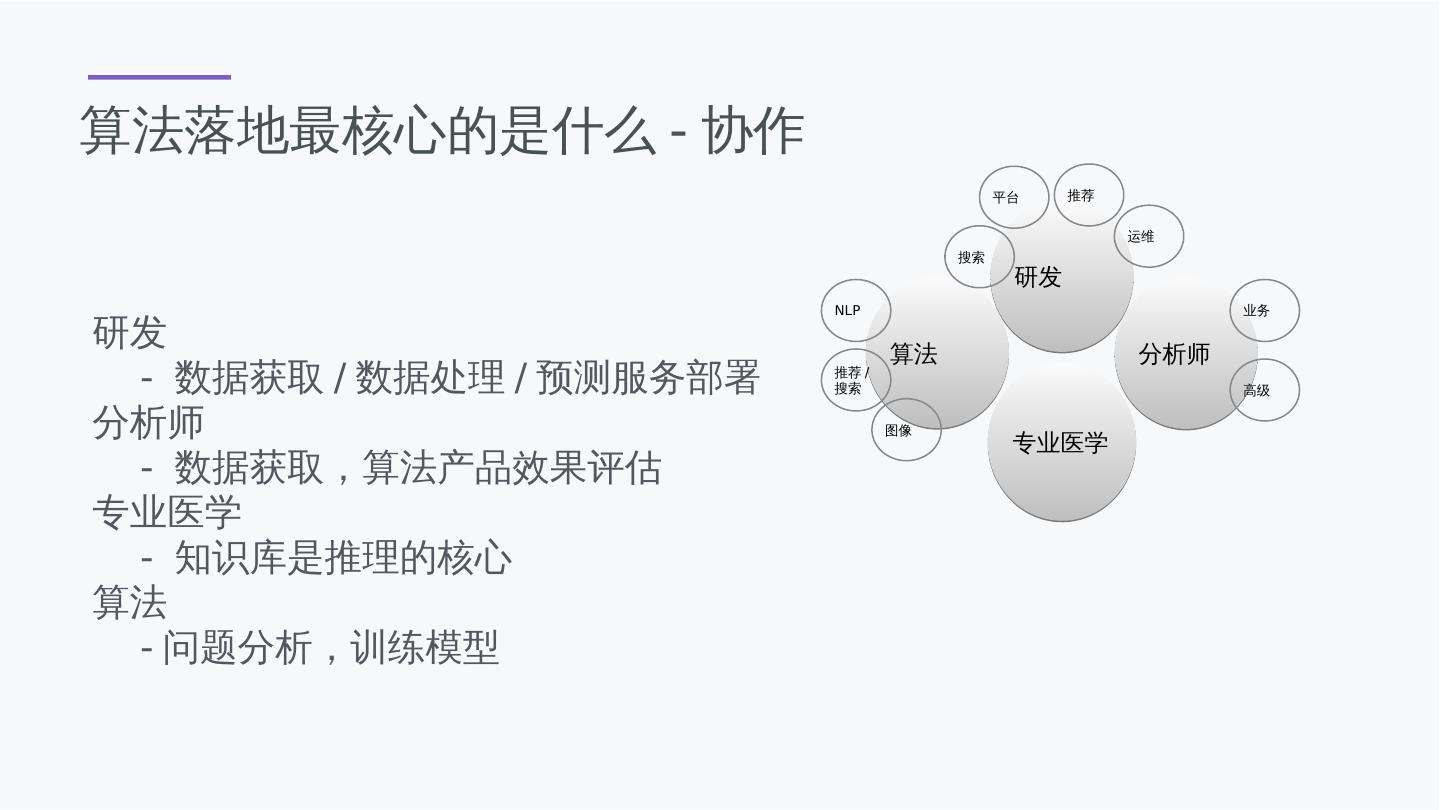
5 .算法落地最核心的是什么-协作 研发 - 数据获取/数据处理/预测服务部署 分析师 - 数据获取,算法产品效果评估 专业医学 - 知识库是推理的核心 算法 -问题分析,训练模型 研发 算法 分析师 专业医学 搜索 平台 推荐 NLP 推荐/搜索 图像 业务 高级 运维
6 .协作成本 问题: 1 算法需要反复清洗数据,直到找到合适的特征集合。 2 工程要用Spark做一遍工程化,主要是为了做定期训练 3 工程要用Java/Scala之类的再写一遍针对单条的,主要是为了做预测 原因: 语系不同,难以复用。算法 Python, 研发 Java/Scala/Go/C++ 框架体系不同,算法SKLearn,C++库,Tensorflow, 研发Spark等 对代码要求不一样。算法希望快速找到合适的特征和模型, 工程注重效率和代码复用
7 .反问自己 能填补这种沟壑么? 1 数据处理过程无法在训练和预测时复用 2 无法很好的衔接算法和工程的框架
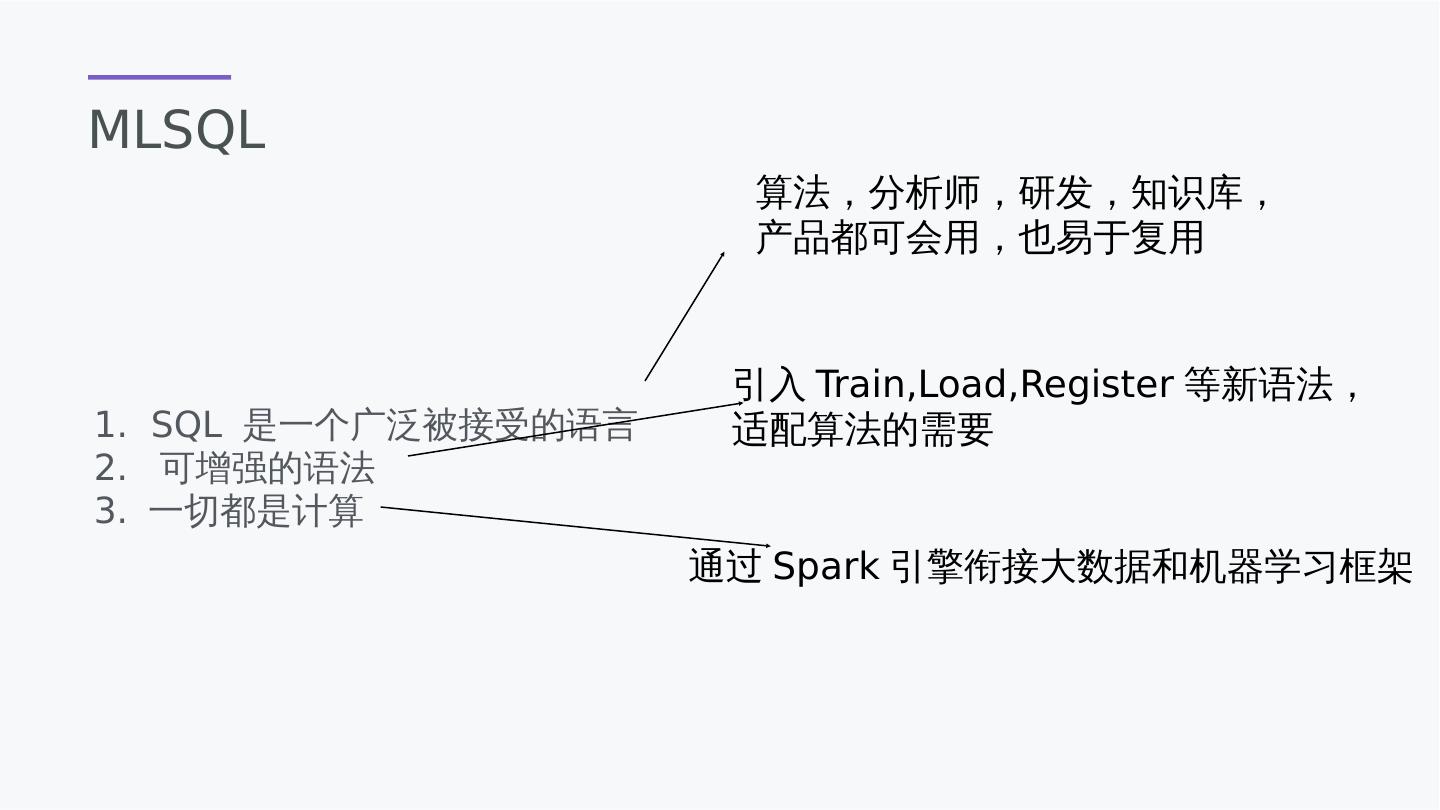
9 .MLSQL 1. SQL 是一个广泛被接受的语言 2. 可增强的语法 3. 一切都是计算 算法,分析师,研发,知识库, 产品都可会用,也易于复用 引入Train,Load,Register等新语法, 适配算法的需要 通过Spark引擎衔接大数据和机器学习框架
11 .一句结论 Spark Mllib就是个玩具
12 .Spark MLlib自身的问题(1) 面向批处理 接口设计不合理 分布式实现带来的精度损失 无法有效的嵌入应用服务/流服务中 编程使用困难 同样的数据,特征, 比如SKlearn准确度会低
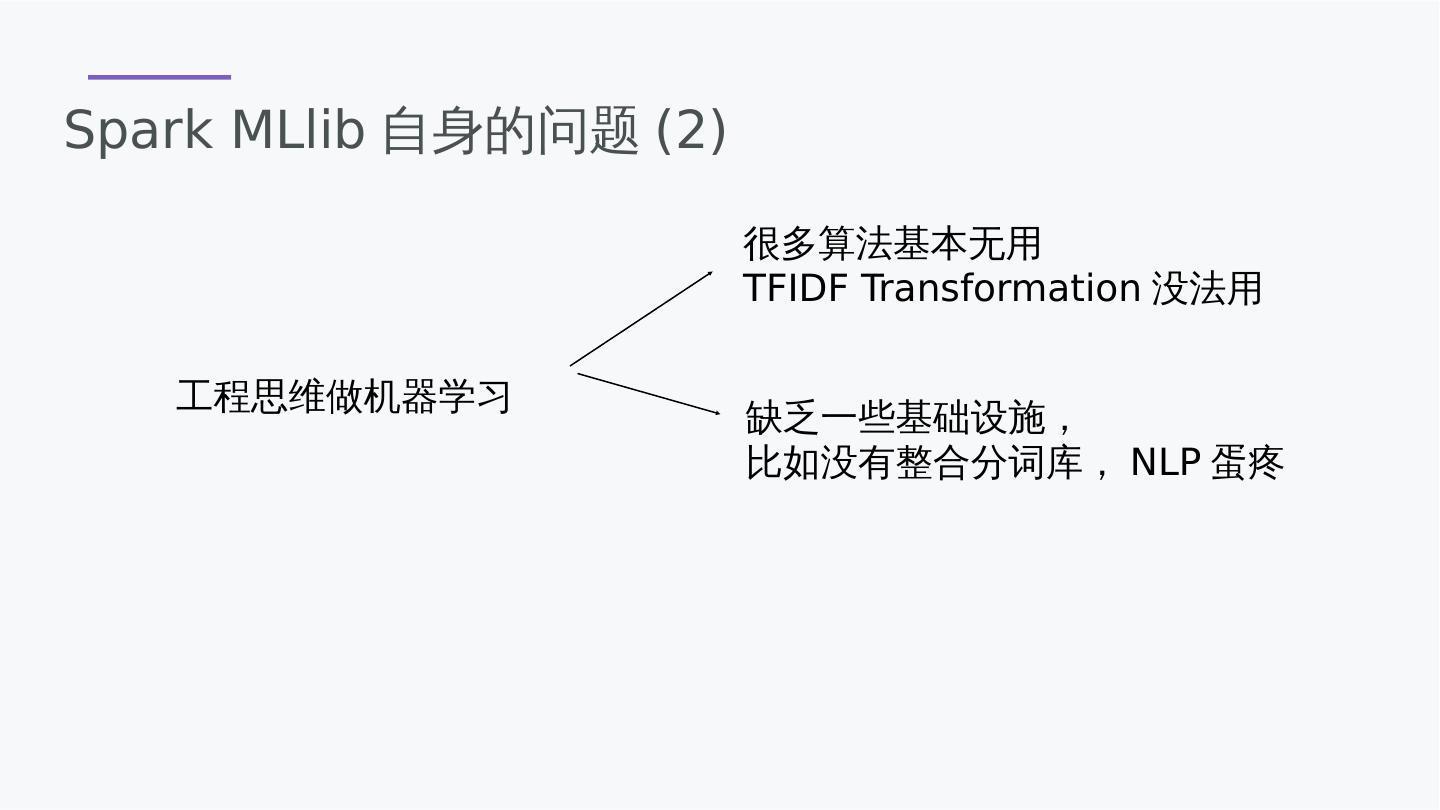
13 .Spark MLlib自身的问题(2) 工程思维做机器学习 很多算法基本无用 TFIDF Transformation没法用 缺乏一些基础设施, 比如没有整合分词库,NLP蛋疼
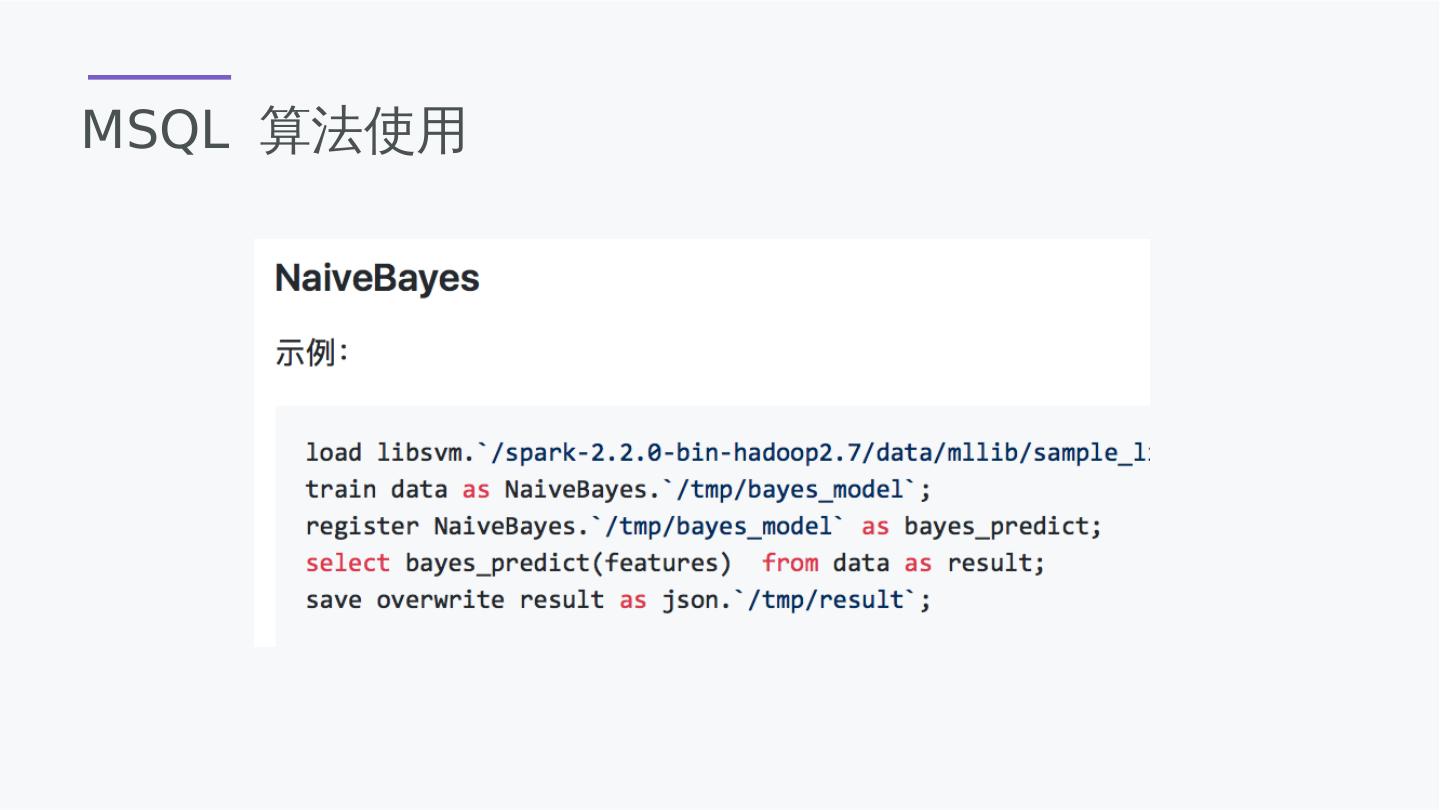
15 .MLSQL-LSTRP五步曲 Load 各种数据源 MySQL/ES/HBase/Parquet/Hive Select 通过多条简单SQL完成复杂数据关联,处理,聚合 Train 选择算法,对处理好的数据进行训练得到模型 Register 将模型注册为为UDF函数 使用SQL/UDF函数对数据进行预测,统计,效果评估
16 .一个较为复杂的例子 https://gist.github.com/allwefantasy/5aca641901e4af6822a99783d6ade65a
17 .MLSQL-额外 UDF大礼包: 向量操作 数组操作
18 .MLSQL-额外2 模型大礼包: 向量操作 数组操作 除了标准模型外, 用户可任意扩展自己的模型包, 扩充MLSQL功能
19 .MLSQL-底层算法框架支持 支持大部分Spark MLlib算法 支持CNN/FC 等对NLP的处理 支持部分算法 可以提交 自己的实现
22 .MSQL TensorFlow 自定义算法
23 .MSQL SKLearn 1 GradientBoostingClassifier 2 RandomForestClassifier 3 SVC 4 MultinomialNB
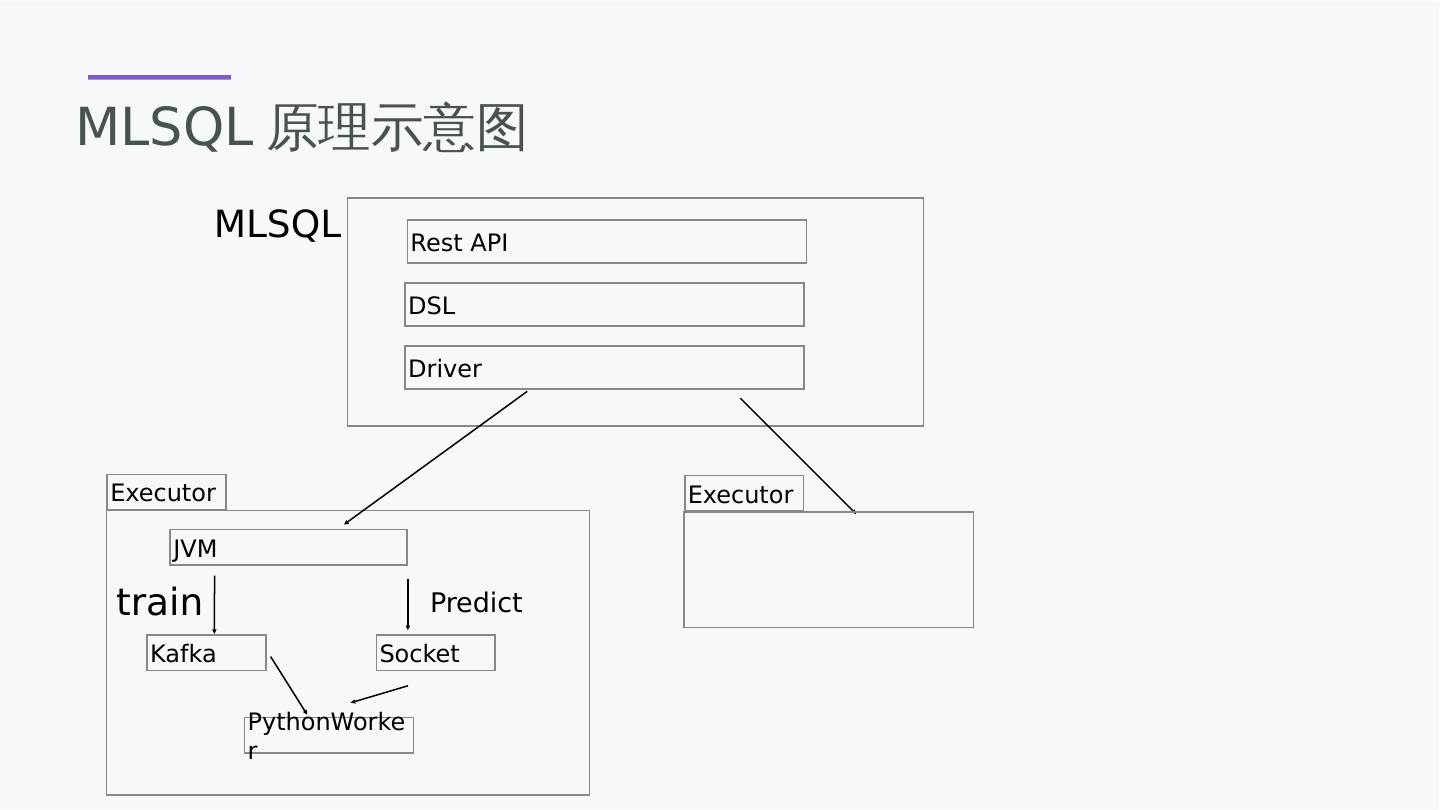
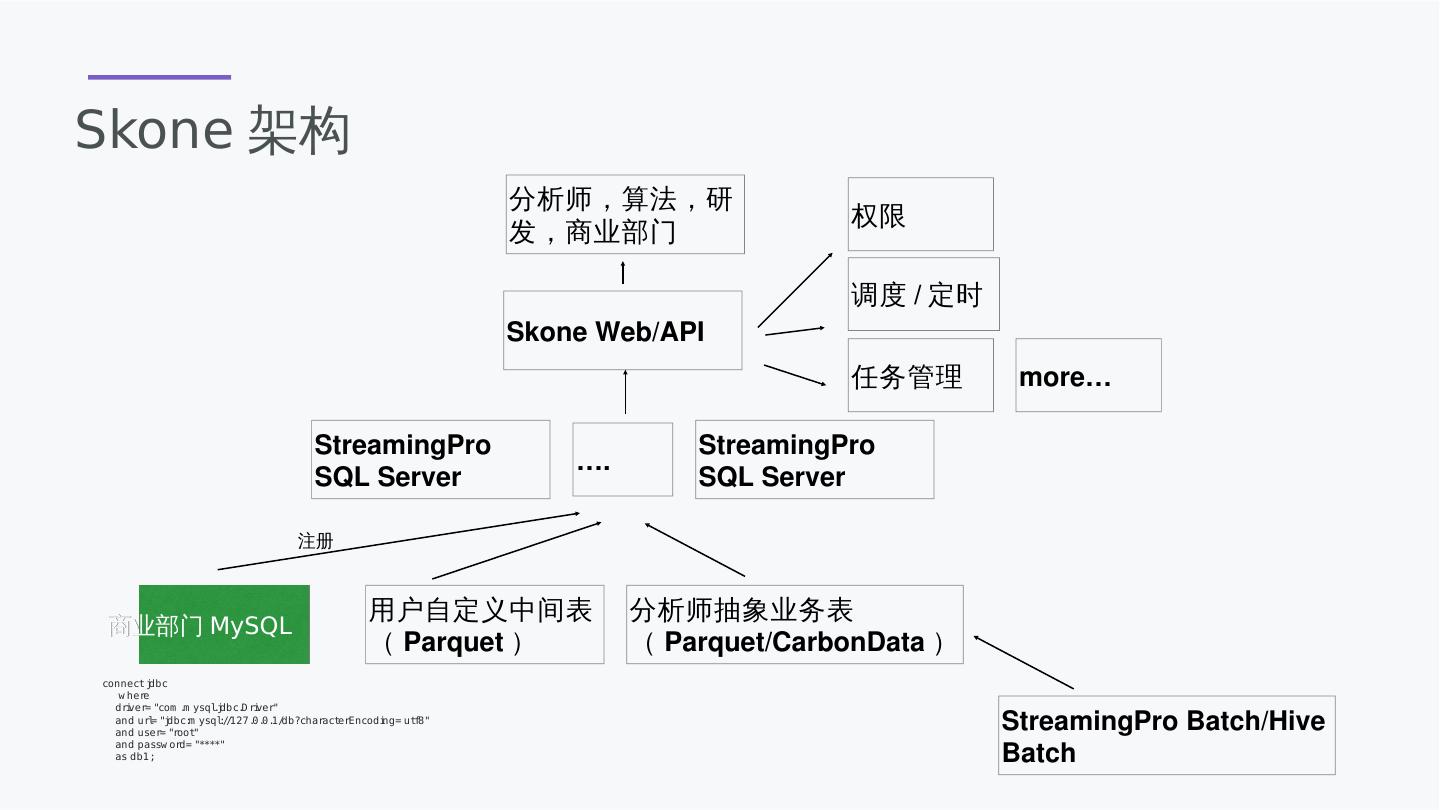
25 .MLSQL原理示意图 Rest API DSL Driver Executor JVM PythonWorker Executor train Kafka Predict Socket MLSQL
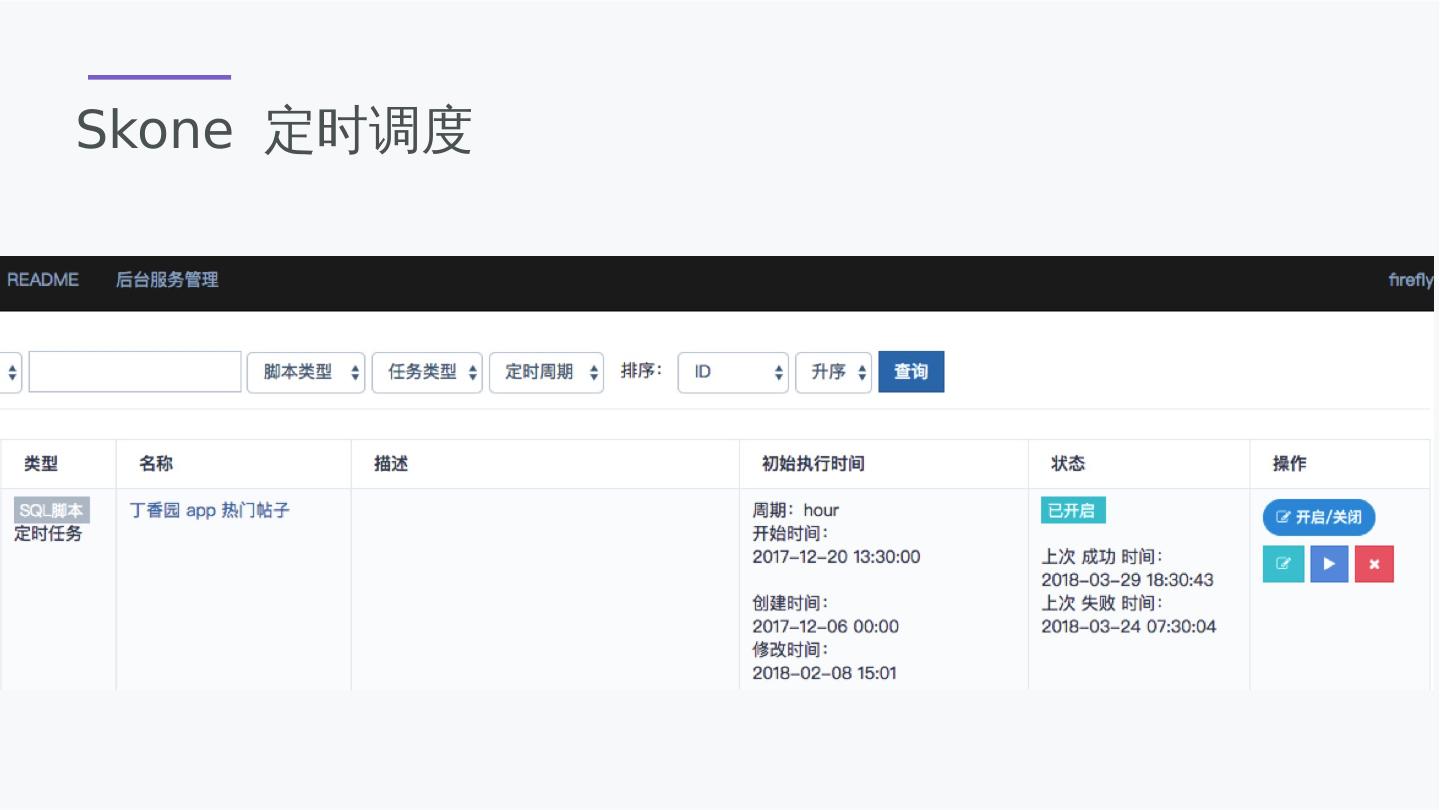
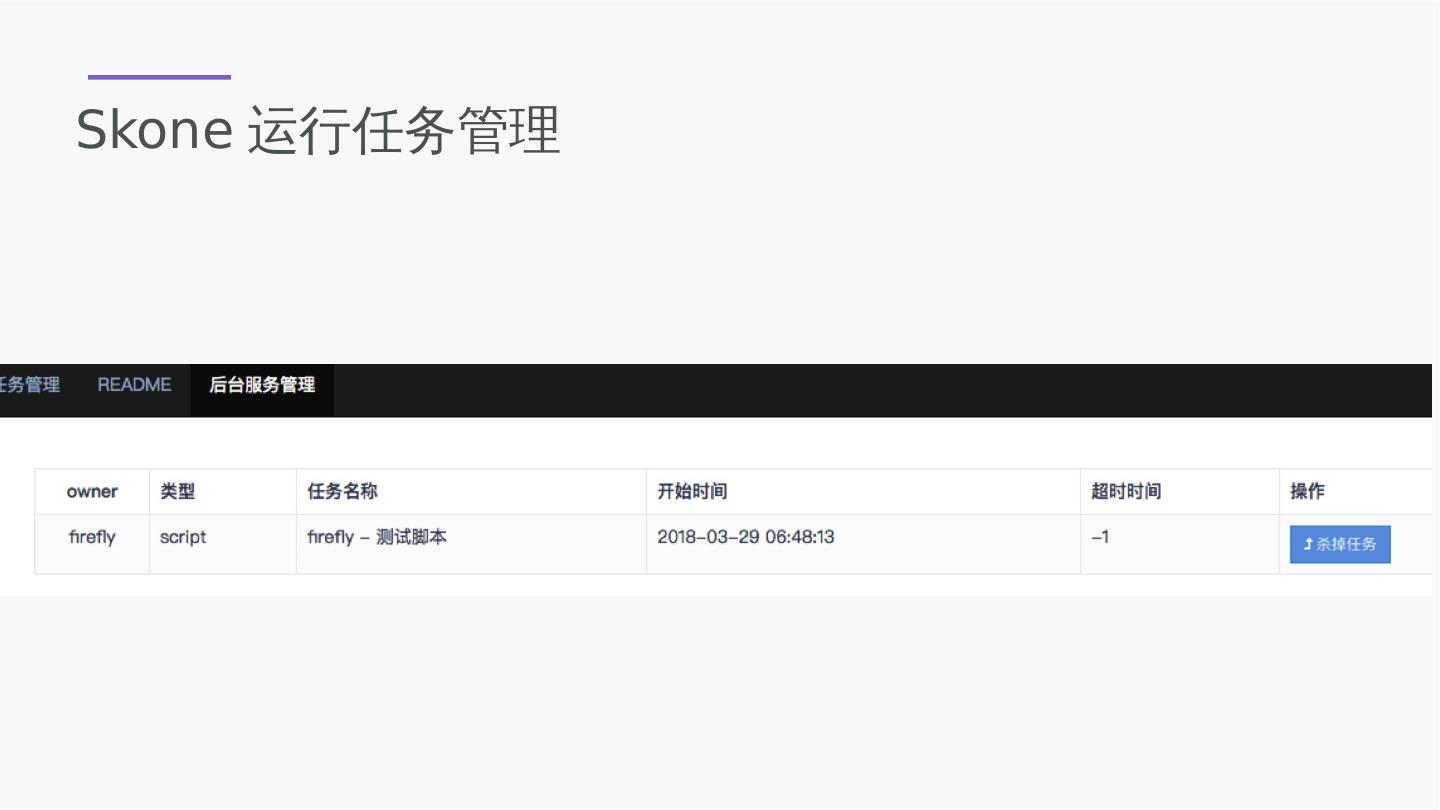
26 .对Spark的增强 除了thrifserver,还集成了Rest API 支持异步脚本执行,支持回调 支持脚本任务的超时设置和取消,有较为完整的任务管理 DSL增强的语法特性,可以通过set 语法设置变量 提供Driver 和 Executor的RPC通讯机制,可以读Spark进行通讯编程。
27 .训练为什么需要Kafka 数据要从多个节点汇总到一个节点,Spark不支持这种行为。 数据要反复消费 Kafka稳定吞吐高
28 .预测为什么不需要Kafka 预测是通过UDF函数,要求低延时 JVM/Python socket通讯高效 复用Spark 的Python worker机制
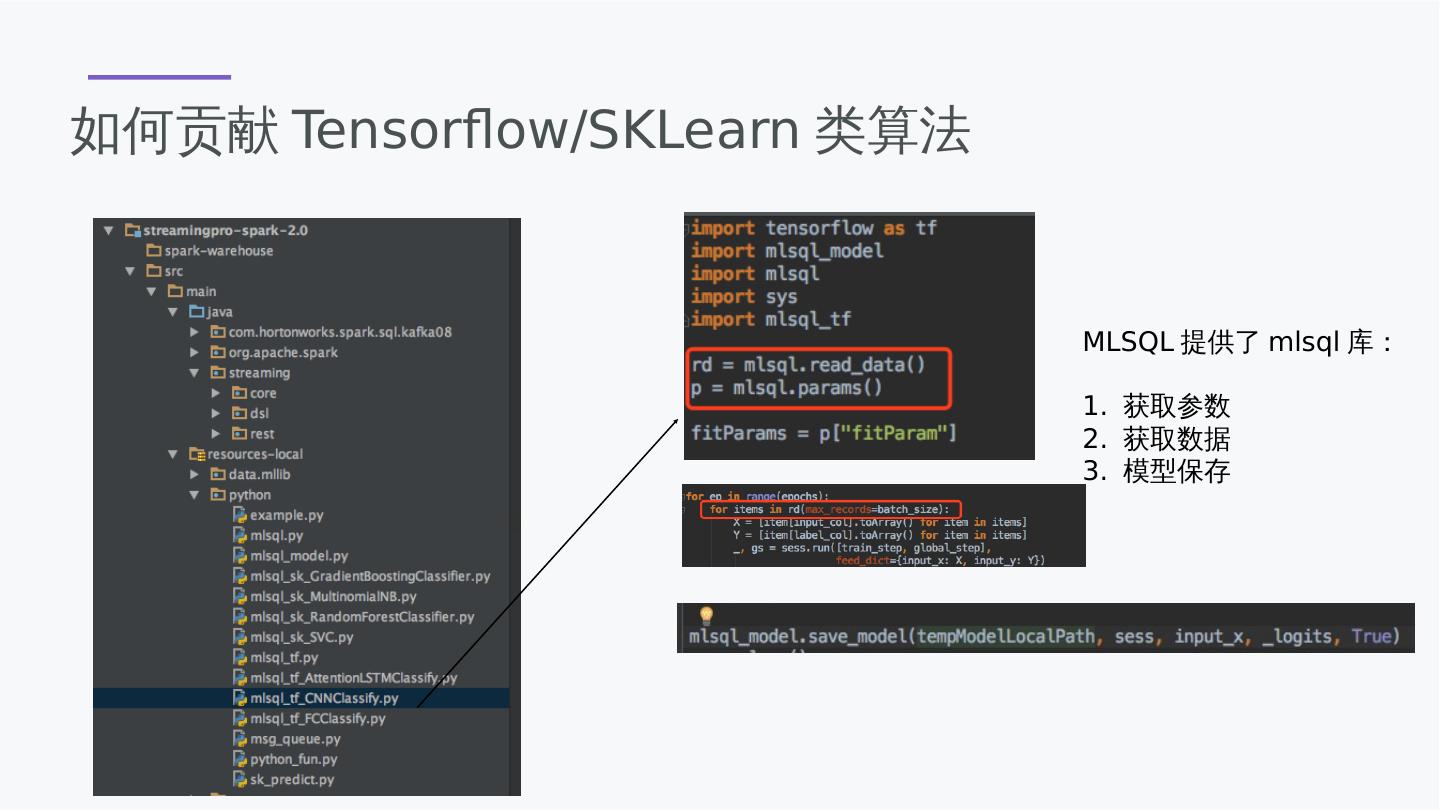
29 .如何贡献Tensorflow/SKLearn类算法 MLSQL提供了mlsql库: 1. 获取参数 2. 获取数据 3. 模型保存