






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
使用Apache Beam和HBase进行高效数据处理
使用Apache Beam和HBase进行高效数据处理
展开查看详情
1 .Efficient and portable data processing with Apache Beam and HBase Eugene Kirpichov, Google
2 . Agenda 1 History of Beam 2 Philosophy of the Beam programming model 3 Apache Beam project 4 Beam and HBase
3 .The Evolution of Apache Beam Colossus BigTable PubSub Dremel Google Cloud Dataflow Spanner Megastore Millwheel Flume Apache Beam MapReduce
4 . (2008) FlumeJava High-level API (2004) MapReduce (2014) Dataflow (2016) Apache Beam SELECT + GROUPBY Batch/streaming agnostic, Open ecosystem, Infinite out-of-order data, Community-driven (2013) Millwheel Portable Vendor-independent Deterministic Streaming
5 .Beam model: Unbounded, temporal, out-of-order data Unified No concept of "batch" / "streaming" at all Time Event time (when it happened, not when we saw it) Windowing Aggregation within time windows Keys Windows scoped to a key (e.g. user sessions) Triggers When is a window "complete enough" What to do when late data arrives
6 .What are you computing? Transforms Where in event time? Windowing When in processing time? Triggers How do refinements relate?
7 .What - transforms Element-Wise Aggregating Composite What Where When How
8 .Pipeline p = Pipeline.create(options); p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*")) .apply(FlatMapElements.via( word → Arrays.asList(word.split("[^a-zA-Z']+")))) .apply(Filter.byPredicate(word → !word.isEmpty())) .apply(Count.perElement()) .apply(MapElements.via( count → count.getKey() + ": " + count.getValue()) .apply(TextIO.Write.to("gs://.../...")); p.run();
9 .Where - windowing ● Windowing divides data into event-time-based finite chunks. ● Required when doing aggregations over unbounded data. What Where When How
10 .When - triggers Control when a Watermark window emits results Processing Time of aggregation Often relative to the watermark (promise about lateness of a Event Time source) What Where When How
11 . How do refinements relate? PCollection<KV<String, Integer>> output = input .apply(Window.into(Sessions.withGapDuration(Minutes(1))) .trigger(AtWatermark() .withEarlyFirings(AtPeriod(Minutes(1))) .withLateFirings(AtCount(1))) .accumulatingAndRetracting()) .apply(Sum.integersPerKey()); What Where When How
12 .Customizing What Where When How 1.Classic Batch 2. Batch with Fixed Windows 3. Streaming 4. Streaming with Speculative + Late Data What Where When How
13 .3 Apache Beam Project
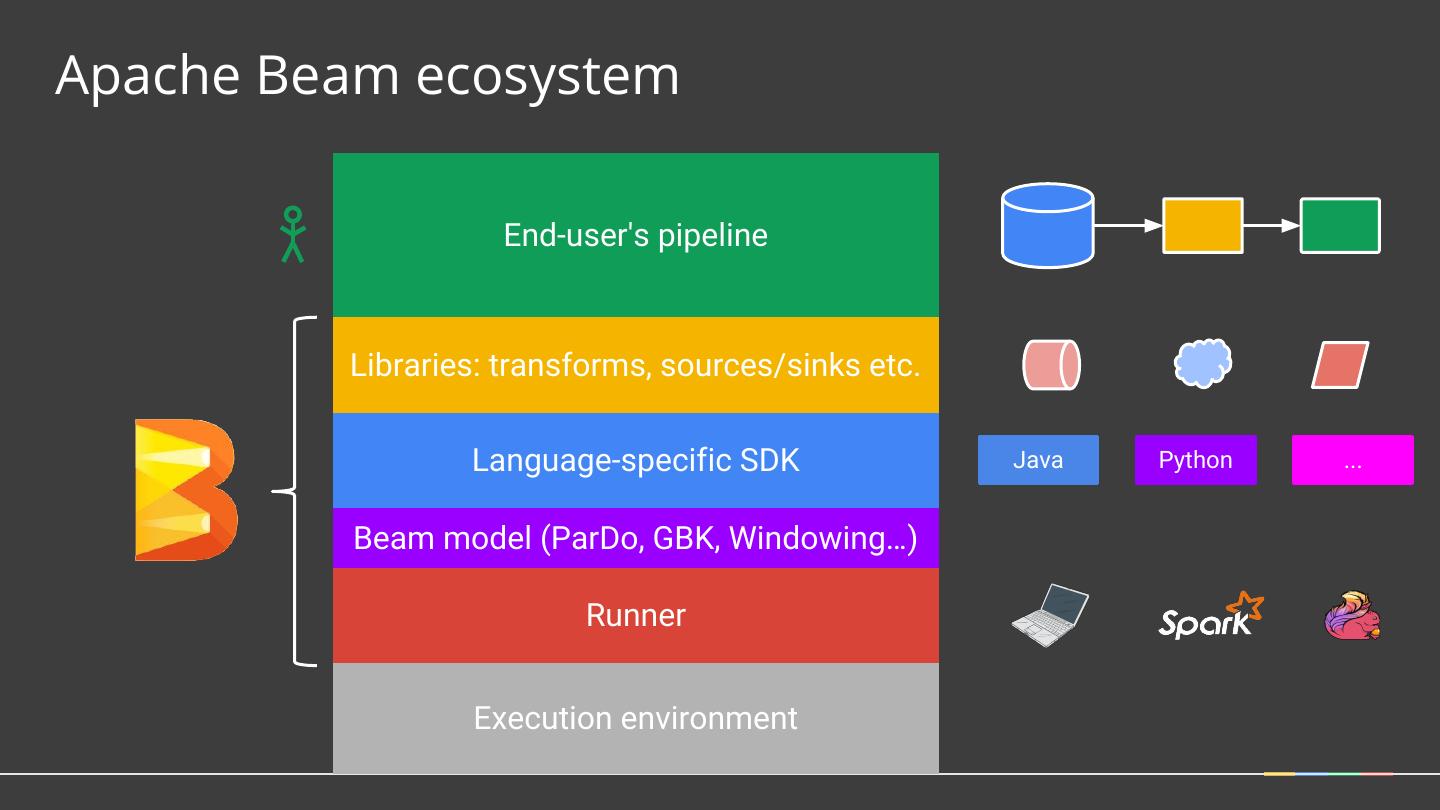
14 .What is Apache Beam? 1. The Beam Model: What / Where / When / How 2. SDKs for writing Beam pipelines -- Java, Python 3. Runners for Existing Distributed Processing Backends ○ Apache Apex ○ Apache Flink ○ Apache Spark ○ Google Cloud Dataflow ○ (WIP) Gearpump and others ○ Local (in-process) runner for testing
15 .The Apache Beam Vision 1. End users: who want to write Other Beam Beam Java Languages Python pipelines in a language that’s familiar. 2. SDK writers: who want to make Beam Model: Pipeline Construction Beam concepts available in new languages. Apache Cloud Apache Flink Dataflow Spark 3. Runner writers: who have a distributed processing environment Beam Model: Fn Runners and want to support Beam pipelines Execution Execution Execution
16 .Apache Beam ecosystem End-user's pipeline Libraries: transforms, sources/sinks etc. Language-specific SDK Java Python ... Beam model (ParDo, GBK, Windowing…) Runner Execution environment
17 . 02/25/2016 05/2017 1st commit to Beam 2.0 ASF repository First Stable Release Early 2016 Internal API redesign Late 2016 and relative chaos Multiple runners Mid 2016 Early 2017 Stabilization of New Polish and stability APIs 02/01/2016 Enter Apache Incubator
18 .Apache Beam Community 178 contributors 24 committers from 8 orgs (none >50%) >3300 PRs, >8600 commits, 27 releases >20 IO (storage system) connectors 5 runners
19 .4 Beam and HBase
20 .Beam IO connector ecosystem Many uses of Beam = importing data from one place to another Files Text, Avro, XML, TFRecord (pluggable FS - local, HDFS, GCS) Hadoop ecosystem HBase, HadoopInputFormat, Hive (HCatalog) Streaming systems Kafka, Kinesis, MQTT, JMS, (WIP) AMQP Google Cloud Pubsub, BigQuery, Datastore, Bigtable, Spanner Other JDBC, Cassandra, Elasticsearch, MongoDB, GridFS
21 .HBaseIO PCollection<Result> data = p.apply( HBaseIO.read() .withConfiguration(conf) .withTableId(table) … withScan, withFilter …) PCollection<KV<byte[], Iterable<Mutation>>> mutations = …; mutations.apply( HBaseIO.write() .withConfiguration(conf)) .withTableId(table)
22 .IO Connectors = just Beam transforms Made of Beam primitives ParDo, GroupByKey, … Write = often a simple ParDo Read = a couple of ParDo, “Source API” for power users ⇒ straightforward to develop, clean API, very flexible, batch/streaming agnostic
23 .Beam Write with HBase A bundle is a group of elements processed and committed together. APIs (ParDo/DoFn): setup() -> Creates Connection startBundle() -> Gets BufferedMutator processElement() -> Applies Mutation(s) Transaction finishBundle() -> BufferedMutator flush tearDown() -> Connection close Mutations must be idempotent, e.g. Put or Delete. Increment and Append should not be used.
24 .Beam Source API (similar to Hadoop InputFormat, but cleaner / more general) Estimate size Split into sub-sources (of ~given size) Read Iterate Get progress Dynamic split Note: Separate API for unbounded sources + (WIP) a new unified API
25 .HBase on Beam Source API HBaseSource Scan Estimate RegionSizeCalculator Split RegionLocation Read Iterate ResultScanner Region Server 1 Get progress Key interpolation Dynamic split* RangeTracker Region Server 2 * Dynamic Split for HBaseIO PR in progress
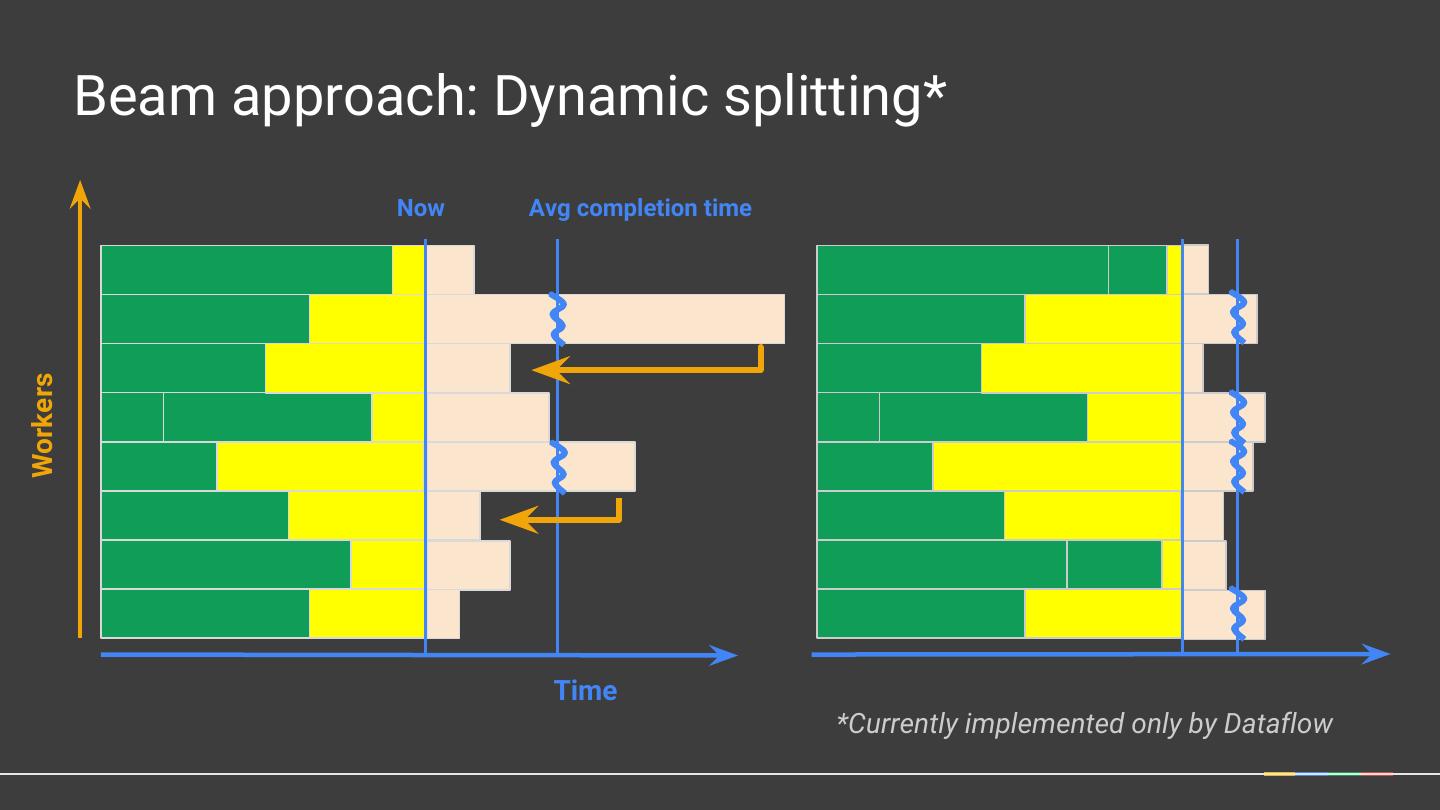
26 .Digression: Stragglers Workers Time Google Cloud Platform 26
27 . Beam approach: Dynamic splitting* Now Avg completion time Workers Time *Currently implemented only by Dataflow
28 .Autoscaling
29 .Learn More! Apache Beam https://beam.apache.org The World Beyond Batch 101 & 102 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102 No Shard Left Behind Straggler Free Data Processing in Cloud Dataflow Join the mailing lists! user-subscribe@beam.apache.org dev-subscribe@beam.apache.org Follow @ApacheBeam on Twitter
3秒后跳转登录页面
去登陆

