Life is but a Stream
分享
点赞
20
收藏
2
下载 6
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
Life occurs in real-time, and not surprisingly, more solutions are being built using streaming technologies. Event-based architectures are becoming the norm, and customers are expecting immediate access to their data. This new world offers many exciting opportunities, but also some new challenges. What do you do when your streaming data is not complete? What if it relies on another data source? Does the dependent data exist yet, and does it come from a 3rd party? How do we merge a complete picture of data when data is sourcing from multiple places at the same time? A new norm in the world of distributed services. Join us as we dive deep into the technical details around these scenarios and more. Expect to learn about stream-stream joins, enriching stream data using local or remote data, and ways to anticipate and correct errors within the stream. Leave with a better understanding of managing data dependencies within a Spark Structured Streaming application.
展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Life is but a stream
Kevin Mellott, FIS, Director of Advanced Data Engine
Aaron Colcord, FIS, Sr. Director of Engineering
#UnifiedAnalytics #SparkAISummit
�
3 .A little Preview
• A Little Background on us.
• Our Influences
• A couple stories about the good times
• Some really good technical stuff
#UnifiedAnalytics #SparkAISummit 3
�
4 .Who is FIS Global?
• The Global leader in financial services
technology
• Ecosystem of products and services
built around core banking
• Customers: banks and credit unions
• FIS Digital One, Digital Data and
Analytics
#UnifiedAnalytics #SparkAISummit 4
�
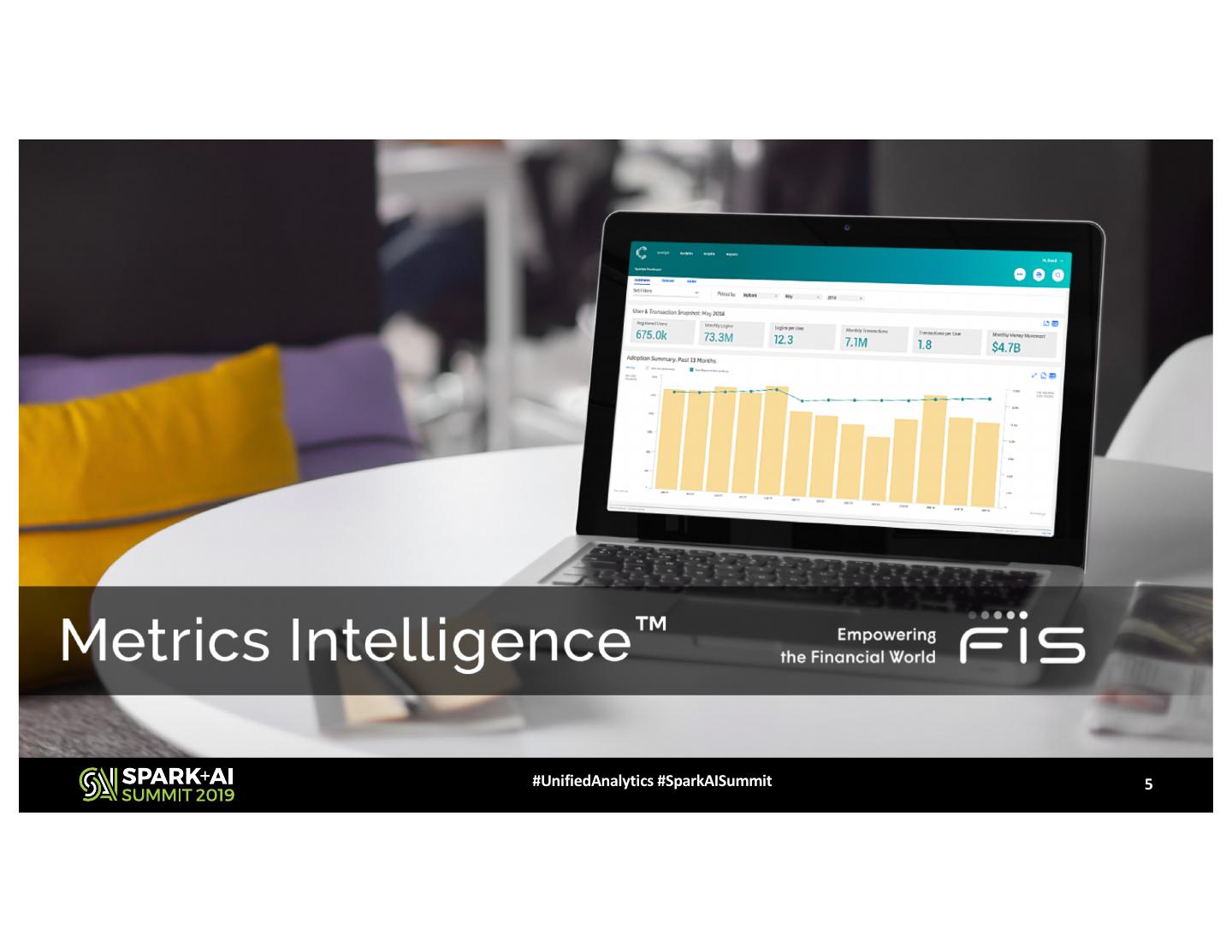
5 .#UnifiedAnalytics #SparkAISummit 5
�
6 .Core Problem of Data Transformation
• It is really hard to prove data transformed correctly
in a normal pipeline aka Batch-Oriented
• The traditional way has been to push data through
the system and then query it out
• Apache Spark can accelerate not only the speed you
transform,
but the speed in which you can validate transformations
• We can switch from Batch Oriented to Streaming (So let’s
do that)
#UnifiedAnalytics #SparkAISummit 6
�
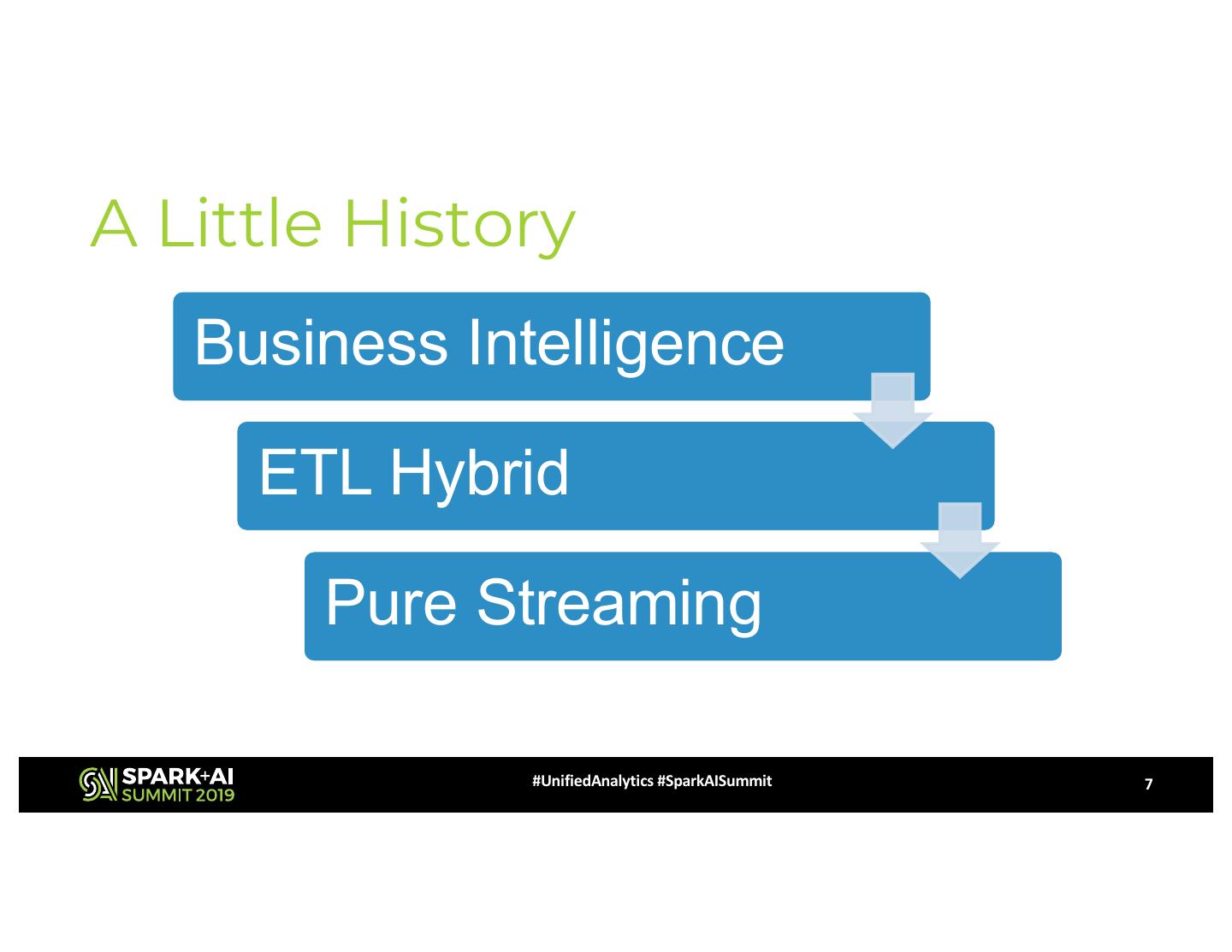
7 .A Little History
Business Intelligence
ETL Hybrid
Pure Streaming
#UnifiedAnalytics #SparkAISummit 7
�
8 .Why oh Why should we just stream?
• Lower overall costs around Data Availability
– i.e. Data has value when it’s there when needed, not later
• Build a great Scalable Infrastructure? Now use it?
• BI is still a thing, we can’t shake it. But we can turbocharge it!
• Let’s extend what we can do past just reporting. AI!
• Data Enrichment is even better, and gets better if you can do
it near-time.
#UnifiedAnalytics #SparkAISummit 8
�
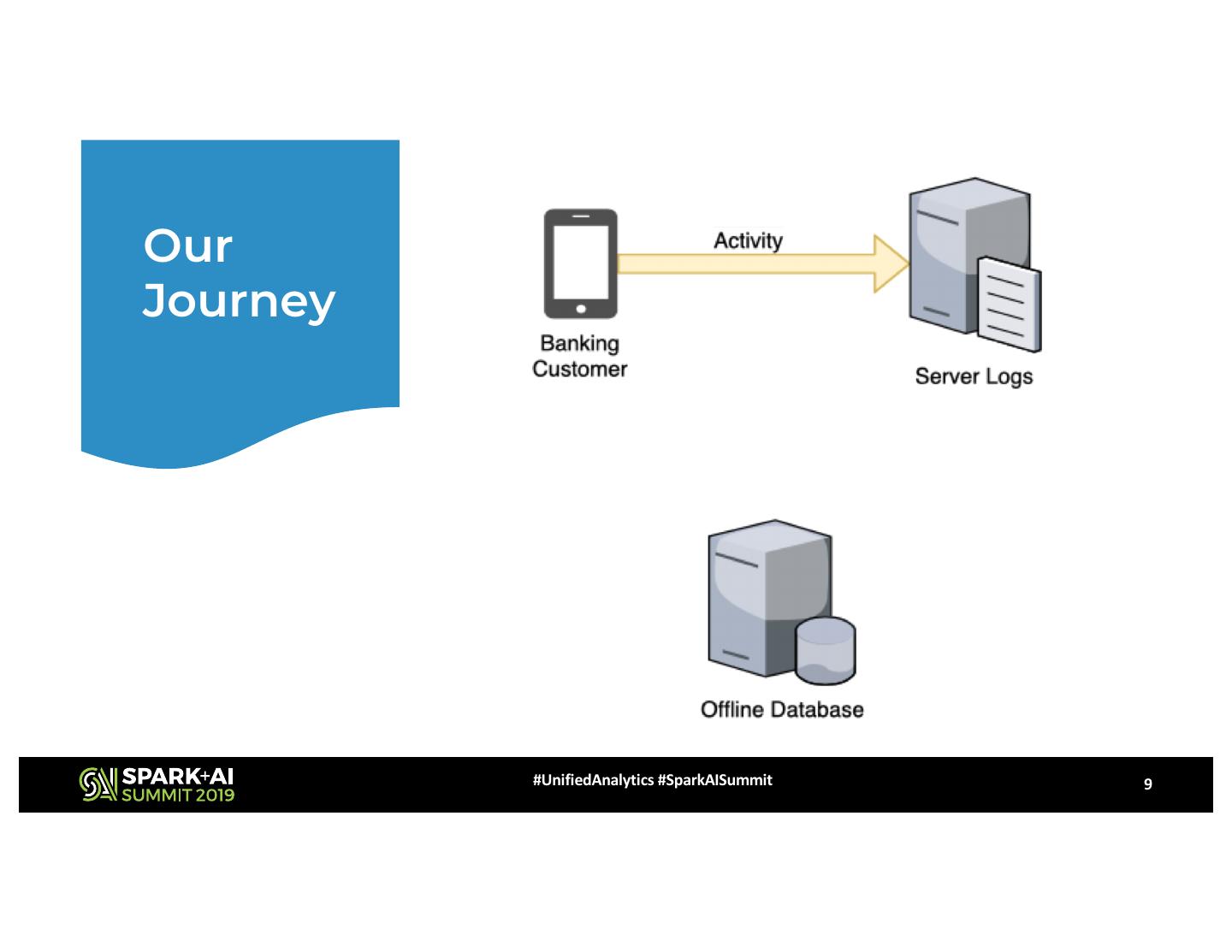
9 .Our
Journey
#UnifiedAnalytics #SparkAISummit 9
�
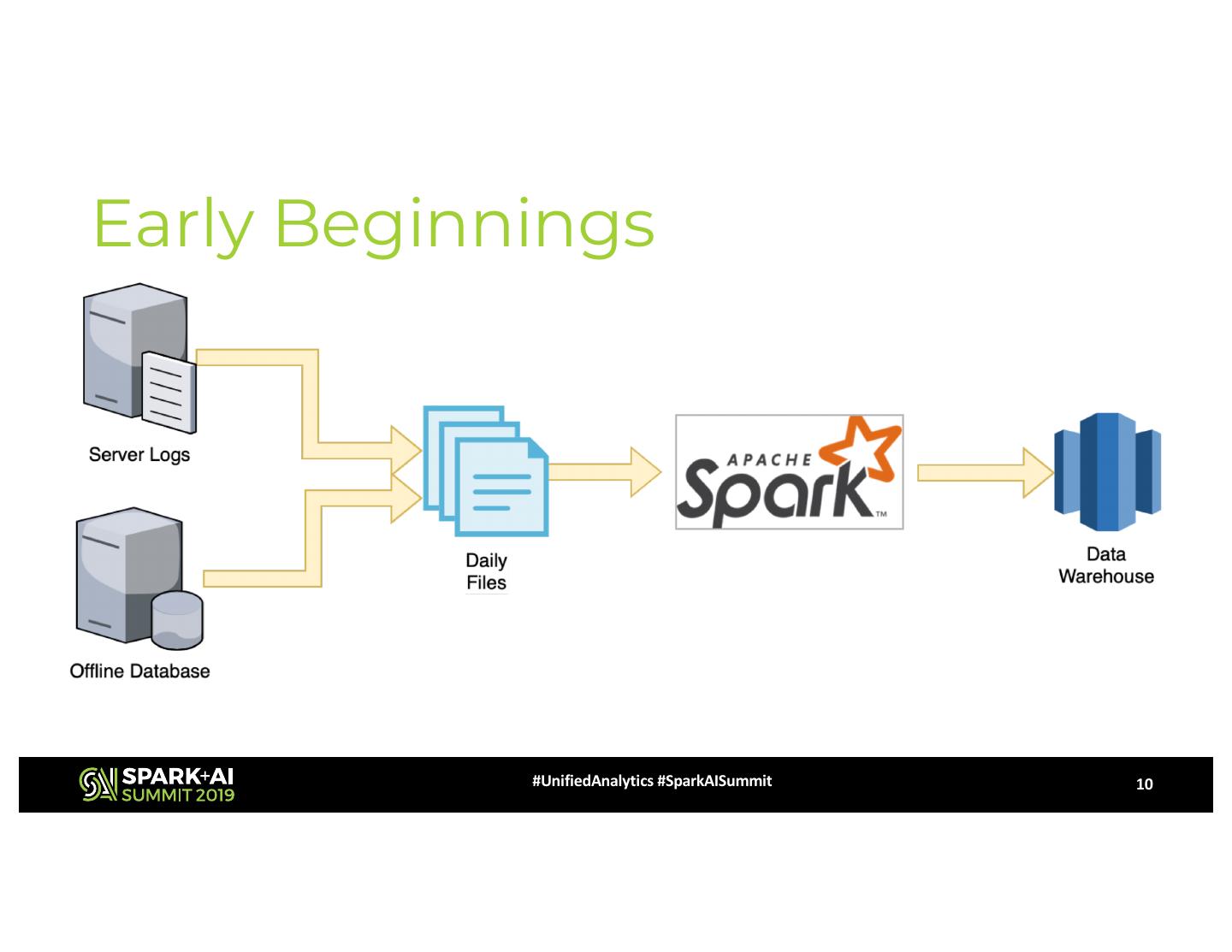
10 .Early Beginnings
#UnifiedAnalytics #SparkAISummit 10
�
11 .Batched Approach
• Pros
– Happy customers!
– Predictable compute
– Easy to reproduce
• Cons
– Delayed metrics
– Complex calculations
#UnifiedAnalytics #SparkAISummit 11
�
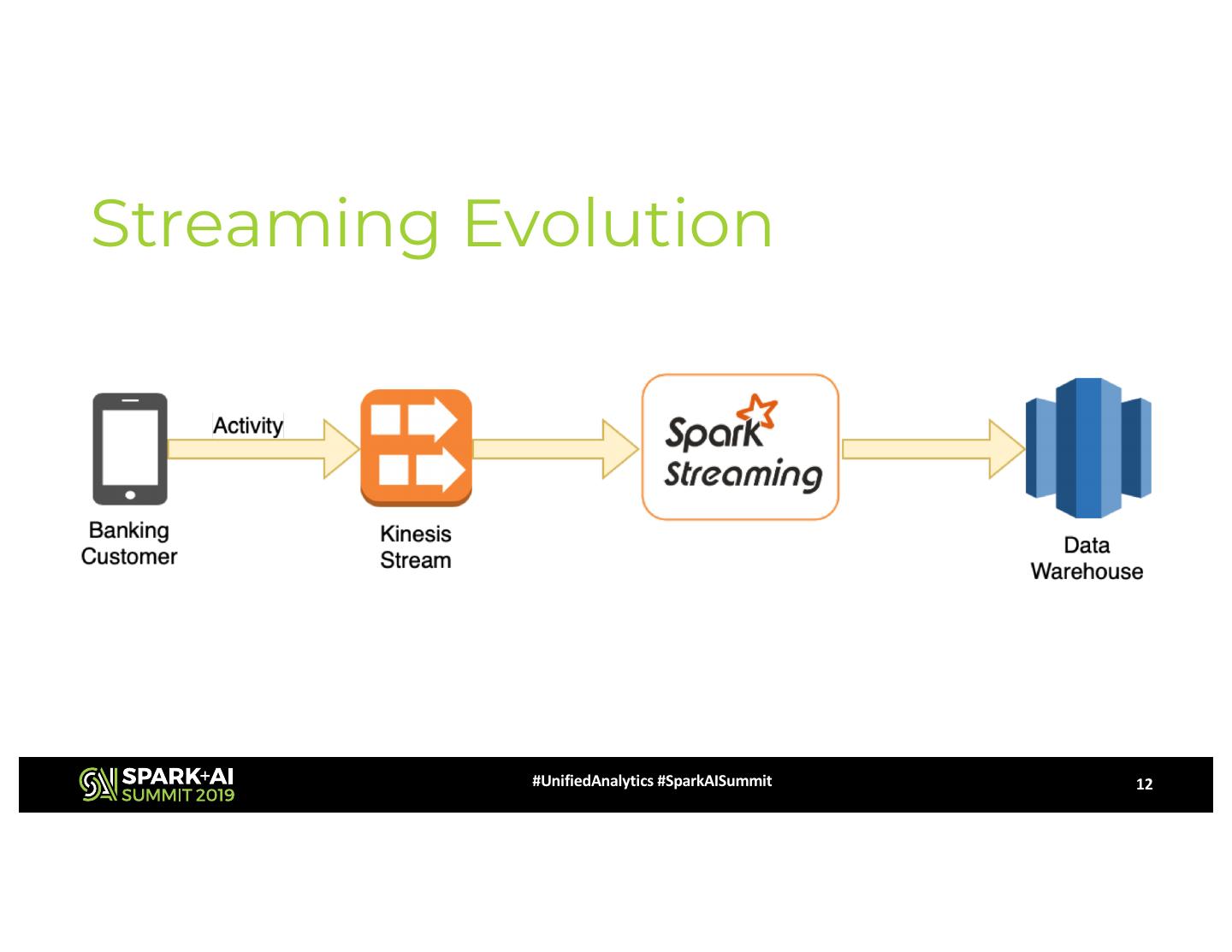
12 .Streaming Evolution
#UnifiedAnalytics #SparkAISummit 12
�
13 .Real-Time Approach
• Pros
– Understand the NOW
– Differentiating use cases
• Cons/challenges
– Performance monitoring
– Complex error conditions
– Data relationships
#UnifiedAnalytics #SparkAISummit 13
�
14 .Interactive Demo
SEC EDGAR
(batch vs stream)
https://github.com/KevinMellott91/
spark-summit-2019-demo
#UnifiedAnalytics #SparkAISummit 14
�
15 .Cheat Sheet
AVOID UNNECESSARY KEEP SCHEMA STATIC PLAN DOWNTIME
COMPLEXITY
#UnifiedAnalytics #SparkAISummit 15
�
16 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�