展开查看详情
1 .面向Kubernetes的DevOps落地实践
——JFrog的Kubernetes之旅
演讲人:高欣
全球敏捷运维峰会 北京站
�
2 .高 欣
gaoxin@jfrogchina.com
• 博士
• JFrog架构师
• 前IBMer
• 敏捷、DevOps、。。。
• 软件产品/云服务 研发、测试、运维、服务、。。。
全球敏捷运维峰会 北京站
�
3 .JFrog内部的Kubernetes实践
o 我们正在做的:
➢ JFrog的应用和服务全面Kubernetes化
➢ 内部的研发和测试环境全面Kubernetes化
o 我们要分享的:
➢ 实践中积累的教训和经验
全球敏捷运维峰会 北京站
�
4 .JFrog内部的Kubernetes实践
——要解决的问题
o 用户安装部署JFrog产品复杂
o 无法快速搭建JFrog产品的全功能测试环境
➢ 无法实现按需使用:开发、测试、技术支持、产品、解决方案。。。任意团队
o 无法为每个分支提供独立的CI/CD流水线支撑
➢ 无法让研发有独立的沙箱环境进行自测
➢ CI/CD流程混乱
全球敏捷运维峰会 北京站
�
5 .Kubernetes is hard!
全球敏捷运维峰会 北京站
�
6 . JFrog内部的Kubernetes实践
——实践的成果
o 为客户提供全产品线的Helm Charts交付方式
➢ Helm install stable/Artifactory-ha
o 云端服务Kubernetes化
➢ GoCenter: http://gocenter.io
o 产品的CI/CD直接对接到Kubernetes环境
➢ 每周部署100+不同产品线、任意版本组合的测试环境,每次部署超过50种微服务
➢ 为每个研发、每个分支,按需提供完全独立的测试环境
全球敏捷运维峰会 北京站
�
7 .JFrog内部的Kubernetes实践
——教训和经验
o 起步:熟悉Kubernetes
o 规划:Kubernetes改造
o 编排:Helm Charts
o 流程:DevSecOps、监测
全球敏捷运维峰会 北京站
�
8 .起步:熟悉Kubernetes
——从小处入手
o 第一个Kubernetes环境
➢ 自己探索:Kubernetes The Hard Way,Kelsey Hightower
(https://github.com/kelseyhightower/kubernetes-the-hard-way)
➢ 公有服务:AKS、EKS、GKE、阿里、腾讯、。。。
➢ 私有部署:miniKube、Rancher、。。。
o 第一个Kubernetes应用
➢ 从小的示例应用开始,如Nginx
➢ 充分利用现有的教程和演示
➢ 每次只设定一个小的、具体的目标
全球敏捷运维峰会 北京站
�
9 . 规划:Kubernetes改造
The Twelve-Factor App
( https://12factor.net/zh_cn/ )
VII.端口绑定:通过端口绑定提供服务
I.基准代码:一份基准代码,多份部署
VIII.并发:通过进程模型进行扩展
II.依赖:显式声明依赖关系
IX.易处理:快速启动和优雅终止可最大化健壮性
III.配置:在环境中存储配置
X.开发环境与线上环境等价:尽可能的保持开发,
IV.后端服务:把后端服务当作附加资源
预发布,线上环境相同
V.构建,发布,运行:严格分离构建和运行
XI.日志:把日志当作事件流
VI.进程:以一个或多个无状态进程运行应用
XII.管理进程:后台管理任务当作一次性进程运行
全球敏捷运维峰会 北京站
�
10 .规划:应用的Kubernetes改造
仅仅把应用装进Docker是远远不够的
o 日志 o 合理地处理SIGTERM信号
➢ STDOUT/STDERR ➢ Shutdown必须是受控的
➢ 处理足够多的日志文件 ➢ Recovery必须是容易的
o 持久化数据 o 重启
➢ 哪些数据需要持久化存储? ➢ 如何处理上一次运行的遗留数据?
全球敏捷运维峰会 北京站
�
11 .规划:应用的Kubernetes改造
高可用将是新的标准配置
o 保证良好的持久性和可用性 o 不停机的滚动升级
➢ 保证向后兼容
o 支持同时运行多个应用实例 o K8s调整中的0宕机
➢ 支持负载均衡 ➢ Cluster Scale-up、Scale-down
➢ Scale-up、Scale-down必须是顺畅的 ➢ 计划中的Node维护
➢ 非计划的Node宕机
全球敏捷运维峰会 北京站
�
12 .规划:应用的Kubernetes改造
你的应用安全吗?
o 容器里不仅仅有自己的代码
➢ 系统包、开源库、三方应用
o 安全漏洞
o 开源许可证
全球敏捷运维峰会 北京站
�
13 .规划:配置的Kubernetes改造
运行环境的资源使用必须是受限的
…
resources:
o Pod的资源限制! requests:
memory: "1Gi"
o 应用本身也需要资源限制 cpu: "100m"
limits:
memory: "2Gi"
o 改造 cpu: "250m"
...
➢ requests/limits
➢ 跨Node的HA
➢ Out Of Resource Handling
(https://kubernetes.io/docs/tasks/administer-cluster/out-of-resource/)
➢ Pod Priority and Preemption
(https://kubernetes.io/docs/concepts/configuration/pod-priority-preemption/)
全球敏捷运维峰会 北京站
�
14 .规划:配置的Kubernetes改造
应用的运行状态必须有可信的健康数据
o readinessProbe
o livenessProbe
o 探针类型
➢ Http - return < 400 on success
➢ Tcp - succeed to open a socket on a given port
➢ Exec - return 0 on success
全球敏捷运维峰会 北京站
�
15 .规划:配置的Kubernetes改造
Pod里只有应用的容器是不够的 Application pod example.
Multiple artifactory logs forwarded by a Fluentbit
container to a log aggregator.
o init容器 —— 在应用容器启动前运行
➢ 准备存储
Pod
➢ 初始化设置
Application
container
o sidecar容器 —— 和应用容器同时运行
➢ 维护
Log
collector Fluentbit Logs
➢ 日志收集 container
➢ 监测
➢ 代理
全球敏捷运维峰会 北京站
�
16 .编排:Kubernetes部署
利用yaml文件编排已经足够好了吗?
o 多个组件、模块,对应多个yaml文件
o 应用的版本化怎么管理?
➢ 怎么管理多个yaml文件的版本组合?
o 配置数据怎么管理?
➢ 怎么部署到多个目标环境? 自测、开发、测试、产品。。。
o 怎么回滚到之前的特定版本?
全球敏捷运维峰会 北京站
�
17 .编排:Helm Charts
Helm —— 容器云应用的安装部署工具
o https://helm.sh
o Helm Hub
➢ https://hub.helm.sh
全球敏捷运维峰会 北京站
�
18 .编排:Helm Charts
版本化管理
o Helm Chart
➢ 一个包包含了所有模块 ——templates/
o Chart的版本化管理
➢ Chart.yaml
o 运行态的版本化管理
➢ Release
全球敏捷运维峰会 北京站
�
19 .编排:Helm Charts
配置数据分离
o 缺省配置
➢ values.yaml
o 目标环境配置
➢ values-test.yaml
➢ values-prod.yaml
全球敏捷运维峰会 北京站
�
20 .编排:Helm Charts
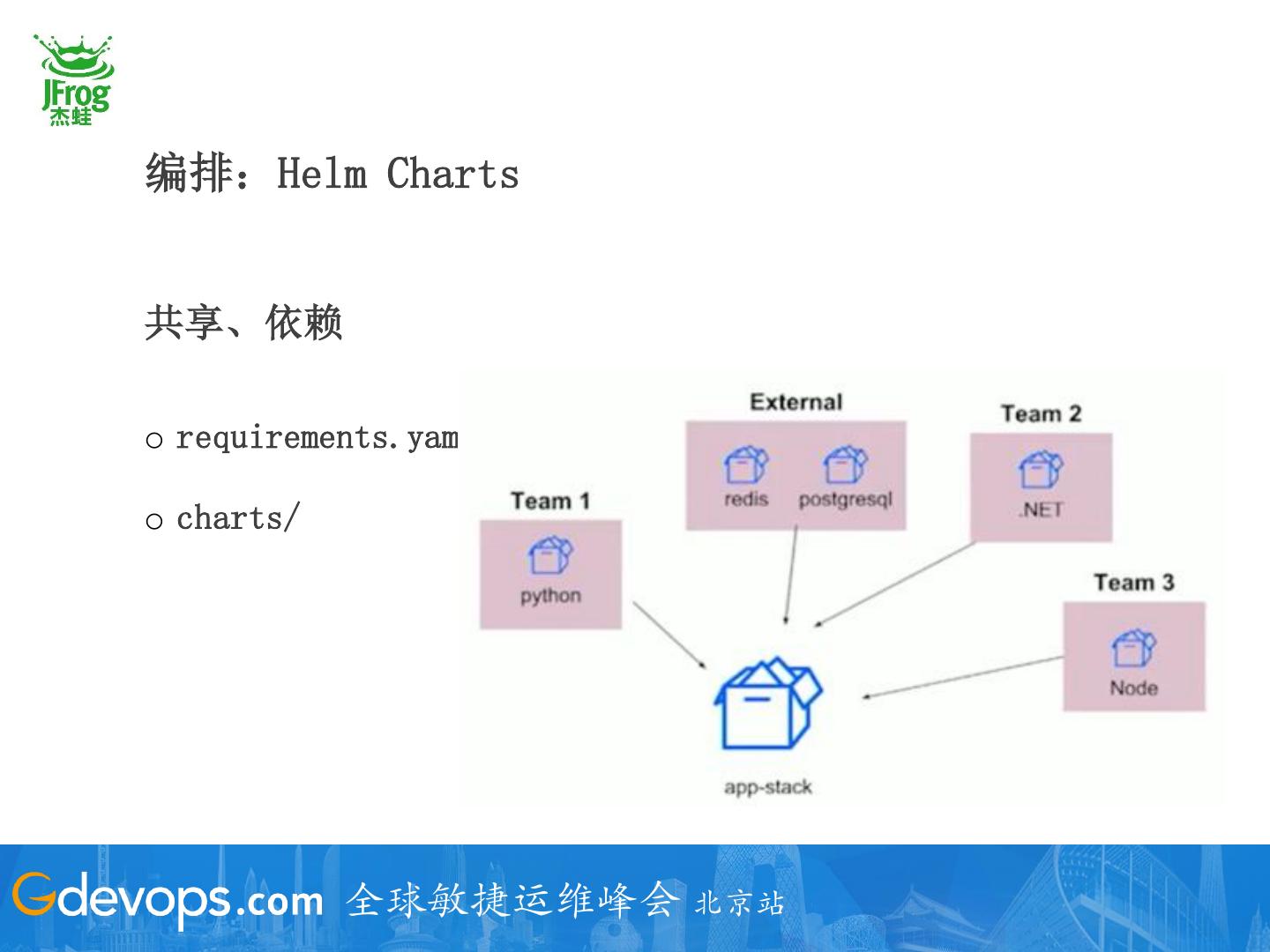
共享、依赖
o requirements.yaml
o charts/
全球敏捷运维峰会 北京站
�
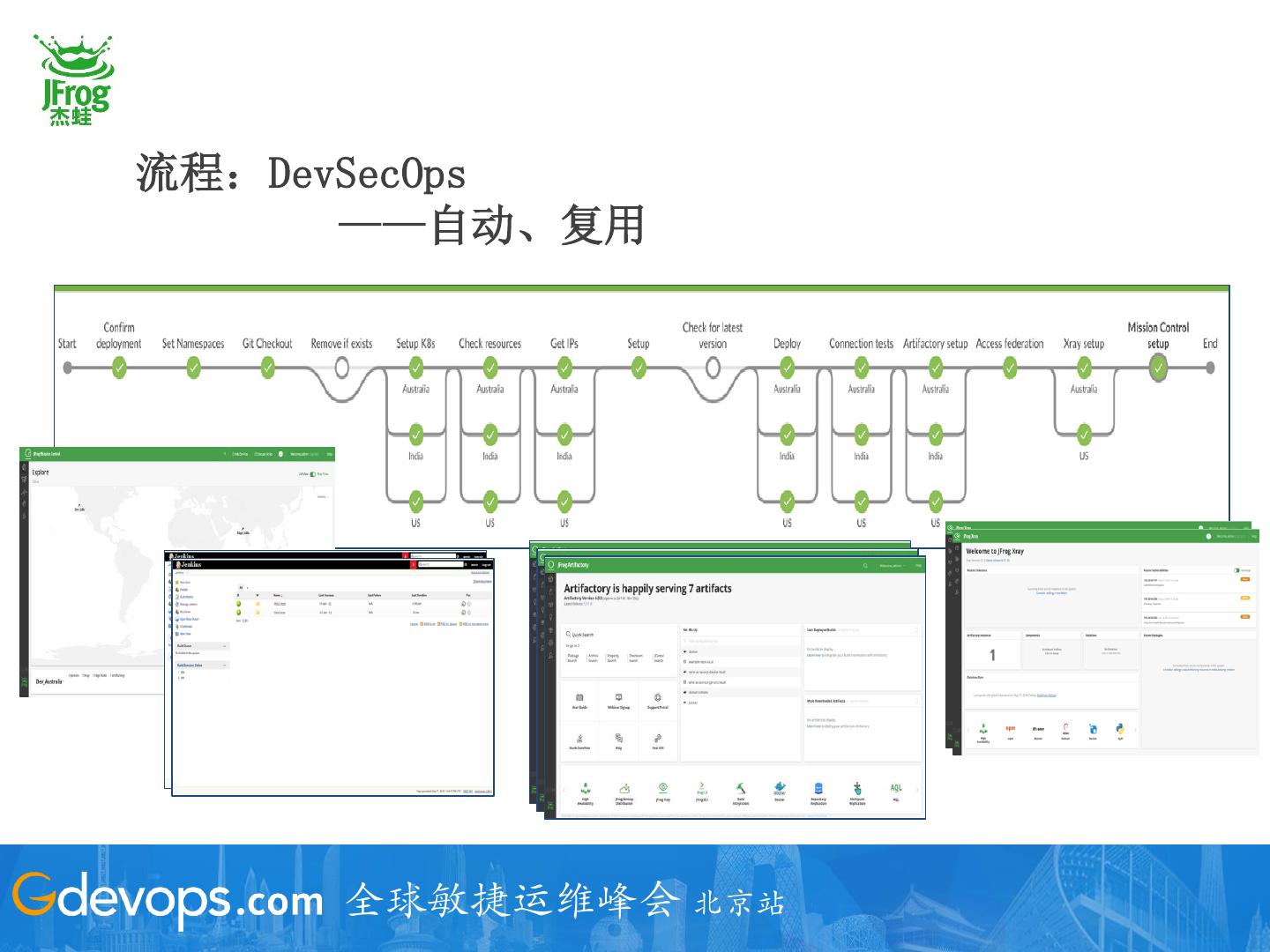
21 .流程:DevSecOps
——自动、复用
全球敏捷运维峰会 北京站
�
22 .流程:制品的统一管理
全球敏捷运维峰会 北京站
�
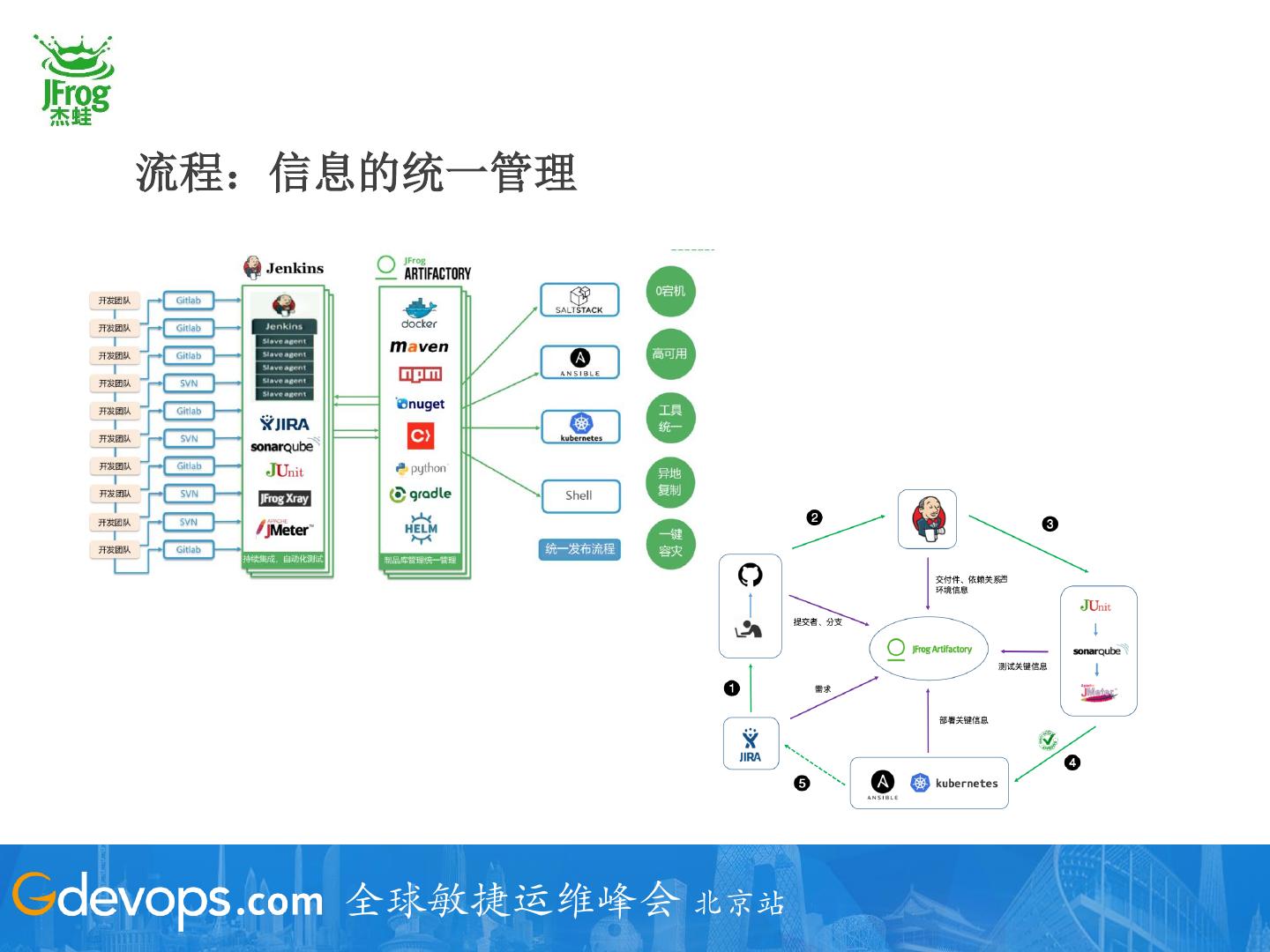
23 .流程:信息的统一管理
全球敏捷运维峰会 北京站
�
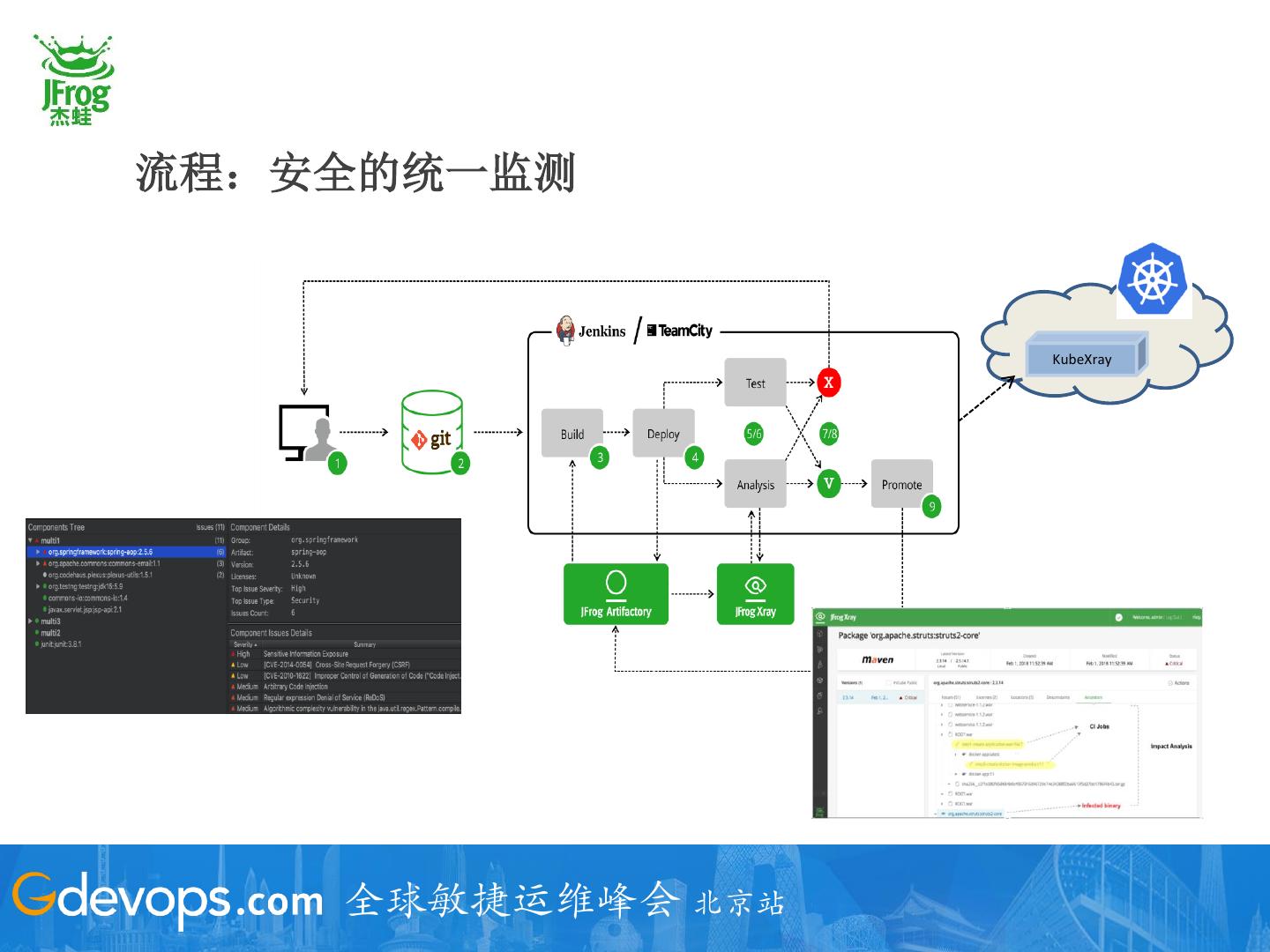
24 .流程:安全的统一监测
KubeXray
全球敏捷运维峰会 北京站
�
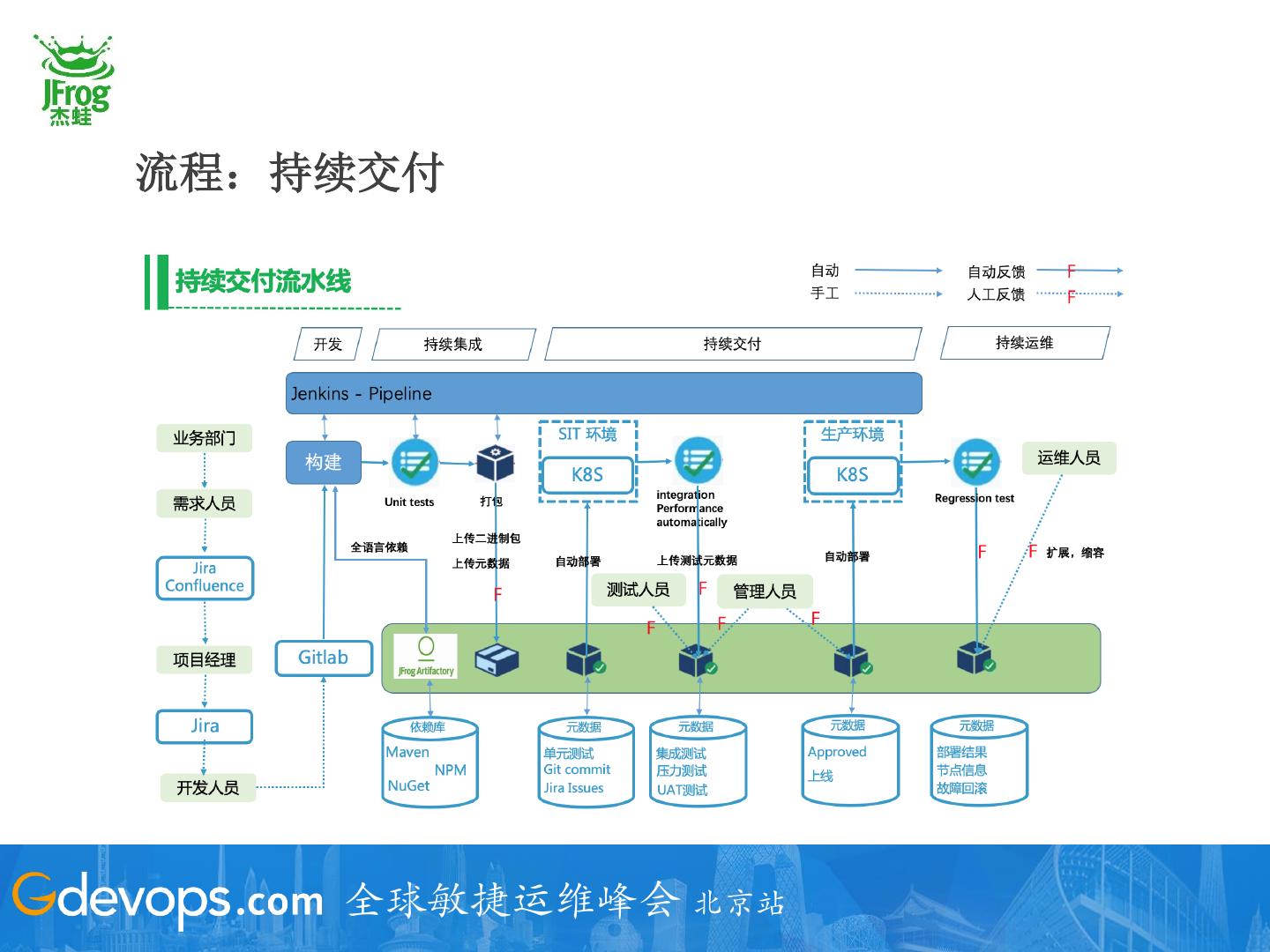
25 .流程:持续交付
流程:你的CI/CD自动化了吗?
全球敏捷运维峰会 北京站
�
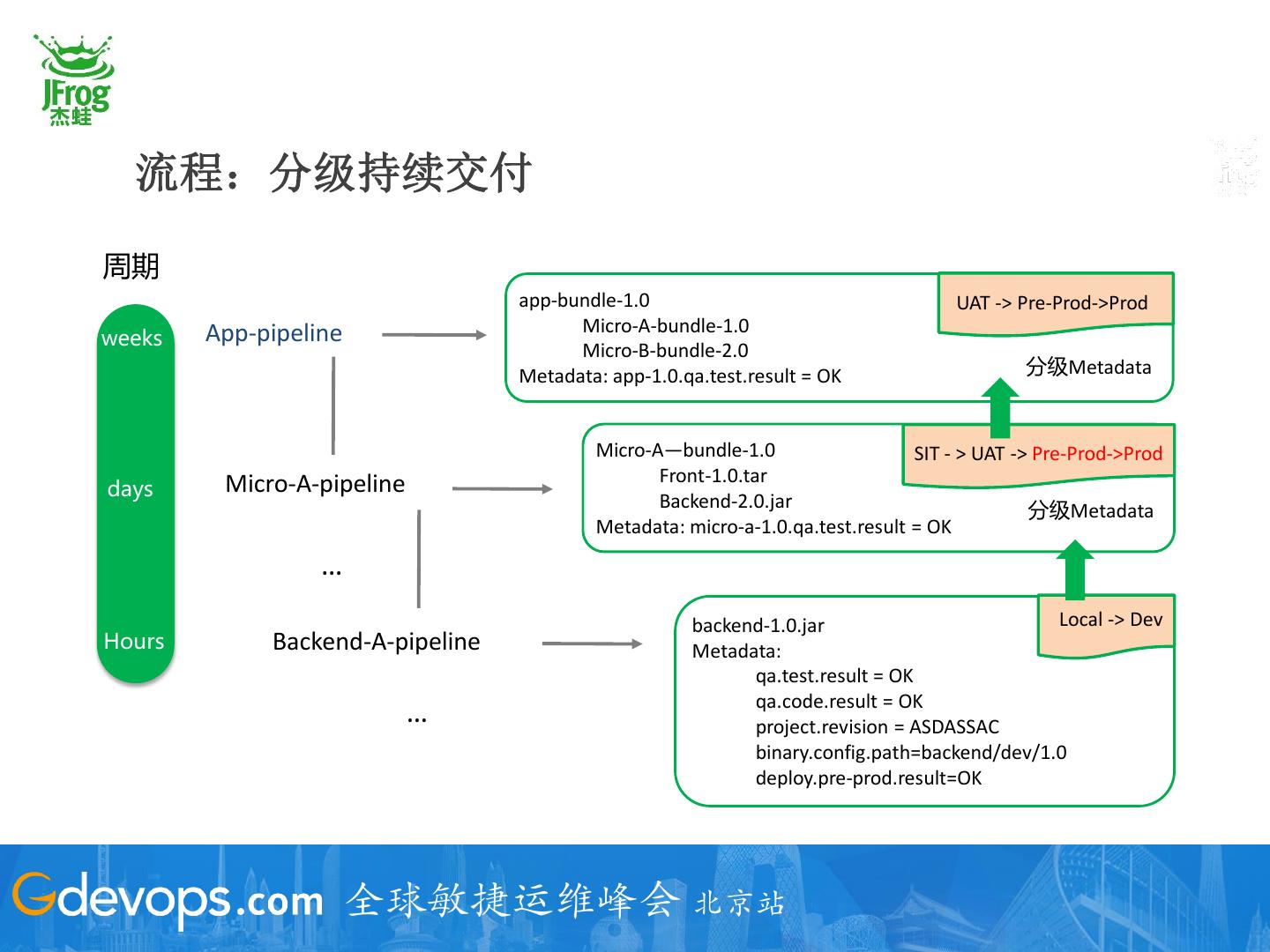
26 . 流程:分级持续交付
周期
app-bundle-1.0 UAT -> Pre-Prod->Prod
App-pipeline Micro-A-bundle-1.0
weeks
Micro-B-bundle-2.0
Metadata: app-1.0.qa.test.result = OK 分级Metadata
Micro-A—bundle-1.0 SIT - > UAT -> Pre-Prod->Prod
Micro-A-pipeline Front-1.0.tar
days
Backend-2.0.jar 分级Metadata
Metadata: micro-a-1.0.qa.test.result = OK
…
backend-1.0.jar Local -> Dev
Hours Backend-A-pipeline Metadata:
qa.test.result = OK
qa.code.result = OK
… project.revision = ASDASSAC
binary.config.path=backend/dev/1.0
deploy.pre-prod.result=OK
全球敏捷运维峰会 北京站
�
27 .流程:应用监测
需要新的监测手段
o ssh不管用了
o 直接用kubectl调试也是不合适的
o Dev/Ops应该能方便地访问可信的数据
➢ 监视
➢ 日志
o 基于可控的OOB(Out-of-Band)工具
o 微服务监测的基本原则 ( https://thenewstack.io/five-principles-monitoring-microservices )
全球敏捷运维峰会 北京站
�
28 .流程:应用监测
监视
o Prometheus
o Graphana
全球敏捷运维峰会 北京站
�
29 .流程:应用监测
日志
o EFK
全球敏捷运维峰会 北京站
�