JindoFS 存储策略和读写优化
分享
点赞
5
收藏
4
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
展开查看详情
1 .JindoFS 存储策略和读写优化
7点开始
更多精彩分享,请访问《Apache Spark中国技术社区》
�
2 .JindoFS 存储策略和读写优化
阿⾥云智能 E-MapReduce 辰山
2020.6.11
�
3 .关于我
姚舜扬(花名:辰山)
计算平台事业部 E-MapReduce
从事大数据存储方面的开发和优化工作
EMR (E-MapReduce) https://www.aliyun.com/product/emapreduce
阿里云 E-MapReduce (EMR) 是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、
HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上使用开源技术建设数据仓库、离
线批处理、在线流式处理、即时查询、机器学习等场景下的大数据解决方案。
�
4 . 1 2 3 4
数据缓存场景 数据读写策 缓存数据管理 最佳实践
略及优化
�
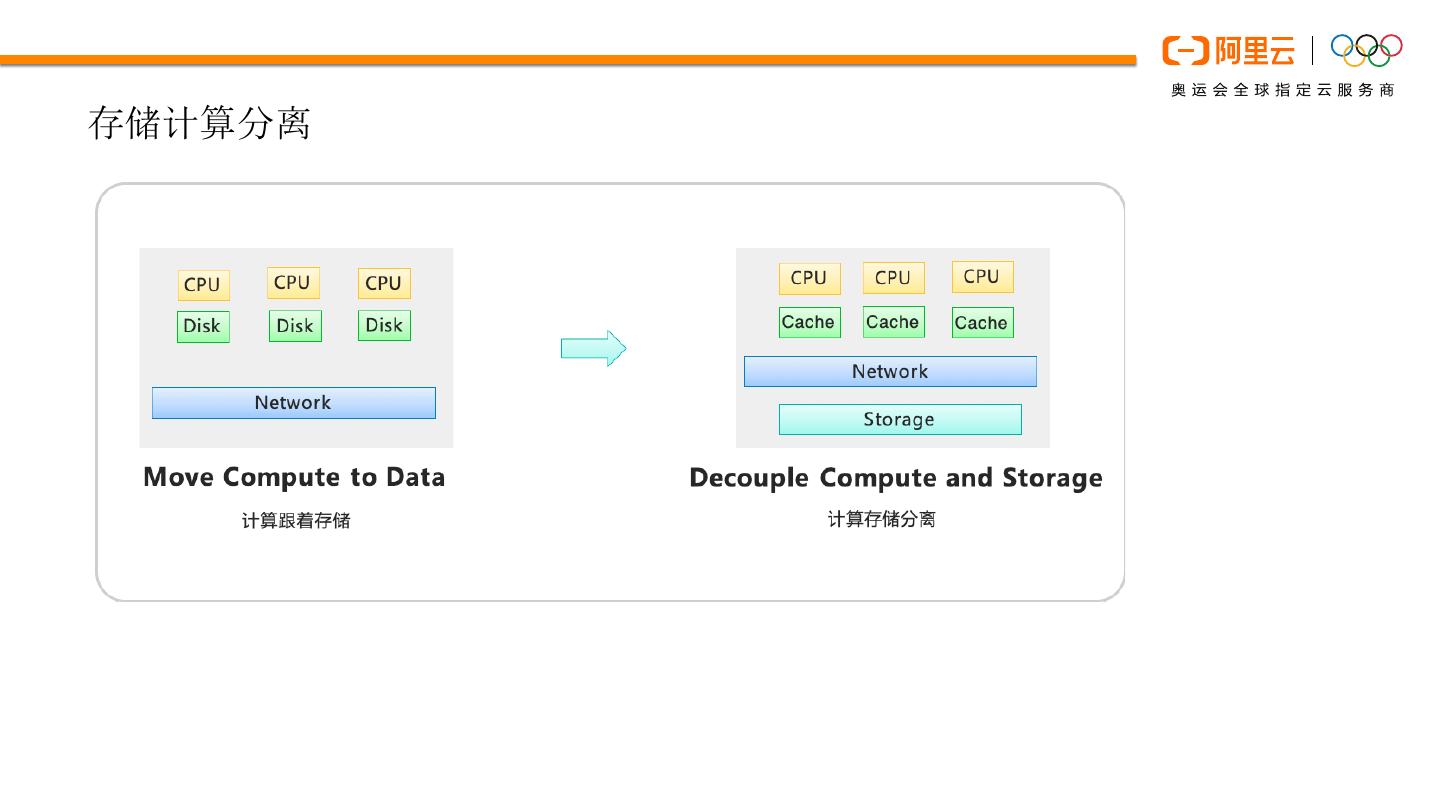
6 .JindoFS 缓存加速
• 云上数据湖场景,使用对象存储作为数
据湖存储后端
• 加速远端 HDFS (coming soon)
Ø 跨区部署的 HDFS
Ø 混合云场景,线上集群访问线下 HDFS 集群
�
7 . 1 2 3 4
数据缓存场景 数据读写策 缓存数据管理 最佳实践
略及优化
�
8 .数据缓存情况下的写策略
Node1 Node1
Client Client
1 1
Storage Service Storage Service
Local Storage
Block2
Block1 Block3
… OSS
2
OSS
�
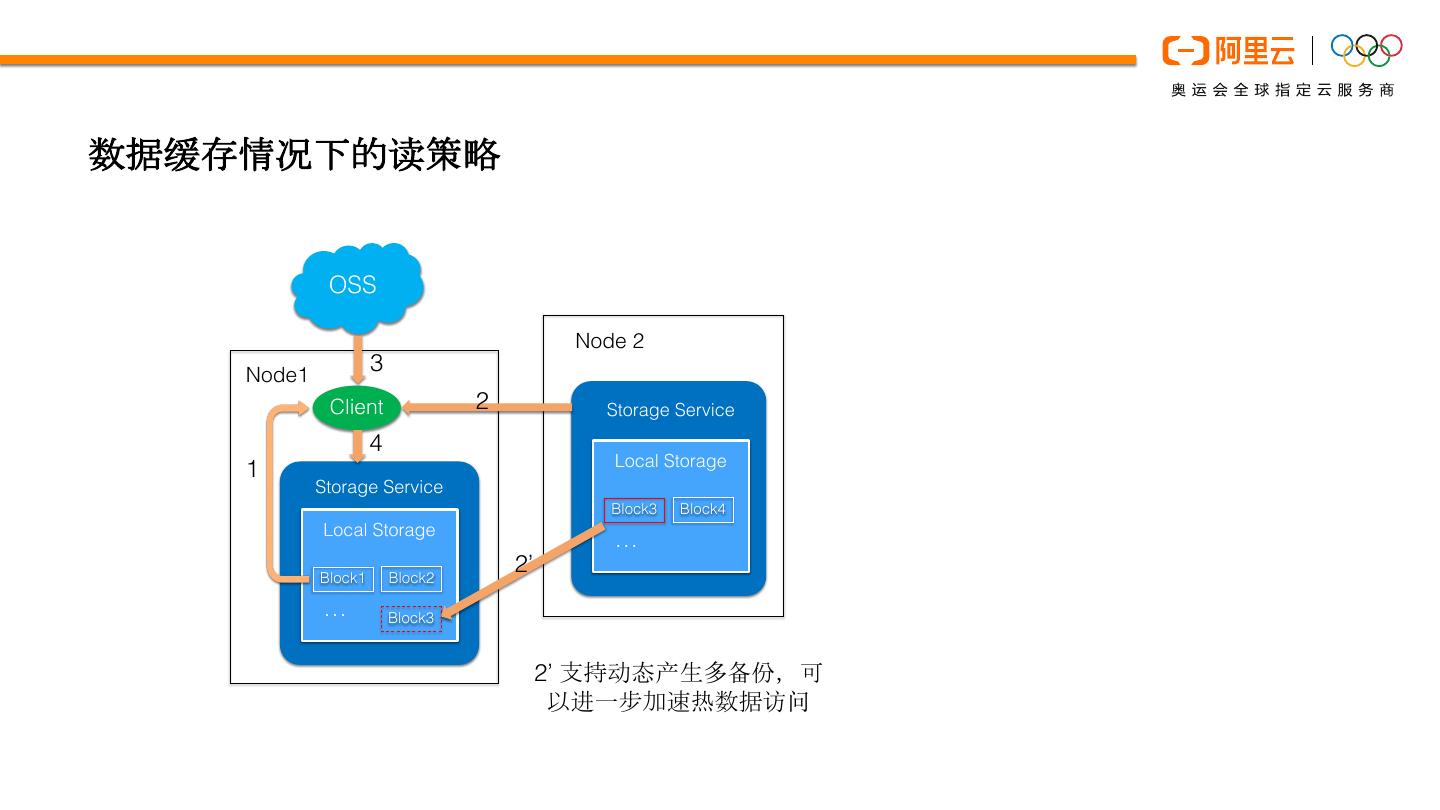
9 .数据缓存情况下的读策略
OSS
Node 2
Node1
3
Client 2 Storage Service
4
Local Storage
1
Storage Service
Block4
Block3 Block3
Local Storage
…
Block2
Block1 Block3
2’
… Block3
2’ 支持动态产生多备份,可
以进一步加速热数据访问
�
10 .Cache Locality
AppMaster
Node1 Node2
Task 1 Task 2 Task 3 Task 4
Block1 Block2 Block3 Block4 Block5 Block6 Block7 Block8
Block9
�
11 .JindoFS 使用
• 最新产品文档:
https://help.aliyun.com/document_detail/164207.html?spm=a2c4g.11186623.6.1086.7d626834TyEdsM
• 基本使用模式:
Block 模式
JindoFS 不开启缓存
(纯OSS客户端)
Cache 模式
开启缓存
• 数据缓存演示
�
12 . 1 2 3 4
数据缓存场景 数据读写策 缓存数据管理 最佳实践
略及优化
�
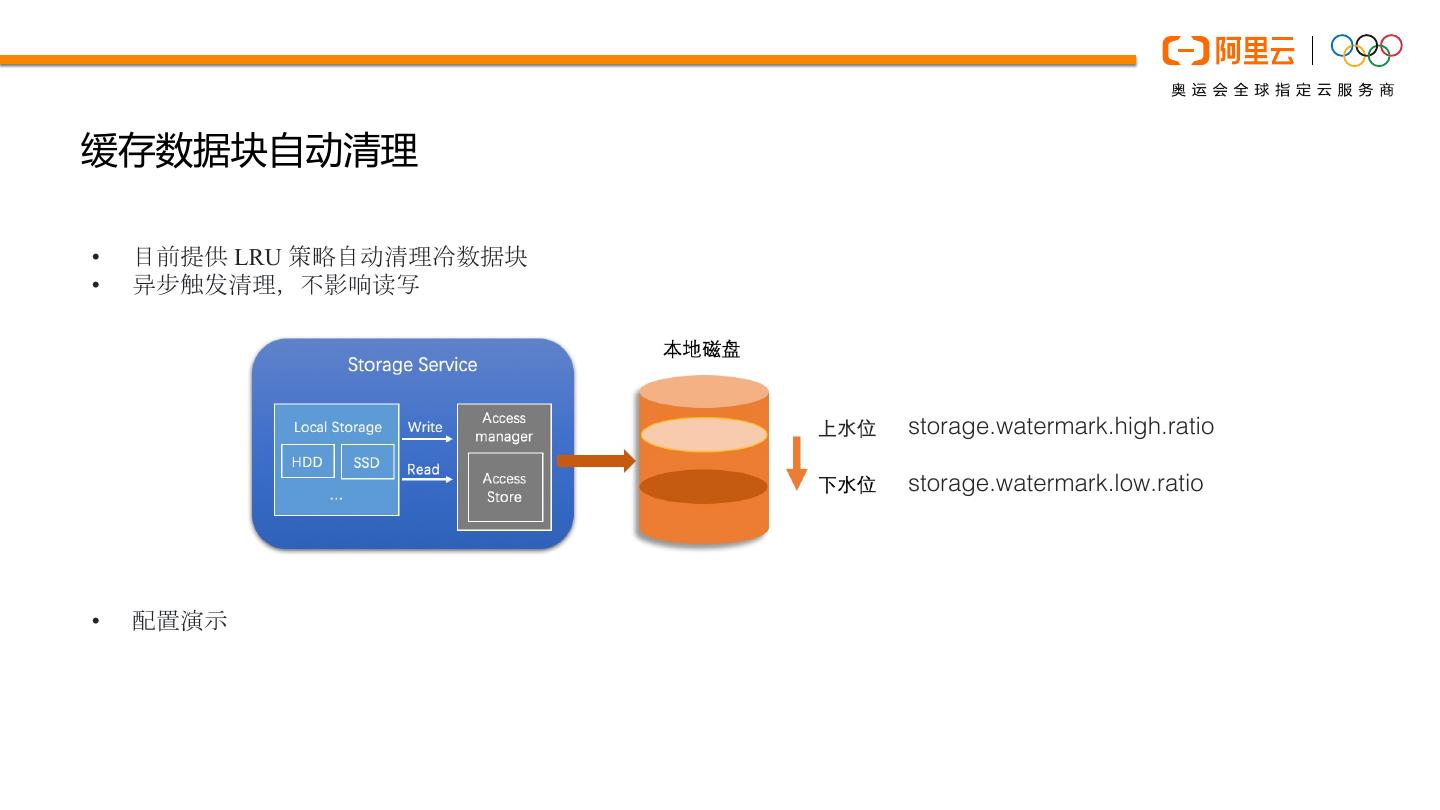
13 .缓存数据块自动清理
• 目前提供 LRU 策略自动清理冷数据块
• 异步触发清理,不影响读写
storage.watermark.high.ratio
storage.watermark.low.ratio
• 配置演示
�
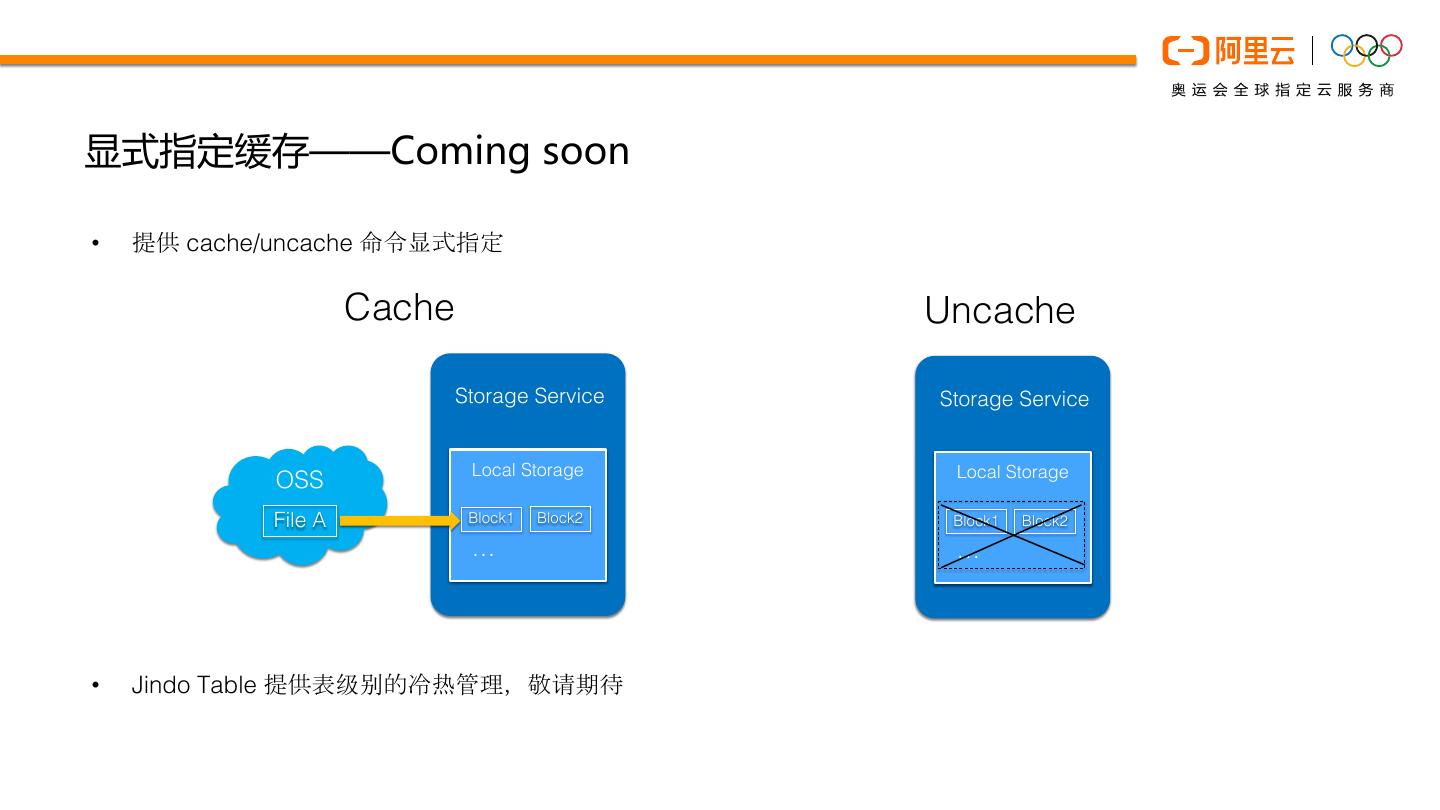
14 .显式指定缓存——Coming soon
• 提供 cache/uncache 命令显式指定
Cache Uncache
Storage Service Storage Service
Local Storage Local Storage
OSS
File A Block1 Block2 Block1 Block2
… …
• Jindo Table 提供表级别的冷热管理,敬请期待
�
15 . 1 2 3 4
数据缓存场景 数据读写策 缓存数据管理 最佳实践
略及优化
�
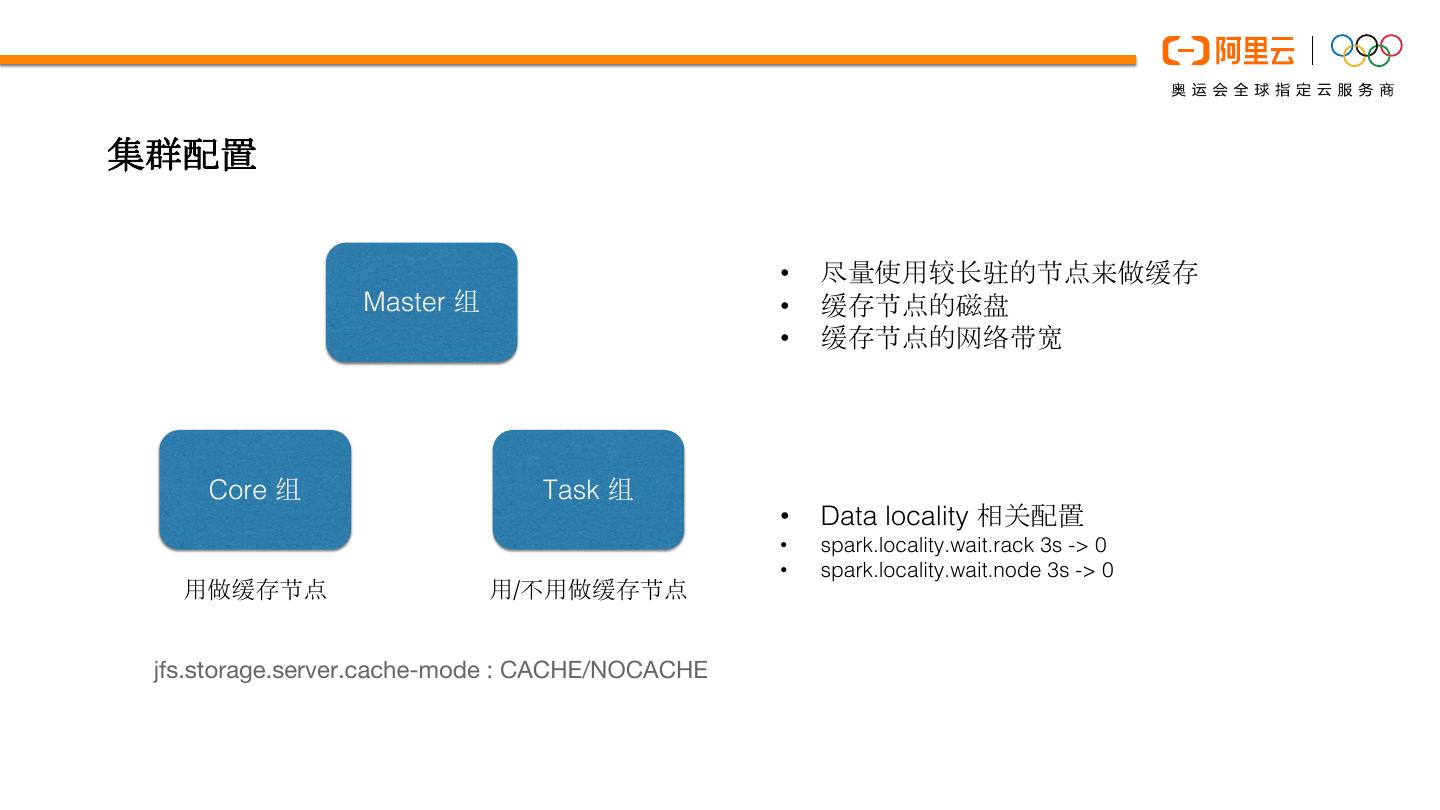
16 .集群配置
• 尽量使用较长驻的节点来做缓存
Master 组 • 缓存节点的磁盘
• 缓存节点的网络带宽
Core 组 Task 组
• Data locality 相关配置
• spark.locality.wait.rack 3s -> 0
• spark.locality.wait.node 3s -> 0
用做缓存节点 用/不用做缓存节点
jfs.storage.server.cache-mode : CACHE/NOCACHE
�
17 .更多精彩分享,请访问《Apache Spark中国技术社区》
�