




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
李亚坤_Hadoop YARN在字节跳动的实践
李亚坤_Hadoop YARN在字节跳动的实践
展开查看详情
1 . E T B. N P U IT
2 . E T B. N P U IT liyakun.hit@bytedance.com (01/32)
3 .01. Introduction to YARN E T N 02. YARN@ByteDance Overview B . U 03. Customization@ByteDance P IT 04. Future Works (02/32)
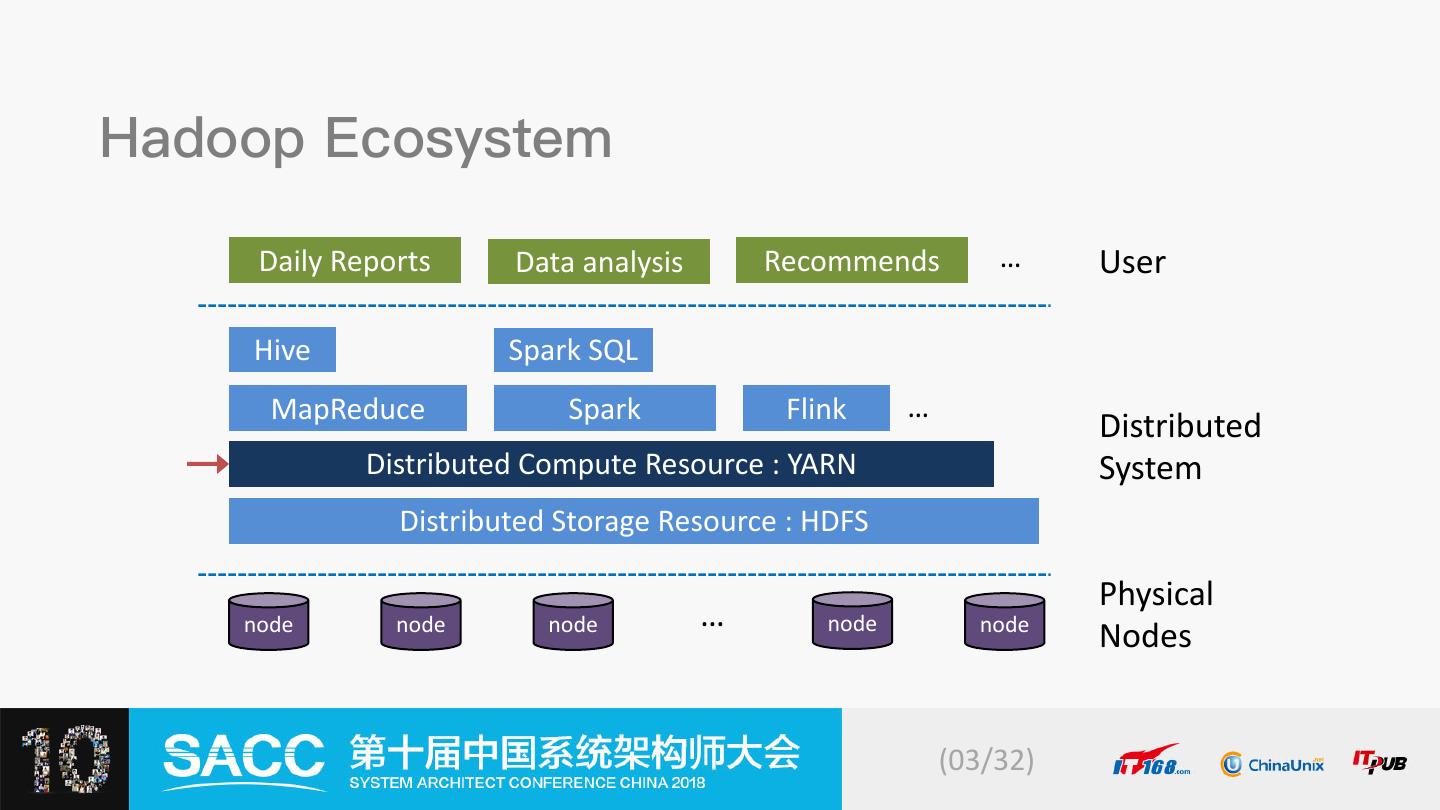
4 . Daily Reports Data analysis Recommends … User Hive Spark SQL MapReduce Spark Flink … Distributed Distributed Compute Resource : YARN System Distributed Storage Resource : HDFS Physical node node node … node node Nodes (03/32)
5 . NodeManager 5 2, 4 Container App Mstr 3 Client 1 Resource NodeManager Manager App Mstr Container Client NodeManager Container Container Container Job Runtime Node Status Resource Request (04/32)
6 .01. Introduction to YARN 02. YARN@ByteDance Overview 03. Customization@ByteDance 04. Future Works (05/32)
7 . N O D ES D I ST R I B U T I O N N O D ES E VO LU T I O N Stock double every 4+ months Nodes - X0K 15X Stream 29% Vcore - XM Batch 71% Memory - XPB Batch Stream 2017-03 2018-09 (06/32)
8 .Queue - ~400 Label - ~100 Cluster - ~10 DataCenter - ~5 (07/32)
9 .Jobs (per day) - ~340K MapReduce - ~300K Spark - ~40K Streaming - ~2K (08/32)
10 .Daily Active User - ~2K Monthly Active User - ~3K ... (09/32)
11 .Dev + Ops + Test - 5 queues disaster tolerance products failure rate user expansion labels multi region data burst (10/32)
12 .01. Introduction to YARN 02. YARN@ByteDance Overview 03. Customization@ByteDance 04. Future Works (11/32)
13 .Better node resource utilization - Delay scheduling for Dominant Resource Fairness node1 node2 node1 node2 2 3 2 2 8 8 7 8 8 7 8 2 2 CPU MEM CPU MEM CPU MEM CPU MEM 11:01 11:02 choose node1 choose node2 (12/32)
14 .Higher Container Throughput - Multithreading version of Fair Scheduler (13/32)
15 .Preemption for Yarn!!! Not for MapReduce - Refactoring preemption code - Preemption among a set of queues - Reduce the impact of preemption to a minimum (14/32)
16 .Failover may cause event avalanche at 5K nodes - Safe mode - Ignore unnecessary event (15/32)
17 .More stringent Stability Requirements at Production - Dynamic Reservation for Fair Scheduler - Label store integrated into ZKRMStateStore - Container logs retention policy & upload asynchronously (16/32)
18 .Stability challenges when scale increases - Hashed application staging & container log directory - NodeManager heartbeat back pressure - Relax locality for non-existent resource requests at beginning (17/32)
19 .Better isolation increases computational efficiency - NUMA awareness support for inner-node isolation MemoryA fast CPU1 slow CPU2 fast MemoryB (18/32)
20 .Make YARN more suitable streaming jobs - Port crisis for NodeManager restart - Reduce external file dependencies at runtime - Container log in real-time (19/32)
21 .- Unified UI for all clusters (jobs, label, queue manage) - Unified Hadoop client for all clusters (20/32)
22 .- Dtop: physical usage monitoring for container/app/queue (21/32)
23 .- Dynamic container resource adjustment restart Resource YARN DTOP job Estimator RM running C C C (22/32)
24 .- User default queue; Abnormal situation notification - Redesigned yarn UI for all clusters (23/32)
25 .- Btrace: For application source awareness k8s hive yarn hdfs k8s: User, Time, Application… hive: User, Time, Server… yarn: User, Time, Application Id… (24/32)
26 .- WebShell for entering the container runtime environment (25/32)
27 .- Reservation visualization for label - Unified history server for all jobs within 7 days (26/32)
28 .- Truman: For scheduling optimization evaluation - ClusterManager: Centralized node resource & label manager (27/32)
29 .- LogIndexService: For search container log in real-time (28/32)
相关推荐
3秒后跳转登录页面
去登陆

