




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Hive as a service
Hive作为数据仓库的核心,其元数据管理已经成为大数据领域事实上的标准,各种大数据处理引擎都尝试对其兼容,本文描述社区如何讲Hive服务以及Hive MetaStore服务独立处理,并支持各种权限验证功能。
展开查看详情
1 .Hive as a service Strata Data Conference March 8 th 2018 Szehon Ho Pawel Szostek Staff Software Engineer , Criteo Apache Hive Committer , PMC Senior Software Engineer , Criteo
2 .About this presentation Plan of this presentation: What is Criteo ? Key figures about our business Hive architecture yesterday vs. today Load Balancing, MySQL + Galera considerations Monitoring and alerting Kerberos Benchmarking Uses in Criteo
3 .Criteo – quest-ce que cest ? Criteo is the biggest tech company you never heard of.
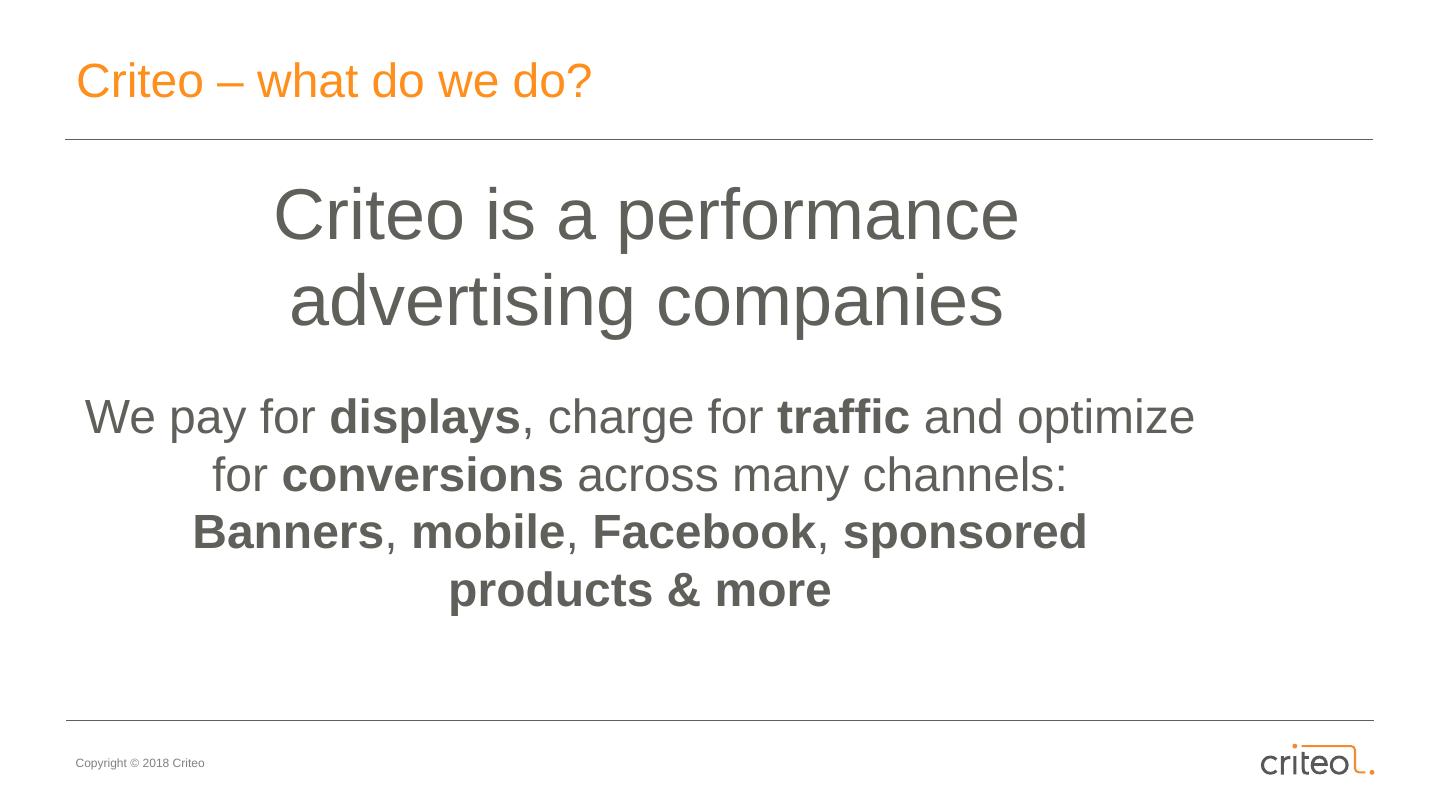
4 .Criteo – what do we do? Criteo is a performance advertising companies We pay for displays , charge for traffic and optimize for conversions across many channels: Banners , mobile , Facebook , sponsored products & more
5 .Criteo – what do we do? Yes, this is us (sorry) https:// info.criteo.com /privacy/ informations?infonorm =3&partner=844&campaignid=48508&zoneid=180208&bannerid=8591434&displayid=76c74aae19&uaCap=0&aid=DPHilnwvNHczOGhpV0ZlaGc4WE1OdWh3VS8zbC9zbVhiLzJBR3pncWxDT0JzaXJjPXw=&u=|QU8F43nlPHdKAiWLUh/X0ZxHlgcj0wSTBN5tY0acwzc=|
6 .Scale of Criteo 18,000 + analytics jobs a day 14PB+ analytics data a day 200 + analysts 600+ engineers 1000+ sales and ops 30 + offices 7 DCs 15 PoPs 3000+ Hadoop nodes ~60k YARN cores 600TB ingested a day in Hadoop 220PB+ raw storage 1.2 billion unique users per month
7 .Scale of our rooftop
8 .Our analytics stack Structured Data Access Data warehousing Data transformation Primary storage v
9 .Hive Overview Hive provides a SQL interface on top of HDFS Hive Metastore allows mapping database structures (database, table, partition, column) to HDFS directories and files Hive engine (CLI or HiveServer2) parses SQL -> query execution by Hadoop jobs (MapReduce, Spark, Tez ) Both components need scale-out to handle increasing load o add text
10 .History of Hive in Criteo Drawbacks of the old setup: Recipes hard to maintain Version Bump Decouple HMS and database Long release process Time-consuming to provision new machines New Direction: Mesos/Marathon Specify jar and configuration file Specify CPU, mem, number of instances => Easy to scale Deploying different Hive versions Auto-healing (health check, restart) HS2 (centralized query execution) Provide access without relying on Hive CLI Boost monitoring capabilities Pool resources provide JDBC access
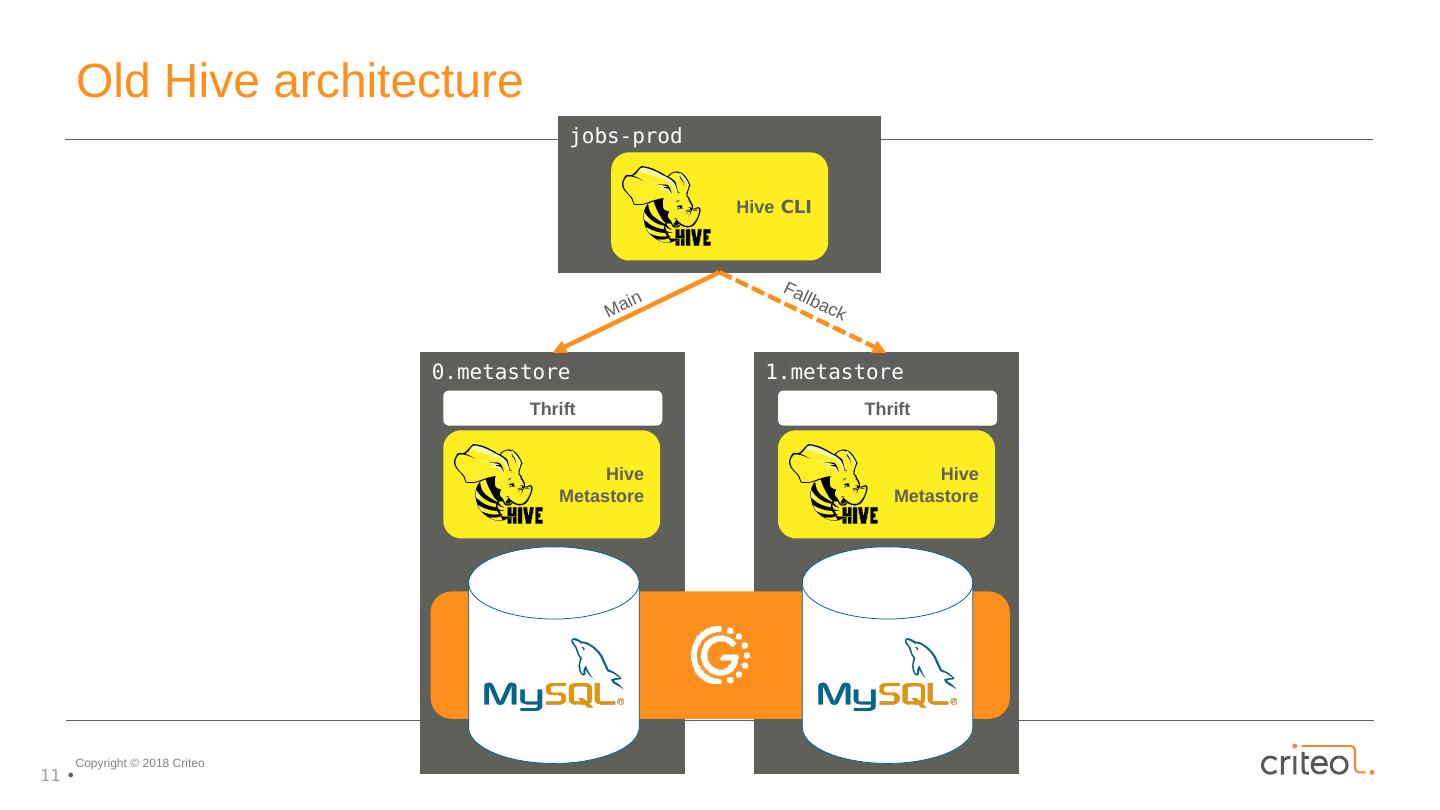
11 .1.metastore 0.metastore jobs- prod Hive Metastore Thrift Hive CLI Main Fallback Hive Metastore Thrift Old Hive architecture
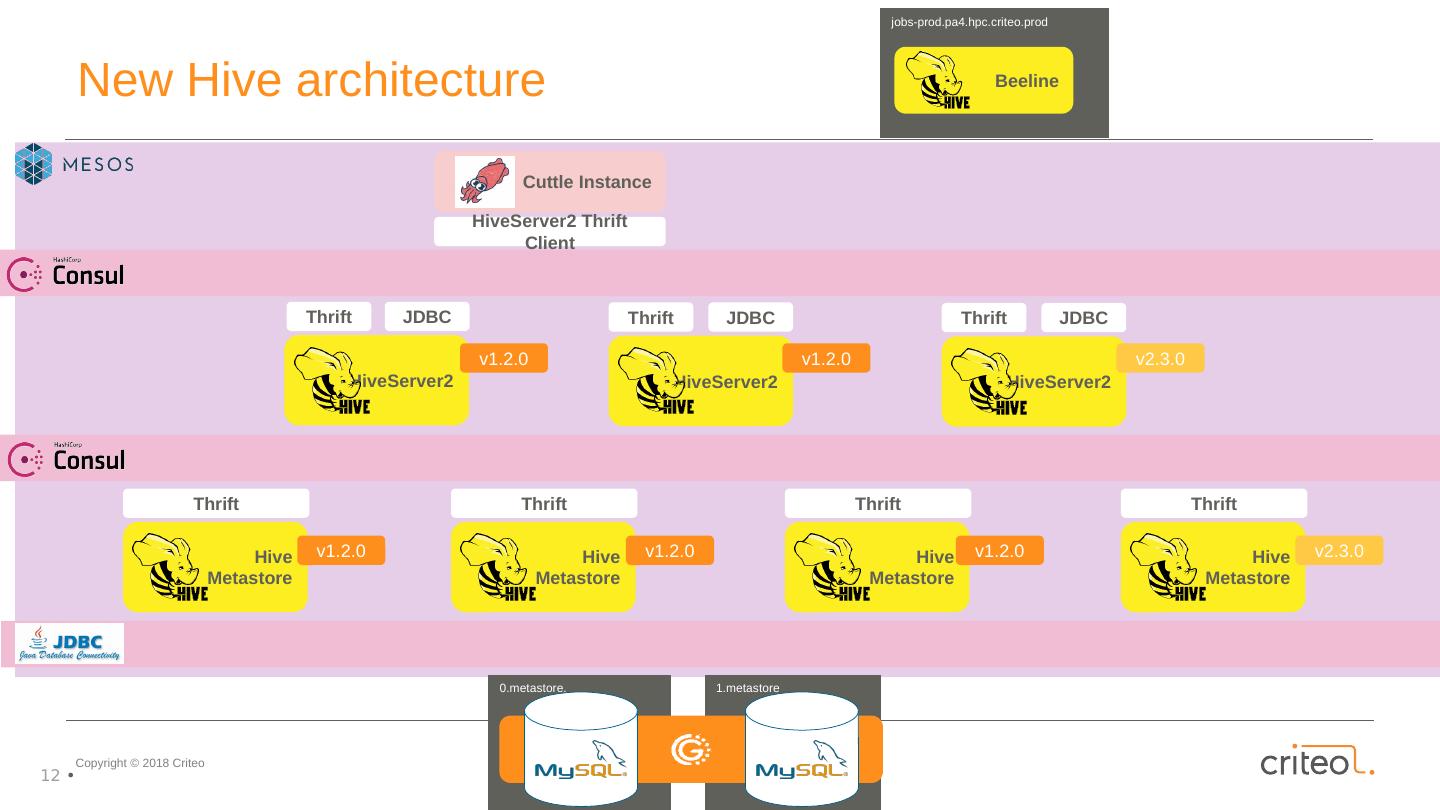
12 .Hive Metastore Thrift Hive Metastore Thrift Hive Metastore Thrift Hive Metastore Thrift HiveServer2 Thrift JDBC HiveServer2 Thrift JDBC HiveServer2 Thrift JDBC HiveServer2 Thrift Client Cuttle Instance jobs-prod.pa4.hpc.criteo.prod Beeline v1.2.0 v1.2.0 v1.2.0 v1.2.0 v2.3.0 v1.2.0 v2.3.0 New Hive architecture 1.metastore 0.metastore.
13 .Load-Balancing 3. MySQL 1 . HiveServer2 2. Metastore 0 .metastore 1 .metastore HiveServer2 HiveServer2 Hive Metastore Hive Metastore jobs-user Beeline Jobs-prod HiveServer2 Thrift Client Cuttle Instance HiveServer2 Hive Metastore Hive Metastore HiveServer2
14 .M Metastore → N MySQL Galera Marketing : "Multi-master synchronous replication" Broadcasts transaction sets to all the nodes Galera in Practice: Write only to one master or risk deadlocks. Reads are also not always synchronous In Criteo Three instances JDBC fallback string (instead of a DNS RR): " jdbc:mysql ://0.mysql.machine:3306,1.mysql.machine:3306,2.mysql.machine:3306/ metastore "
15 .Load Balancing on Mesos An open-source scalable service-discovery and KV store Criteo Marathon registered automatically with Consul: Marathon health status Host, ports curl - s " http ://localhost:8500/v1/ health / service / hive-metastore ?passing&dc =pa4" | jq [ { " Node ": { " Node ": "mesos-node001.criteo.prod", " Address ": "10.200.0.2", " Datacenter ": "pa4", }, " Checks ": [ { " Node ": " mesos - node001.criteo.prod ", " Name ": " Serf Health Status ", " Status ": " passing ", }, # more checks ... ] }, # more nodes ... ]
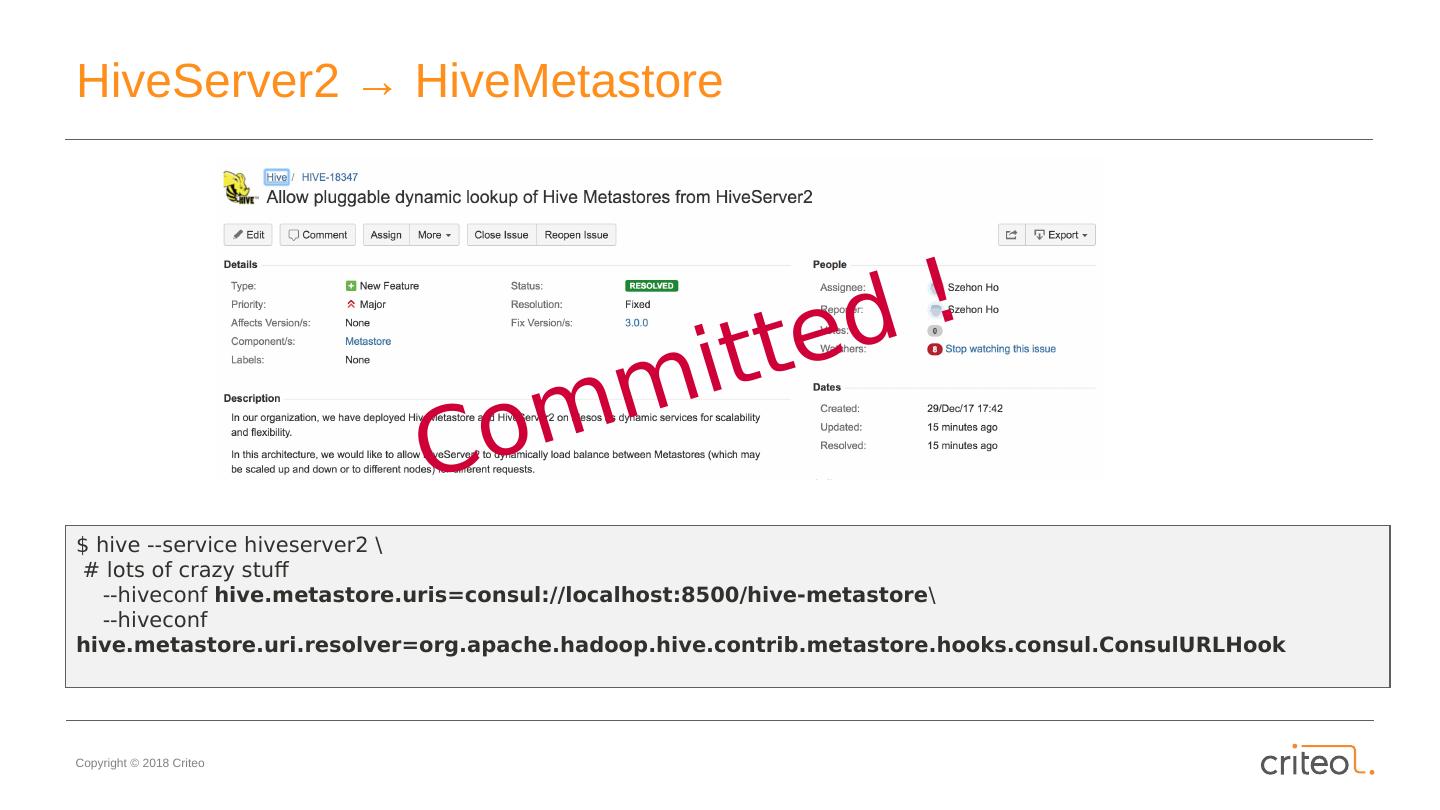
16 .HiveServer2 → HiveMetastore $ hive --service hiveserver2 \ # lots of crazy stuff -- hiveconf hive.metastore.uris =consul://localhost:8500/hive-metastore \ -- hiveconf hive.metastore.uri.resolver =org.apache.hadoop.hive.contrib.metastore.hooks.consul.ConsulURLHook Committed !
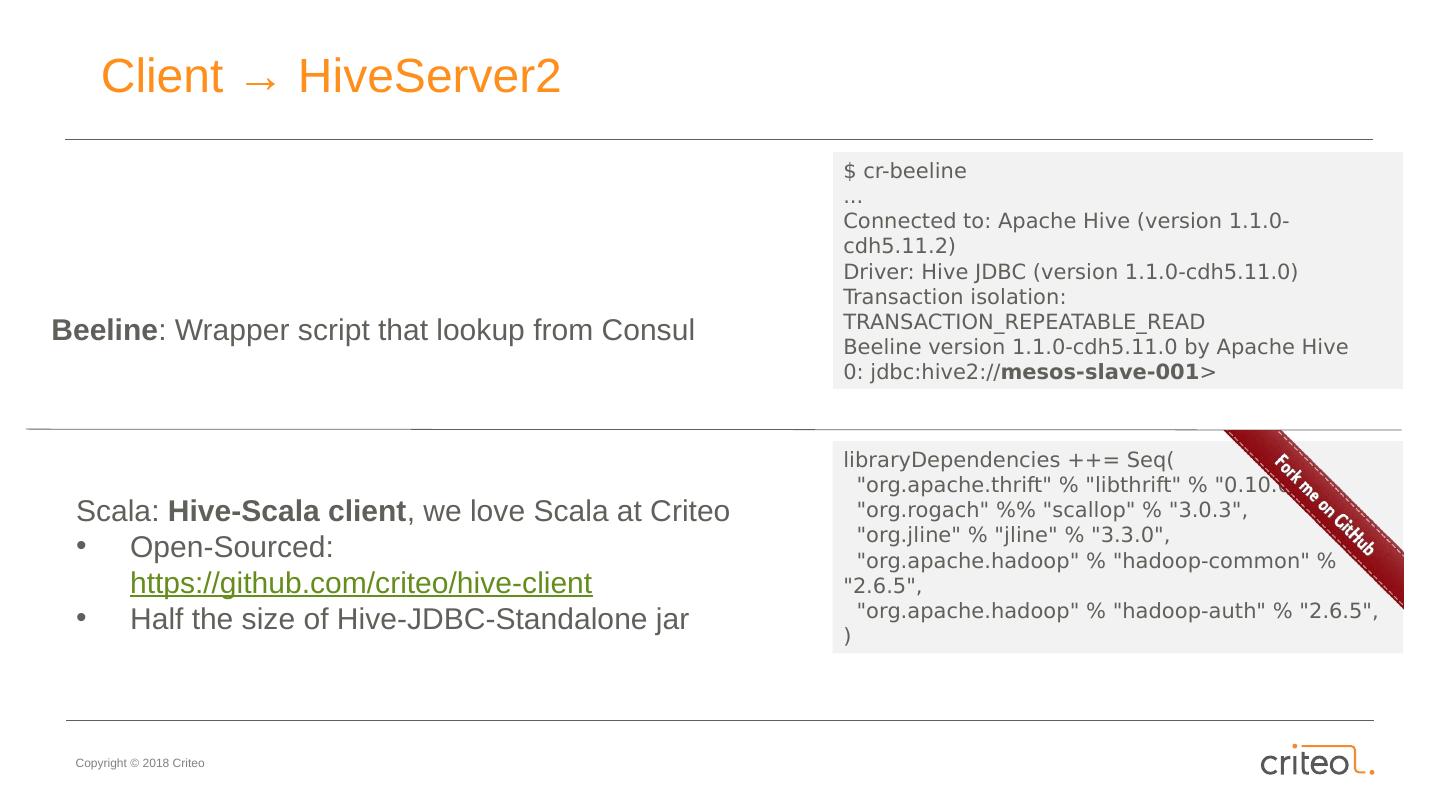
17 .Client → HiveServer2 Beeline : Wrapper script that lookup from Consul Scala: Hive-Scala client , we love Scala at Criteo Open-Sourced: https://github.com/criteo/hive-client Half the size of Hive-JDBC-Standalone jar libraryDependencies ++= Seq ( " org.apache.thrift " % " libthrift " % "0.10.0", " org.rogach " %% "scallop" % "3.0.3", " org.jline " % " jline " % "3.3.0", " org.apache.hadoop " % " hadoop -common" % "2.6.5", " org.apache.hadoop " % " hadoop-auth " % "2.6.5", ) $ cr-beeline ... Connected to: Apache Hive (version 1.1.0-cdh5.11.2) Driver: Hive JDBC (version 1.1.0-cdh5.11.0) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 1.1.0-cdh5.11.0 by Apache Hive 0: jdbc:hive2:// mesos-slave-001 >
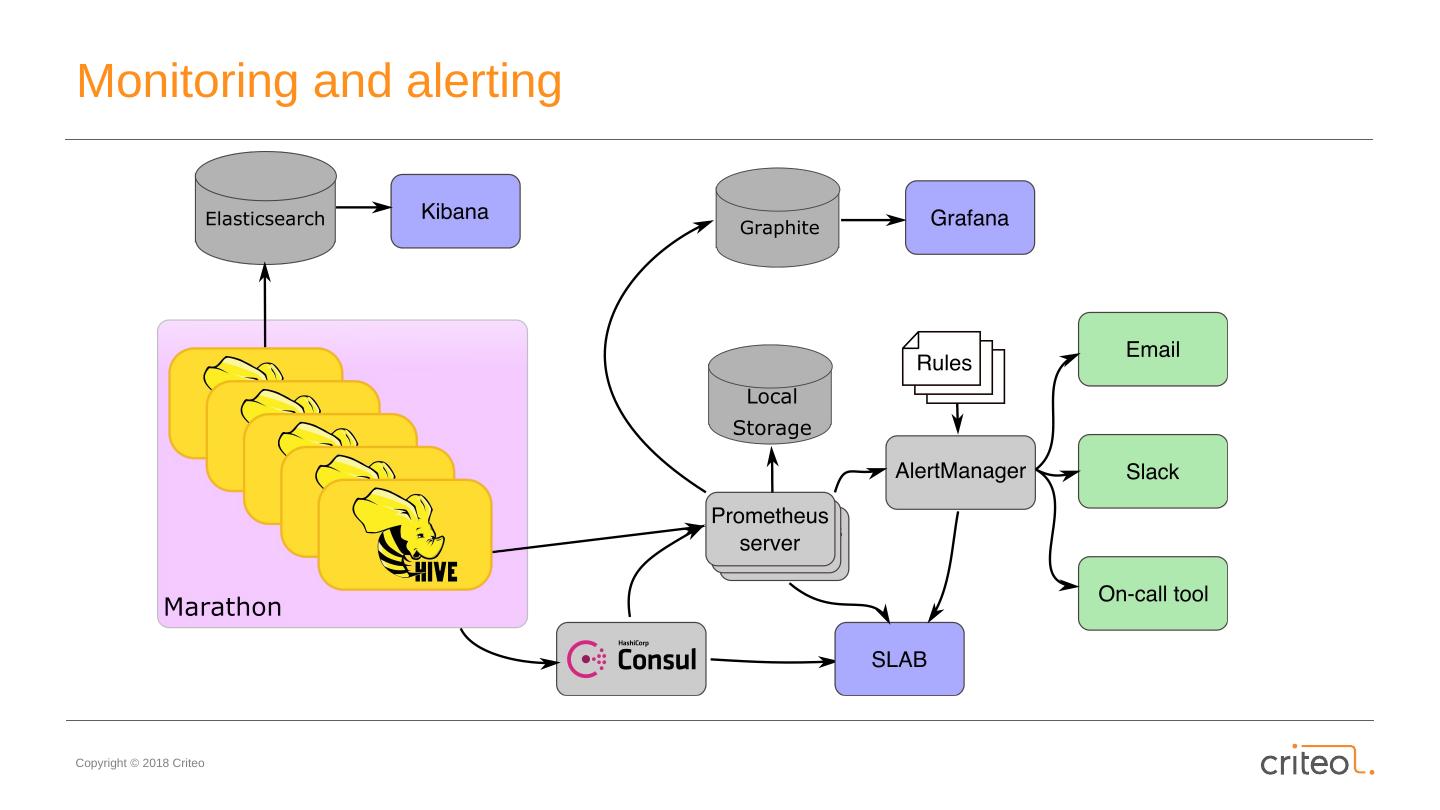
18 .Monitoring and alerting
19 .Monitoring and alerting $ curl hadoop-gateway.criteo.preprod:8001 hive: beeline_access { exported_instance ="mesos-node001.criteo.preprod"} 1.0 hive: hpc_kdc_access 0.0 hive: legacy_access { exported_instance ="11-11-11-11-11-11.criteo.preprod"} 0.0 hive: legacy_access { exported_instance ="22-22-22-22-22-22.criteo.preprod"} 0.0 hive: beeline_latency { exported_instance ="mesos-node001.criteo.preprod"} 2.2 ALERT HPCKDCAccess IF hive:hpc_kdc_access {cluster="prod_pa4"} == 1 FOR 3m LABELS { severity = "ticket", perimeter = "analytics-infrastructure" } ANNOTATIONS { summary = "HPC KDC access", description = "Cannot kinit in prod_pa4 against HPC KDC", documentation = " https://confluence.criteois.com/x/8AHiBg " }
20 .SLAB ( github.com / criteo /slab)
21 .Hive + Mesos + Kerberos This are us trying to understand Kerberos
22 .Hive + Mesos + Kerberos This is the painful tidbit Hive does not accept headless keytabs (e.g. hive@PA4.HPC.CRITEO.PROD ) When running in Marathon you dont know which machines youll run on When connecting to Hive users have to specify the kerberos principal We had to cheat by using service keytabs for fake machines We had to tweak our krb5.conf $ klist - kt / hive.keytab Keytab name: FILE:./ hive.keytab KVNO Timestamp Principal ---- ------------------- ----------------------------------------------- 2 23/05/2017 16:06:59 hive/hadoop-hive-metastore@PA4.HPC.CRITEO.PREPROD 2 23/05/2017 16:07:16 hive/hadoop-hive-hiveserver2@PA4.HPC.CRITEO.PREPROD [ libdefaults ] dns_canonicalize_hostname = false
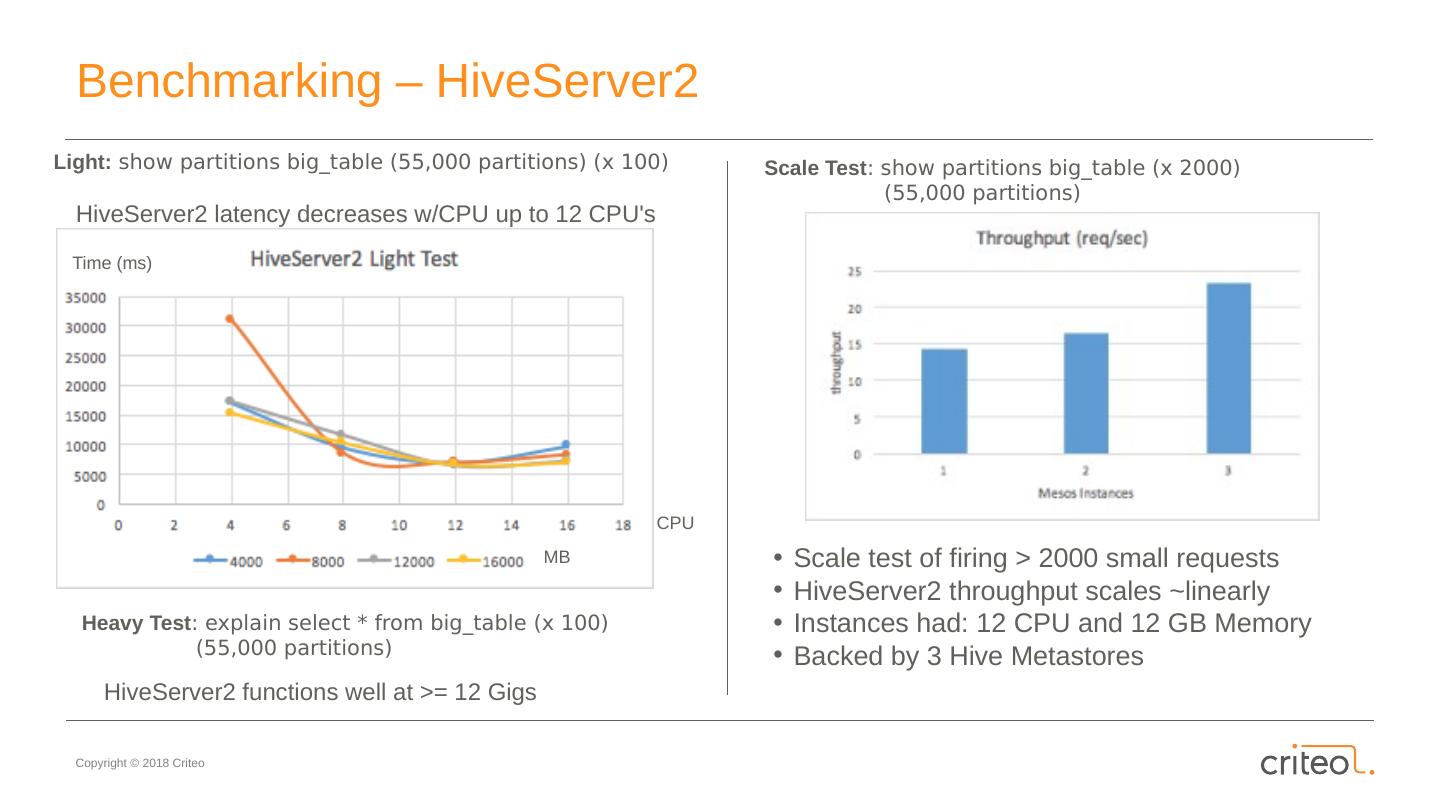
23 .Benchmarking – Hive Metastore Test: List partitions of really_huge_table with 1000 parallel connections from 3 machines Questions: How many CPUs/memory do we need per Mesos instance to survive the peak traffic? How does CPUs/memory impact performance? How many instances do we need to achieve the same performance as on bare-metal? Does performance of our set-up scale with number of instances? Total throughput
24 .Benchmarking – Hive Metastore Test: List partitions of really_huge_table with 1000 parallel connections from 3 machines Questions: How many CPUs/memory do we need per Mesos instance to survive the peak traffic? How does CPUs/memory impact performance? How many instances do we need to achieve the same performance as on bare-metal? Does performance of our set-up scale with number of instances? Total throughput
25 .Benchmarking – Hive Metastore Test: List partitions of really_huge_table with 1000 parallel connections from 3 machines Questions: How many CPUs/memory do we need per Mesos instance to survive the peak traffic? How does CPUs/memory impact performance? How many instances do we need to achieve the same performance as on bare-metal? Does performance of our set-up scale with number of instances? Total throughput
26 .Conclusions – what did we achieve? Decommissioning of Hive CLI Scaling out Hive Components Load balancing and high availability Self-healing with Marathon Lightweight Hive client Upgraded monitoring Enable Hive Upgrade
相关推荐
3秒后跳转登录页面
去登陆

