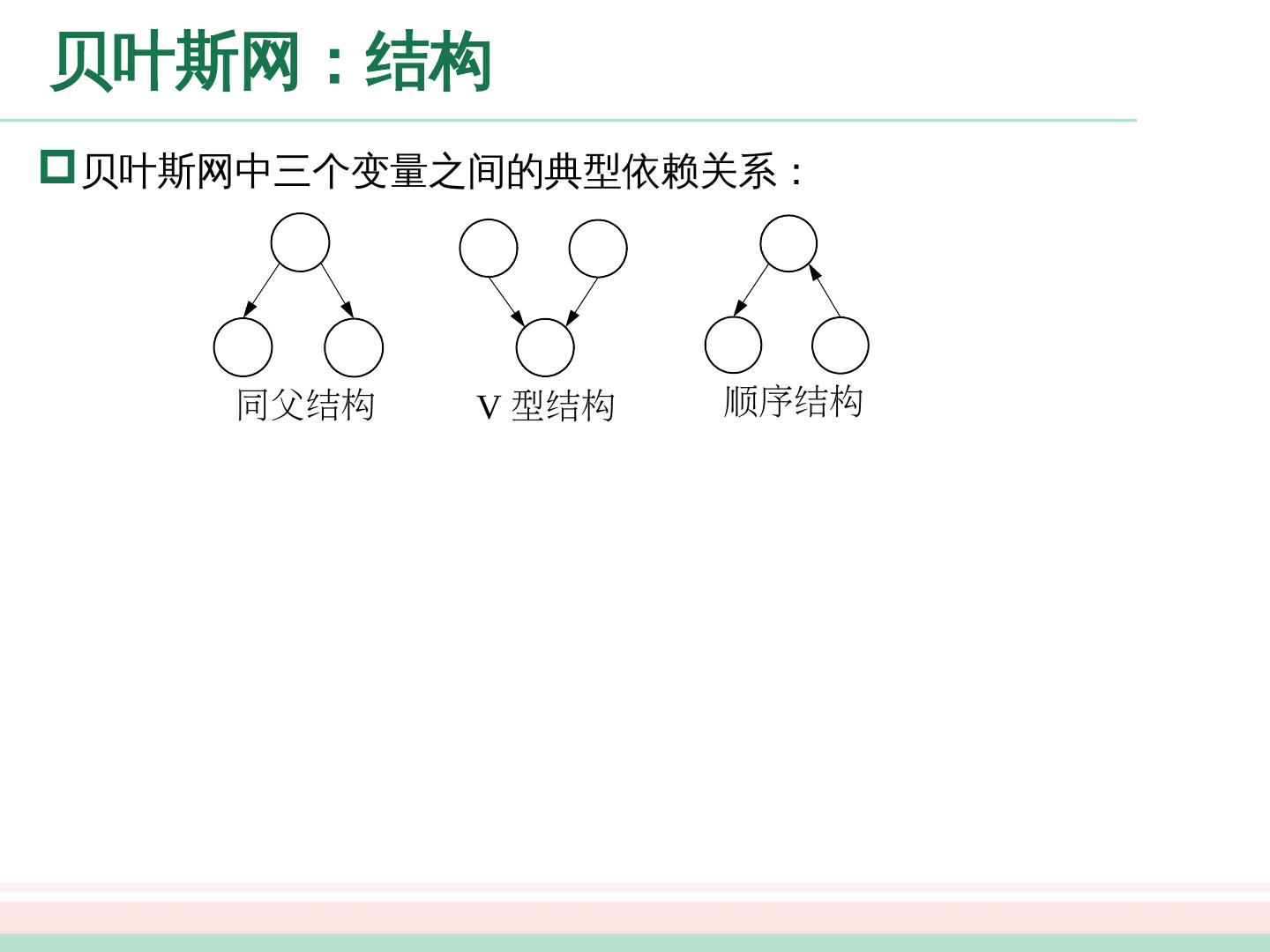
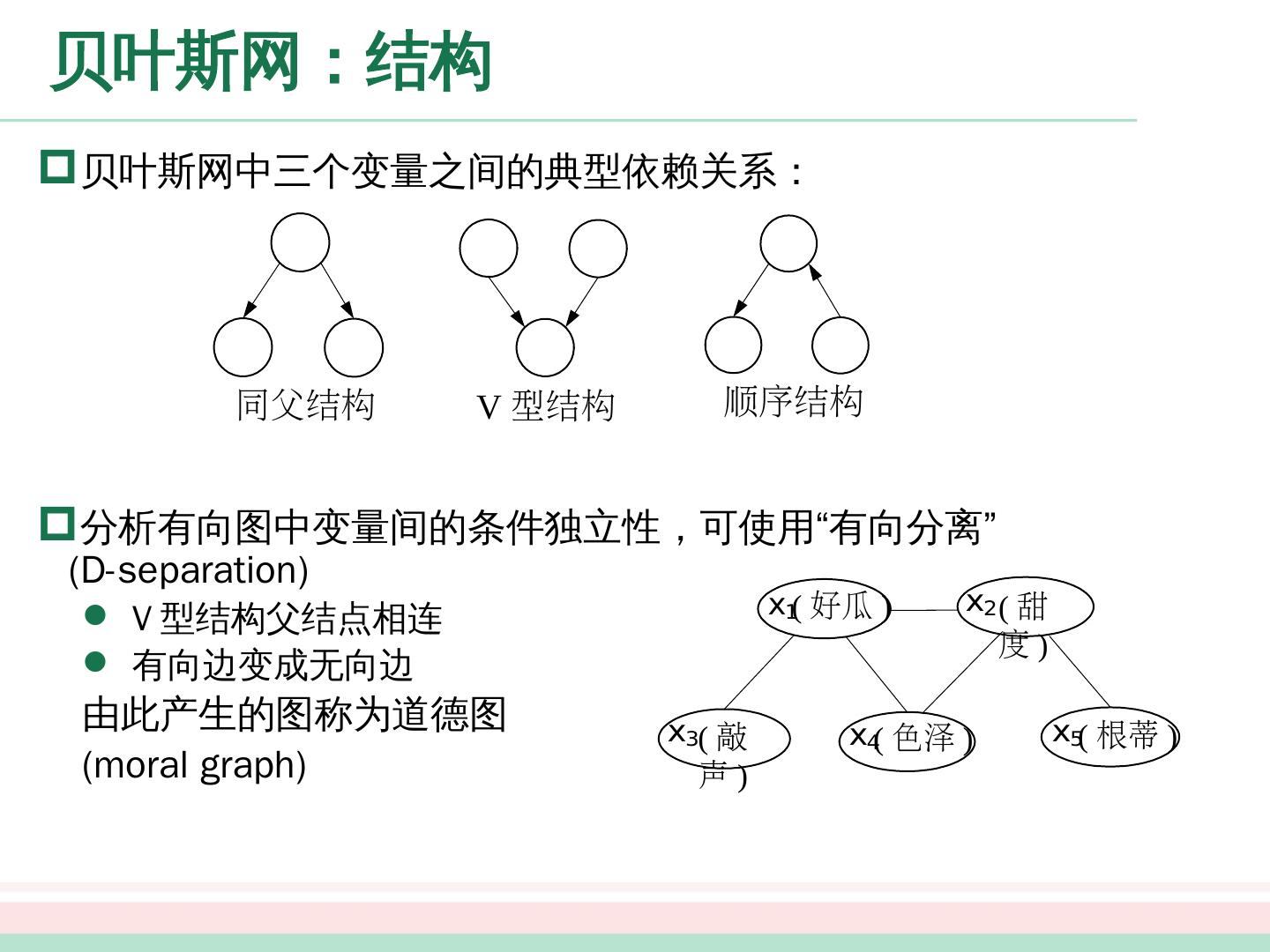
展开查看详情
3 .章节目录 贝叶斯决策论 极大似然估计 朴素贝叶斯分类器 半朴素贝叶斯分类器 贝叶斯网 EM 算法
4 .章节目录 贝叶斯决策论 极大似然估计 朴素贝叶斯分类器 半朴素贝叶斯分类器 贝叶斯网 EM 算法
5 .贝叶斯决策论 贝叶斯决策论( Bayesian decision theory )是在概率框架下实施决策的基本方法 。 在分类问题情况下,在 所有相关概率都已知的理想情形下,贝叶斯决策考虑如何基于这些概率和误判损失来选择最优的类别标记。
6 .贝叶斯决策论 贝叶斯决策论( Bayesian decision theory )是在概率框架下实施决策的基本方法 。 在分类问题情况下,在 所有相关概率都已知的理想情形下,贝叶斯决策考虑如何基于这些概率和误判损失来选择最优的类别标记。 假设有 种可能的类别标记,即 , 是将一个真实标记为 的样本误分类为 所产生的 损失。基于 后验概率 可获得将样本 分类为 所产生的期望损失( expected loss ),即在样本上的“条件风险”( conditional risk ) 我们的任务是寻找一个判定准则 以最小化总体风险
7 .贝叶斯决 策论 显然,对每个样本 ,若 能最小化条件风险 , 则总体风险 也 将被最小化 。
8 .贝叶斯决 策论 显然,对每个样本 ,若 能最小化条件风险 , 则总体风险 也 将被最小化 。 这 就产生了贝叶斯判定准则( Bayes decision rule ): 为最小化总体风险,只需在每个样本上选择那个能使条件风险 最小的类别标记, 即 此时,被称为贝叶斯最优分 类器 (Bayes optimal classifier ) ,与之对应的总体风险 称为贝叶斯风险 (Bayes risk) 反映了分类起所能达到的最好性能,即通过机器学习所能产生的模型精度的理论上限。
9 .贝叶斯决策论 具体来说, 若目标是最小化分类错误率,则误判损失 可写 为
10 .贝叶斯决策论 具体来说, 若目标是最小化分类错误率,则误判损失 可写 为 此时条件风险
11 .贝叶斯决策论 具体来说, 若目标是最小化分类错误率,则误判损失 可写 为 此时条件风险 于是,最小化分类错误率的贝叶斯最有分类器 为 即对每个样本 , 选择能使后验 概率 最大 的类别 标记。
12 .贝叶斯决策论 不难看出,使用贝叶斯判定准则来最小化决策风险,首先要获得后验 概率 。 然而,在 现实 中通常难以直接获得。机器 学习所要实现的是基于有限的训练样本尽可能准确地估计出后验 概率 。 主要有两种策略: 判别式模型( discriminative models ) 给 定 ,通过直接建模 , 来 预测 决策树, BP 神经网络,支持向 量机 生成式 模型( generative models ) 先 对联合概率分布 建模,再由此 获得 生成式模型考虑
14 .贝叶斯决策论 生成式模型 基于贝叶斯定理, 可写成
15 .贝叶斯决策论 生成式模型 基于贝叶斯定理, 可写成 先验概率 样本空间中各类样本所占的比例,可通过各类样本出现的频率估计(大数定理)
16 .贝叶斯决策论 生成式模型 基于贝叶斯定理, 可写成 先验概率 样本空间中各类样本所占的比例,可通过各类样本出现的频率估计(大数定理) “证据” ( evidence ) 因子,与类标记无关
17 .贝叶斯决策论 生成式模型 基于贝叶斯定理, 可写成 先验概率 样本空间中各类样本所占的比例,可通过各类样本出现的频率估计(大数定理) “证据” ( evidence ) 因子,与类标记无关 类标记 相对于样本 的 “ 类条件概率 ” ( class-conditional probability ), 或称“似然”。
18 .贝叶斯决策论 生成式模型 基于贝叶斯定理, 可写成 先验概率 样本空间中各类样本所占的比例,可通过各类样本出现的频率估计(大数定理) “证据” ( evidence ) 因子,与类标记无关 类标记 相对于样本 的 “ 类条件概率 ” ( class-conditional probability ), 或称“似然”。
19 .极大似然估计 估计类条件概率的常用 策略:先假定其具有某种确定的概率分布形式,再基于训练样本对概率分布参数 估计。 记关于类别 的 类条件概率为 , 假设 具有 确定的形式被参数 唯一确定,我们的任务就是利用训练集 估计参数
20 .极大似然估计 估计类条件概率的常用 策略:先假定其具有某种确定的概率分布形式,再基于训练样本对概率分布参数 估计。 记关于类别 的 类条件概率为 , 假设 具有 确定的形式被参数 唯一确定,我们的任务就是利用训练集 估计参数 概率 模型的训练过程就是参数估计过程,统计学界的两个学派提供了不同的方案: 频率主义学派 ( frequentist ) 认为参数虽然未知,但却存在客观值,因此可通过优化似然函数等准则来确定参数值 贝叶斯学派 (Bayesian) 认为参数是未观察到的随机变量、其本身也可由分布,因此可假定参数服从一个先验分布,然后基于观测到的数据计算参数的后验分布。
21 .极大似然估计 令 表示训练集中第 类样本的组合的集合,假设这些样本是独立的,则参数 对于数据集 的似然 是 对 进行极大似然估计,寻找能最大化似然 的参数值 。直观上看,极大似然估计是试图在 所有可能的取值中,找到一个使数据出现的“可能性”最大值。
22 .极大似然估计 令 表示训练集中第 类样本的组合的集合,假设这些样本是独立的,则参数 对于数据集 的似然 是 对 进行极大似然估计,寻找能最大化似然 的参数值 。直观上看,极大似然估计是试图在 所有可能的取值中,找到一个使数据出现的“可能性”最大值。 式 (7.9) 的连乘操作易造成下溢, 通常使用对数 似然 (log-likelihood) 此时 参数 的极大似然估计 为
23 .极大似然估计 例如,在连续属性情形下,假设概率密度函数 ,则参数 和 的极大似然估计为 也就是说,通过极大似然法得到的正态分布均值就是样本均值,方差就是 的均值,这显然是一个符合直觉的结果。 需注意的是,这种参数化的方法虽能使类条件概率估计变得相对简单,但估计结果的准确性严重依赖于所假设的概率分布形式是否符合潜在的真实数据分布。
24 .极大似然估计 例如,在连续属性情形下,假设概率密度函数 ,则参数 和 的极大似然估计为 也就是说,通过极大似然法得到的正态分布均值就是样本均值,方差就是 的均值,这显然是一个符合直觉的结果。 需注意的是,这种参数化的方法虽能使类条件概率估计变得相对简单,但估计结果的准确性严重依赖于所假设的概率分布形式是否符合潜在的真实数据分布。
25 .朴素贝叶斯分类器 估计 后验概率 主要 困难:类条件概率 是所有属性上的联合 概率难以从有限的训练样本估计获得。 朴素贝叶斯 分类器 (Naïve Bayes Classifier) 采用 了“属性条件独立性假设 ” (attribute conditional independence assumption) : 每个属性独立地对分类结果发生 影响。 基于属性条件独立性假设 , (7.8) 可 重写 为 其中 为 属性数目, 为 在第 个属性上的取值。
27 .朴素贝叶斯分类器 由于 对所有类别来说 相同,因此 基于式 (7.6) 的贝叶斯 判定准则有 这就是朴素贝叶斯分类起的表达式子
28 .朴素 贝叶斯分类器 朴素 贝叶斯分类器的训练器的训练过程就是基于训练集 估计类先验概率 并为每个属性估计条件概率 。 令 表示训练集 中第 类样本组合的集合,若有充足的独立同分布样本,则可容易地估计出类先验概率 对离散属性而言,令 表示 中在第 个属性上取值为 的样本组成的集合,则条件概率 可估计为 对连续属性而言可考虑概率密度函数,假定 ,其中 和 分别是第 类样本在第 个属性上取值的均值和方差,则有
29 .朴素贝叶斯分类器 例子:用西瓜数据集 3.0 训练一个朴素贝叶斯分类器,对测试例“测 1 ”进行分类 (p151, 西瓜数据集 p84 表 4.3)